Que signifient les plages de jetons par seconde dans le débit approvisionné ?
Cet article explique comment et pourquoi Databricks mesure les jetons par seconde pour les charges de travail de débit approvisionné pour les API Foundation Model.
Les performances des modèles de langage volumineux (LLMs) sont souvent mesurées en termes de jetons par seconde. Lorsque vous configurez des points de terminaison de service de modèle de production, il est important de prendre en compte le nombre de demandes envoyées par votre application au point de terminaison. Cela vous aide à comprendre si votre point de terminaison doit être configuré pour être mis à l’échelle afin de ne pas avoir d’impact sur la latence.
Lors de la configuration des plages de scale-out pour les points de terminaison déployés avec un débit approvisionné, Databricks a trouvé plus facile de mesurer les entrées entrantes dans votre système à l’aide de jetons.
Qu’est-ce que les jetons ?
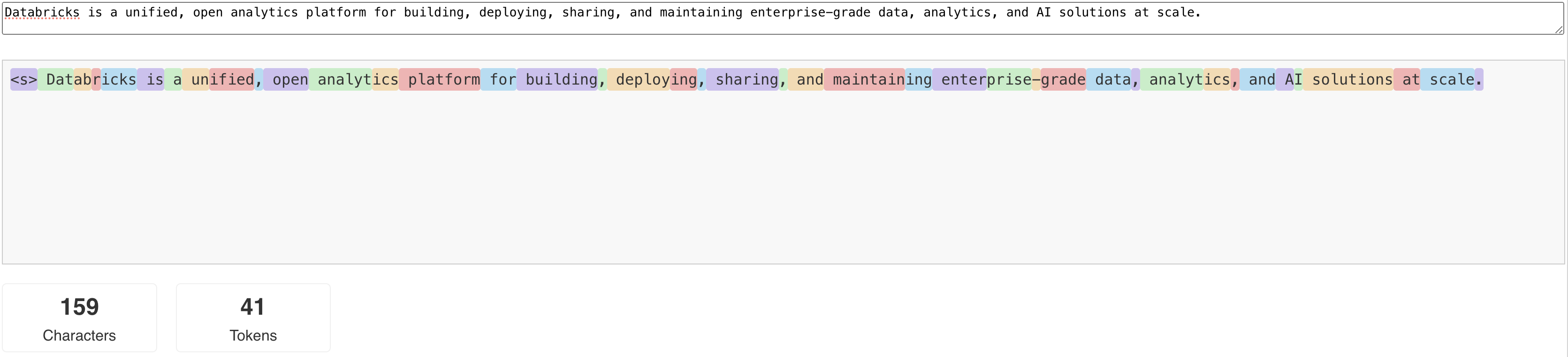
Les LLMs lisent et génèrent du texte selon ce que l’on appelle un jeton . Les jetons peuvent être des mots ou des sous-mots, et les règles exactes pour fractionner du texte en jetons varient d’un modèle à un autre. Par exemple, vous pouvez utiliser des outils en ligne pour voir comment le tokenizer de Llama convertit les mots en jetons.
Le diagramme suivant montre un exemple de la façon dont le tokenizer Llama décompose le texte :
Pourquoi mesurer les performances LLM en termes de jetons par seconde ?
Traditionnellement, les points de terminaison de service sont configurés en fonction du nombre de requêtes simultanées par seconde (RPS). Toutefois, une demande d'inférence LLM prend une durée différente en fonction du nombre de jetons transmis et du nombre de jetons générés, ce qui peut entraîner un déséquilibre entre les requêtes. Par conséquent, décider de la quantité de scale-out dont votre point de terminaison a besoin nécessite vraiment de mesurer l’échelle du point de terminaison en termes de contenu de votre demande : les jetons.
Différents cas d’usage présentent des ratios de jetons d’entrée et de sortie différents :
- Longueurs variables des contextes d’entrée: bien que certaines requêtes n’impliquent que quelques jetons d’entrée, par exemple une courte question, d’autres peuvent impliquer des centaines ou même des milliers de jetons, comme un document long pour résumer. Cette variabilité rend la configuration d’un point de terminaison de service uniquement en fonction de rps difficile, car elle ne tient pas compte des demandes de traitement variables des différentes requêtes.
