Interroger des modèles IA génératifs
Dans cet article, vous allez découvrir comment mettre en forme les demandes de requête pour les modèles de fondation et les modèles externes, et comment les envoyer à votre point de terminaison de service de modèles.
Pour les requêtes portant sur des modèles Machine Learning ou Python traditionnels, consultez Mise en service de points de terminaison des requêtes pour les modèles personnalisés.
Mosaic AI Model Serving prend en charge les API de modèles de fondation et les modèles externes pour accéder aux modèles d’IA générative. Model Serving utilise une API compatible avec OpenAI unifiée et un SDK pour les interroger. Ceci permet d’expérimenter et de personnaliser des modèles d’IA générative pour la production parmi les clouds et les fournisseurs pris en charge.
Mosaic AI Model Serving propose les options suivantes pour envoyer des demandes de scoring aux points de terminaison qui servent les modèles de fondation ou les modèles externes :
| Method | Détails |
|---|---|
| Client OpenAI | Interrogez un modèle hébergé par un point de terminaison de service de modèles Mosaic AI en utilisant le client OpenAI. Spécifiez le nom du point de terminaison de service de modèle comme entrée du model. Pris en charge pour les modèles de conversation, d’incorporation et de complétion rendus disponibles par des API de modèle de fondation ou des modèles externes. |
| Interface utilisateur de service | Dans la page Point de terminaison de service, sélectionnez Interroger le point de terminaison. Insérez les données d’entrée du modèle au format JSON, puis cliquez sur Envoyer la requête. Si le modèle a un exemple d’entrée enregistré, utilisez Afficher l’exemple pour le charger. |
| API REST | Appelez et interrogez le modèle en utilisant l’API REST. Pour plus de détails, consultez POST /serving-endpoints/{name}/invocations. Pour les requêtes de scoring adressées aux points de terminaison servant plusieurs modèles, consultez Interroger des modèles individuels derrière un point de terminaison. |
| Kit de développement logiciel (SDK) de déploiements MLflow | Utilisez la fonction predict() du Kit de développement logiciel (SDK) Déploiements MLflow pour interroger le modèle. |
| Databricks pour Python SDK | Databricks pour Python SDK est une couche sur l’API REST. Il gère les détails de bas niveau, tels que l’authentification, ce qui facilite l’interaction avec les modèles. |
| Fonction SQL | Appelez l’inférence de modèle directement à partir de SQL à l’aide de la fonction SQL ai_query. Voir Interroger un modèle servi avec ai_query(). |
Exigences
- Un point de terminaison de mise en service de modèles.
- Un espace de travail Databricks dans une région prise en charge.
- Pour envoyer une demande de scoring via le client OpenAI, l’API REST ou le Kit de développement logiciel (SDK) de déploiement MLflow, vous devez disposer d’un jeton d’API Databricks.
Important
À titre de meilleure pratique de sécurité pour les scénarios de production, Databricks vous recommande d’utiliser des jetons OAuth machine à machine pour l’authentification en production.
Pour les tests et le développement, Databricks recommande d’utiliser un jeton d’accès personnel appartenant à des principaux de service et non pas à des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Installer des packages
Après avoir sélectionné une méthode d’interrogation, vous devez d’abord installer le package approprié sur votre cluster.
Client OpenAI
Pour utiliser le client OpenAI, le package databricks-sdk[openai] doit être installé sur votre cluster. Databricks SDK fournit un wrapper pour construire le client OpenAI avec l’autorisation automatiquement configurée pour interroger des modèles IA génératifs. Exécutez la commande suivante dans votre Notebook ou dans votre terminal local :
!pip install databricks-sdk[openai]>=0.35.0
Les éléments suivants ne sont nécessaires que lors de l’installation du package sur un Notebook Databricks
dbutils.library.restartPython()
API REST
L’accès à l’API REST de service est disponible dans le Runtime Databricks pour Machine Learning.
Kit de développement logiciel (SDK) de déploiements MLflow
!pip install mlflow
Les éléments suivants ne sont nécessaires que lors de l’installation du package sur un Notebook Databricks
dbutils.library.restartPython()
Databricks pour Python SDK
Le kit de développement logiciel (SDK) Databricks pour Python est déjà installé sur tous les clusters Azure Databricks qui utilisent Databricks Runtime 13.3 LTS ou une version ultérieure. Pour les clusters Azure Databricks qui utilisent Databricks Runtime 12.2 LTS et les versions antérieures, vous devez d’abord installer le kit de développement logiciel (SDK) Databricks pour Python. Consultez le Kit de développement logiciel (SDK) Databricks pour Python.
