Orchestrer des tâches Azure Databricks avec Apache Airflow
Cet article décrit la prise en charge d’Apache Airflow pour orchestrer des pipelines de données avec Azure Databricks, contient des instructions pour installer et configurer Airflow localement, et fournit un exemple de déploiement et d’exécution d’un workflow Azure Databricks avec Airflow.
Orchestration des travaux dans un pipeline de données
Le développement et le déploiement d’un pipeline de traitement des données nécessite souvent la gestion de dépendances complexes entre les tâches. Par exemple, un pipeline peut lire les données d’une source, nettoyer ces données, transformer les données nettoyées et écrire les données transformées dans une cible. Vous avez également besoin de la prise en charge des tests, de la planification et de la résolution des erreurs lorsque vous opérationnalisez un pipeline.
Les systèmes de workflow résolvent ces problèmes en vous permettant de définir des dépendances entre les tâches, de planifier le moment de l’exécution des pipelines et de monitorer les workflows. Apache Airflow est une solution open source conçue pour la gestion et la planification des pipelines de données. Airflow représente les pipelines de données sous forme de graphes orientés acycliques (DAG) d’opérations. Vous définissez un workflow dans un fichier Python, puis Airflow gère la planification et l’exécution. La connexion d’Airflow à Azure Databricks vous permet de tirer parti du moteur Spark optimisé qui est fourni par Azure Databricks avec les fonctionnalités de planification d’Airflow.
Spécifications
- L’intégration entre Airflow et Azure Databricks nécessite la version 2.5.0 d’Airflow ou une version ultérieure. Les exemples de cet article sont testés avec la version 2.6.1.
- Airflow nécessite Python 3.8, 3.9, 3.10 ou 3.11. Les exemples de cet article sont testés avec Python 3.8.
- Les instructions pour installer et exécuter Airflow présentées dans cet article nécessitent pipenv pour créer un environnement virtuel Python.
Opérateurs Airflow pour Databricks
Un DAG d’Airflow est composé de tâches, où chaque tâche exécute un opérateur d’Airflow. Les opérateurs d’Airflow prenant en charge l’intégration à Databricks sont implémentés dans le fournisseur Databricks.
Le fournisseur Databricks inclut des opérateurs pour exécuter un certain nombre de tâches sur un espace de travail Azure Databricks, notamment l’importation de données dans une table, l’exécution de requêtes SQL et l’utilisation de dossiers Git Databricks.
Le fournisseur Databricks implémente deux opérateurs pour déclencher des travaux :
- DatabricksRunNowOperator nécessite un travail Azure Databricks existant et utilise la requête d’API POST /api/2.1/jobs/run-now pour déclencher une exécution. Databricks recommande l’utilisation de
DatabricksRunNowOperator, car il réduit le nombre de duplications des définitions de travaux. En outre, les exécutions de travaux déclenchées avec cet opérateur peuvent être trouvées dans l’interface utilisateur des travaux. - DatabricksSubmitRunOperator ne nécessite pas de travail Azure Databricks existant, et il utilise la requête d’API POST /api/2.1/jobs/runs/submit pour envoyer la spécification du travail et déclencher une exécution.
Pour créer un travail Azure Databricks ou réinitialiser un travail existant, le fournisseur Databricks implémente le DatabricksCreateJobsOperator. Le DatabricksCreateJobsOperator utilise les requêtes d’API POST /api/2.1/jobs/create et POST /api/2.1/jobs/reset. Vous pouvez utiliser le DatabricksCreateJobsOperator avec le DatabricksRunNowOperator pour créer et exécuter un travail.
Remarque
L’utilisation des opérateurs Databricks pour déclencher un travail nécessite la fourniture d’informations d’identification dans la configuration de la connexion Databricks. Consultez Créer un jeton d’accès personnel Azure Databricks pour Airflow.
Les opérateurs Databricks Airflow écrivent l’URL de la page d’exécution des travaux dans les journaux Airflow toutes les polling_period_seconds (la valeur par défaut est de 30 secondes). Pour plus d’informations, consultez le package apache-airflow-providers-databricks sur le site web Airflow.
