Databricks Runtime pour le Machine Learning
Databricks Runtime for Machine Learning (Databricks Runtime ML) automatise la création d'un cluster avec une infrastructure d'apprentissage automatique et d'apprentissage profond prédéfinie comprenant les bibliothèques ML et DL les plus courantes. Pour obtenir la liste complète des bibliothèques incluses dans chaque version de Databricks Runtime ML, consultez les notes de publication.
Remarque
Pour accéder aux données dans Unity Catalog pour les flux de travail Machine Learning, le mode d’accès du cluster doit être un utilisateur unique (affecté). Les clusters partagés ne sont pas compatibles avec Databricks Runtime pour le Machine Learning. De plus, Databricks Runtime ML n’est pas pris en charge sur les clusters TableACL ou les clusters dont spark.databricks.pyspark.enableProcessIsolation config est défini sur true.
Créer un cluster à l'aide de Databricks Runtime ML
Lorsque vous créez un cluster, sélectionnez une version de Databricks Runtime ML dans le menu déroulant Version Databricks Runtime. Les runtimes de ML UC et GPU sont disponibles.
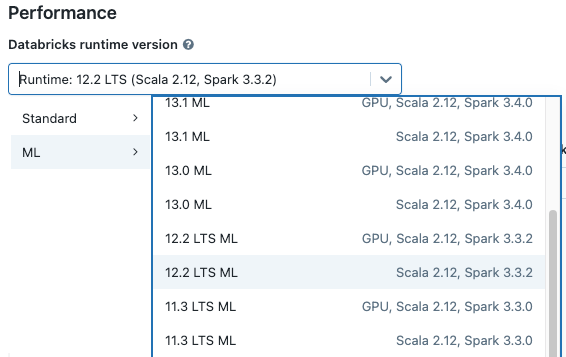
Si vous sélectionnez un cluster dans le menu déroulant du notebook, la version de Databricks Runtime s’affiche à droite du nom du cluster :
Si vous sélectionnez un runtime ML avec GPU, vous êtes invité à sélectionner un Type de pilote et un Type de Workercompatibles. Les types d’instance incompatibles sont grisés dans les menus déroulants. Les types d’instances avec GPU sont répertoriés sous l’étiquette Accéléré GPU. Pour plus d’informations sur la création de clusters GPU Azure Databricks, consultez Calcul avec GPU. Databricks Runtime ML intègre des pilotes matériels GPU et des bibliothèques NVIDIA comme CUDA.
Photon et Databricks Runtime ML
Lorsque vous créez un cluster de processeur exécutant Databricks Runtime 15.2 ML ou une version ultérieure, vous pouvez choisir d’activer Photon. Photon améliore les performances des applications à l’aide de Spark SQL, de Spark DataFrames, d’ingénierie de caractéristiques, de GraphFrames et de xgboost4j. Il n’est pas prévu pour améliorer les performances sur les applications utilisant des RDD Spark, des fonctions définies par l’utilisateur Pandas et des langages non JVM tels que Python. Ainsi, les packages Python tels que XGBoost, PyTorch et TensorFlow ne voient pas d’amélioration avec Photon.
Les API Spark RDD et Spark MLlib ont une compatibilité limitée avec Photon. Lors du traitement de grands jeux de données en utilisant Spark RDD ou Spark MLlib, vous pouvez rencontrer des problèmes de mémoire Spark. Consultez Problèmes de mémoire Spark.
Bibliothèques incluses dans Databricks Runtime ML
Databricks Runtime ML comprend une variété de bibliothèques ML populaires. Les bibliothèques sont mises à jour avec chaque version pour inclure de nouvelles fonctionnalités et des correctifs.
Databricks a désigné un sous-ensemble des bibliothèques prises en charge en tant que bibliothèques de niveau supérieur. Pour ces bibliothèques, Databricks offre une cadence de mise à jour plus rapide, en mettant à jour les versions les plus récentes des packages avec chaque version du runtime (conflits de dépendances). Databricks fournit également une prise en charge avancée, des tests et des optimisations incorporées pour les bibliothèques de niveau supérieur.
Pour obtenir la liste complète des bibliothèques de niveau supérieur et des autres bibliothèques fournies, consultez les notes de publication de Databricks Runtime ML.
Vous pouvez installer des bibliothèques supplémentaires afin de créer un environnement personnalisé pour votre notebook ou cluster.
- Pour mettre une bibliothèque à la disposition de tous les notebooks s’exécutant sur un cluster, créez une bibliothèque de clusters. Vous pouvez également utiliser un script init pour installer des bibliothèques sur des clusters lors de leur création.
- Pour installer une bibliothèque disponible uniquement pour une session de notebook spécifique, utilisez des bibliothèques Python avec étendue de notebook.