Interroger un modèle de saisie semi-automatique de conversation
Voici des exemples d’interrogation d’un modèle de conversation. L’exemple s’applique à l’interrogation d’un modèle de conversation mis à disposition à l’aide de l’une des fonctionnalités Model Serving : API de modèles de fondation ou modèles externes.
Pour obtenir un exemple d’inférence par lots, consultez l’inférence Batch à l’aide du débit provisionné des API Foundation Model.
Client OpenAI
Voici une demande de conversation pour le modèle DBRX Instruct mis à disposition par le point de terminaison avec paiement par jeton des API Foundation Model, databricks-dbrx-instruct dans votre espace de travail.
Pour utiliser le client OpenAI, spécifiez le nom du point de terminaison de service du modèle comme entrée du model.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
Pour interroger des modèles de base en dehors de votre espace de travail, vous devez utiliser directement le client OpenAI. Vous avez également besoin de votre instance d’espace de travail Databricks pour connecter le client OpenAI à Databricks. L’exemple suivant suppose que vous disposez d’un jeton d’API Databricks et openai installé sur votre calcul.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
API REST
Important
L’exemple suivant utilise des paramètres d’API REST pour interroger des points de terminaison de service qui servent des modèles de base. Ces paramètres sont en préversion publique, et la définition est susceptible de changer. Consultez POST /serving-endpoints/{name}/invocations.
Voici une demande de conversation pour le modèle DBRX Instruct mis à disposition par le point de terminaison avec paiement par jeton des API Foundation Model, databricks-dbrx-instruct dans votre espace de travail.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": " What is a mixture of experts model?"
}
]
}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-dbrx-instruct/invocations \
Kit de développement logiciel (SDK) de déploiements MLflow
Important
L’exemple suivant utilise l’API predict() à partir du Kit SDK de déploiements MLflow.
Voici une demande de conversation pour le modèle DBRX Instruct mis à disposition par le point de terminaison avec paiement par jeton des API Foundation Model, databricks-dbrx-instruct dans votre espace de travail.
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
chat_response = client.predict(
endpoint="databricks-dbrx-instruct",
inputs={
"messages": [
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
{
"role": "user",
"content": "What is a mixture of experts model??"
}
],
"temperature": 0.1,
"max_tokens": 20
}
)
Databricks pour Python SDK
Voici une demande de conversation pour le modèle DBRX Instruct mis à disposition par le point de terminaison avec paiement par jeton des API Foundation Model, databricks-dbrx-instruct dans votre espace de travail.
Ce code doit être exécuté dans un bloc-notes dans votre espace de travail. Consultez Utiliser le Kit de développement logiciel (SDK) Databricks pour Python à partir d’un notebook Azure Databricks.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-dbrx-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="You are a helpful assistant."
),
ChatMessage(
role=ChatMessageRole.USER, content="What is a mixture of experts model?"
),
],
max_tokens=128,
)
print(f"RESPONSE:\n{response.choices[0].message.content}")
LangChain
Pour formuler une requête à un point de terminaison de modèle de base à l’aide de LangChain, vous pouvez utiliser la classe ChatDatabricks ChatModel et spécifier le endpoint.
L’exemple suivant utilise la classe ChatModel ChatDatabricks dans LangChain pour formuler une requête à databricks-dbrx-instruct, le point de terminaison de paiement par jeton de l’API Foundation Model.
%pip install databricks-langchain
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_databricks import ChatDatabricks
messages = [
SystemMessage(content="You're a helpful assistant"),
HumanMessage(content="What is a mixture of experts model?"),
]
llm = ChatDatabricks(endpoint_name="databricks-dbrx-instruct")
llm.invoke(messages)
SQL
Important
L’exemple suivant utilise la fonction SQL intégrée, ai_query. Cette fonction est en préversion publique et sa définition est susceptible de changer. Voir Interroger un modèle servi avec ai_query().
Voici une demande de conversation pour meta-llama-3-1-70b-instruct, mis à disposition par le point de terminaison avec paiement par jeton des API Foundation Model, databricks-meta-llama-3-1-70b-instruct dans votre espace de travail.
