Pourquoi le traitement incrémentiel des flux ?
Les entreprises pilotées par les données d’aujourd’hui produisent en permanence des données, ce qui nécessite des pipelines de données d’ingénierie qui ingèrent et transforment ces données en continu. Ces pipelines doivent pouvoir traiter et fournir des données exactement une fois, produire des résultats avec des latences inférieures à 200 millisecondes et essayer de réduire les coûts.
Cet article décrit les approches de traitement par lots et de flux incrémentiels pour les pipelines de données d’ingénierie, pourquoi le traitement de flux incrémentiel est la meilleure option et les étapes suivantes pour commencer à utiliser les offres de traitement de flux incrémentiels Databricks, Streaming sur Azure Databricks et Qu’est-ce que Delta Live Tables ?. Ces fonctionnalités vous permettent d’écrire et d’exécuter rapidement des pipelines qui garantissent la sémantique de remise, la latence, le coût, etc.
Pièges des travaux par lots répétés
Lors de la configuration de votre pipeline de données, vous pouvez d’abord écrire des tâches de traitement par lots répétées pour ingérer vos données. Par exemple, toutes les heures, vous pouvez exécuter un travail Spark qui lit à partir de votre source et écrit des données dans un récepteur comme Delta Lake. Le défi avec cette approche consiste à traiter de façon incrémentielle votre source, car le travail Spark qui s’exécute toutes les heures doit commencer à l’endroit où le dernier s’est terminé. Vous pouvez enregistrer le dernier horodatage des données que vous avez traitées, puis sélectionner toutes les lignes avec des horodatages plus récents que cet horodatage, mais il existe des pièges :
Pour exécuter un pipeline de données continu, vous pouvez essayer de planifier un travail de traitement par lots horaire qui lit de façon incrémentielle à partir de votre source, effectue des transformations et écrit le résultat dans un récepteur, tel que Delta Lake. Cette approche peut avoir des pièges :
- Un travail Spark qui interroge toutes les nouvelles données après un horodatage manquera les données tardives.
- Un travail Spark qui échoue peut entraîner des garanties exactement une fois, s’il n’est pas géré avec soin.
- Un travail Spark qui répertorie le contenu des emplacements de stockage cloud pour trouver de nouveaux fichiers deviendra coûteux.
Vous devez ensuite transformer ces données à plusieurs reprises. Vous pouvez écrire des travaux de traitement par lots répétés qui agrègent ensuite vos données ou appliquent d’autres opérations, ce qui complique davantage et réduit l’efficacité du pipeline.
Exemple de lot
Pour bien comprendre les pièges de l’ingestion et de la transformation par lots pour votre pipeline, tenez compte des exemples suivants.
Données manquées
Étant donné une rubrique Kafka avec des données d’utilisation qui déterminent la quantité de frais de vos clients et que votre pipeline ingère par lots, la séquence d’événements peut ressembler à ceci :
- Votre premier lot a deux enregistrements à 8 h et 18 h 30.
- Vous mettez à jour le dernier horodatage à 8h30.
- Vous obtenez un autre enregistrement à 8h15.
- Votre deuxième lot interroge tout après 8 h 30, vous manquez donc l’enregistrement à 8 h 15.
En outre, vous ne souhaitez pas surcharger ou sous-charger vos utilisateurs afin de vous assurer que vous ingérer chaque enregistrement exactement une fois.