- Longueurs variables de sortie en fonction du cas d’usage: Différents cas d’usage pour les modèles de langage LLM peuvent entraîner des longueurs de jetons de sortie très différentes. La génération de jetons de sortie est la partie la plus gourmande en temps de l’inférence LLM, ce qui peut avoir un impact considérable sur le débit. Par exemple, le résumé consiste en des réponses plus courtes, plus concises, mais la génération de texte, comme la rédaction d’articles ou de descriptions de produits, permet de générer des réponses beaucoup plus longues.
Comment sélectionner la plage de jetons par seconde pour mon point de terminaison ?
Les points de terminaison de mise en service de débit approvisionné sont configurés en termes de plage de jetons par seconde que vous pouvez envoyer au point de terminaison. Le point de terminaison effectue un scale-up et un scale-down pour gérer la charge de votre application de production. Vous êtes facturé par heure en fonction de la plage de jetons par seconde vers laquelle votre point de terminaison est mis à l’échelle.
La meilleure façon de connaître la plage de jetons par seconde qui convient à votre cas d'usage de votre point de terminaison au débit provisionné est d'effectuer un test de charge avec un jeu de données représentatif. Consultez Effectuer l’évaluation de votre propre point de terminaison LLM.
Il existe deux facteurs importants à prendre en compte :
- Présentation de la façon dont Databricks mesure les performances en jetons par seconde du LLM.
- Fonctionnement de la mise à l’échelle automatique.
Présentation de la façon dont Databricks mesure les jetons par seconde des performances du LLM
Databricks évalue les points de terminaison par rapport à une charge de travail représentant des tâches de résumé courantes pour les cas d’usage de génération augmentée de récupération. Plus précisément, la charge de travail se compose des éléments suivants :
- 2 048 jetons d’entrée
- 256 jetons de sortie
Les plages de jetons affichées combinent le débit de jetons d’entrée et de sortie et optimisent par défaut l’équilibrage du débit et de la latence.
Databricks confirme que les utilisateurs peuvent envoyer autant de jetons par seconde simultanément au point de terminaison, avec une taille de lot de 1 par requête. Cela simule plusieurs requêtes qui atteignent le point de terminaison en même temps, ce qui représente plus précisément la façon dont vous utiliseriez réellement le point de terminaison en production.
- Par exemple, si un point de terminaison de service de débit provisionné a un taux défini de 2304 jetons par seconde (2048 + 256), une seule requête avec une entrée de 2048 jetons et une sortie attendue de 256 jetons est censée prendre environ une seconde à exécuter.
- De même, si le taux est défini sur 5600, vous pouvez vous attendre à une seule requête, avec le nombre de jetons d’entrée et de sortie ci-dessus, à prendre environ 0,5 secondes pour s’exécuter, c’est-à-dire que le point de terminaison peut traiter deux requêtes similaires en environ une seconde.
Si votre charge de travail varie selon les critères ci-dessus, vous pouvez vous attendre à ce que la latence varie en fonction du taux de débit provisionné répertorié. Comme indiqué précédemment, la génération de jetons de sortie est plus gourmande en temps que d’inclure plus de jetons d’entrée. Si vous effectuez une inférence par lot et que vous souhaitez estimer le temps nécessaire à sa fin, vous pouvez calculer le nombre moyen de jetons d’entrée et de sortie et comparer à la charge de travail de référence Databricks ci-dessus.
- Par exemple, si vous avez 1 000 lignes, avec un nombre moyen de jetons d’entrée de 3 000 et un nombre moyen de jetons de sortie de 500 et un débit provisionné de 3 500 jetons par seconde, il peut prendre plus de que 1 000 secondes totales (une seconde par ligne) en raison du nombre moyen de jetons plus grand que le benchmark Databricks.
- De même, si vous avez 1 000 lignes, une entrée moyenne de 1 500 jetons, une sortie moyenne de 100 jetons et un débit provisionné de 1 600 jetons par seconde, il peut prendre moins de que 1 000 secondes (une seconde par ligne) en raison du nombre moyen de jetons étant moins que le benchmark Databricks.