Remarque
La fonction ai_query() ne prend pas en charge les points de terminaison de requête qui servent le modèle DBRX ou DBRX Instruct.
SELECT ai_query(
"databricks-meta-llama-3-1-70b-instruct",
"Can you explain AI in ten words?"
)
Par exemple, voici le format de requête attendu pour un modèle de conversation lors de l’utilisation de l’API REST. Pour les modèles externes, vous pouvez inclure des paramètres supplémentaires valides pour une configuration de fournisseur et de point de terminaison donnée. Consultez Paramètres de requête supplémentaires.
{
"messages": [
{
"role": "user",
"content": "What is a mixture of experts model?"
}
],
"max_tokens": 100,
"temperature": 0.1
}
Voici un format de réponse attendu pour une requête effectuée à l’aide de l’API REST :
{
"model": "databricks-dbrx-instruct",
"choices": [
{
"message": {},
"index": 0,
"finish_reason": null
}
],
"usage": {
"prompt_tokens": 7,
"completion_tokens": 74,
"total_tokens": 81
},
"object": "chat.completion",
"id": null,
"created": 1698824353
}
Interroger un modèle d’incorporations
Voici une requête d’incorporation pour le modèle gte-large-en mis à disposition par les API Foundation Model. L’exemple s’applique à l’interrogation d’un modèle d’incorporation mis à disposition à l’aide de l’une des fonctionnalités Model Serving : API de modèles de fondation ou modèles externes.
Client OpenAI
Pour utiliser le client OpenAI, spécifiez le nom du point de terminaison de service du modèle comme entrée du model.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
Pour interroger des modèles de base en dehors de votre espace de travail, vous devez utiliser directement le client OpenAI, comme illustré ci-dessous. L’exemple suivant suppose que vous disposez d’un jeton d’API Databricks et d’openai installé sur votre calcul. Vous avez également besoin de votre instance d’espace de travail Databricks pour connecter le client OpenAI à Databricks.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
API REST
Important
L’exemple suivant utilise des paramètres d’API REST pour interroger les points de terminaison de service qui servent les modèles de fondation ou les modèles externes. Ces paramètres sont en préversion publique, et la définition est susceptible de changer. Consultez POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{ "input": "Embed this sentence!"}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-gte-large-en/invocations
Kit de développement logiciel (SDK) de déploiements MLflow
Important
L’exemple suivant utilise l’API predict() à partir du Kit SDK de déploiements MLflow.
import mlflow.deployments
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
embeddings_response = client.predict(
endpoint="databricks-gte-large-en",
inputs={
"input": "Here is some text to embed"
}
)
Databricks pour Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-gte-large-en",
input="Embed this sentence!"
)
print(response.data[0].embedding)
LangChain
Pour utiliser un modèle d’API Databricks Foundation Model dans LangChain en tant que modèle d’intégration, importez la classe DatabricksEmbeddings et spécifiez le paramètre endpoint de la manière suivante :
%pip install databricks-langchain
from langchain_databricks import DatabricksEmbeddings
embeddings = DatabricksEmbeddings(endpoint="databricks-gte-large-en")
embeddings.embed_query("Can you explain AI in ten words?")
SQL
Important
L’exemple suivant utilise la fonction SQL intégrée, ai_query. Cette fonction est en préversion publique et sa définition est susceptible de changer. Voir Interroger un modèle servi avec ai_query().
SELECT ai_query(
"databricks-gte-large-en",
"Can you explain AI in ten words?"
)
Voici le format de requête attendu pour un modèle d’incorporations. Pour les modèles externes, vous pouvez inclure des paramètres supplémentaires valides pour une configuration de fournisseur et de point de terminaison donnée. Consultez Paramètres de requête supplémentaires.
{
"input": [
"embedding text"
]
}
Voici le format de réponse attendu :
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": []
}
],
"model": "text-embedding-ada-002-v2",
"usage": {
"prompt_tokens": 2,
"total_tokens": 2
}
}
Vérifier si les incorporations sont normalisées
Utilisez ce qui suit pour vérifier si les incorporations générées par votre modèle sont normalisées.
import numpy as np
def is_normalized(vector: list[float], tol=1e-3) -> bool:
magnitude = np.linalg.norm(vector)
return abs(magnitude - 1) < tol
Interroger un modèle de saisie semi-automatique de texte
Client OpenAI
Important
L’interrogation de modèles de saisie semi-automatique de texte rendues disponibles à l’aide des API Foundation Model pay-per token à l’aide du client OpenAI n’est pas prise en charge. Seule l’interrogation de modèles externes à l’aide du client OpenAI est prise en charge, comme illustré dans cette section.
