Principes directeurs pour le lakehouse
Les principes directeurs sont des règles de niveau zéro qui définissent et influencent votre architecture. Pour créer un data lakehouse qui aide votre entreprise à réussir maintenant et dans le futur, un consensus entre les parties prenantes de votre organisation est essentiel.
Organiser les données et offrir des données approuvées en tant que produits
L’organisation des données est essentielle pour la création d’un lac de données à haute valeur ajoutée destiné à être utilisé dans le décisionnel et dans le ML/l’IA. Traitez les données comme un produit, avec une définition, un schéma et un cycle de vie clairs. Assurez-vous de la cohérence sémantique et du fait que la qualité des données s’améliore de couche en couche, afin que les utilisateurs métier puissent faire entièrement confiance aux données.
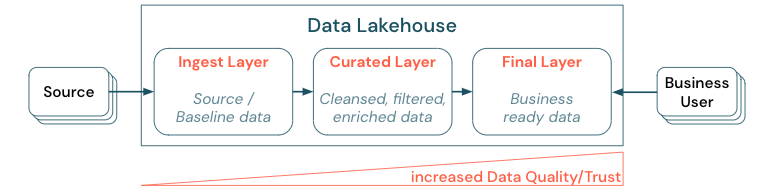
Organiser les données en établissant une architecture en couches (ou multitronçon) est une bonne pratique qui est critique pour le lakehouse, car elle permet aux équipes de données de structurer les données en fonction des niveaux de qualité, et de définir des rôles et des responsabilités pour chaque couche. Il est courant d’utiliser une approche multicouches telle que décrite ci-dessous :
- Couche d’ingestion : les données sources sont ingérées dans la première couche du lakehouse et doivent y être conservées. Quand toutes les données en aval sont créées à partir de la couche d’ingestion, la reconstruction des couches suivantes à partir de cette couche est possible si nécessaire.
- Couche organisée : l’objectif de la deuxième couche est de contenir des données nettoyées, affinées, filtrées et agrégées. L’objectif de cette couche est de fournir une base solide et fiable pour les analyses et les rapports sur l’ensemble des rôles et fonctions.
- Couche finale : la troisième couche est créée autour des besoins métier ou des besoins des projets ; elle fournit une vue différente en tant que produits de données pour d’autres unités métier ou d’autres projets, en préparant les données autour des besoins en matière de sécurité (par exemple des données anonymisées) ou en les optimisant pour les performances (avec des vues préagrégées). Les produits de données de cette couche sont considérés comme la vérité pour l’entreprise.
Les pipelines utilisant toutes les couches doivent s’assurer que les contraintes de qualité des données sont satisfaites, ce qui signifie que les données sont précises, complètes, accessibles et cohérentes à tout moment, même pendant des lectures et des écritures simultanées. La validation des nouvelles données se produit au moment de l’entrée des données dans la couche organisée, et les étapes ETL suivantes sont destinées à améliorer la qualité de ces données. La qualité des données doit s’améliorer au fur et à mesure que les données progressent à travers les couches : du point de vue de l’entreprise, la confiance dans les données va donc s’accroître.
Éliminer les silos de données et réduire au minimum le déplacement des données
Ne créez pas de copies d’un jeu de données avec des processus métier s’appuyant sur ces différentes copies. Les copies peuvent devenir des silos de données qui ne sont plus synchronisées, ce qui entraîne une baisse de la qualité de votre lac de données, et au final, des insights obsolètes ou incorrects. En outre, pour partager des données avec des partenaires externes, utilisez un mécanisme de partage d’entreprise qui permet un accès direct aux données de façon sécurisée.
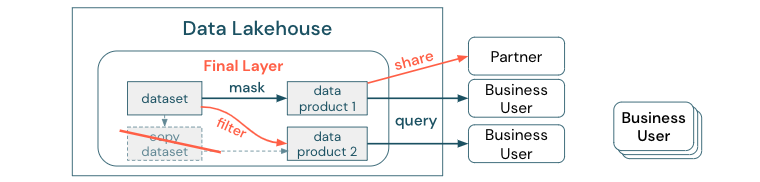
Pour faire une distinction claire entre une copie des données et un silo de données : une copie autonome ou désinvolte des données n’est pas dangereuse par elle-même. Elle est parfois nécessaire de stimuler l’agilité, l’expérimentation et l’innovation. Cependant, si ces copies deviennent opérationnelles avec les produits de données métier en aval qui en dépendent, elles deviennent des silos de données.
Pour empêcher la création de silos de données, les équipes de données tentent généralement de créer un mécanisme ou un pipeline de données pour maintenir toutes les copies synchronisées avec l’original. Étant donné qu’il est peu probable que cela se fasse de façon cohérente, la qualité des données finit par se dégrader. Cela peut également entraîner des coûts plus élevés et une perte significative de confiance par les utilisateurs. D’autre part, plusieurs cas d’usage métier nécessitent un partage de données avec des partenaires ou des fournisseurs.
