Phase Spark lente avec peu d’E/S
Si vous avez une phase lente avec peu d’E/S, la cause peut être l’une des suivantes :
- Lecture de nombreux petits fichiers
- Écriture de nombreux petits fichiers
- Lenteur des fonctions définies par l’utilisateur
- join Cartésien
- Explosion join
Presque tous ces problèmes peuvent être identifiés à l’aide du DAG SQL.
Ouvrir le DAG SQL
Pour ouvrir le DAG SQL, faites défiler jusqu’en haut de la page du travail, puis cliquez sur Associated SQL Query :

Vous devez maintenant voir le DAG. Si ce n’est pas le cas, faites défiler un peu et vous devriez le voir :
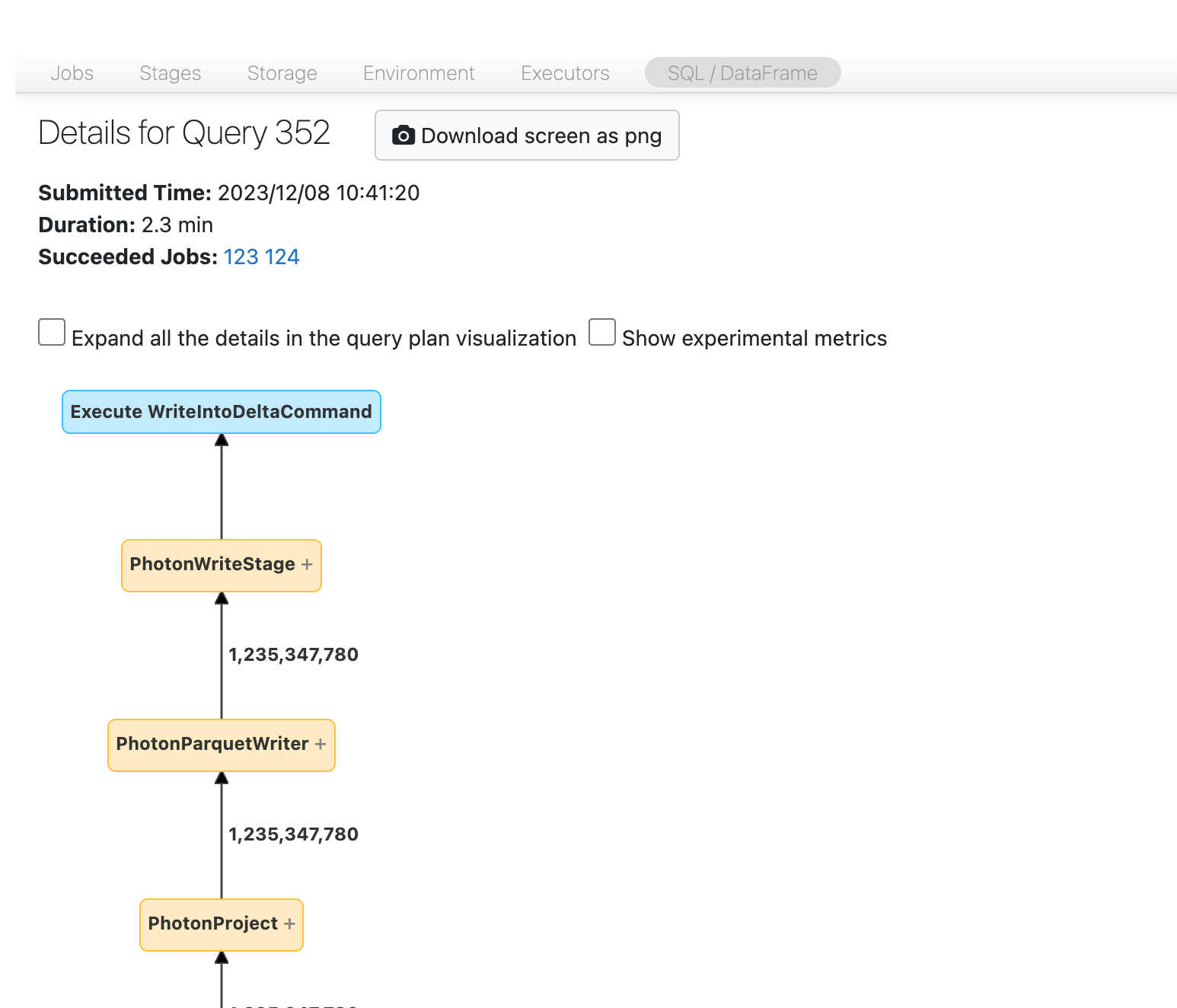
Avant de continuer, familiarisez-vous un peu avec le graphe orienté acyclique (DAG) et examinez where est consacré le temps. Certains nœuds du DAG ont des informations utiles sur le temps et d’autres ne le font pas. Par exemple, ce bloc a pris 2,1 minutes et fournit même l’ID d’étape :

