Recommandations attendues et modèles avancés
Cet article contient des recommandations pour l’implémentation des attentes à grande échelle et des exemples de modèles avancés pris en charge par les attentes. Ces modèles utilisent plusieurs jeux de données conjointement avec les attentes et exigent que les utilisateurs comprennent la syntaxe et la sémantique des vues matérialisées, des tables de diffusion en continu et des attentes.
Pour obtenir une vue d’ensemble de base du comportement et de la syntaxe des attentes, consultez Gérer la qualité des données avec des attentes de pipeline.
Attentes portables et réutilisables
Databricks recommande les meilleures pratiques suivantes lors de l’implémentation des attentes pour améliorer la portabilité et réduire les charges de maintenance :
| Recommandation | Impact |
|---|---|
| Stockez les définitions d’attente séparément de la logique de pipeline. | Appliquez facilement des attentes à plusieurs jeux de données ou pipelines. Mettez à jour, auditez et gérez les attentes sans modifier le code source du pipeline. |
| Ajoutez des balises personnalisées pour créer des groupes d’attentes associées. | Filtrez les attentes en fonction des étiquettes. |
| Appliquez des attentes de manière cohérente dans des jeux de données similaires. | Utilisez les mêmes attentes entre plusieurs jeux de données et pipelines pour évaluer une logique identique. |
Les exemples suivants illustrent l’utilisation d’une table delta ou d’un dictionnaire pour créer un référentiel d’attente central. Les fonctions Python personnalisées appliquent ensuite ces attentes aux jeux de données dans un exemple de pipeline :