Pour utiliser le client OpenAI, spécifiez le nom du point de terminaison de service du modèle comme entrée du model. L’exemple suivant interroge le modèle de complétions claude-2 hébergé par Anthropic en utilisant le client OpenAI. Pour utiliser le client OpenAI, renseignez le champ model avec le nom du point de terminaison de service du modèle qui héberge le modèle que vous voulez interroger.
Cet exemple utilise un point de terminaison créé précédemment, anthropic-completions-endpoint, configuré pour accéder aux modèles externes à partir du fournisseur de modèles Anthropic. Découvrez comment créer des points de terminaison de modèle externe.
Consultez les Modèles pris en charge pour obtenir des modèles supplémentaires que vous pouvez interroger, et leurs fournisseurs.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
completion = openai_client.completions.create(
model="anthropic-completions-endpoint",
prompt="what is databricks",
temperature=1.0
)
print(completion)
API REST
Voici une demande de saisie semi-automatique pour interroger un modèle d’achèvement mis à disposition à l’aide de modèles externes.
Important
L’exemple suivant utilise des paramètres d’API REST pour interroger les points de terminaison de service qui servent des modèles externes. Ces paramètres sont en préversion publique, et la définition est susceptible de changer. Consultez POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is a quoll?", "max_tokens": 64}' \
https://<workspace_host>.databricks.com/serving-endpoints/<completions-model-endpoint>/invocations
Kit de développement logiciel (SDK) de déploiements MLflow
Voici une demande de saisie semi-automatique pour interroger un modèle d’achèvement mis à disposition à l’aide de modèles externes.
Important
L’exemple suivant utilise l’API predict() à partir du Kit SDK de déploiements MLflow.
import os
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
os.environ['DATABRICKS_HOST'] = "https://<workspace_host>.databricks.com"
os.environ['DATABRICKS_TOKEN'] = "dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
completions_response = client.predict(
endpoint="<completions-model-endpoint>",
inputs={
"prompt": "What is the capital of France?",
"temperature": 0.1,
"max_tokens": 10,
"n": 2
}
)
# Print the response
print(completions_response)
Databricks pour Python SDK
TThe following is a completions request for querying a completions model made available using external models.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="<completions-model-endpoint>",
prompt="Write 3 reasons why you should train an AI model on domain specific data sets."
)
print(response.choices[0].text)
SQL
Important
L’exemple suivant utilise la fonction SQL intégrée, ai_query. Cette fonction est en préversion publique et sa définition est susceptible de changer. Voir Interroger un modèle servi avec ai_query().
SELECT ai_query(
"<completions-model-endpoint>",
"Can you explain AI in ten words?"
)
Voici le format de requête attendu pour un modèle d’achèvement. Pour les modèles externes, vous pouvez inclure des paramètres supplémentaires valides pour une configuration de fournisseur et de point de terminaison donnée. Consultez Paramètres de requête supplémentaires.
