Résoudre les problèmes et réparer les échecs de travaux
Supposez que vous avez été averti (par exemple au moyen d’une notification par e-mail, d’une solution de monitoring ou dans l’interface utilisateur des travaux Azure Databricks) qu’une tâche a échoué dans une exécution de votre travail Azure Databricks. Les étapes décrites dans cet article fournissent des conseils pour vous aider à identifier la cause de la défaillance, des suggestions pour résoudre les problèmes que vous trouvez et comment réparer les exécutions de travaux ayant échoué.
Identifier la cause de l’échec
Pour rechercher la tâche ayant échoué dans l’interface utilisateur des travaux Azure Databricks
Cliquez sur
 Exécutions de tâches dans la barre latérale.
Exécutions de tâches dans la barre latérale.Dans la colonne Nom, cliquez sur le nom d’un travail. L’onglet Exécutions montre les exécutions actives et les exécutions terminées, y compris les exécutions échouées. La vue matricielle dans l’onglet Exécutions montre un historique des exécutions pour le travail, notamment les exécutions abouties ou échouées de chaque tâche du travail. Une exécution de tâche peut ne pas avoir de succès, car elle a échoué ou a été ignorée, ou encore parce qu’une tâche dépendante a échoué. À l’aide de la vue matricielle, vous pouvez rapidement identifier les échecs de tâche pour votre exécution de travail.
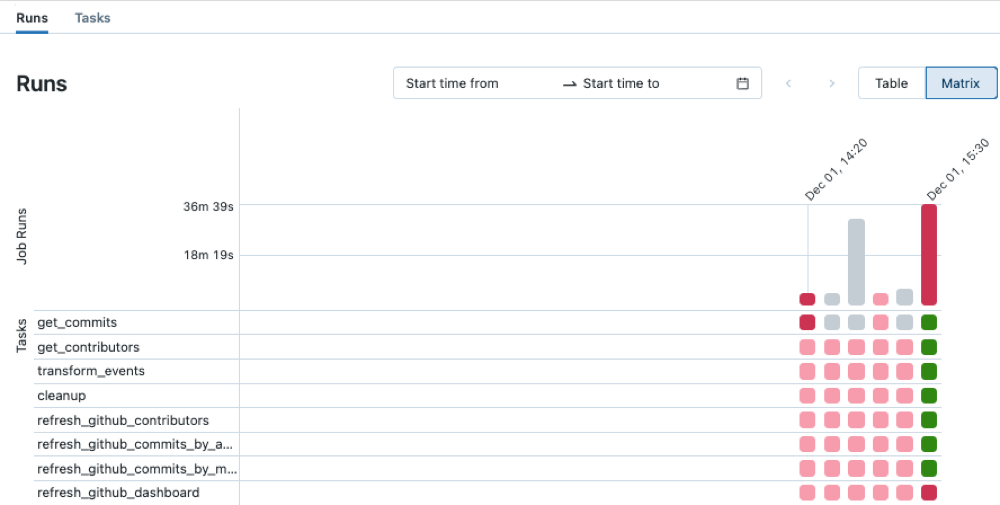
Pointez sur une tâche ayant échoué pour afficher les métadonnées associées. Ces métadonnées incluent les dates de début et de fin, le statut, les détails de durée du cluster et, dans certains cas, un message d’erreur.
Pour identifier la cause de l’échec, cliquez sur la tâche ayant échoué. La page Détails de l’exécution de la tâche s’affiche, avec la sortie de la tâche, le message d’erreur et les métadonnées associées.
Corriger la cause de l’échec
Votre tâche peut avoir échoué pour diverses raisons, par exemple un problème de qualité des données, une configuration incorrecte ou des ressources insuffisantes de calcul. Voici quelques suggestions d’étapes pour résoudre certaines causes courantes d’échecs de tâches :
- Si l’échec est lié à la configuration de la tâche, cliquez sur Modifier la tâche. La configuration de la tâche s’ouvre dans un nouvel onglet. Mettez à jour la configuration de la tâche en fonction des besoins, puis cliquez sur Enregistrer la tâche.
- Si le problème est lié à des ressources de cluster, par exemple une insuffisance d’instances, il existe plusieurs options :
- Si votre travail est configuré de façon à utiliser un cluster de travaux, réfléchissez à l’utilisation d’un cluster universel partagé.
- Modifiez la configuration du cluster. Cliquez sur Modifier la tâche. Dans le panneau Détails du travail, sous Calcul, cliquez sur Configurer pour configurer le cluster. Vous pouvez modifier le nombre de Workers, les types d’instance ou d’autres options de configuration de cluster. Vous pouvez également cliquer sur Échanger pour basculer vers un autre cluster disponible. Pour être sûr d’utiliser de manière optimale les ressources disponibles, passez en revue les bonnes pratiques en matière de configuration de cluster.