Delta Table
L’exemple suivant crée une table nommée rules pour gérer les règles :
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
L’exemple Python suivant définit les attentes de qualité des données en fonction des règles de la table rules. La fonction get_rules() lit les règles de la table rules et retourne un dictionnaire Python contenant des règles correspondant à l’argument tag passé à la fonction.
Dans cet exemple, le dictionnaire est appliqué en utilisant les décorateurs @dlt.expect_all_or_drop() pour imposer des contraintes de qualité des données.
Par exemple, tous les enregistrements qui échouent aux règles marquées avec validity sont supprimés de la table raw_farmers_market :
import dlt
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Python Module
L’exemple suivant crée un module Python pour gérer les règles. Pour cet exemple, stockez ce code dans un fichier nommé rules_module.py dans le même dossier que le notebook utilisé comme code source pour le pipeline :
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
L’exemple Python suivant définit les attentes de qualité des données en fonction des règles définies dans le fichier rules_module.py. La fonction get_rules() retourne un dictionnaire Python contenant des règles correspondant à l’argument tag passé.
Dans cet exemple, le dictionnaire est utilisé avec des décorateurs @dlt.expect_all_or_drop() pour imposer des contraintes de qualité des données.
Par exemple, tous les enregistrements qui échouent aux règles marquées avec validity sont supprimés de la table raw_farmers_market :
