Techniques CI/CD avec Git et les dossiers Git Databricks (référentiels)
Découvrez les techniques d’utilisation des dossiers Git Databricks dans des workflows CI/CD. En configurant des dossiers Git Databricks dans l’espace de travail, vous pouvez utiliser le contrôle de code source pour les fichiers projet dans les référentiels Git et les intégrer à vos pipelines d’engineering données.
La figure suivante montre une vue d’ensemble des techniques et du workflow.
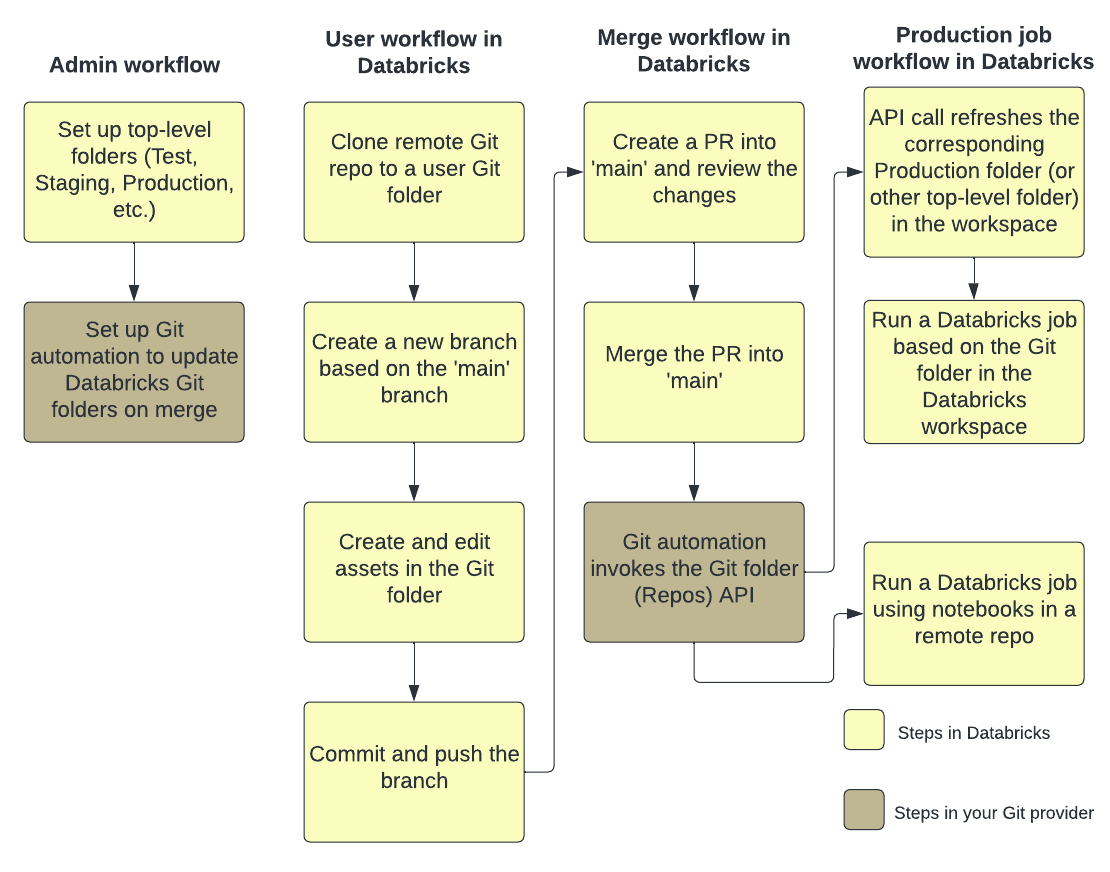
Pour obtenir une vue d’ensemble de CI/CD avec Azure Databricks, consultez Qu’est-ce que le CI/CD sur Azure Databricks ?.
Flux de développement
Les dossiers Git Databricks ont des dossiers au niveau de l’utilisateur. Les dossiers de niveau utilisateur sont créés automatiquement quand les utilisateurs clonent un dépôt distant pour la première fois. Vous pouvez considérer les dossiers Git Databricks dans les dossiers utilisateur comme des « validations locales » propres à chaque utilisateur, où les utilisateurs apportent des modifications à leur code.
