Fichier binaire
Databricks Runtime prend en charge les fichiers binaires et convertit chacun d’eux en un enregistrement unique qui contient le contenu brut et les métadonnées du fichier. La source de données de fichier binaire produit un DataFrame avec les colonnes suivantes et éventuellement des colonnes de partition :
path (StringType): Chemin d'accès au fichier.modificationTime (TimestampType): Heure de dernière modification de l'événement. Dans certaines implémentations Hadoop FileSystem, ce paramètre peut ne pas être disponible et la valeur est définie sur une valeur par défaut.length (LongType): Longueur du fichier en octets.content (BinaryType): Contenu du fichier.
Pour lire les fichiers binaires, spécifiez format pour le binaryFile de la source de données.
Images
Databricks recommande d’utiliser la source de données de fichier binaire pour charger des données d’image.
La fonction Databricks display prend en charge l’affichage des données d’image chargées à l’aide de la source de données binaire.
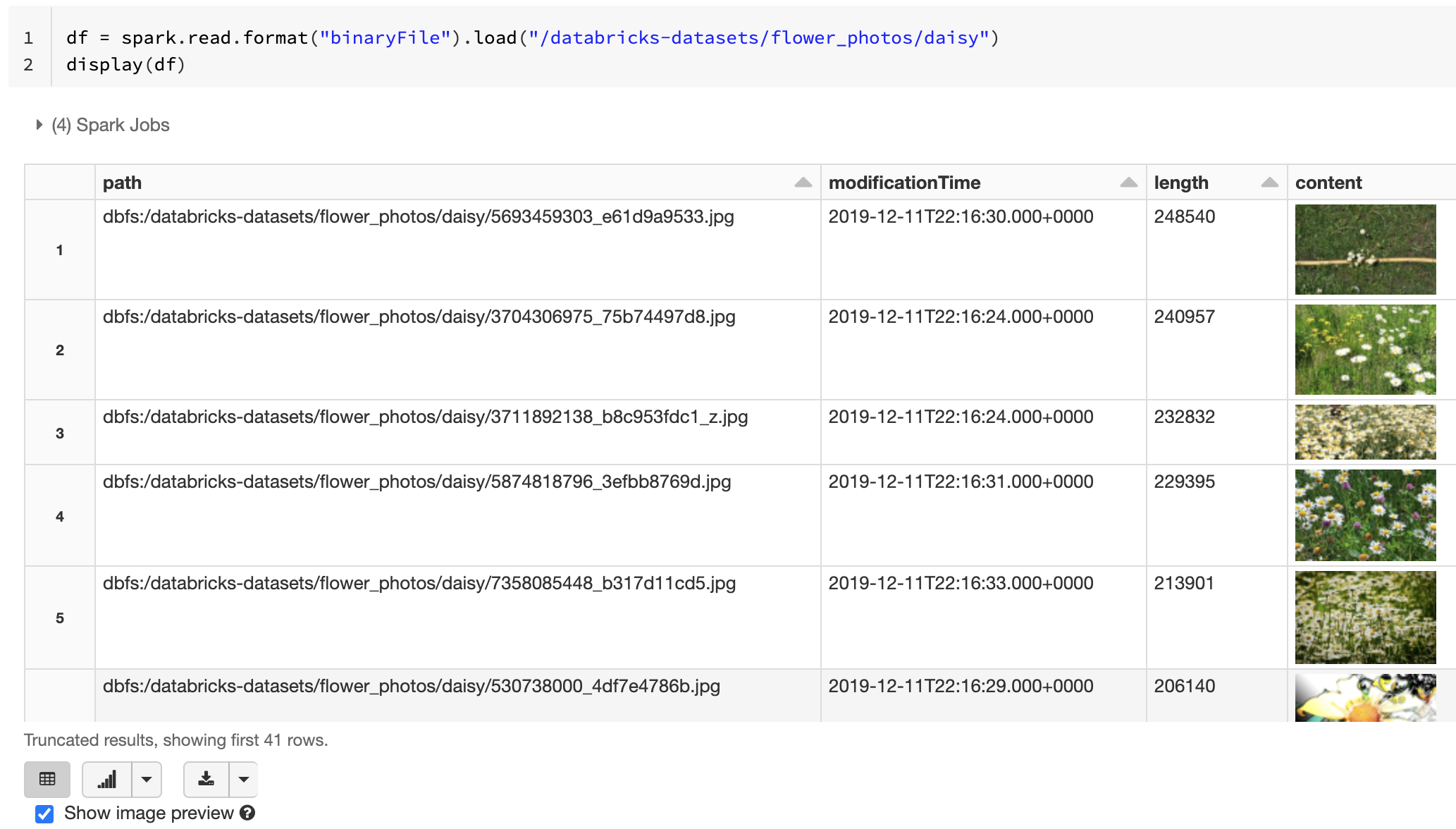
Si tous les fichiers chargés ont un nom de fichier avec une extension d’image, l’aperçu d’image est automatiquement activé :
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
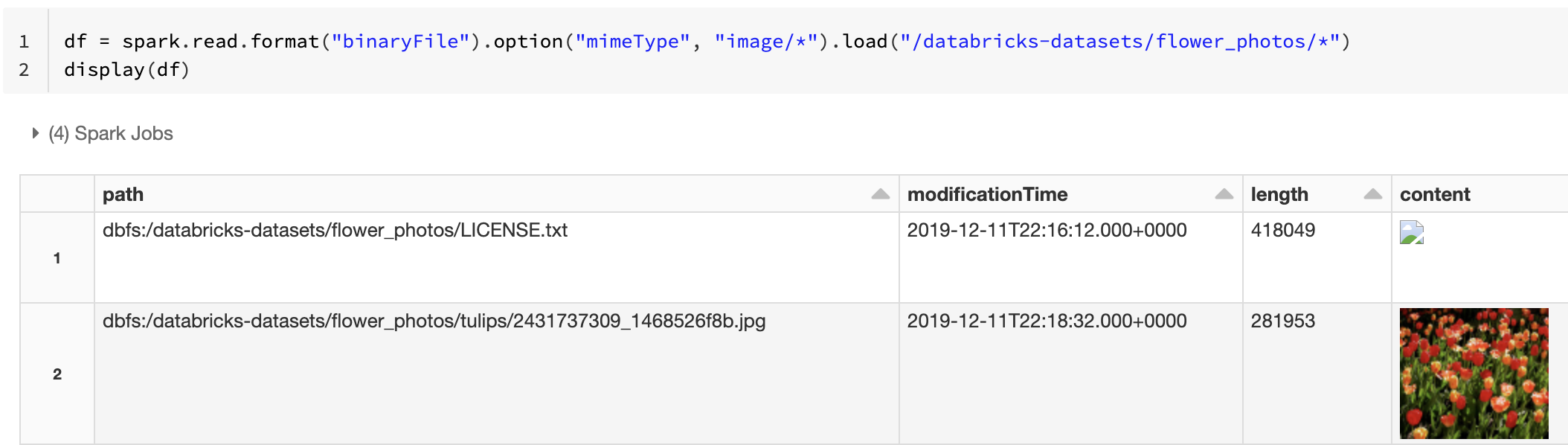
Vous pouvez également forcer la fonctionnalité d’aperçu de l’image en utilisant l’option mimeType avec une valeur de chaîne "image/*" pour annoter la colonne binaire. Les images sont décodées en fonction de leurs informations de format dans le contenu binaire. Les types d’images pris en charge sont bmp, gif, jpeg et png. Les fichiers non pris en charge apparaissent sous la forme d’une icône d’image cassée.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Pour plus d’informations sur le flux de travail recommandé pour traiter les données d’image, consultez Solution de référence pour les applications image.
Options
Pour charger des fichiers avec des chemins d’accès correspondant à un modèle Glob donné tout en conservant le comportement de la découverte de partition, vous pouvez utiliser l’option pathGlobFilter. Le code suivant lit tous les fichiers JPG du répertoire d’entrée avec la découverte de partition :
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Si vous souhaitez ignorer la détection de partition et rechercher des fichiers de manière récursive dans le répertoire d’entrée, utilisez l’option recursiveFileLookup. Cette option effectue une recherche dans les répertoires imbriqués même si leurs noms ne suivent pas un schéma d’affectation de noms de partition comme date=2019-07-01.
Le code suivant lit tous les fichiers JPG de manière récursive à partir du répertoire d’entrée et ignore la détection de la partition :
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Des API similaires existent pour Scala, Java et R.
Remarque
Pour améliorer le niveau de performance de lecture lors du chargement des données, Azure Databricks recommande d’enregistrer les données chargées à partir de fichiers binaires à l’aide de tables Delta :
df.write.save("<path-to-table>")