import dlt
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dlt.table
@dlt.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dlt.table
@dlt.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
dlt.read("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Validation du nombre de lignes
L’exemple suivant valide l’égalité des nombres de lignes entre table_a et table_b pour vérifier qu’aucune donnée n’est perdue pendant les transformations :
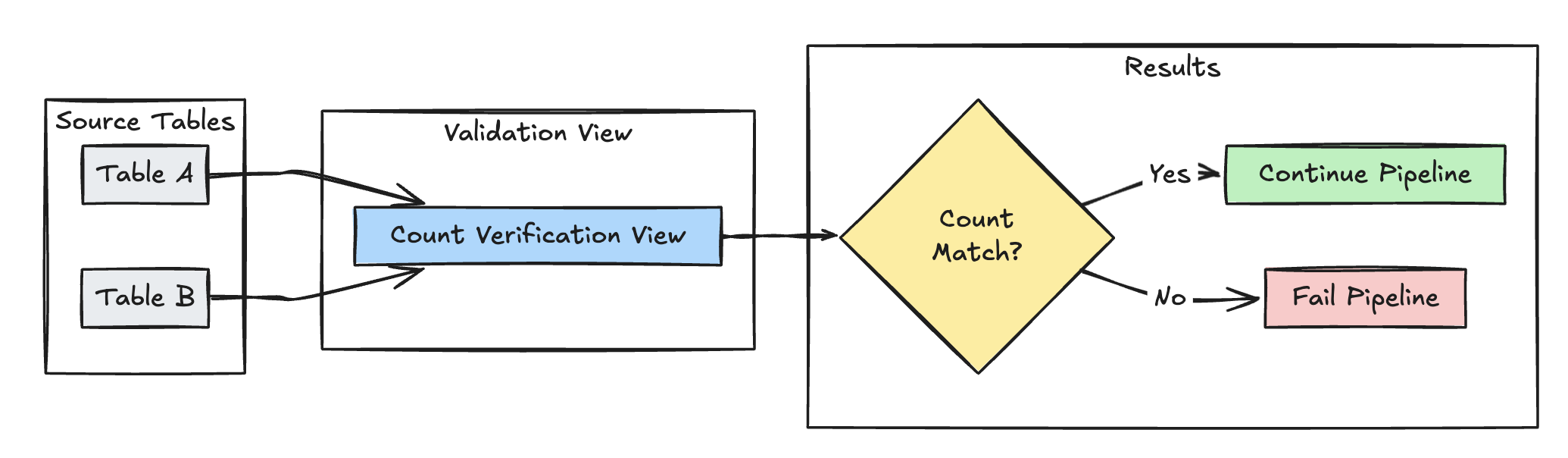
Python
@dlt.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dlt.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Détection des enregistrements manquants
L’exemple suivant vérifie que tous les enregistrements attendus sont présents dans la table report :
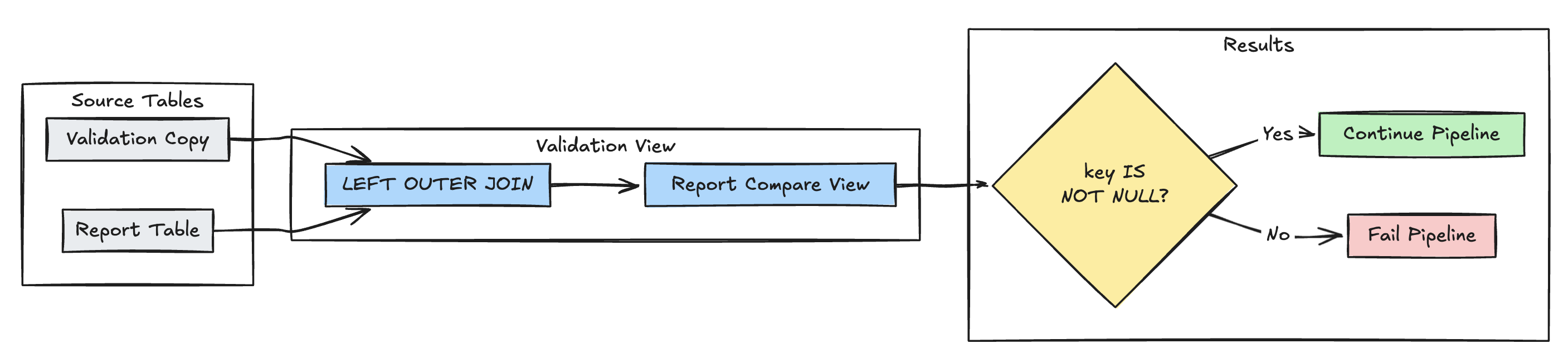
Python
@dlt.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dlt.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
dlt.read("validation_copy").alias("v")
.join(
dlt.read("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
Unicité de la clé primaire
L’exemple suivant valide les contraintes de clé primaire entre les tables :
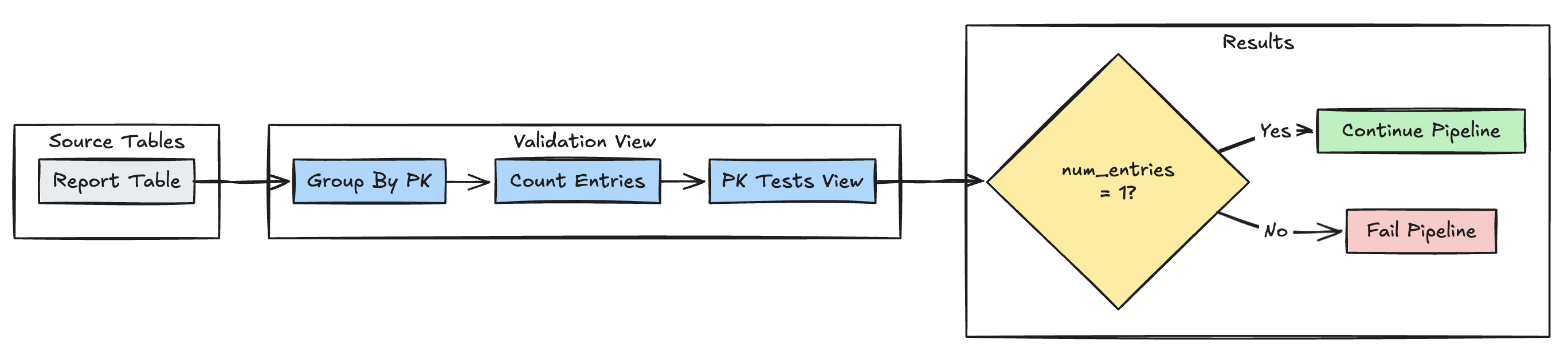
Python
@dlt.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dlt.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
dlt.read("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Modèle d’évolution de schéma
L’exemple suivant montre comment gérer l’évolution du schéma pour des colonnes supplémentaires. Utilisez ce modèle lorsque vous migrez des sources de données ou gérez plusieurs versions des données en amont, ce qui garantit la compatibilité descendante tout en appliquant la qualité des données :
