Gérer le code d’entraînement avec les exécutions MLflow
Cet article décrit les exécutions MLflow pour gérer la formation Machine Learning. Il comprend également des conseils sur la façon de gérer et de comparer les exécutions entre les expériences.
Une exécution MLflow correspond à une seule exécution de code de modèle. Chaque enregistrement d'exécution enregistre les informations suivantes :
- Source: nom du bloc-notes qui a lancé l’exécution ou le nom du projet et le point d’entrée pour l’exécution.
- Version : hachage de validation Git si le notebook est stocké dans un dossier Git Databricks ou exécuté à partir d’un projet MLflow. Sinon, révision du notebook.
- Heures de début et de fin : heures de début et de fin de l’exécution.
- Paramètres: paramètres de modèle enregistrés en tant que paires clé-valeur. Les clés et les valeurs sont des chaînes.
- Métriques: métriques d’évaluation de modèle enregistrées sous forme de paires clé-valeur. La valeur est numérique. Chaque mesure peut être mise à jour tout au long de l’exécution (par exemple, pour suivre le mode de convergence de la fonction de perte de votre modèle) et les enregistrements MLflow et vous permet de visualiser l’historique de la métrique.
- Tags: exécute les métadonnées enregistrées en tant que paires clé-valeur. Vous pouvez mettre à jour les balises pendant et après la fin d’une exécution. Les clés et les valeurs sont des chaînes.
- Artifacts: fichiers de sortie dans n’importe quel format. Par exemple, vous pouvez enregistrer des images, des modèles (par exemple, un modèle Pickle scikit-Learn) et des fichiers de données (par exemple, un fichier parquet) en tant qu’artefact.
Toutes les exécutions de MLflow sont enregistrées dans l'expérience active. Si vous n’avez pas explicitement défini une expérience comme expérience active, les exécutions sont consignées dans l’expérience du Notebook.
Afficher les exécutions
Vous pouvez accéder à une exécution à partir de sa page d’expérience parente ou directement à partir du bloc-notes qui a créé l’exécution.
Dans la page expérimentation, dans le tableau exécutions, cliquez sur l’heure de début d’une exécution.
Dans le notebook, cliquez sur ![]() à côté de la date et de l’heure de l’exécution dans la barre latérale Exécutions d’expérience.
à côté de la date et de l’heure de l’exécution dans la barre latérale Exécutions d’expérience.
L'écran d’exécution affiche les paramètres utilisés pour l’exécution, les métriques résultant de l’exécution, ainsi que toutes les balises et les notes. Pour afficher les Notes, les Paramètres, les Métriques ou les Balises de cette exécution, cliquez sur ![]() à gauche de l’étiquette.
à gauche de l’étiquette.
Vous accédez également aux artefacts enregistrés à partir d’une exécution dans cet écran.