Pour estimer le débit provisionné idéal nécessaire pour terminer votre charge de travail d'inférence par lots, vous pouvez utiliser le notebook de la section Effectuer l'inférence LLM par lot en utilisant ai_query
Fonctionnement de la mise à l’échelle automatique
La mise en service des modèles propose un système de mise à l’échelle automatique rapide qui met à l’échelle le calcul sous-jacent pour répondre à la demande de jetons par seconde de votre application. Databricks augmente le débit provisionné en unités de jetons par seconde, donc vous ne payez pour des unités supplémentaires de débit provisionné que lorsqu'elles sont réellement utilisées.
Le graphique de latence de débit suivant montre un point de terminaison de débit provisionné testé avec un nombre croissant de requêtes parallèles. Le premier point représente 1 requête, la deuxième, 2 requêtes parallèles, la troisième, 4 requêtes parallèles, et ainsi de suite. Au fur et à mesure que le nombre de demandes augmente, et par conséquent la demande de jetons par seconde, vous constatez que la capacité augmente également. Cette augmentation indique que la mise à l’échelle automatique augmente le calcul disponible. Toutefois, vous pouvez commencer à voir que le débit se stabilise, atteignant un maximum de ~8 000 jetons par seconde lorsque d'autres requêtes parallèles sont effectuées. La latence totale augmente à mesure que d’autres requêtes doivent attendre dans la file d’attente avant d’être traitées, car le calcul alloué est utilisé simultanément.
Remarque
Vous pouvez maintenir la constance du débit en désactivant la fonctionnalité de mise à l'échelle à zéro et en configurant un débit minimal sur le point de terminaison de distribution. Cela évite d’attendre que le point de terminaison soit mis à l’échelle.
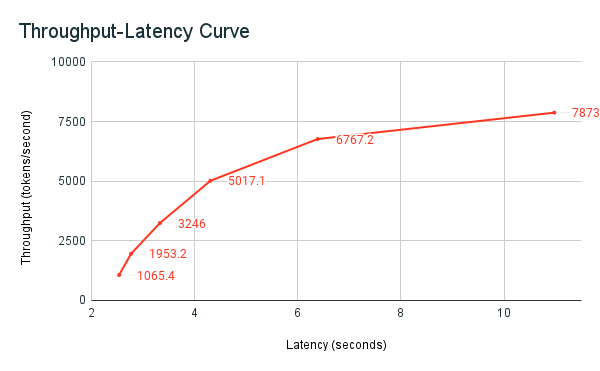 Graph
Graph
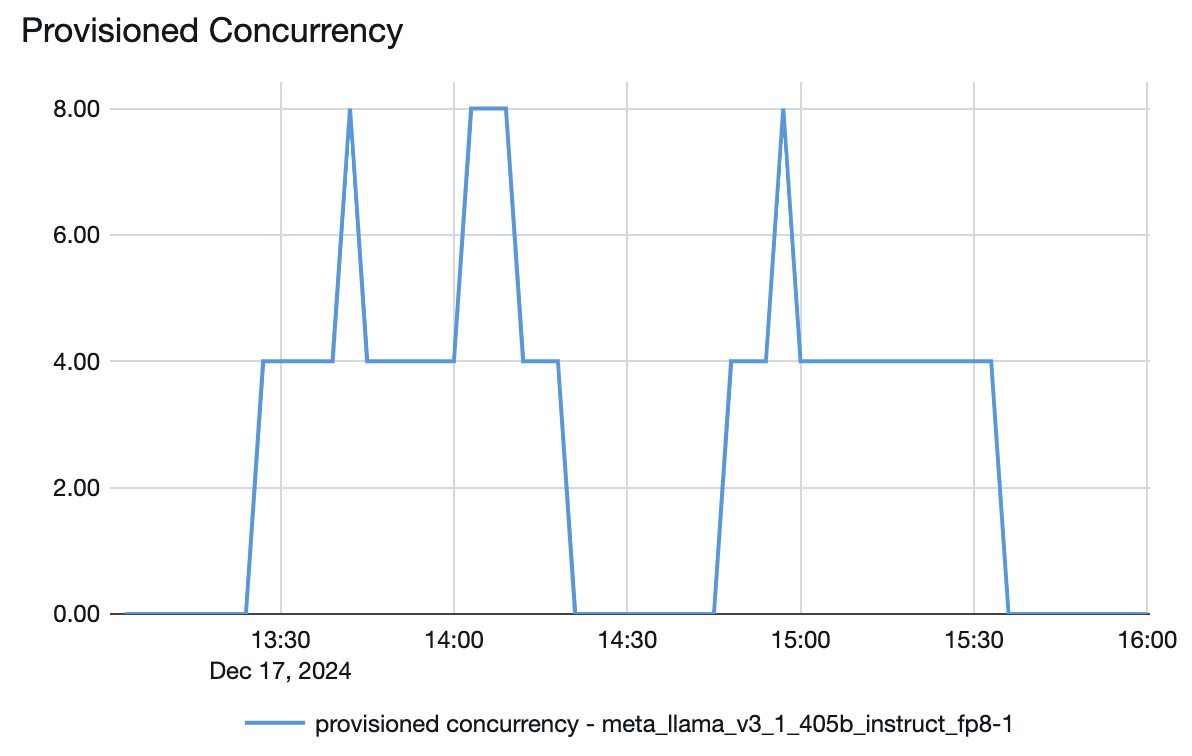
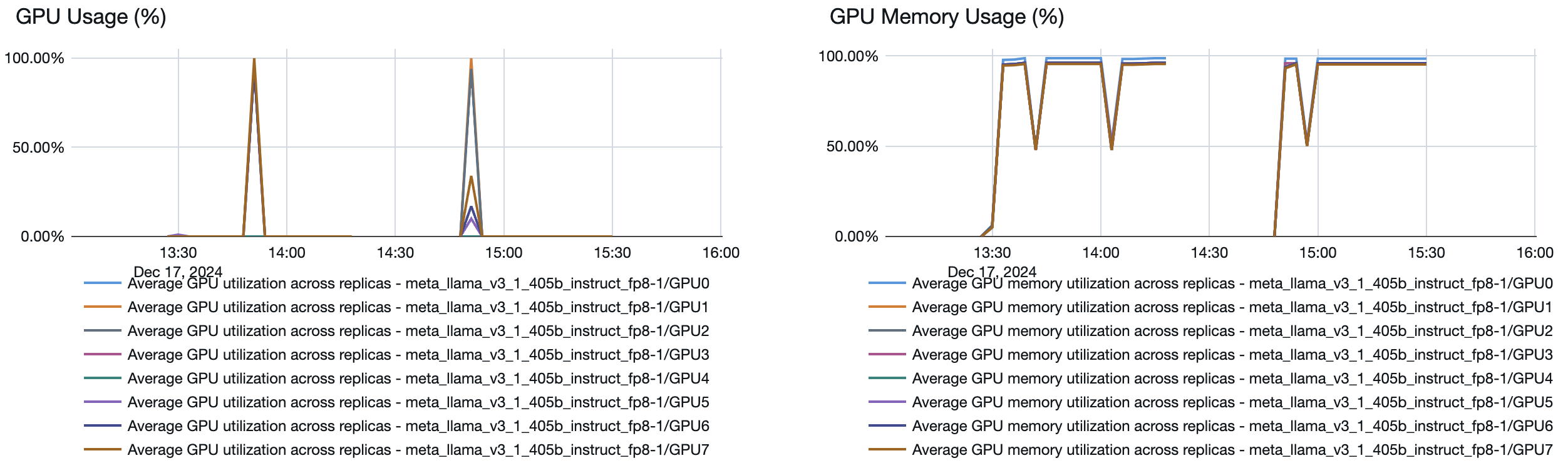
Vous pouvez également voir à partir du point de terminaison de mise en service la façon dont les ressources sont mises en place ou hors service en fonction de la demande :
Figure de Concurrence provisionnée