Dans votre dossier utilisateur dans les dossiers Git Databricks, clonez votre référentiel distant. Une meilleure pratique consiste à créer une branche de fonctionnalité ou à sélectionner une branche créée précédemment pour votre travail, au lieu de valider et d’envoyer directement les modifications à la branche principale. Vous pouvez apporter des modifications, les valider et les transmettre dans cette branche. Lorsque vous êtes prêt à fusionner votre code, vous pouvez le faire dans l’interface utilisateur Dossiers Git.
Spécifications
Ce workflow nécessite que vous ayez déjà configuré votre intégration Git.
Remarque
Databricks recommande que chaque développeur travaille sur sa propre branche de fonctionnalité. Pour plus d’informations sur la résolution des conflits de fusion, consultez Résoudre les conflits de fusion.
Collaborer dans des dossiers Git
Le flux de travail suivant utilise une branche appelée feature-b basée sur la branche primaire.
- Clonez votre dépôt Git existant dans votre espace de travail Databricks.
- Utilisez l’interface utilisateur Dossiers Git pour créer une branche de fonctionnalité à partir de la branche primaire. Par souci de simplicité, cet exemple utilise une branche de fonctionnalité unique,
feature-b. Vous pouvez créer et utiliser plusieurs branches de fonctionnalité pour accomplir votre travail. - Apportez vos changements aux notebooks Azure Databricks et autres fichiers dans le référentiel.
- Validez et envoyez (push) vos modifications à votre fournisseur Git.
- Des contributeurs peuvent désormais cloner le dépôt Git dans leur propre dossier utilisateur.
- Alors qu’il travaille sur une nouvelle branche, un collègue apporte des changements aux notebooks et à d’autres fichiers dans le dossier Git.
- Le contributeur valide et envoie ses modifications au fournisseur Git.
- Pour fusionner les modifications d’autres branches ou rebaser la branche feature-b dans Databricks, dans l’interface utilisateur Dossiers Git, utilisez l’un des flux de travail suivants :
- Fusionnez des branches. En l’absence de conflit, la fusion est envoyée au dépôt Git distant avec
git push. - Rebasez sur une autre branche.
- Fusionnez des branches. En l’absence de conflit, la fusion est envoyée au dépôt Git distant avec
- Quand vous êtes prêt à fusionner votre travail avec le référentiel Git distant et la branche
main, utilisez l’interface utilisateur Dossiers Git pour fusionner les modifications de feature-b. Si vous préférez, vous pouvez fusionner à la place les modifications directement avec le référentiel Git appuyant votre dossier Git.
Flux de travail de production
Dossiers Git Databricks fournit deux options pour l’exécution de vos travaux de production :
- Option 1 : fournissez une référence Git au dépôt distant dans la définition du travail. Par exemple, exécutez un notebook spécifique dans la branche
maind’un dépôt Git. - Option 2 : configurer un référentiel Git de production et appeler les API Repos pour le mettre à jour par programmation. Exécutez les travaux sur le dossier Git Databricks qui clone ce référentiel distant. L’appel d’API Repos doit être la première tâche du travail.
Option 1 : exécuter des travaux à l’aide de notebooks dans un dépôt distant
Simplifiez le processus de définition de travail et conservez une source unique de vérité en exécutant un travail Azure Databricks à l’aide de notebooks situés dans un référentiel Git distant. Cette référence Git peut être un commit, une balise ou une branche Git, et vous la fournissez vous-même dans la définition du travail.
Cela permet d’éviter les modifications involontaires apportées à votre travail de production, par exemple quand un utilisateur apporte des modifications locales dans un dépôt de production ou change de branche. Cela automatise également l’étape de déploiement continu (CD), car vous n’avez pas besoin de créer un dossier Git de production distinct dans Databricks, de gérer les autorisations le concernant et de le tenir à jour.
Consultez Utiliser Git avec des travaux.
Option 2 : configurer un dossier Git de production et l’automatisation Git
Dans cette option, vous configurez un dossier Git de production et l’automatisation pour mettre à jour le dossier Git lors d’une fusion.
Étape 1 : Configurer des dossiers de premier niveau
L’administrateur crée des dossiers de premier niveau non utilisateur. Le cas d’usage le plus courant de ces dossiers de premier niveau consiste à créer des dossiers de développement, de préproduction et de production contenant des dossiers Git Databricks pour les versions ou branches appropriées pour le développement, la préproduction et la production. Par exemple, si votre entreprise utilise la branche main pour la production, le dossier Git « production » doit contenir la branche main extraite.