Ce nœud vous oblige à l’ouvrir pour voir qu’il a fallu 1,4 minutes :
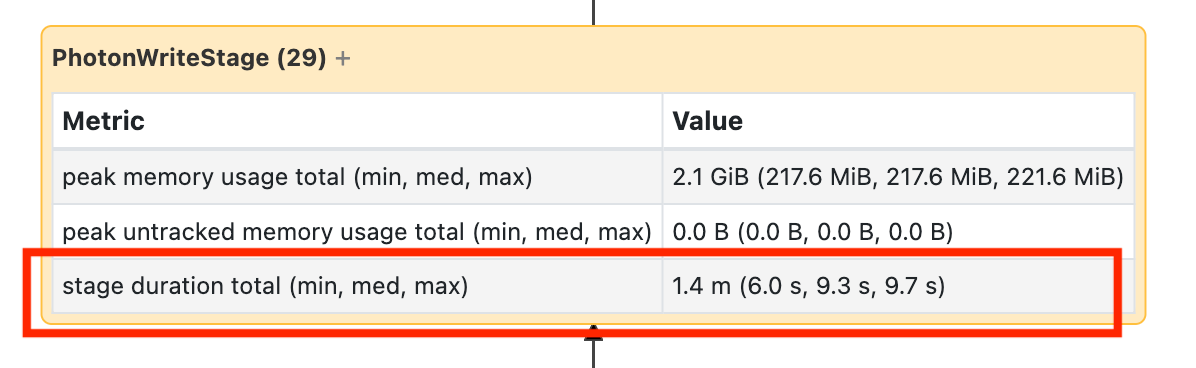
Ces heures sont cumulatives. Il s’agit donc du temps total consacré à toutes les tâches, et non à l’heure d’horloge. Mais ces temps sont tout de même très utiles, car ils sont corrélés avec l’heure d’horloge et avec le coût.
Il est utile de vous familiariser avec where dans le DAG, où le temps est utilisé.
Lecture de nombreux petits fichiers
Si l’un de vos opérateurs d’analyse prend beaucoup de temps, ouvrez-le et recherchez le nombre de fichiers lus :
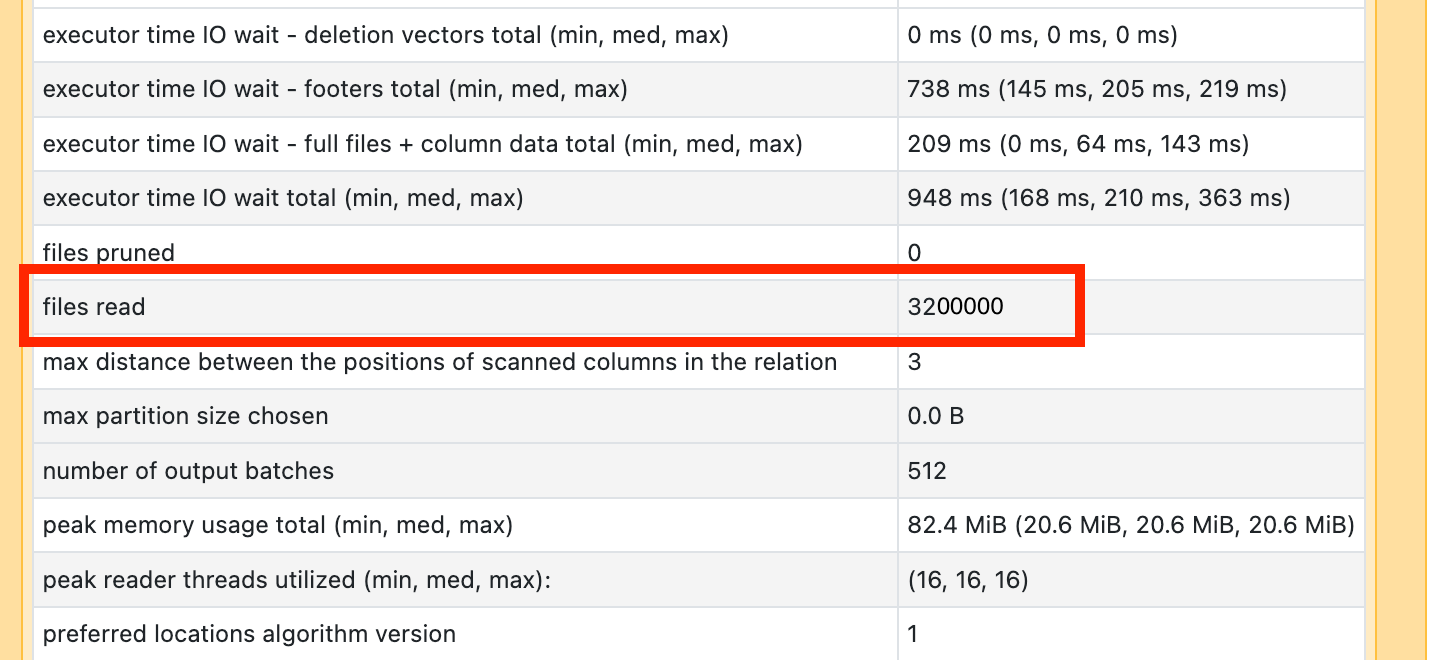
Si vous lisez des dizaines de milliers de fichiers ou plus, vous risquez d’avoir un petit problème de fichier. Vos fichiers ne doivent pas être inférieurs à 8 Mo. Le problème de petit fichier est le plus souvent dû au partitionnement avec trop de columns ou à une cardinalité élevée de column.
