Espaces entre les travaux Spark
Vous observez la présences d’espaces dans la chronologie de vos travaux, comme suit :
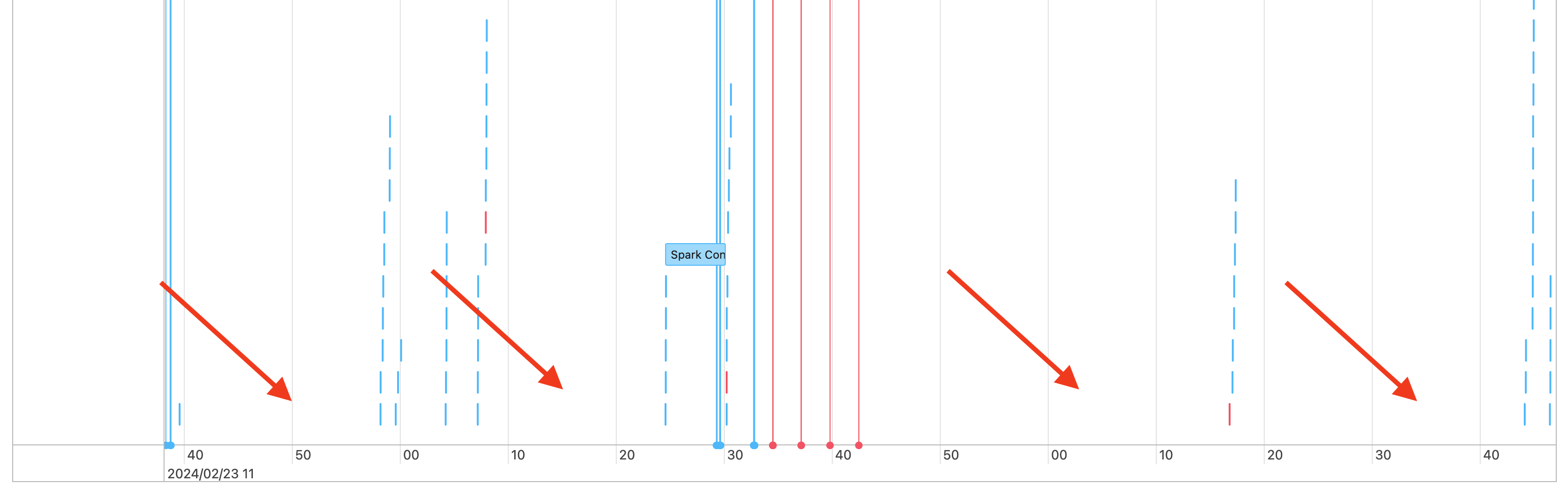
Il peut y avoir diverses raisons à cela. Si les espaces constituent une proportion élevée du temps consacré à votre charge de travail, vous devez déterminer ce qui provoque ces espaces et s’ils sont attendus ou non. Il y a plusieurs choses qui peuvent se produire pendant les espaces :
- Il n’y a pas de travail à exécuter
- Le pilote compile un plan d’exécution complexe
- Exécution de code non-spark
- Le pilote est surchargé
- Le cluster ne fonctionne pas correctement
Aucun travail
Sur le calcul à usage général, l’absence de travail à faire est l’explication la plus probable de la présence des espaces. Étant donné que le cluster est en cours d’exécution et que les utilisateurs envoient des requêtes, les espaces sont attendus. Ces espaces correspondent au temps qui s’écoule entre les soumissions de requêtes.
Plan d’exécution complexe
Par exemple, si vous utilisez withColumn() dans une boucle, cela crée un plan dont le traitement est très coûteux. Les espaces peuvent correspondre au temps consacré par le pilote à simplement créer et traiter le plan. Si c’est le cas, essayez de simplifier le code. Utilisez selectExpr() pour combiner plusieurs appels withColumn() en une expression unique, ou convertissez le code en SQL. Vous pouvez toujours incorporer le code SQL dans votre code Python, en utilisant Python pour manipuler la requête avec des fonctions de chaîne. Cela résout souvent ce type de problème.