En général, les autorisations sur ces dossiers de niveau supérieur sont en lecture seule pour tous les utilisateurs non administrateurs au sein de l’espace de travail. Pour ces dossiers de premier niveau, nous vous recommandons de ne donner au(x) principal(aux) de service que les autorisations PEUT MODIFIER et PEUT GÉRER afin d’éviter que les utilisateurs de l’espace de travail ne modifient accidentellement votre code de production.
Étape 2 : Configurer les mises à jour automatisées des dossiers Git Databricks avec l’API Dossiers Git
Pour conserver un dossier Git dans Databricks à la dernière version, vous pouvez configurer l’automatisation Git pour appeler l’API Repos. Dans votre fournisseur Git, configurez une automatisation qui, après chaque fusion réussie d’une demande de tirage dans la branche primaire, appelle le point de terminaison de l’API Repos sur le dossier Git approprié pour le mettre à jour avec la version la plus récente.
Par exemple, sur GitHub, cela peut être accompli avec GitHub Actions. Pour plus d’informations, consultez API Repos.
Utiliser un principal de service pour l’automatisation avec les dossiers Git Databricks
Vous pouvez utiliser la console de compte Azure Databricks ou l’interface CLI Databricks pour créer un principal de service autorisé à accéder aux dossiers Git de votre espace de travail.
Pour créer un service principal, consultez Gérer les services principaux. Lorsque vous disposez d’un principal de service dans votre espace de travail, vous pouvez y lier vos informations d’identification Git afin qu’elle puisse accéder aux dossiers Git de votre espace de travail dans le cadre de votre automatisation.
Autoriser un principal de service à accéder aux dossiers Git
Pour fournir un accès autorisé à vos dossiers Git pour un principal de service à l’aide de la console de compte Azure Databricks :
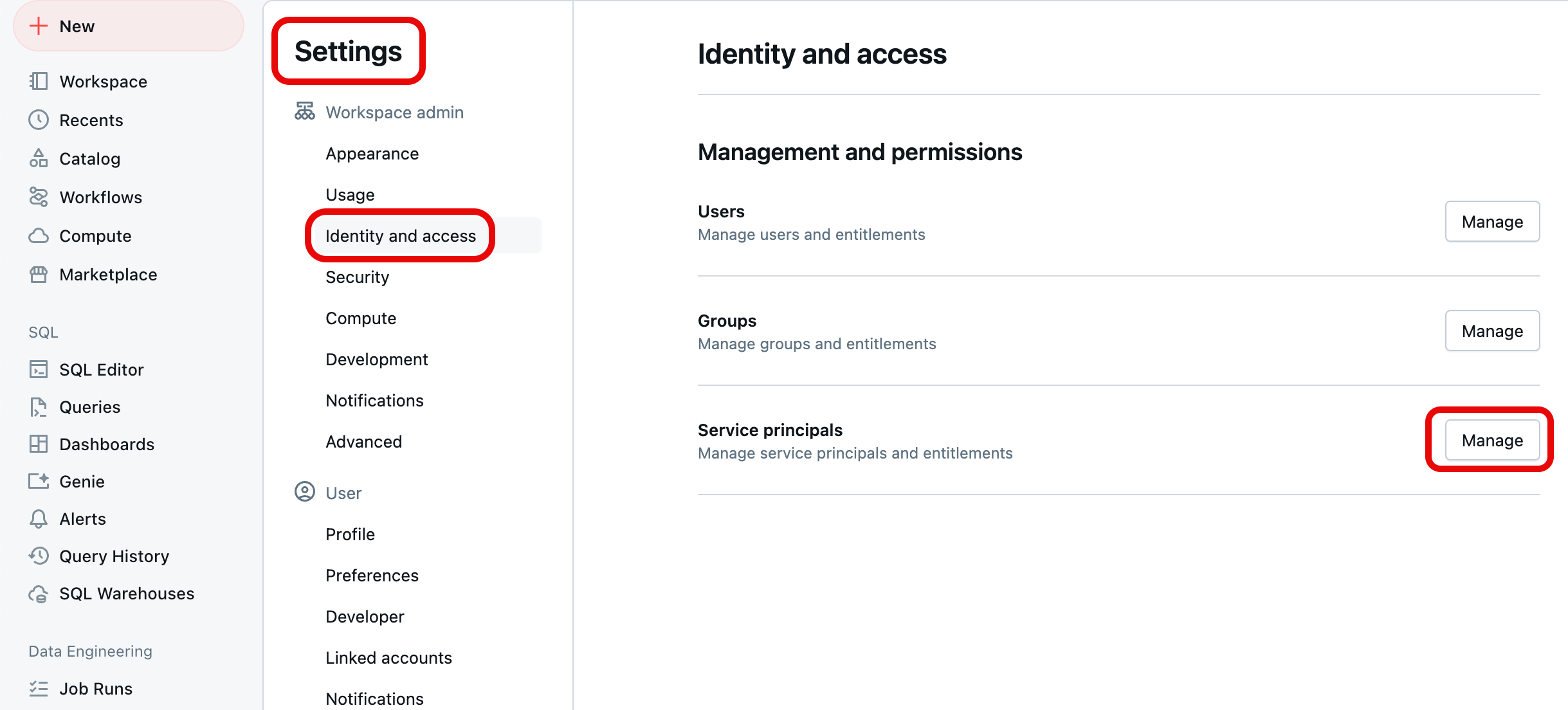
Connectez-vous à votre espace de travail Azure Databricks. Vous devez disposer de privilèges d’administrateur pour votre espace de travail pour effectuer ces étapes. Si vous n’avez pas de privilèges d’administrateur pour votre espace de travail, demandez-lui ou contactez l’administrateur de votre compte.
Dans le coin supérieur droit de n’importe quelle page, cliquez sur votre nom d’utilisateur, puis sélectionnez Paramètres.
