Entraîner des modèles de recommandation
Cet article comprend deux exemples de modèles de recommandation basés sur le deep learning sur Azure Databricks. Par rapport aux modèles de recommandation traditionnels, les modèles de deep learning peuvent obtenir des résultats de qualité plus élevés et s’adapter à des quantités de données plus importantes. À mesure que ces modèles continuent d’évoluer, Databricks fournit une infrastructure permettant d’entraîner efficacement des modèles de recommandation à grande échelle capables de gérer des centaines de millions d’utilisateurs.
Un système de recommandation général peut être considéré comme un entonnoir avec les étapes indiquées dans le diagramme.
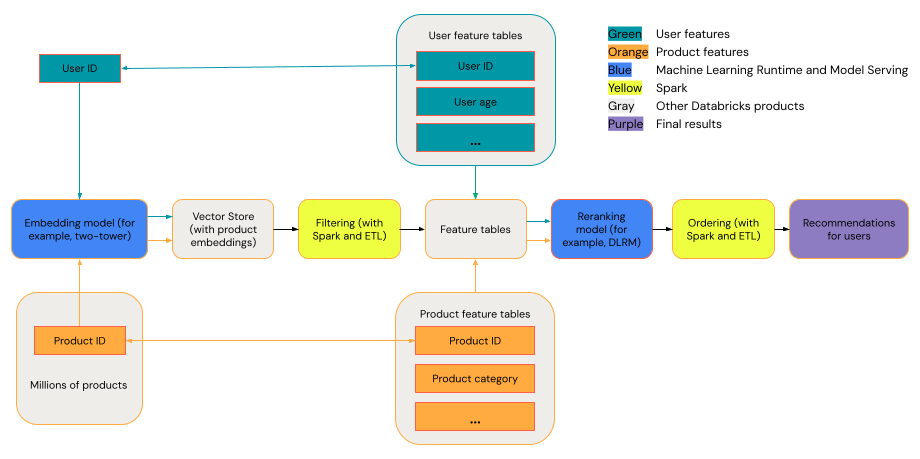
Certains modèles, tels que le modèle à deux tours, fonctionnent mieux que les modèles de récupération. Ces modèles sont plus petits et peuvent fonctionner efficacement sur des millions de points de données. D’autres modèles, tels que DLRM ou DeepFM, fonctionnent mieux que les modèles de reclassement. Ces modèles peuvent prendre davantage de données, sont plus volumineux et peuvent fournir des recommandations affinées.
Spécifications
Databricks Runtime 14.3 LTS ML
outils
Les exemples de cet article illustrent les outils suivants :
- TorchDistributor : TorchDistributor est une infrastructure qui vous permet d’exécuter un entraînement de modèle PyTorch à grande échelle sur Databricks. Elle utilise Spark pour l’orchestration et peut être mise à l’échelle vers autant de GPU que disponibles dans votre cluster.
- Mosaïque StreamingDataset : StreamingDataset améliore les performances et la scalabilité de l’entraînement sur de grands ensembles de données sur Databricks à l’aide de fonctionnalités telles que la prérécupération et l’entrelacement.
- MLflow : Mlflow permet de suivre les paramètres, les métriques et les points de contrôle de modèle.
- TorchRec : les systèmes de recommandation modernes utilisent des tables de choix incorporées pour gérer des millions d’utilisateurs et d’éléments pour générer des recommandations de haute qualité. Les tailles d’incorporation supérieures améliorent les performances du modèle, mais nécessitent une mémoire GPU importante et des configurations multi-GPU. TorchRec fournit une infrastructure pour mettre à l’échelle des modèles de recommandation et des tables de choix sur plusieurs GPU, ce qui est idéal pour les grandes incorporations.
Exemple : Recommandations vidéo à l’aide d’une architecture de modèle à deux tours
Le modèle à deux tours est conçu pour gérer des tâches de personnalisation à grande échelle en traitant séparément les données utilisateur et élément avant de les combiner. Il est capable de générer efficacement des centaines ou des milliers de recommandations de qualité décentes. Le modèle attend généralement trois entrées : une fonctionnalité user_id, une fonctionnalité product_id et une étiquette binaire définissant si l’interaction <utilisateur, produit> a été positive (l’utilisateur a acheté le produit) ou négative (l’utilisateur a donné au produit une évaluation d’une étoile). Les sorties du modèle sont des incorporations pour les utilisateurs et les éléments, qui sont ensuite généralement combinés (souvent à l’aide d’un produit point ou d’une similarité cosinus) pour prédire les interactions entre les éléments utilisateur.