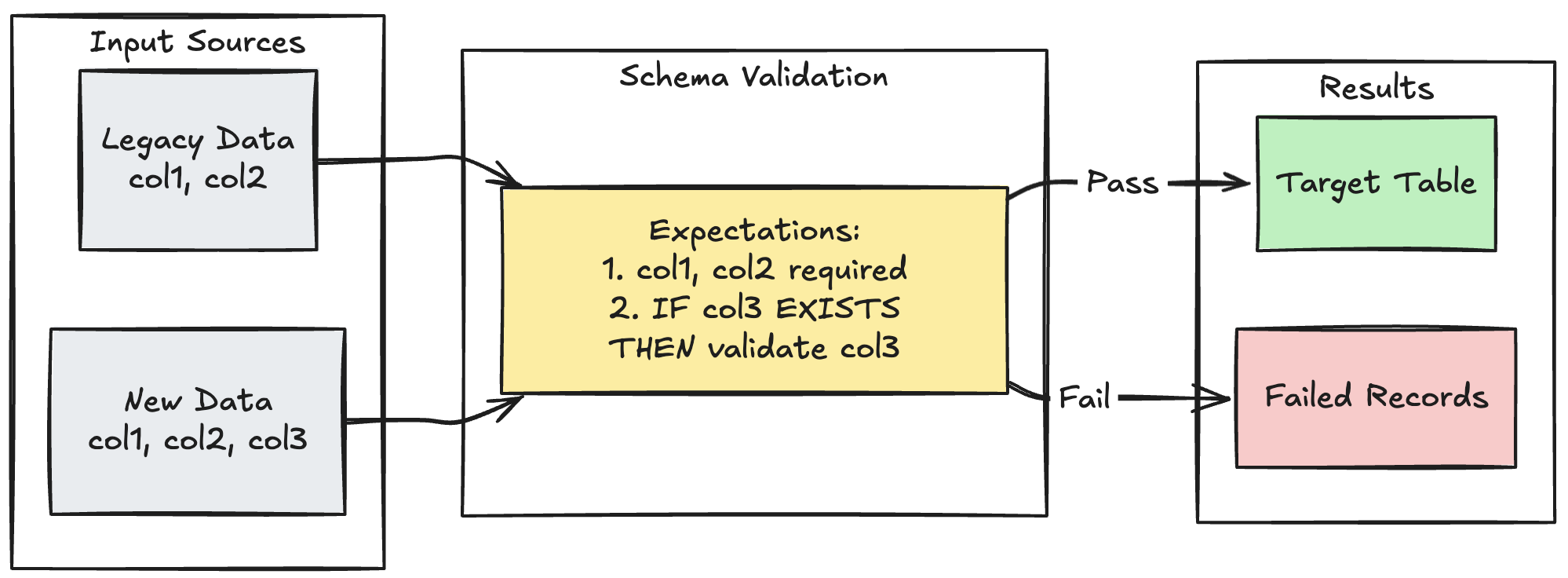
Python
@dlt.table
@dlt.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
Modèle de validation basé sur une plage
L’exemple suivant montre comment valider de nouveaux points de données par rapport aux plages statistiques historiques, ce qui permet d’identifier les valeurs hors norme et les anomalies dans votre flux de données :
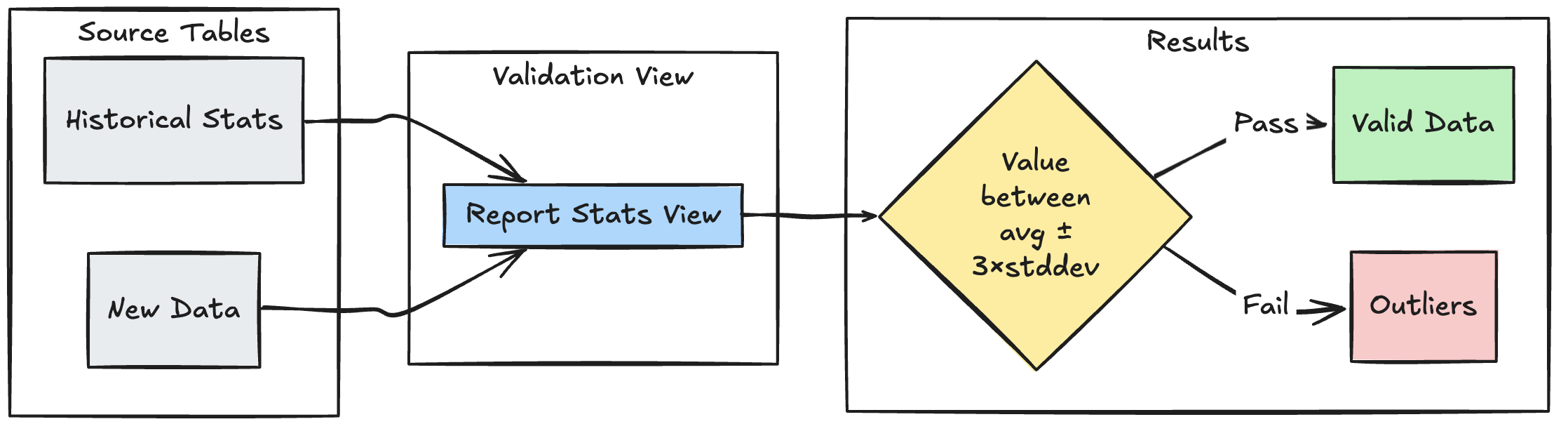
Python
@dlt.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dlt.table
@dlt.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return dlt.read("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
Mettre en quarantaine des enregistrements non valides
Ce modèle combine les attentes avec les tables et vues temporaires pour suivre les métriques de qualité des données pendant les mises à jour du pipeline et activer des chemins de traitement distincts pour les enregistrements valides et non valides dans les opérations en aval.
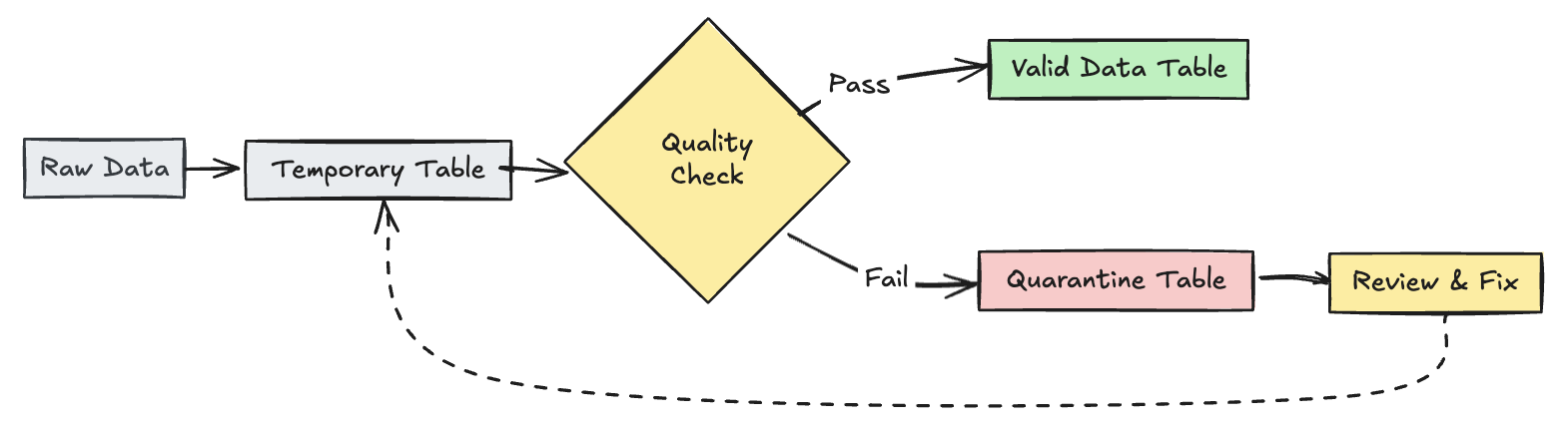
Python
import dlt
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dlt.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dlt.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dlt.expect_all(rules)
def trips_data_quarantine():
return (
dlt.readStream("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dlt.view
def valid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=false")
@dlt.view
def invalid_trips_data():
return dlt.read("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;