Exécution de code non-Spark
Le code Spark est écrit en SQL ou à l’aide d’une API Spark comme PySpark. Toute exécution de code qui n’est pas Spark apparaît dans la chronologie sous forme d’espace. Par exemple, vous pouvez avoir une boucle en Python qui appelle des fonctions Python natives. Ce code ne s’exécute pas dans Spark, et peut apparaître sous forme d’espace dans la chronologie. Si vous ne savez pas si votre code exécute Spark, essayez de l’exécuter de manière interactive dans un notebook. Si le code utilise Spark, vous verrez des travaux Spark sous la cellule :

Vous pouvez également développer la liste déroulante Spark Jobs sous la cellule pour voir si les travaux s’exécutent activement (dans le cas où Spark serait désormais inactif). Si vous n’utilisez pas Spark, vous ne verrez pas Spark Jobs sous la cellule, ou vous constaterez qu’aucun travail n’est actif. Si vous ne pouvez pas exécuter le code de manière interactive, vous pouvez essayer de vous connecter à votre code et de faire correspondre les espaces avec les sections de votre code par horodatage, mais cela peut être difficile.
Si vous observez des espaces dans votre chronologie causés par l’exécution de code non-Spark, cela signifie que vos Workers sont tous inactifs, avec comme conséquence probable un gaspillage d’argent pendant les espaces. Peut-être est-ce intentionnel et inévitable, mais si vous pouvez écrire ce code de façon à utiliser Spark, vous utilisez entièrement le cluster. Commencez par ce tutoriel pour apprendre à utiliser Spark.
Le pilote est surchargé
Pour déterminer si votre pilote est surchargé, vous devez examiner les métriques du cluster.
Si votre cluster est sur DBR 13.0 ou version ultérieure, cliquez sur Metrics comme indiqué dans cette capture d’écran :
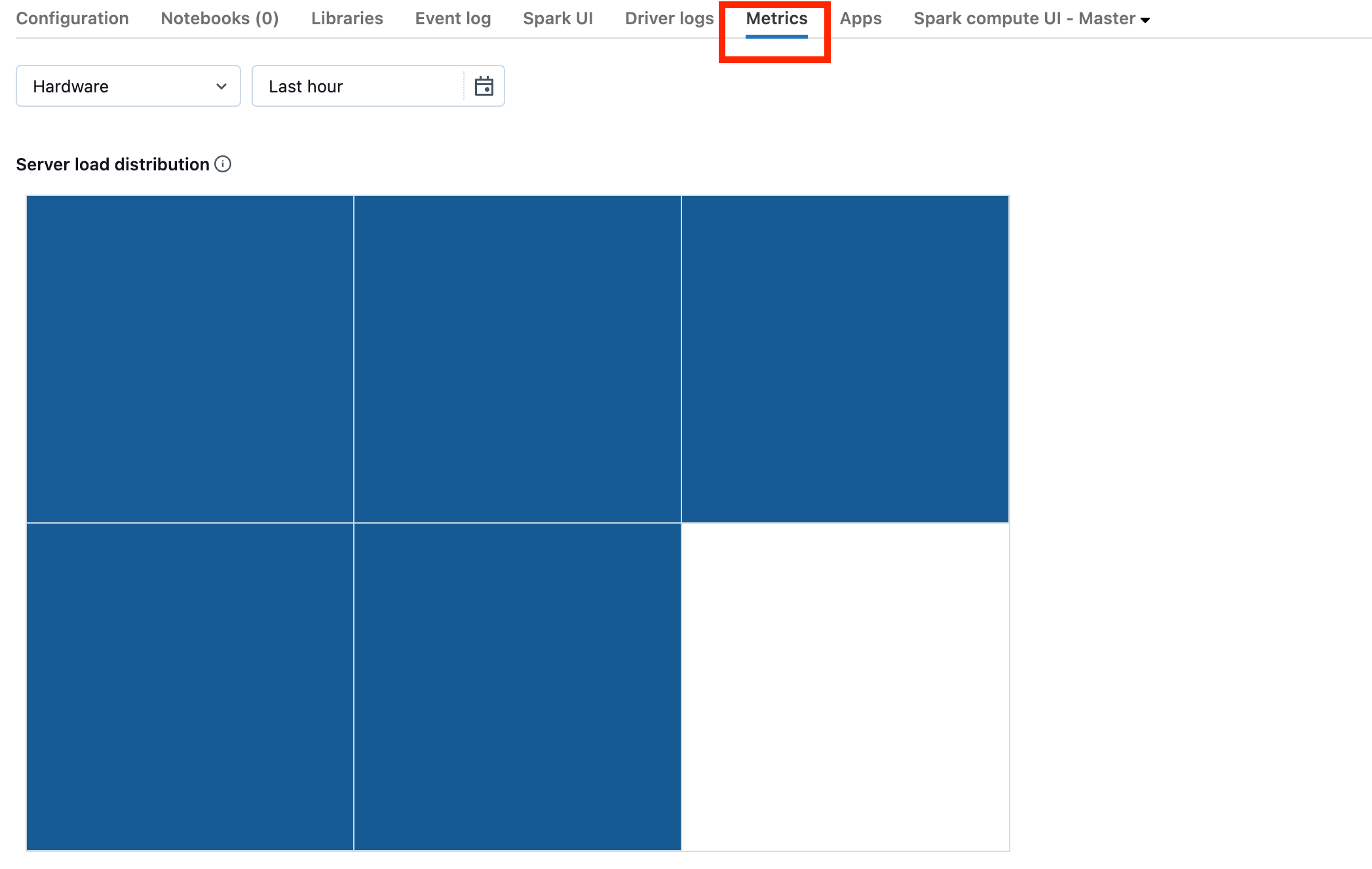
Notez la visualisation de distribution de charge du serveur. Vous devez vérifier si le pilote est fortement chargé. Cette visualisation présente un bloc de couleur pour chaque machine du cluster. Rouge signifie fortement chargé, et bleu signifie pas du tout chargé.
La capture d’écran précédente montre un cluster globalement inactif. Si le pilote était surchargé, la visualisation se présenterait comme suit :