- Si nécessaire, demandez à un administrateur d’augmenter les quotas de ressources dans le compte cloud et la région où votre espace de travail est déployé.
- Si l’échec est dû au dépassement du nombre maximal d’exécutions simultanées :
- Attendez que les autres exécutions se terminent, ou
- Cliquez sur Modifier la tâche. Dans le panneau Détails du travail, cliquez sur Modifier les exécutions simultanées, entrez une nouvelle valeur pour Nombre maximal d’exécutions simultanées, puis cliquez sur Confirmer.
Dans certains cas, la cause d’une défaillance peut être en amont de votre travail, par exemple l’indisponibilité d’une source de données externe. Vous pouvez toujours tirer parti de la fonctionnalité de réparation d’exécution abordée dans la section suivante une fois le problème externe résolu.
Réexécuter les tâches échouées et ayant été ignorées
Après l’identification des raisons de l’échec, vous pouvez réparer les travaux multitâches en échec ou annulés en exécutant seulement le sous-ensemble des tâches qui ont échoué et toutes les tâches dépendantes. Comme que les tâches qui ont réussi et toutes les tâches qui en dépendent ne sont pas réexécutées, cette fonctionnalité réduit le temps et les ressources nécessaires à la récupération suite à l’échec des exécutions de travaux.
Vous pouvez modifier les paramètres du travail ou des tâches avant de réparer l’exécution du travail. Les tâches qui échouent sont réexécutées avec les paramètres actuels du travail et des tâches. Par exemple, si vous changez le chemin d’un notebook ou un paramètre du cluster, la tâche est réexécutée avec les paramètres du notebook ou du cluster mis à jour.
Affichez l’historique de toutes les exécutions de tâches dans la page Détails de l’exécution des tâches.
Remarque
- Si une ou plusieurs tâches partagent un cluster de travail, une exécution de réparation crée un cluster de travail. Par exemple, si l’exécution d’origine utilisait le cluster de travaux
my_job_cluster, la première exécution de réparation utilise le nouveau cluster de travauxmy_job_cluster_v1, ce qui vous permet de voir facilement le cluster et les paramètres du cluster utilisés par l’exécution initiale et toutes les exécutions de réparation. Les paramètres pourmy_job_cluster_v1sont identiques aux paramètres actuels pourmy_job_cluster. - La réparation est prise en charge seulement avec les travaux qui orchestrent deux tâches ou plus.
- La valeur Durée affichée dans l’onglet Exécutions représente le temps écoulé entre l’heure de début de la première exécution et l’heure de fin de la dernière exécution de réparation. Par exemple, si une exécution a échoué deux fois et a réussi à la troisième exécution, la durée inclut la durée des trois exécutions.
Pour réparer une exécution de travail en échec :
- Cliquez sur le lien pour l’exécution échouée dans la colonne Heure de début de la table des exécutions de travaux ou cliquez sur l’exécution échouée dans la vue matricielle. La page Détails d’exécution des travaux apparaît.
- Cliquez sur Exécution de réparation. La boîte de dialogue Réparer l’exécution du travail s’affiche, listant toutes les tâches en échec et toutes les tâches dépendantes qui seront réexécutées.
- Pour ajouter ou modifier des paramètres pour les tâches à réparer, entrez les paramètres dans la boîte de dialogue Réparer l’exécution du travail. Les paramètres que vous entrez dans la boîte de dialogue Réparer l’exécution du travail remplacent les valeurs existantes. Lors des exécutions de réparation suivantes, vous pouvez rétablir un paramètre à sa valeur d’origine en désactivant la clé et la valeur dans la boîte de dialogue Réparer l’exécution du travail.
- Cliquez sur Réparer l’exécution dans la boîte de dialogue Réparer l’exécution du travail.
- Une fois la réparation de l’exécution terminée, la vue matricielle est mise à jour avec une nouvelle colonne pour l’exécution réparée. Toutes les tâches ayant échoué qui étaient rouges doivent maintenant être vertes, ce qui indique une exécution réussie pour l’ensemble de votre travail.
Afficher et gérer des échecs de travaux continus
Lorsque des échecs consécutifs d’un travail continu dépassent un seuil, les travaux Azure Databricks utilisent un backoff exponentiel pour une nouvelle tentative du travail. Lorsqu’un travail se trouve dans l’état backoff exponentiel, un message dans le panneau Détails du travail affiche des informations, notamment :
- Nombre de défaillances consécutives.
- La période pendant laquelle le travail doit s’exécuter sans erreur pour être considéré comme réussi.
- La période avant la nouvelle tentative, si aucune exécution n’est active.
Pour annuler l’exécution active, réinitialiser la période de nouvelle tentative et démarrer une nouvelle exécution du travail, cliquez sur Redémarrer l’exécution.