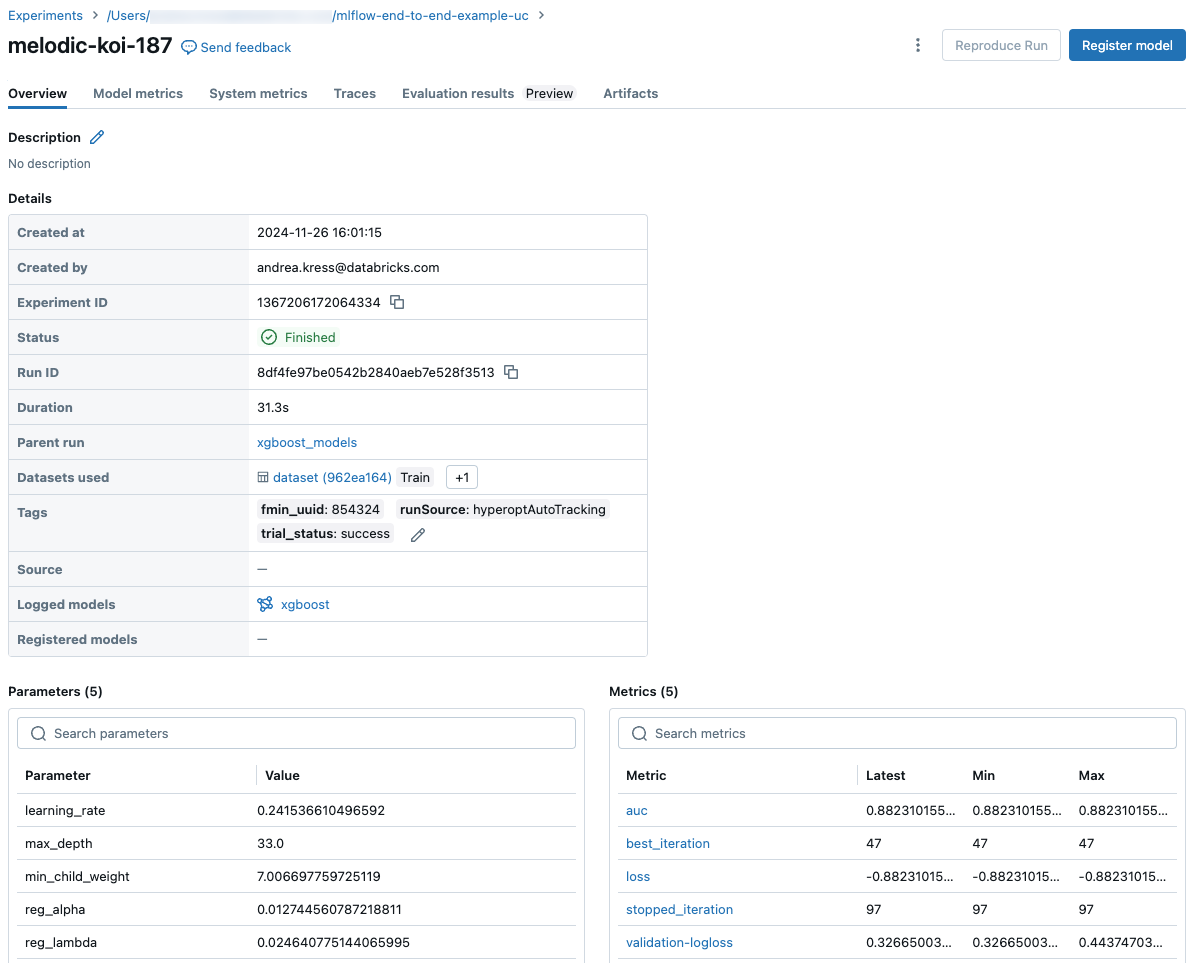
Extraits de code pour la prédiction
Si vous enregistrez un modèle depuis une exécution, le modèle apparaît dans la section Artefacts de cette page. Pour afficher des extraits de code illustrant la façon de charger et d’utiliser le modèle pour faire des prédictions sur Spark et pandas trames, cliquez sur le nom du modèle.
Afficher le bloc-notes ou le projet Git utilisé pour une exécution
Pour afficher la version du bloc-notes qui a créé une exécution :
- Dans la page expérience, cliquez sur le lien dans la colonne source.
- Sur la page exécuter, cliquez sur le lien en regard de source.
- Dans le notebook, dans la barre latérale Exécutions d’expérience, cliquez sur l’icône Notebook
 dans la zone correspondant à cette exécution d’expérience.
dans la zone correspondant à cette exécution d’expérience.
La version du bloc-notes associée à l’exécution s’affiche dans la fenêtre principale avec une barre de surbrillance montrant la date et l’heure de l’exécution.
Si l’exécution a été lancée à distance à partir d’un projet git, cliquez sur le lien dans le champ validation git pour ouvrir la version spécifique du projet utilisé dans l’exécution. Le lien dans le champ source ouvre la branche principale du projet git utilisé dans l’exécution.