Installer l’intégration entre Airflow et Azure Databricks localement
Pour installer Airflow et le fournisseur Databricks localement pour les tests et le développement, procédez comme suit. Pour obtenir d’autres options d’installation Airflow, notamment la création d’une installation de production, consultez Installation dans la documentation sur Airflow.
Ouvrez un terminal et exécutez les commandes suivantes :
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Remplacez <firstname>, <lastname> et <email> par votre nom d’utilisateur et votre e-mail. Vous serez invité à entrer un mot de passe pour l’utilisateur administrateur. Veillez à enregistrer ce mot de passe, car il est nécessaire de se connecter à l’interface utilisateur Airflow.
Ce script effectue les étapes suivantes :
- Il crée un répertoire nommé
airflowet il remplace le répertoire actuel par celui-ci. - Il utilise
pipenvpour créer et générer un environnement virtuel Python. Databricks recommande l’utilisation d’un environnement virtuel Python pour isoler les versions de package et les dépendances de code dans cet environnement. Cette isolation permet de réduire les incompatibilités de versions de package et les collisions de dépendance de code inattendues. - Il initialise une variable d’environnement nommée
AIRFLOW_HOMEdéfinie sur le chemin du répertoireairflow. - Il Installe les packages de fournisseur Airflow et Azure Databricks.
- Il crée un répertoire
airflow/dags. Airflow utilise le répertoiredagspour stocker les définitions des DAG. - Il initialise une base de données SQLite qu’Airflow utilisera pour effectuer le suivi des métadonnées. Dans un déploiement de production Airflow, vous configurez Airflow avec une base de données standard. La base de données SQLite et la configuration par défaut de votre déploiement Airflow sont initialisées dans le répertoire
airflow. - Il crée un utilisateur administrateur pour Airflow.
Conseil
Pour confirmer l’installation du fournisseur Databricks, exécutez la commande suivante dans le répertoire d’installation Airflow :
airflow providers list
Démarrer le serveur web et le planificateur Airflow
Le serveur web Airflow est nécessaire pour afficher l’interface utilisateur Airflow. Pour démarrer le serveur web, ouvrez un terminal dans le répertoire d’installation Airflow et exécutez les commandes suivantes :
Remarque
Si le serveur web Airflow ne parvient pas à démarrer en raison d’un conflit de ports, vous pouvez modifier le port par défaut dans la configuration Airflow.
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
Le planificateur est le composant d’Airflow qui planifie les DAG. Pour démarrer le planificateur, ouvrez un nouveau terminal dans le répertoire d’installation Airflow et exécutez les commandes suivantes :
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Tester l’installation Airflow
Pour vérifier l’installation Airflow, vous pouvez exécuter l’un des exemples de DAG inclus dans Airflow :
- Dans une fenêtre de navigateur, ouvrez
http://localhost:8080/home. Connectez-vous à l’interface utilisateur Airflow avec le nom d’utilisateur et le mot de passe que vous avez créés lors de l’installation d’Airflow. La page des DAG d’Airflow s’affiche. - Cliquez sur le bouton bascule Pause/Unpause DAG (Suspendre/Reprendre le DAG) pour reprendre l’exécution de l’un des exemples de DAG, par exemple,
example_python_operator. - Déclenchez l’exemple de DAG en cliquant sur le bouton Déclencher le DAG.
- Cliquez sur le nom du DAG pour afficher les détails, y compris l’état d’exécution du DAG.
Créer un jeton d’accès personnel Azure Databricks pour Airflow
Airflow se connecte à Databricks à l’aide d’un jeton d’accès personnel (PAT) Azure Databricks. Pour créer un pater, suivez les étapes décrites dans les jetons d’accès personnels Azure Databricks pour les utilisateurs de l’espace de travail.
Remarque
En guise de bonne pratique de sécurité, quand vous vous authentifiez avec des outils, systèmes, scripts et applications automatisés, Databricks recommande d’utiliser des jetons d’accès personnels appartenant à des principaux de service et non des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Vous pouvez également vous authentifier auprès d’Azure Databricks à l’aide d’un jeton Microsoft Entra ID. Consultez Connexion Databricks dans la documentation Airflow.