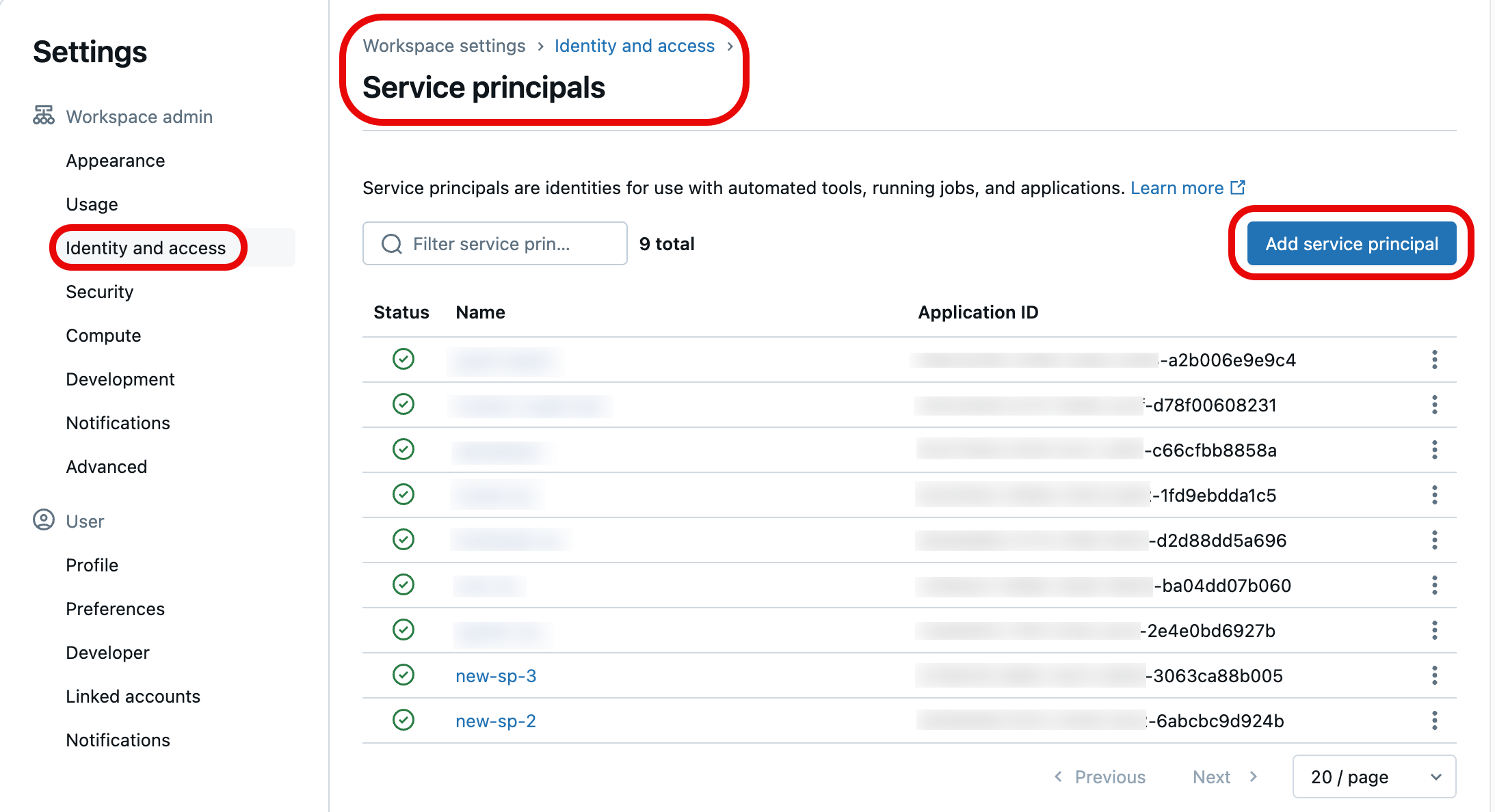
Sélectionnez Identité et accès sous l’administrateur de l’espace de travail dans le volet de navigation gauche, puis sélectionnez le bouton Gérer pour Principaux de service.
Dans la liste des principaux de service, sélectionnez celui que vous souhaitez mettre à jour avec les informations d’identification Git. Vous pouvez également créer un principal de service en sélectionnant Ajouter un principal de service.
Sélectionnez l’onglet Intégration Git. (Si vous n’avez pas créé le principal de service ou que vous n’avez pas reçu le privilège du gestionnaire de principal de service sur celui-ci, il sera grisé.) Sous celui-ci, choisissez le fournisseur Git pour les informations d’identification (telles que GitHub), sélectionnez Lier un compte Git, puis sélectionnez Lien.
Vous pouvez également utiliser un jeton d’accès personnel (PAT) Git si vous ne souhaitez pas lier vos propres informations d’identification Git. Pour utiliser un jeton d’accès personnel à la place, sélectionnez jeton d’accès personnel et fournissez les informations