Ajouter une étiquette à une exécution
Les étiquettes sont des paires clé-valeur que vous pouvez créer et utiliser ultérieurement pour rechercher des exécutions.
Dans la page de l’exécution, cliquez sur
 si l’élément n’est pas déjà ouvert. Le tableau Étiquettes s’affiche.
si l’élément n’est pas déjà ouvert. Le tableau Étiquettes s’affiche.
Cliquez dans les champs Nom et Valeur, puis entrez la clé et la valeur de votre étiquette.
Cliquez sur Add.
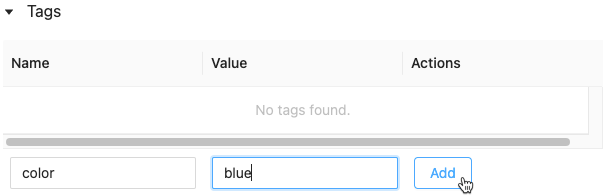
Modifier ou supprimer une balise pour une exécution
Pour modifier ou supprimer une étiquette existante, utilisez les icônes de la colonne Actions.

Reproduire l’environnement logiciel d’une exécution
Vous pouvez reproduire l’environnement logiciel exact pour l’exécution en cliquant sur reproduire l’exécution. La boîte de dialogue suivante s’affiche :
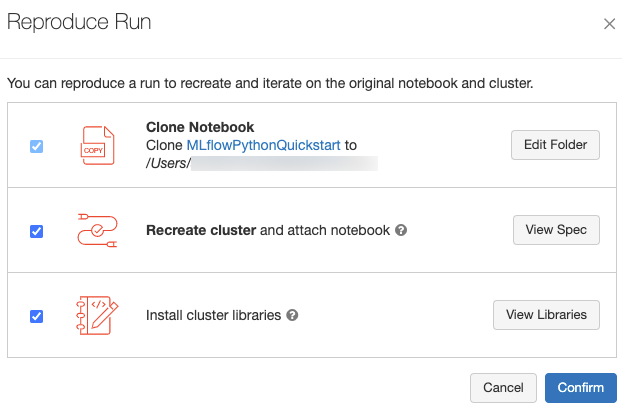
Avec les paramètres par défaut, lorsque vous cliquez sur confirmer:
- Le bloc-notes est cloné à l’emplacement indiqué dans la boîte de dialogue.
- Si le cluster d’origine existe toujours, le bloc-notes cloné est attaché au cluster d’origine et le cluster est démarré.
- Si le cluster d’origine n’existe plus, un nouveau cluster avec la même configuration, y compris les bibliothèques installées, est créé et démarré. Le bloc-notes est attaché au nouveau cluster.
Vous pouvez sélectionner un autre emplacement pour le bloc-notes cloné et inspecter la configuration du cluster et les bibliothèques installées :
- Pour sélectionner un autre dossier pour enregistrer le bloc-notes cloné, cliquez sur modifier le dossier.
- Pour afficher la spécification du cluster, cliquez sur afficher la spécification. Pour cloner uniquement le bloc-notes et non le cluster, désactivez cette option.
- Pour afficher les bibliothèques installées sur le cluster d’origine, cliquez sur afficher les bibliothèques. Si vous ne vous souciez pas d’installer les mêmes bibliothèques que sur le cluster d’origine, décochez cette option.
Gérer les exécutions
Renommer l’exécution
Pour renommer une exécution, cliquez sur ![]() dans le coin supérieur droit de la page de l’exécution, puis sélectionnez Renommer.
dans le coin supérieur droit de la page de l’exécution, puis sélectionnez Renommer.
Séries de filtres
Vous pouvez rechercher des exécutions en fonction de valeurs de paramètre ou de métrique. Vous pouvez également rechercher des exécutions par balise.