{
"prompt": "What is mlflow?",
"max_tokens": 100,
"temperature": 0.1,
"stop": [
"Human:"
],
"n": 1,
"stream": false,
"extra_params":
{
"top_p": 0.9
}
}
Voici le format de réponse attendu :
{
"id": "cmpl-8FwDGc22M13XMnRuessZ15dG622BH",
"object": "text_completion",
"created": 1698809382,
"model": "gpt-3.5-turbo-instruct",
"choices": [
{
"text": "MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides tools for tracking experiments, managing and deploying models, and collaborating on projects. MLflow also supports various machine learning frameworks and languages, making it easier to work with different tools and environments. It is designed to help data scientists and machine learning engineers streamline their workflows and improve the reproducibility and scalability of their models.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 83,
"total_tokens": 88
}
}
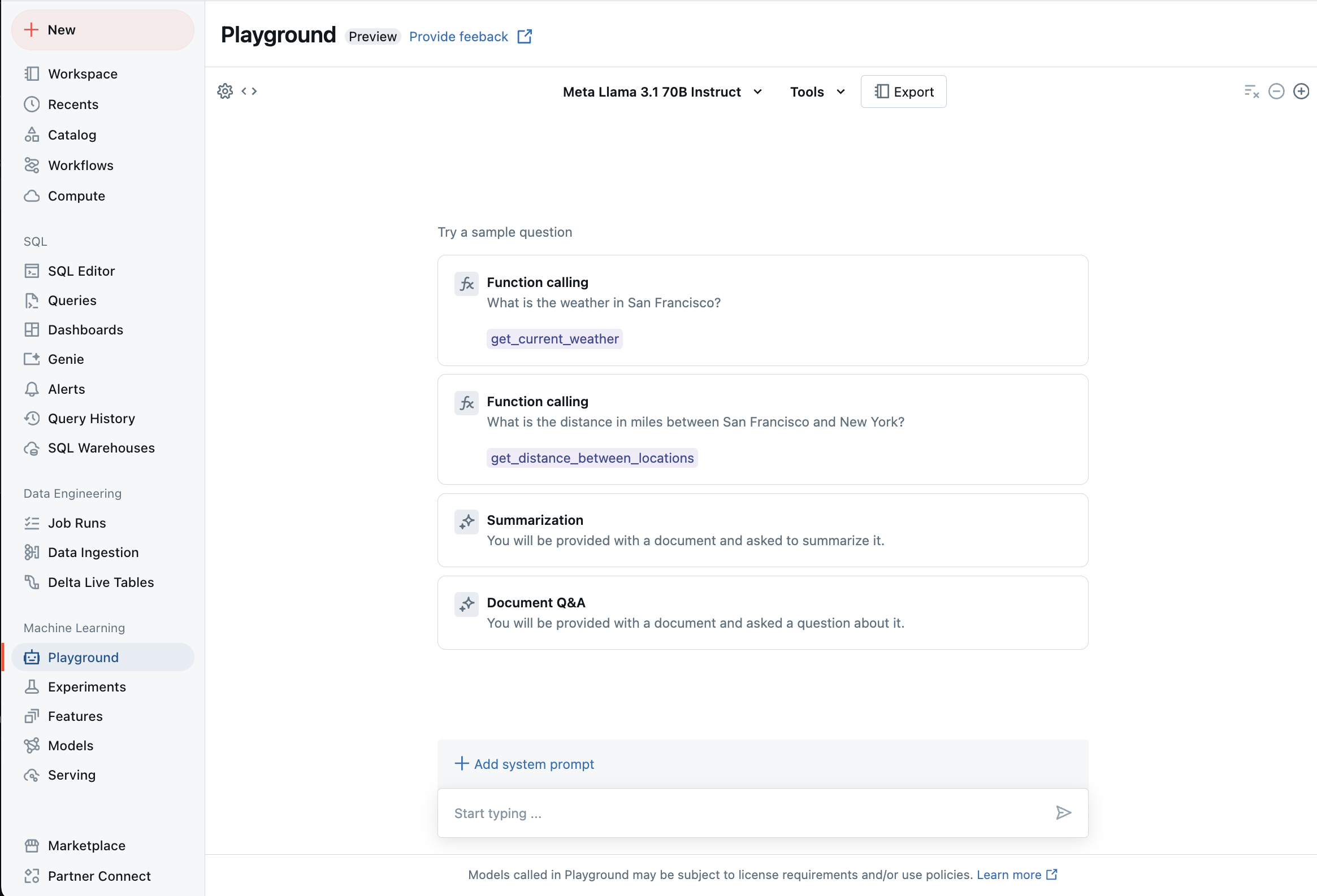
Conversation avec des LLM pris en charge en utilisant AI Playground
Vous pouvez interagir avec des grands modèles de langage pris en charge en utilisant AI Playground. Le terrain de jeu de l’IA est un environnement de type conversation dans lequel vous pouvez tester, inviter et comparer des LLM à partir de votre espace de travail Azure Databricks.
Ressources supplémentaires
- Tables d’inférence pour la surveillance et le débogage des modèles
- Inférence par lots à l’aide du débit provisionné des API Foundation Model
- API Databricks Foundation Model
- Modèles externes dans le service de modèles Mosaic AI
- Tutoriel : Créer des points de terminaison de modèle externe pour interroger des modèles OpenAI
- Modèles pris en charge pour le paiement par jeton
- Référence de l’API REST Foundation Model