relatives au jeton pour le compte Git lors de l’authentification de l’accès du principal de service. Pour plus d’informations sur l’acquisition d’un PAT à partir d’un fournisseur Git, consultez Configurer les informations d’identification Git & Connecter un référentiel distant à Azure Databricks.
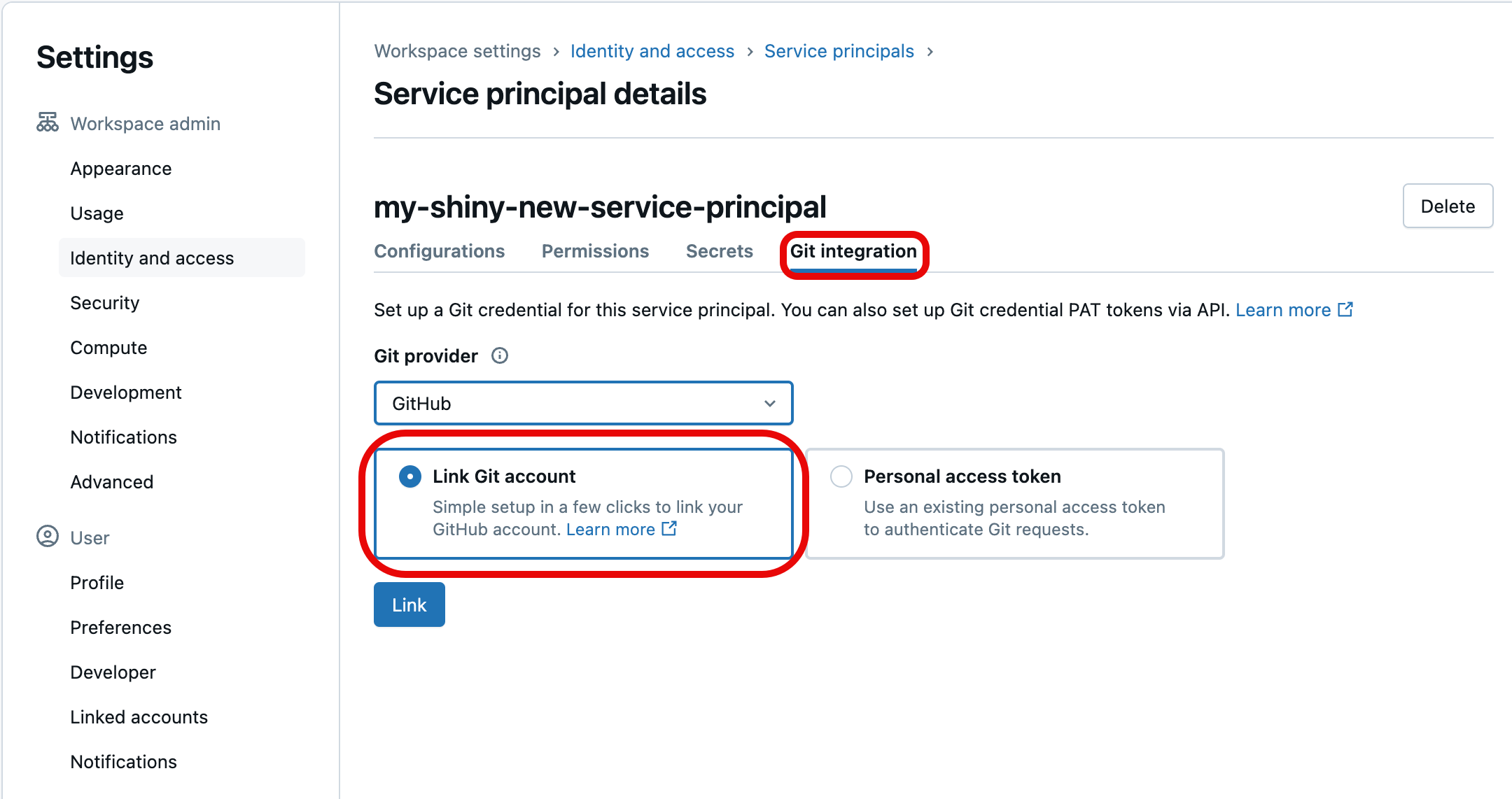
Vous serez invité à sélectionner le compte d’utilisateur Git à lier. Choisissez le compte d’utilisateur Git que le principal de service utilisera pour accéder et sélectionnez Continuer. (Si vous ne voyez pas le compte d’utilisateur que vous souhaitez utiliser, sélectionnez Utiliser un autre compte.)
Dans la boîte de dialogue suivante, sélectionnez Autoriser Databricks. Le message « Compte en cours de liaison… » apparaîtra brièvement suivi par les détails du compte de service mis à jour.
Écran de confirmation
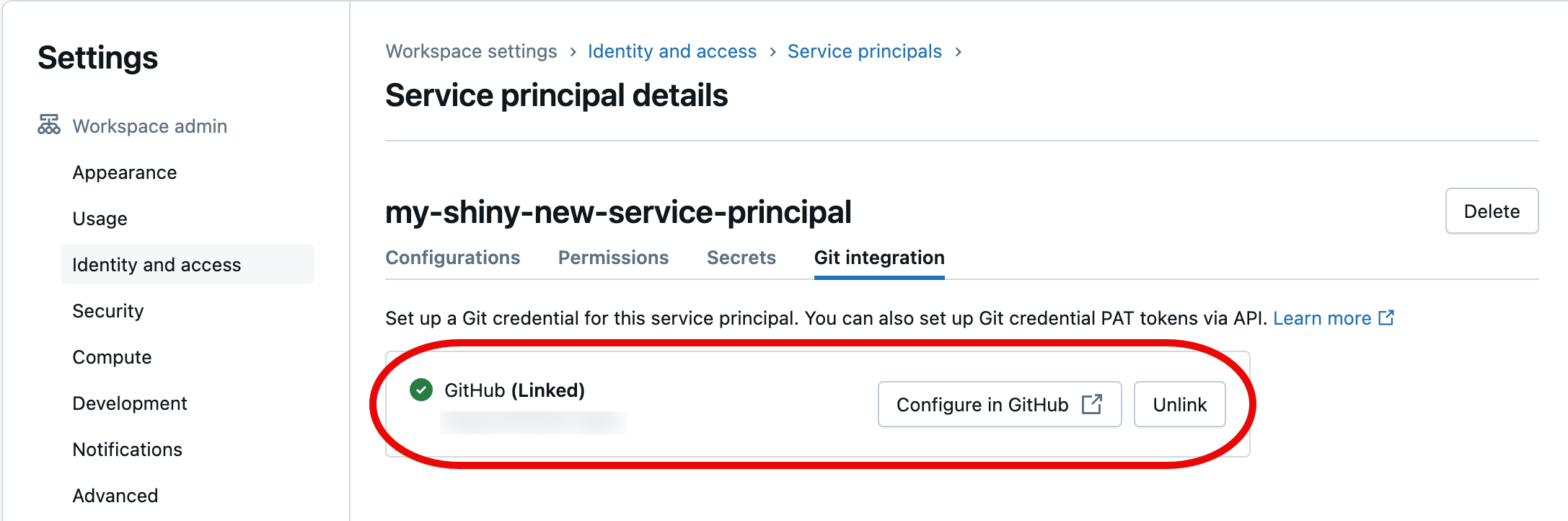
Le principal de service que vous avez choisi applique désormais les informations d’identification Git liées lors de l’accès à vos ressources de dossier Git de l’espace de travail Azure Databricks dans le cadre de votre automatisation.