Pour rechercher des exécutions qui correspondent à une expression contenant des valeurs de paramètres et de métriques, entrez une requête dans le champ de recherche, puis cliquez sur Rechercher. Voici quelques exemples de syntaxe de requête :
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Par défaut, les valeurs de métrique sont filtrées en fonction de la dernière valeur journalisée. À l’aide de
MINouMAX, vous pouvez rechercher des exécutions en fonction des valeurs de métrique minimales ou maximales, respectivement. Seules les exécutions enregistrées après août 2024 ont des valeurs de métrique minimales et maximales.Pour rechercher des exécutions par balise, entrez des balises au format :
tags.<key>="<value>". Les valeurs de chaîne doivent être placées entre guillemets, comme indiqué.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Les clés et les valeurs peuvent contenir des espaces. Si la clé contient des espaces, vous devez la placer entre les battements comme indiqué.
tags.`my custom tag` = "my value"
Vous pouvez également filtrer les exécutions en fonction de leur état (actif ou supprimé) et selon qu’une version de modèle est associée ou non à l’exécution. Pour ce faire, effectuez vos sélections respectivement dans les menus déroulants État et Heure de création.
Exécutions de téléchargement
Sélectionnez une ou plusieurs exécutions.
Cliquez sur Télécharger CSV. Un fichier CSV contenant les champs suivants est téléchargé :
Run ID,Name,Source Type,Source Name,User,Status,<parameter1>,<parameter2>,...,<metric1>,<metric2>,...
Supprimer les exécutions
Pour supprimer des exécutions à l’aide de l’interface utilisateur Databricks Mosaic AI, effectuez les étapes suivantes :
- Dans l'expérience, sélectionnez une ou plusieurs exécutions en cliquant dans la case à cocher à gauche de l’exécution.
- Cliquez sur Supprimer.
- Si la série de tests est une exécution parente, déterminez si vous souhaitez également supprimer les exécutions descendantes. Cette option est sélectionnée par défaut.
- Cliquez sur Delete (Supprimer) pour confirmer. Les exécutions supprimées sont enregistrées pendant 30 jours. Pour afficher les exécutions supprimées, sélectionnez supprimé dans le champ État.
Exécutions de suppression en bloc basées sur l’heure de création
Vous pouvez utiliser Python pour supprimer en bloc les exécutions d’une expérience créées avant un horodatage UNIX ou au moment défini par celui-ci.
À l’aide de Databricks Runtime 14.1 ou d’une version ultérieure, vous pouvez appeler l’API mlflow.delete_runs pour supprimer les exécutions et retourner le nombre d’exécutions supprimées.
Voici les paramètres de mlflow.delete_runs :
experiment_id: ID de l’expérience contenant les exécutions à supprimer.max_timestamp_millis: horodatage de création maximal en millisecondes depuis l’époque UNIX pour la suppression des exécutions. Seules les exécutions créées avant ou au moment de cet horodatage sont supprimées.max_runs: Facultatif. Entier positif qui indique le nombre maximal d’exécutions à supprimer. La valeur maximale autorisée pour max_runs est de 10 000. Si la valeur n’est pas spécifiée, la valeur par défaut demax_runsest 10 000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
À l’aide de Databricks Runtime 13.3 LTS ou version antérieure, vous pouvez exécuter le code client suivant dans un notebook Azure Databricks.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Pour connaître les paramètres et les spécifications de valeur de retour pour la suppression d’exécutions en fonction de l’heure de création, consultez la documentation de l’API Expériences Azure Databricks.
Restaurer des exécutions
Vous pouvez restaurer des exécutions précédemment supprimées à l’aide de l’interface utilisateur Databricks Mosaic AI.
- Dans la page Expérience, sélectionnez Supprimée dans le champ État pour afficher les exécutions supprimées.
- Pour sélectionner une ou plusieurs exécutions, cochez la case à gauche de chaque exécution.
- Cliquez sur Restaurer.