Configurer une connexion Azure Databricks
Votre installation Airflow contient une connexion par défaut pour Azure Databricks. Pour mettre à jour la connexion afin de vous connecter à votre espace de travail à l’aide du jeton d’accès personnel que vous avez créé ci-dessus :
- Dans une fenêtre de navigateur, ouvrez
http://localhost:8080/connection/list/. Si vous êtes invité à vous connecter, entrez votre nom d’utilisateur et votre mot de passe administrateur. - Sous ID de connexion, recherchez databricks_default, puis cliquez sur le bouton Modifier l’enregistrement.
- Remplacez la valeur du champ Hôte par le nom de l’instance de l’espace de travail de votre déploiement Azure Databricks, par exemple,
https://adb-123456789.cloud.databricks.com. - Dans le champ Mot de passe, entrez votre jeton d’accès personnel Azure Databricks.
- Cliquez sur Enregistrer.
Si vous utilisez un jeton Microsoft Entra ID, consultez Connexion Databricks dans la documentation Airflow pour plus d’informations sur la configuration de l’authentification.
Exemple : créer un DAG Airflow pour exécuter un travail Azure Databricks
L’exemple suivant montre comment créer un déploiement Airflow simple qui s’exécute sur votre ordinateur local et déploie un exemple de DAG pour déclencher des exécutions dans Azure Databricks. Dans cet exemple, vous allez :
- Créer un notebook et ajouter du code pour afficher un message d’accueil basé sur un paramètre configuré.
- Créer un travail Azure Databricks avec une seule tâche qui exécute le notebook.
- Configurer une connexion entre Airflow et votre espace de travail Azure Databricks.
- Créer un DAG Airflow pour déclencher le travail du notebook. Vous définissez le DAG dans un script Python à l’aide de
DatabricksRunNowOperator. - Utilisez l’interface utilisateur Airflow pour déclencher le DAG et afficher l’état d’exécution.
Créer un notebook
Cet exemple utilise un notebook contenant deux cellules :
- La première cellule contient un widget de texte Databricks Utilities qui définit une variable nommée
greetinget définie sur la valeurworldpar défaut. - La deuxième cellule affiche la valeur de la variable
greetingpréfixée avechello.
Pour créer le notebook :
Accédez à votre espace de travail Azure Databricks, cliquez sur
 Nouveau dans la barre latérale, puis sélectionnez Notebook.
Nouveau dans la barre latérale, puis sélectionnez Notebook.Attribuez un nom à votre notebook, tel que Hello Airflow, et vérifiez que la langue par défaut est défini sur Python.
Copiez le code Python suivant et collez-le dans la première cellule du notebook.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")Ajoutez une nouvelle cellule en dessous de la première cellule, puis copiez-collez le code Python suivant dans la nouvelle cellule :
print("hello {}".format(greeting))
Créer un travail
Cliquez sur
 Workflows dans la barre latérale.
Workflows dans la barre latérale.Cliquez sur
 .
.L’onglet Tâches apparaît avec la boîte de dialogue de création de tâche.