Traitement redondant
Ensuite, supposons que vos données contiennent des lignes d’achats utilisateur et que vous souhaitez agréger les ventes par heure afin que vous connaissiez les heures les plus populaires dans votre magasin. Si les achats pour la même heure arrivent dans différents lots, vous aurez plusieurs lots qui produisent des sorties pendant la même heure :
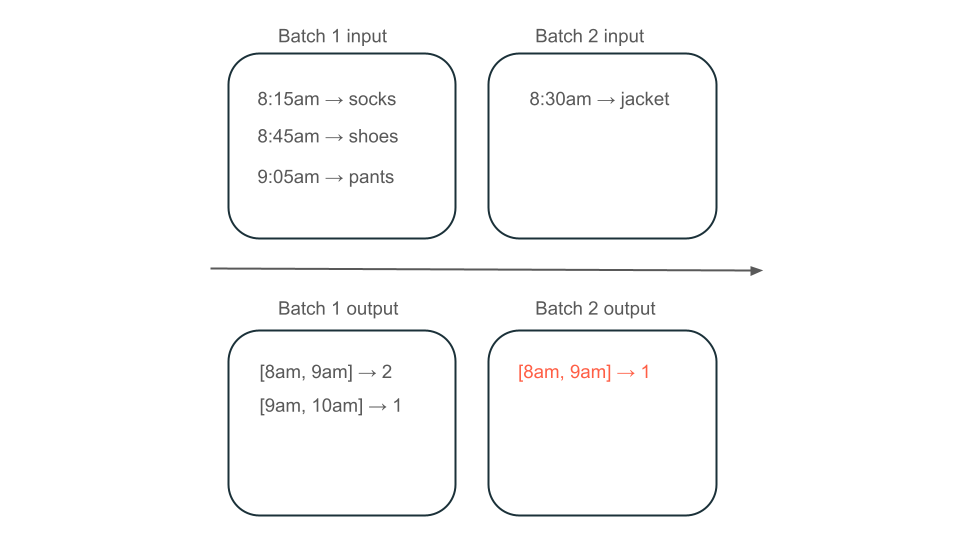
La fenêtre de 8h à 9h a-t-elle deux éléments (la sortie du lot 1), un élément (la sortie du lot 2) ou trois (la sortie de aucun lot) ? Les données requises pour produire une fenêtre donnée de temps s’affichent sur plusieurs lots de transformation. Pour résoudre ce problème, vous pouvez partitionner vos données par jour et retraiter toute la partition lorsque vous devez calculer un résultat. Ensuite, vous pouvez remplacer les résultats dans votre récepteur :
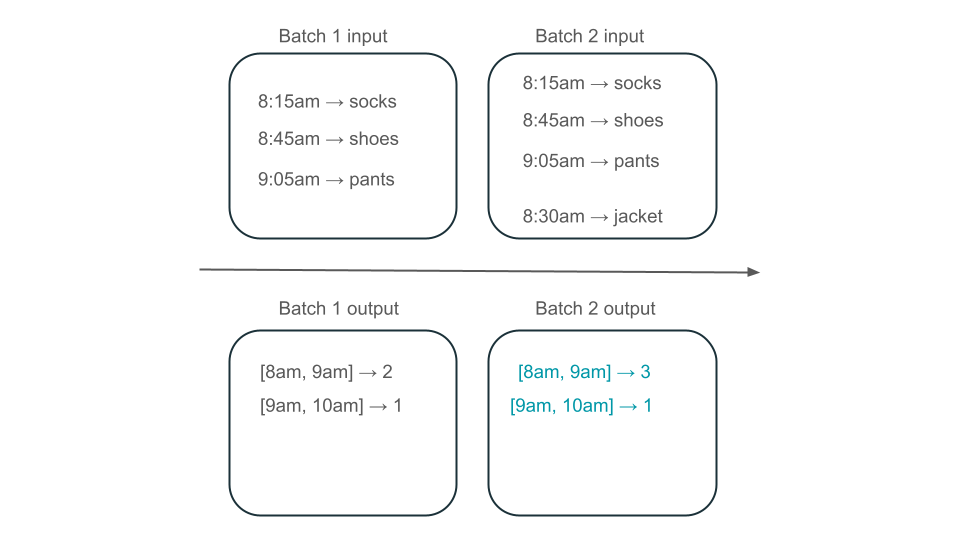
Toutefois, cela se produit au détriment de la latence et du coût, car le deuxième lot doit effectuer le travail inutile de traitement des données qu’il a peut-être déjà traitées.