- Cliquez sur Restaurer pour confirmer. Pour afficher les exécutions restaurées, sélectionnez Active dans le champ État.
Restauration en bloc d’exécutions en fonction de l’heure de suppression
Vous pouvez également utiliser Python pour restaurer en bloc les exécutions d’une expérience supprimées au moment d’un horodatage UNIX ou après celui-ci.
À l’aide de Databricks Runtime 14.1 ou version ultérieure, vous pouvez appeler l’API mlflow.restore_runs pour restaurer les exécutions et retourner le nombre d’exécutions restaurées.
Voici les paramètres mlflow.restore_runs :
experiment_id: ID de l’expérience contenant les exécutions à restaurer.min_timestamp_millis: horodatage de suppression minimal en millisecondes depuis l’époque UNIX pour la restauration des exécutions. Seules les exécutions supprimées au moment de cet horodatage ou après celui-ci sont restaurées.max_runs: Facultatif. Entier positif qui indique le nombre maximal d’exécutions à restaurer. La valeur maximale autorisée pour max_runs est de 10 000. S’il n’est pas spécifié, max_runs est défini par défaut à 10 000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
À l’aide de Databricks Runtime 13.3 LTS ou version antérieure, vous pouvez exécuter le code client suivant dans un notebook Azure Databricks.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Pour connaître les paramètres et les spécifications de valeur de retour pour la restauration d’exécutions en fonction de l’heure de création, consultez la documentation de l’API Expériences Azure Databricks.
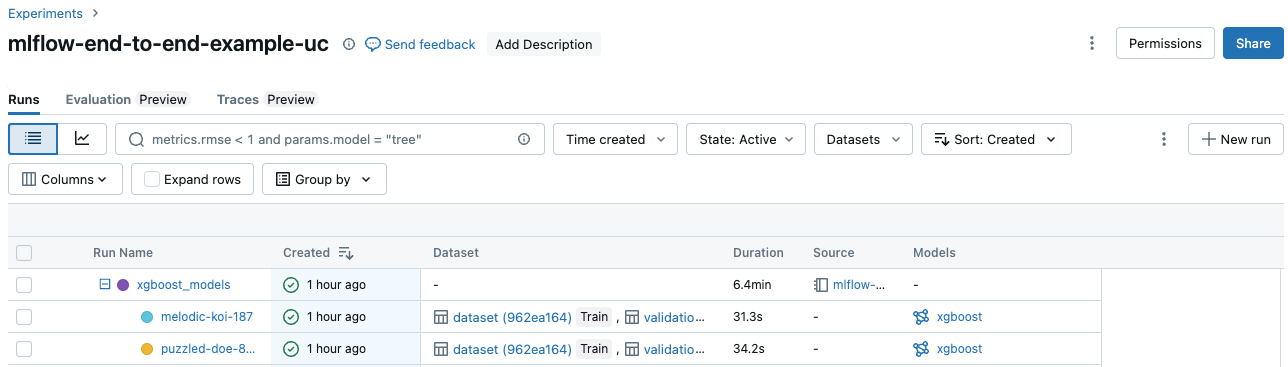
Comparer les exécutions
Vous pouvez comparer les exécutions à partir d’une seule expérience ou de plusieurs expériences. La page Comparaison des exécutions présente des informations sur les exécutions sélectionnées dans des formats graphiques et tabulaires. Vous pouvez également créer des visualisations des résultats d’exécution et des tables d’informations d’exécution, de paramètres d’exécution et de métriques.
Pour créer une visualisation :
- Sélectionnez le type de tracé (Tracé de coordonnées parallèles, Nuage de points ou Tracé de contour).
Pour un Tracé de coordonnées parallèles, sélectionnez les paramètres et les métriques à tracer. À partir de là, vous pouvez identifier les relations entre les paramètres et les métriques sélectionnés de façon à mieux définir l’espace de réglage des hyperparamètres pour vos modèles.