Comme le modèle à deux tours fournit des incorporations pour les utilisateurs et les produits, vous pouvez placer ces incorporations dans une base de données vectorielle, telle que le Magasin de vecteurs Databricks, et effectuer des opérations de type similarité-recherche sur les utilisateurs et les éléments. Par exemple, vous pouvez placer tous les éléments dans un magasin de vecteurs et, pour chaque utilisateur, interroger le magasin de vecteurs pour rechercher les cent premiers éléments dont les incorporations sont similaires à celles de l’utilisateur.
L’exemple de notebook suivant déploie l’entraînement de modèle à deux tours à l’aide de l’ensemble de données « Apprendre à partir d'ensembles d'éléments » pour prédire la probabilité qu’un utilisateur évalue un certain film de manière élevée. Il utilise la mosaïque StreamingDataset pour le chargement de données distribuées, TorchDistributor pour l’entraînement de modèle distribué et Mlflow pour le suivi et la journalisation des modèles.
Bloc-notes de modèle de recommandation à deux tours
Ce notebook est également disponible dans la Place de marché Databricks : notebook à deux tours
Remarque
- Les entrées pour le modèle à deux tours sont le plus souvent les caractéristiques catégorielles user_id et product_id. Le modèle peut être modifié pour prendre en charge plusieurs vecteurs de caractéristique pour les utilisateurs et les produits.
- Les sorties du modèle à deux tours sont généralement des valeurs binaires indiquant si l’utilisateur aura une interaction positive ou négative avec le produit. Le modèle peut être modifié pour d’autres applications telles que la régression, la classification multiclasse et les probabilités pour plusieurs actions utilisateur (par exemple, abandonner ou acheter). Les sorties complexes doivent être déployées avec soin, car les objectifs concurrents peuvent dégrader la qualité des incorporations générées par le modèle.
Exemple : Entraîner une architecture DLRM avec un jeu de données synthétique
DLRM est une architecture de réseau neuronal de pointe conçue spécifiquement pour les systèmes de personnalisation et de recommandation. Il combine des entrées catégorielles et numériques pour modéliser efficacement les interactions entre les éléments utilisateur et prédire les préférences utilisateur. Les DLRM s’attendent généralement à des entrées qui incluent à la fois des fonctionnalités éparses (telles que l’ID utilisateur, l’ID d’élément, l’emplacement géographique ou la catégorie de produit) et des fonctionnalités denses (telles que l’âge de l’utilisateur ou le prix de l’élément). La sortie d’une DLRM est généralement une prédiction de l’engagement de l’utilisateur, telle que les taux de clic ou la probabilité d’achat.
Les DLRM offrent une infrastructure hautement personnalisable qui peut gérer des données à grande échelle, ce qui lui permet d’effectuer des tâches de recommandation complexes dans différents domaines. Étant donné qu’il s’agit d’un modèle plus grand que l’architecture à deux tours, ce modèle est souvent utilisé dans la phase de reclassement.
L’exemple de notebook suivant génère un modèle DLRM pour prédire des étiquettes binaires à l’aide de fonctionnalités denses (numériques) et de fonctionnalités éparses (catégorielles). Il utilise un ensemble de données synthétique pour effectuer l’apprentissage du modèle, de la mosaïque StreamingDataset pour le chargement de données distribuées, de TorchDistributor pour la formation du modèle distribué et de Mlflow pour le suivi et la journalisation des modèles.
Notebook DLRM
Ce notebook est également disponible dans la Place de marché Databricks : notebook DLRM.
Comparaison des modèles à deux tours et DLRM
Le tableau présente quelques instructions pour sélectionner le modèle de recommandation à utiliser.
| Type de modèle | Taille de l’ensemble de données nécessaire pour l’entraînement | Taille de modèle | Types d’entrée pris en charge | Types de sortie pris en charge | Cas d’utilisation |
|---|---|---|---|---|---|
| Deux tours | Plus petit | Plus petit | Généralement, deux fonctionnalités (user_id, product_id) | Principalement la classification binaire et la génération d’incorporations | Génération de centaines ou de milliers de recommandations possibles |
| DLRM | Plus grand | Plus grand | Diverses fonctionnalités catégorielles et denses (user_id, gender, geographic_location, product_id, product_category, …) | Classification multi-classe, régression, autres | Récupération affinée (recommandation de dizaines d’éléments hautement pertinents) |
En résumé, le modèle à deux tours est mieux utilisé pour générer des milliers de recommandations de bonne qualité très efficacement. Un exemple peut être des recommandations vidéo d’un fournisseur de câbles. Le modèle DLRM est le mieux utilisé pour générer des recommandations très spécifiques basées sur davantage de données. Par exemple, il peut s’agir d’un détaillant qui souhaite présenter à un client un plus petit nombre d’articles qu’il est très susceptible d’acheter.