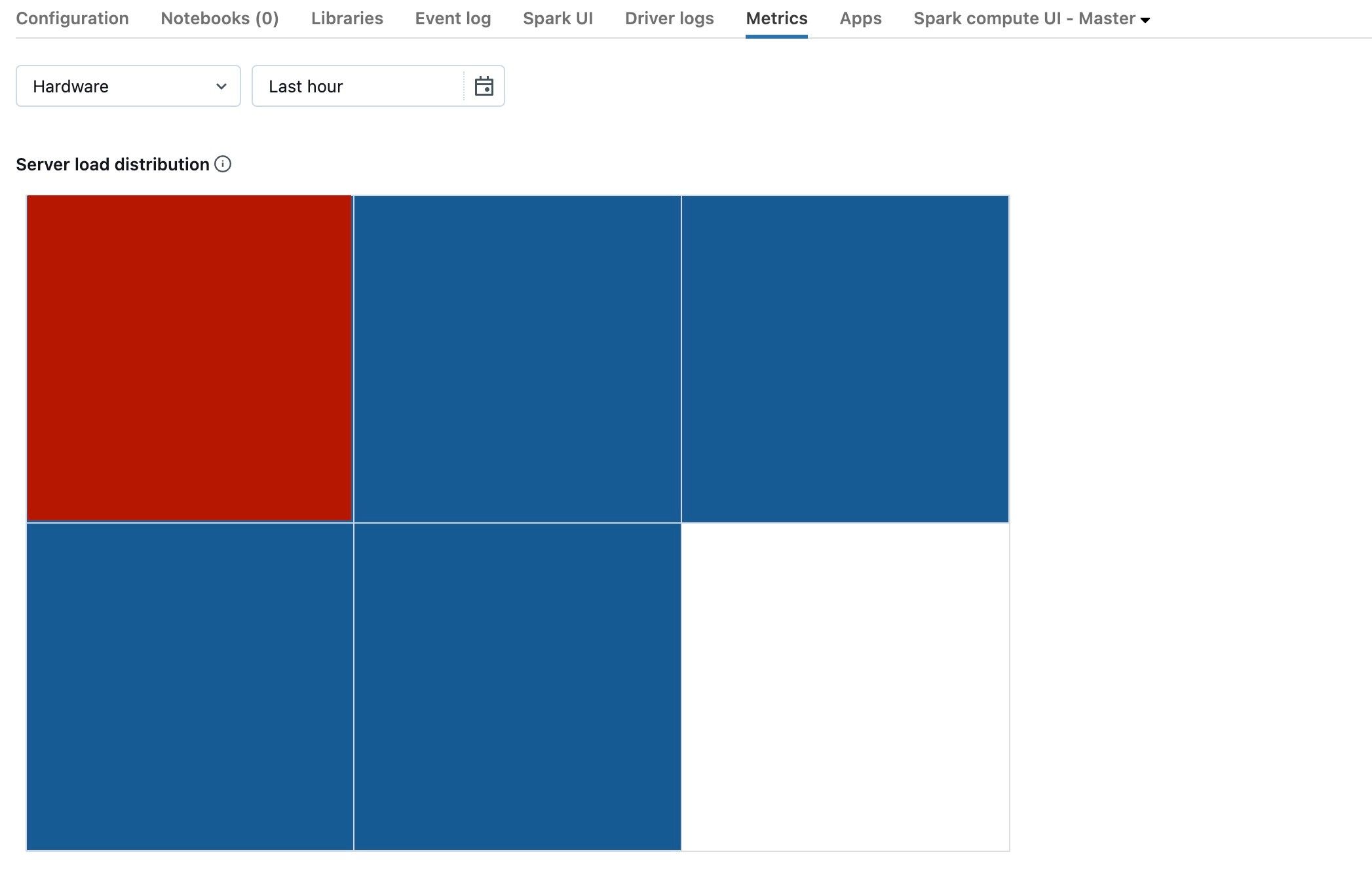
Nous pouvons observer qu’un carré est rouge, tandis que les autres sont bleus. Placez votre souris sur le carré rouge pour vous assurer que le bloc rouge représente votre pilote.
Pour corriger un pilote surchargé, consultez Pilote Spark surchargé.
Le cluster ne fonctionne pas correctement
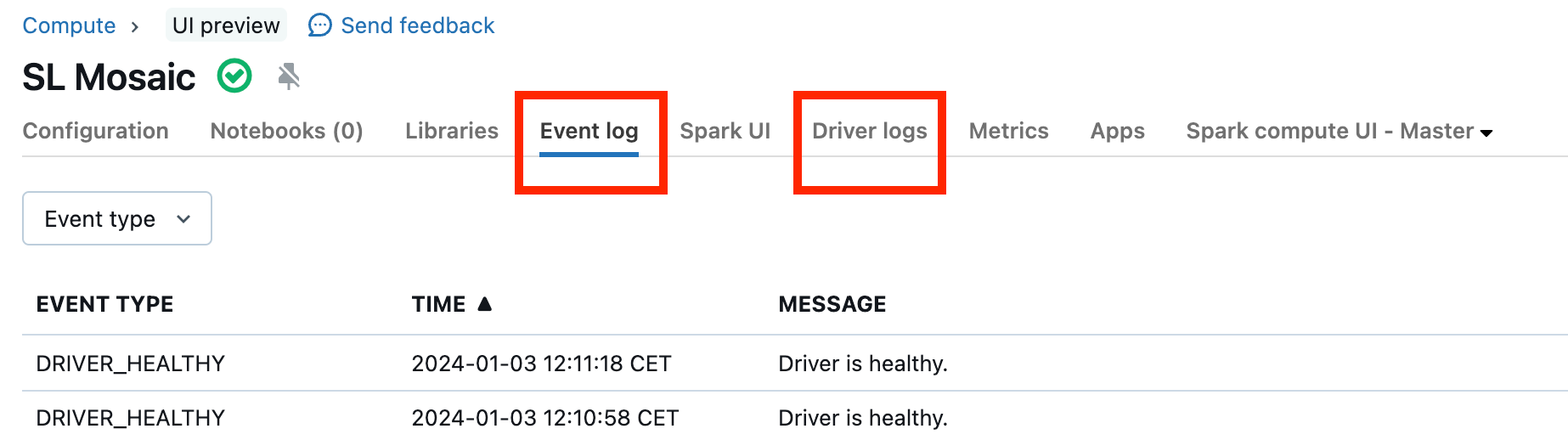
Les dysfonctionnements de cluster sont rares, mais si c’est le cas, il peut être difficile de déterminer ce qui s’est produit. Vous pouvez simplement redémarrer le cluster pour voir si cela résout le problème. Vous pouvez également examiner les journaux pour voir s’il y a quelque chose de suspect. Les onglets Event log et Driver logs, mis en surbrillance dans la capture d’écran ci-dessous, sont les endroits à consulter :
Vous pouvez activer la remise des journaux de calcul pour accéder aux journaux des Workers. Vous pouvez également modifier le niveau de journal, mais vous devrez peut-être contacter votre équipe de compte Databricks pour obtenir de l’aide.