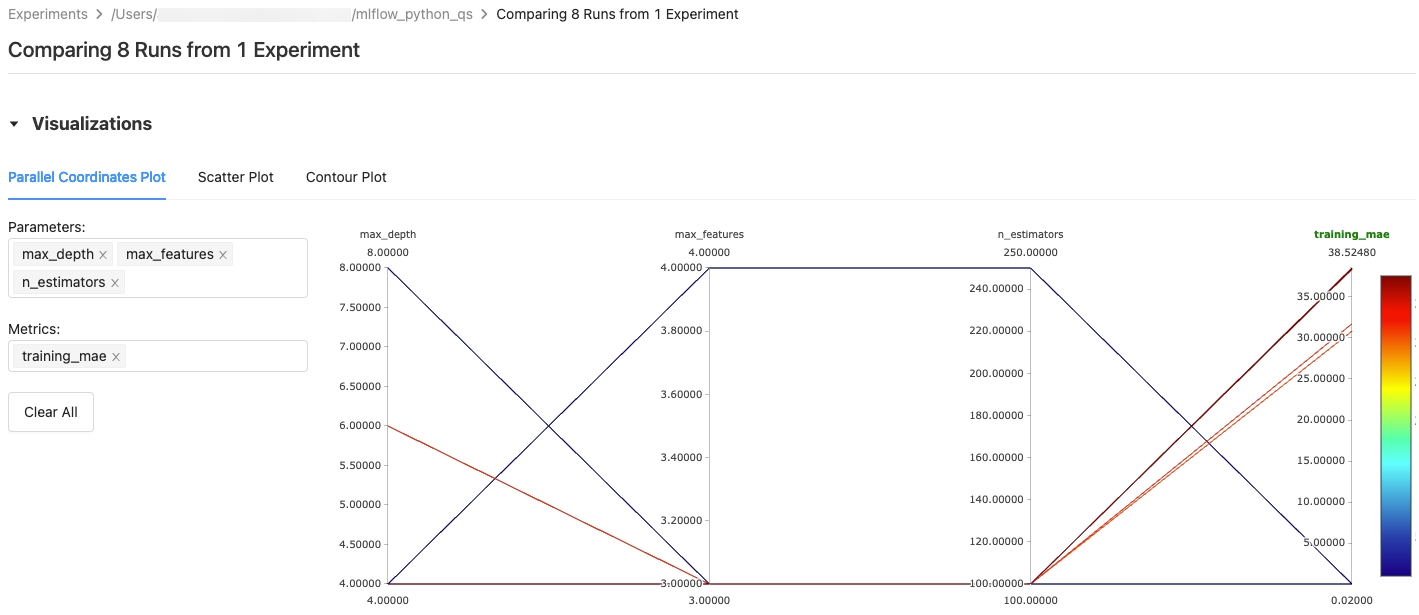
Pour un Nuage de points ou un Tracé de contour, sélectionnez le paramètre ou la métrique à afficher sur chaque axe.
Les tables Paramètres et Métriques affichent les paramètres d’exécution et les métriques de toutes les exécutions sélectionnées. Les colonnes de ces tables sont identifiées par la table Détails de l’exécution immédiatement au-dessus. Pour simplifier, vous pouvez masquer les paramètres et les métriques identiques dans les exécutions sélectionnées en basculant  .
.