Un aspect important est de partager de façon sécurisée et fiable la version la plus récente du jeu de données. Des copies du jeu de données ne sont souvent pas suffisantes, car elles se trouver rapidement désynchronisées. Au lieu de cela, les données doivent être partagées via des outils de partage des données d’entreprise.
Démocratiser la création de valeur via le libre-service
Le meilleur lac de données ne peut pas fournir une valeur ajoutée suffisante si les utilisateurs ne peuvent pas accéder facilement à la plateforme ou aux données pour leurs tâches du domaine du décisionnel et du ML/IA. Réduisez les obstacles à l’accès aux données et aux plateformes pour toutes les unités métier. Envisagez des processus de gestion des données allégés, et fournissez un accès en libre-service pour la plateforme et les données sous-jacentes.
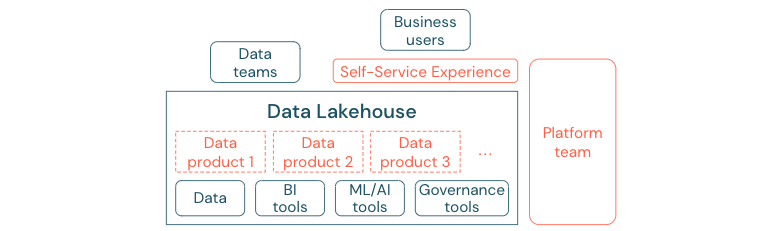
Les entreprises qui ont réussi à passer à une culture pilotée par les données vont prospérer. Cela signifie que chaque unité métier dérive ses décisions de modèles analytiques, ou de l’analyse de ses propres données ou de ses données fournies de façon centralisée. Pour les consommateurs, les données doivent être facilement découvrables et accessibles de façon sécurisée.
Un bon concept pour les producteurs de données est celui des « données en tant que produit » : les données sont offertes et gérées par une unité ou un partenaire métier comme un produit, et elles consommées par d’autres parties avec un contrôle approprié des autorisations. Au lieu s’appuyer sur une équipe centrale et des processus potentiellement lents pour le traitement des demandes, ces produits de données doivent être créés, offerts, découverts et consommés dans une expérience en libre-service.
Cependant, il n’y a pas que les données qui importent. La démocratisation des données nécessite les outils appropriés pour permettre à tout le monde de produire ou de consommer et de comprendre les données. Pour cela, vous avez besoin que le lakehouse de données soit une plateforme de données et d’IA moderne, qui fournisse l’infrastructure et les outils pour construire des produits de données sans dupliquer le travail nécessaire à mise en place d’une autre pile d’outils.
Adopter une stratégie de gouvernance des données à l’échelle de l’organisation
Les données sont une ressource critique pour toutes les organisations, mais vous ne pouvez pas accorder à tous les utilisateurs l’accès à toutes les données. L’accès aux données doit être géré de façon active. Le contrôle d’accès, l’audit et le suivi des traçabilités sont essentiels à l’utilisation correcte et sécurisée des données.
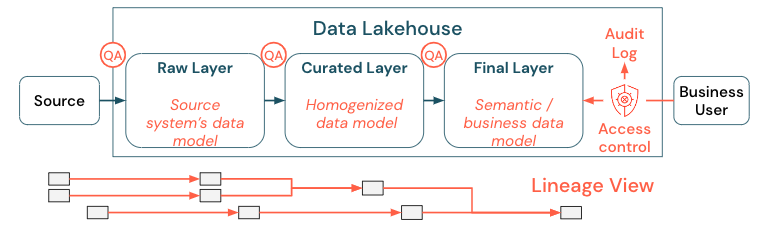
La gouvernance des données est un vaste sujet. Le lakehouse couvre les dimensions suivantes :
Qualité des données
Le prérequis le plus important pour obtenir des rapports, des résultats d’analyse et des modèles corrects et significatifs est que les données doivent être de grande qualité. L’assurance qualité (AQ) doit être présente à toutes les étapes du pipeline. Pour implémenter cela, il faut par exemple avoir des contrats de données, respecter des contrats SLA, garder les schémas stables et les faire évoluer de manière contrôlée.
Catalogue des données
Un autre aspect important est la découverte des données : les utilisateurs de tous les domaines métier, en particulier dans un modèle libre-service, doivent être en mesure de découvrir facilement les données pertinentes. Par conséquent, un lakehouse a besoin d’un catalogue de données qui couvre toutes les données pertinentes pour l’entreprise. Les principaux objectifs d’un catalogue de données sont les suivants :
- Garantir que le même concept métier est appelé et déclaré de façon uniforme dans l’entreprise. Vous pouvez le considérer comme un modèle sémantique dans la couche organisée et dans la couche finale.
- Suivre avec précision la traçabilité des données afin que les utilisateurs puissent expliquer comment ces données sont parvenues à leur forme et leur format actuels.
- Conserver des métadonnées de grande qualité, qui sont aussi importantes que les données elles-mêmes pour une utilisation appropriée des données.