Si vous avez de la chance, il vous suffira d’exécuter OPTIMIZE Quoi qu’il en soit, vous devez reconsidérer votre disposition de fichier .
Écriture de nombreux petits fichiers
Si votre écriture prend beaucoup de temps, ouvrez-la et recherchez le nombre de fichiers et la quantité de données écrites :
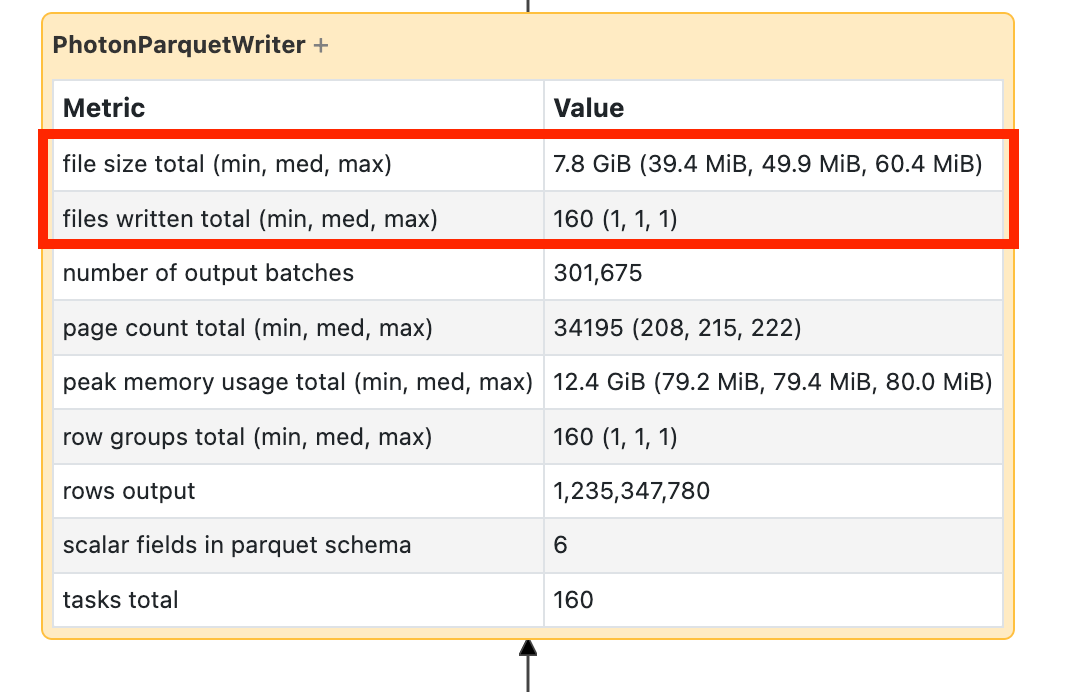
Si vous écrivez des dizaines de milliers de fichiers ou plus, vous risquez d’avoir un petit problème de fichier. Vos fichiers ne doivent pas être inférieurs à 8 Mo. Le problème de petit fichier est le plus souvent dû au partitionnement avec trop de columns ou à une cardinalité élevée de column. Vous devez reconsidérer la disposition de vos fichiers ou activer les écritures optimisées.
Lenteur des fonctions définies par l’utilisateur
Si vous savez que vous avez des fonctions définies par l’utilisateur ou que vous observez quelque chose qui s’y apparente dans votre DAG, votre problème provient peut-être de la lenteur des fonctions définies par l’utilisateur :
Si vous pensez souffrir de ce problème, essayez de commenter votre fonction définie par l’utilisateur pour voir comment cela affecte la vitesse de votre pipeline. Si l’UDF est effectivement where et consomme du temps, il est préférable de réécrire l’UDF en utilisant des fonctions natives. Si cela n’est pas possible, réfléchissez au nombre de tâches de la phase exécutant votre fonction définie par l’utilisateur. Si le nombre de tâches est inférieur au nombre de cœurs de votre cluster, repartition() votre DataFrame avant d’utiliser la fonction définie par l’utilisateur :
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
Les fonctions définies par l’utilisateur peuvent également souffrir de problèmes de mémoire. Considérez que chaque tâche peut avoir à charger toutes les données dans son partition en mémoire. Si ces données sont trop volumineuses, les choses peuvent get très lentes ou instables. La repartition peut également résoudre ce problème en réduisant la taille de chaque tâche.
join Cartésien
Si vous voyez un join cartésien ou une boucle imbriquée join dans votre DAG, vous devez savoir que ces jointures sont très coûteuses. Assurez-vous que c’est ce que vous avez prévu et voyez s’il y a une autre façon.
Jointure join ou explode
Si vous constatez que quelques lignes vont dans un nœud et qu’il en sort énormément plus, votre problème est peut-être lié à une join explosive ou explode() :
 Explosif
Explosif
Pour en savoir plus sur les explosions, consultez le guide d'optimisation Databricks .