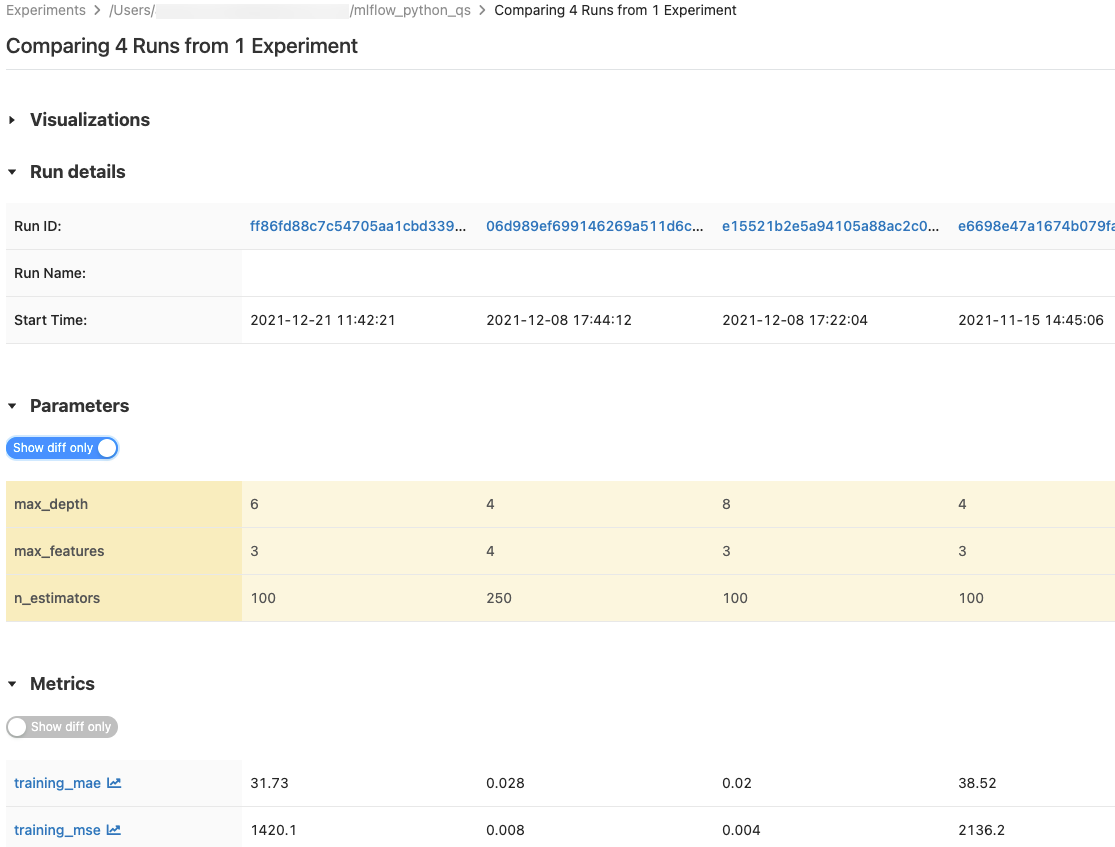
Comparer les exécutions à partir d’une seule expérience
- Dans la page d’expérience, sélectionnez deux exécutions ou plus en cliquant dans la case à cocher à gauche de l’exécution, ou sélectionnez toutes les exécutions en cochant la case en haut de la colonne.
- Cliquez sur Comparer. L’écran Comparaison de
<N>exécutions s’affiche.
Comparer les exécutions de plusieurs expériences
- Dans la page expériences, sélectionnez les expériences que vous souhaitez comparer en cliquant dans la zone à gauche du nom de l’expérience.
- Cliquez sur Comparer (n) (n est le nombre d’expériences que vous avez sélectionnées). Un écran s’affiche montrant toutes les exécutions des expériences que vous avez sélectionnées.
- Sélectionnez deux exécutions ou plus en cliquant dans la case à cocher à gauche de l’exécution, ou sélectionnez toutes les exécutions en cochant la case en haut de la colonne.
- Cliquez sur Comparer. L’écran Comparaison de
<N>exécutions s’affiche.
Copier des exécutions entre des espaces de travail
Pour importer ou exporter des exécutions MLflow vers ou à partir de votre espace de travail Databricks, vous pouvez utiliser le projet open source MLflow Export-Import alimenté par la communauté.