Intégration de Terraform
Vous pouvez également gérer les dossiers Git Databricks dans une configuration entièrement automatisée à l’aide de Terraform et de databricks_repo :
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Pour utiliser Terraform afin d’ajouter des informations d’identification Git à un principal de service, ajoutez la configuration suivante :
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Configurer un pipeline CI/CD automatisé avec les dossiers Git Databricks
Voici une automatisation simple que vous pouvez exécuter en tant qu’action GitHub.
Spécifications
- Vous avez créé un dossier Git dans un espace de travail Databricks qui fait le suivi de la branche de base dans laquelle la fusion est effectuée.
- Vous disposez d’un package Python qui crée les artefacts à placer dans un emplacement DBFS. Votre code doit :
- Mettre à jour le dépôt associé à votre branche préférée (par exemple,
development) pour contenir les dernières versions de vos notebooks. - Générer tous les artefacts et les copier dans le chemin d’accès de la bibliothèque.
- Remplacer les dernières versions des artefacts de build pour éviter d’avoir à mettre à jour manuellement les versions d’artefact dans votre travail.
- Mettre à jour le dépôt associé à votre branche préférée (par exemple,
Créer un flux de travail CI/CD automatisé
Configurez des secrets pour que votre code puisse accéder à l’espace de travail Databricks. Ajoutez les secrets suivants au dépôt GitHub :
- DEPLOYMENT_TARGET_URL : définissez cette valeur sur l’URL de votre espace de travail. N’incluez pas la
/?osous-chaîne. - DEPLOYMENT_TARGET_TOKEN : définissez-le sur un jeton d’accès personnel Databricks (PAT). Vous pouvez générer un PAT Databricks en suivant les instructions de l’authentification par jeton d’accès personnel Azure Databricks.
- DEPLOYMENT_TARGET_URL : définissez cette valeur sur l’URL de votre espace de travail. N’incluez pas la
Accédez à l’onglet Actions de votre dépôt Git, puis cliquez sur le bouton Nouveau workflow. En haut de la page, sélectionnez Configurer un workflow vous-même et collez ce script :

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itMettez à jour les valeurs de variable d’environnement suivantes avec vos propres valeurs :
- DBFS_LIB_PATH : chemin d’accès dans DBFS aux bibliothèques (wheels) que vous utiliserez dans cette automatisation. Commence par
dbfs:. Par exemple :dbfs:/mnt/myproject/libraries. - REPO_PATH : chemin d’accès dans votre espace de travail Databricks au dossier Git où les notebooks seront mis à jour.
- LATEST_WHEEL_NAME : nom du dernier fichier de roue Python compilé (
.whl). Cela permet d’éviter de mettre à jour manuellement les versions de wheel dans vos travaux Databricks. Par exemple :your_wheel-latest-py3-none-any.whl.
- DBFS_LIB_PATH : chemin d’accès dans DBFS aux bibliothèques (wheels) que vous utiliserez dans cette automatisation. Commence par
Sélectionnez Commiter les modifications... pour commiter le script en tant que workflow GitHub Actions. Une fois que la demande de tirage (pull request) pour ce workflow est fusionnée, accédez à l’onglet Actions du dépôt Git et vérifiez que les actions ont réussi.