Aucun piège avec le traitement de flux incrémentiel
Le traitement de flux incrémentiel permet d’éviter facilement tous les pièges des travaux de traitement par lots répétés pour ingérer et transformer des données. Databricks Structured Streaming et Delta Live Tables gèrent les complexités d’implémentation de la diffusion en continu pour vous permettre de vous concentrer uniquement sur votre logique métier. Vous devez uniquement spécifier la source à laquelle se connecter, quelles transformations doivent être effectuées sur les données et où écrire le résultat.
Ingestion incrémentielle
L’ingestion incrémentielle dans Databricks est alimentée par Apache Spark Structured Streaming, qui peut consommer de manière incrémentielle une source de données et l’écrire dans un récepteur. Le moteur Structured Streaming peut consommer des données exactement une seule fois, et le moteur peut gérer les données hors commande. Le moteur peut être exécuté dans des notebooks ou à l’aide de tables de streaming dans Delta Live Tables.
Le moteur Structured Streaming sur Databricks fournit des sources de diffusion en continu propriétaires telles que AutoLoader, qui peuvent traiter de manière incrémentielle les fichiers cloud de manière rentable. Databricks fournit également des connecteurs pour d’autres bus de messages populaires tels qu’Apache Kafka, Amazon Brokers, Apache Pulsar et Google Pub/Sub.
Transformation incrémentielle
La transformation incrémentielle dans Databricks avec Structured Streaming vous permet de spécifier des transformations en DataFrames avec la même API qu’une requête par lots, mais elle effectue le suivi des données entre les lots et les valeurs agrégées au fil du temps afin que vous n’ayez pas à le faire. Il n’a jamais à retraiter les données. Il est donc plus rapide et plus rentable que les travaux de traitement par lots répétés. Structured Streaming produit un flux de données qu’il peut ajouter à votre récepteur, comme Delta Lake, Kafka ou tout autre connecteur pris en charge.
Les vues matérialisées dans les tables dynamiques Delta sont alimentées par le moteur Enzyme. Enzyme traite toujours de façon incrémentielle votre source, mais au lieu de produire un flux, il crée une vue matérialisée, qui est une table précalcalisée qui stocke les résultats d’une requête que vous lui donnez. Enzyme est en mesure de déterminer efficacement la façon dont les nouvelles données affectent les résultats de votre requête et conserve la table précalcalée à jour.
Les vues matérialisées créent une vue sur votre agrégat qui est toujours mise à jour efficacement afin que, par exemple, dans le scénario décrit ci-dessus, vous savez que la fenêtre de 8h à 9h possède trois éléments.
Structured Streaming ou Delta Live Tables ?
La différence significative entre Structured Streaming et Delta Live Tables est la façon dont vous opérationnalisez vos requêtes de diffusion en continu. Dans Structured Streaming, vous spécifiez manuellement de nombreuses configurations et vous devez assembler manuellement des requêtes. Vous devez démarrer explicitement des requêtes, attendre qu’elles se terminent, les annuler en cas d’échec et d’autres actions. Dans Delta Live Tables, vous donnez de manière déclarative à Delta Live Tables vos pipelines à exécuter, et il les maintient en cours d’exécution.
Delta Live Tables a également des fonctionnalités telles que les vues matérialisées, qui précomputent efficacement et incrémentiellement les transformations de vos données.
Pour plus d’informations sur ces fonctionnalités, consultez Streaming sur Azure Databricks et Qu’est-ce que Delta Live Tables ?.
Étapes suivantes
Créez votre premier pipeline avec Delta Live Tables. Consulter Tutoriel : Exécuter votre premier pipeline Delta Live Tables.
Exécutez vos premières requêtes Structured Streaming sur Databricks. Consultez Exécuter votre première charge de travail Structured Streaming.
Utilisez une vue matérialisée. Consultez Utiliser des vues matérialisées dans Databricks SQL.