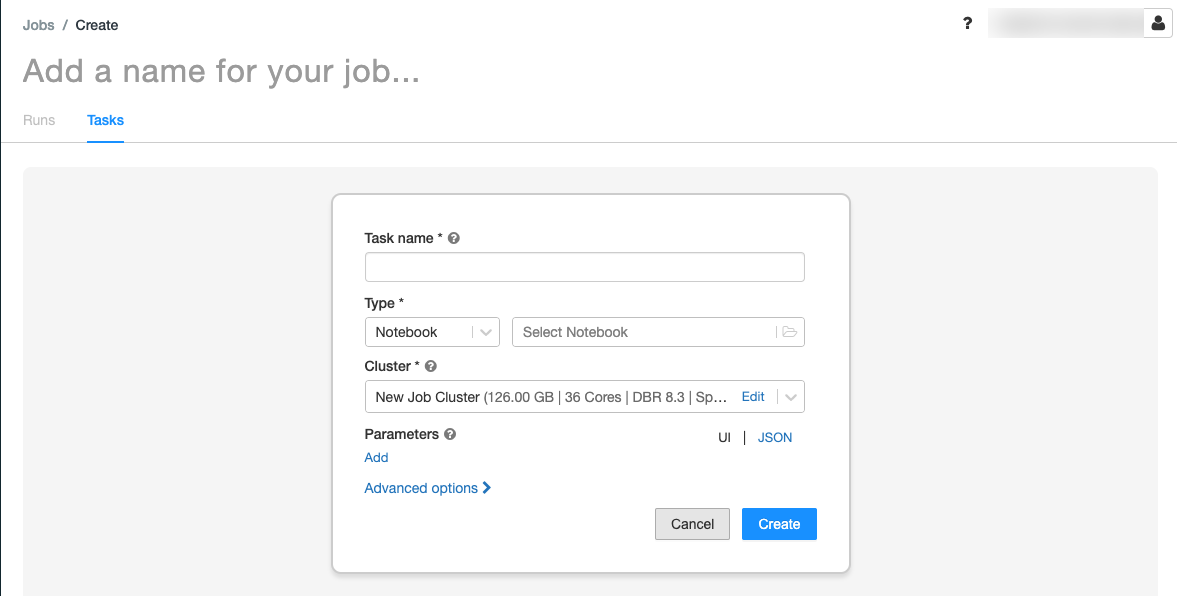
Remplacez Add a name for your job… (Ajoutez un nom pour votre travail) par le nom de votre travail.
Dans le champ Task name (Nom de la tâche), entrez un nom pour la tâche, par exemple, greeting-task.
Dans le menu déroulant Type, sélectionnez Notebook .
Dans le menu déroulant Source, sélectionnez Espace de travail.
Cliquez sur la zone de texte Chemins d’accès et utilisez l’explorateur de fichiers pour rechercher le notebook que vous avez créé, cliquez sur le nom du notebook, puis cliquez sur Confirmer.
Cliquez sur Add (Ajouter) sous Parameters (Paramètres). Dans le champ Key, entrez
greeting. Dans le champ Value, entrezAirflow user.Cliquez sur Create task.
Dans le panneau Détails du travail, copiez la valeur ID de travail. Cette valeur est nécessaire pour déclencher la tâche à partir d’Airflow.
Exécuter le travail
Pour tester votre nouveau travail dans l’interface utilisateur des travaux Azure Databricks, cliquez sur  dans le coin supérieur droit. Une fois l’exécution terminée, vous pouvez vérifier la sortie en affichant les détails de l’exécution du travail.
dans le coin supérieur droit. Une fois l’exécution terminée, vous pouvez vérifier la sortie en affichant les détails de l’exécution du travail.
Créer un DAG Airflow
Vous définissez un DAG Airflow dans un fichier Python. Pour créer un DAG dans le but de déclencher l’exemple de travail de notebook :
Dans un éditeur de texte ou un IDE, créez un fichier nommé
databricks_dag.pyavec le contenu suivant :from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )Remplacez
JOB_IDpar la valeur de l’ID de travail enregistrée précédemment.Enregistrez le fichier dans le répertoire
airflow/dags. Airflow lit et installe automatiquement les fichiers DAG stockés dansairflow/dags/.
Installer et vérifier le DAG dans Airflow
Pour déclencher et vérifier le DAG dans l’interface Airflow :
- Dans une fenêtre de navigateur, ouvrez
http://localhost:8080/home. L’écran des DAG Airflow s’affiche. - Localisez
databricks_dag, puis cliquez sur le bouton bascule Pause/Unpause DAG (Suspendre/Reprendre le DAG) pour reprendre l’exécution du DAG. - Déclenchez le DAG en cliquant sur le bouton Déclencher le DAG.
- Cliquez sur une exécution dans la colonne Exécutions pour afficher l’état et les détails de l’exécution.