Contrôle d’accès
Comme la création de valeur à partir des données du lakehouse se fait dans tous les domaines métier, le lakehouse doit être construit avec la sécurité comme principale préoccupation. Les entreprises peuvent avoir une stratégie d’accès aux données plus ouverte ou bien suivre strictement le principe des privilèges minimum. Indépendamment de cela, des contrôles d’accès aux données doivent être en place dans chaque couche. Il est important d’implémenter des schémas d’autorisation d’un niveau très fin dès le début (contrôle d’accès au niveau des colonnes et des lignes, contrôle d’accès en fonction du rôle ou de l’attribut). Les entreprises peuvent commencer par des règles moins strictes. Néanmoins, à mesure que la plate-forme du lac de données s’accroît, tous les mécanismes et processus d’un régime de sécurité plus sophistiqué doivent déjà être en place. En outre, tous les accès aux données du lakehouse doivent être gouvernés par des journaux d’audit depuis le tout début.
Encourager les interfaces ouvertes et les formats ouverts
Les interfaces ouvertes et les formats de données ouverts sont essentiels pour l’interopérabilité entre le lakehouse et d’autres outils. Elle simplifie également l’intégration avec des systèmes existants et ouvre un écosystème de partenaires qui ont déjà intégré leurs outils à la plateforme.
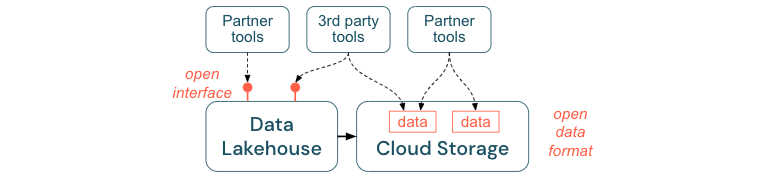
Les interfaces ouvertes sont essentielles pour permettre l’interopérabilité et pour éviter de dépendre d’un seul fournisseur. Traditionnellement, les fournisseurs ont créé des technologies propriétaires et des interfaces fermées qui limitaient la façon dont les entreprises peuvent stocker, traiter et partager des données.
La création d’interfaces ouvertes vous aide à construire pour le futur :
- Elle augmente la longévité et la portabilité des données, ce qui vous permet de les utiliser avec plus d’applications et pour plus de cas d’usage.
- Elle ouvre un écosystème de partenaires, qui peuvent rapidement tirer parti des interfaces ouvertes pour intégrer leurs outils à la plateforme du lakehouse.
Enfin, grâce à un alignement sur des formats standard ouverts pour les données, les coûts totaux seront considérablement inférieurs : vous pouvez accéder aux données directement sur le stockage cloud sans devoir les canaliser à travers une plateforme propriétaire qui peut entraîner des coûts élevés de sortie et de calcul.
Créer pour mettre à l’échelle et optimiser les performances et les coûts
Les données continuent inévitablement de croître et de devenir plus complexes. Pour équiper votre organisation pour les besoins futurs, votre lakehouse doit être en mesure de se mettre à l’échelle. Par exemple, vous devez être en mesure d’ajouter facilement de nouvelles ressources à la demande. Les coûts doivent être limités à la consommation réelle.
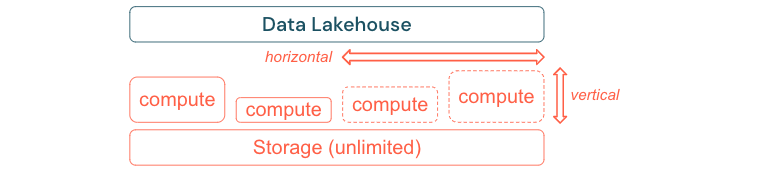
Les processus ETL Standard, les rapports métier et les tableaux de bord ont souvent des besoins en ressources prévisibles en termes de mémoire et de calcul. Cependant, les nouveaux projets, les tâches saisonnières ou des approches modernes comme l’apprentissage de modèles (attrition, prévision, maintenance) génèrent des pics de besoins en ressources. Pour permettre à une entreprise d’effectuer toutes ces charges de travail, une plateforme évolutive pour la mémoire et le calcul est nécessaire. De nouvelles ressources doivent être ajoutées facilement à la demande, et seule la consommation réelle doit générer des coûts. Une fois le pic passé, les ressources peuvent être à nouveau libérées et les coûts réduits en conséquence. Ceci est souvent appelé mise à l’échelle horizontale (moins ou plus de nœuds) et mise à l’échelle verticale (des nœuds plus grands ou plus petits).
La mise à l’échelle permet également aux entreprises d’améliorer les performances des requêtes en sélectionnant des nœuds avec plus de ressources ou des clusters avec plus de nœuds. Cependant, au lieu d’une mise à disposition permanente de machines et de clusters de grande taille, ceux-ci peuvent être provisionnés à la demande seulement pendant la durée nécessaire pour optimiser les performances globales en fonction des coûts. Un autre aspect de l’optimisation est le stockage par rapport aux ressources de calcul. Comme il n’existe pas de relation claire entre le volume des données et les charges de travail utilisant ces données (par exemple, utiliser seulement des parties des données ou effectuer des calculs intensifs sur de petites quantités de données), il est recommandé d’installer sur une plateforme d’infrastructure qui dissocie ressources de stockage et ressources de calcul.