Qu’est-ce que Delta Live Tables ?
Remarque
Delta Live Tables nécessite le plan Premium. Contactez l'équipe de votre compte Databricks pour plus d'informations.
Delta Live Tables est une infrastructure déclarative conçue pour simplifier la création de pipelines d’extraction, de transformation et de chargement fiables et gérables. Vous spécifiez les données à ingérer et comment la transformer, et Delta Live Tables automatise les aspects clés de la gestion de votre pipeline de données, notamment l’orchestration, la gestion des calculs, la surveillance, l’application de la qualité des données et la gestion des erreurs.
Delta Live Tables repose sur Apache Spark, mais au lieu de définir vos pipelines de données à l’aide d’une série de tâches Apache Spark distinctes, vous définissez des tables de diffusion en continu et des vues matérialisées que le système doit créer et les requêtes nécessaires pour remplir et mettre à jour ces tables de diffusion en continu et les vues matérialisées.
Pour en savoir plus sur les avantages de la création et de l’exécution de vos pipelines ETL avec Delta Live Tables, consultez la page du produit Delta Live Tables.
avantages des tables dynamiques Delta par rapport à Apache Spark
Apache Spark est un moteur d’analytique unifiée open source polyvalent, y compris ETL. Delta Live Tables s’appuie sur Spark pour traiter des tâches de traitement ETL spécifiques et courantes. Delta Live Tables peut accélérer considérablement votre chemin de production lorsque vos besoins incluent ces tâches de traitement, notamment :
- Ingestion de données à partir de sources classiques.
- Transformation incrémentielle des données.
- Exécution de la capture des changements de données (CDC).
Toutefois, les tables dynamiques Delta ne conviennent pas à l’implémentation de certains types de logique procédurale. Par exemple, les exigences de traitement telles que l’écriture dans une table externe ou l’inclusion d’une condition qui fonctionne sur un stockage de fichiers externe ou des tables de base de données ne peuvent pas être effectuées dans le code définissant un jeu de données Delta Live Tables. Pour implémenter le traitement non pris en charge par Delta Live Tables, Databricks recommande d’utiliser Apache Spark ou d’inclure le pipeline dans un travail Databricks qui effectue le traitement dans une tâche de travail distincte. Consultez Tâche de pipelines Delta Live Tables pour les travaux.
Le tableau suivant compare Delta Live Tables avec Apache Spark :
| Capacité | Delta Live Tables | Apache Spark |
|---|---|---|
| Transformations de données | Vous pouvez transformer des données à l’aide de SQL ou Python. | Vous pouvez transformer des données à l’aide de SQL, Python, Scala ou R. |
| Traitement incrémentiel des données | De nombreuses transformations de données sont automatiquement traitées de manière incrémentielle. | Vous devez déterminer quelles données sont nouvelles afin de pouvoir les traiter de manière incrémentielle. |
| Orchestration | Les transformations sont automatiquement orchestrées dans l’ordre approprié. | Vous devez vous assurer que différentes transformations s’exécutent dans l’ordre correct. |
| Parallélisme | Toutes les transformations sont exécutées avec le niveau correct de parallélisme. | Vous devez utiliser des threads ou un orchestrateur externe pour exécuter des transformations non liées en parallèle. |
| Gestion des erreurs | Les échecs sont automatiquement retentés. | Vous devez décider comment gérer les erreurs et les nouvelles tentatives. |
| Surveillance | Les métriques et les événements sont enregistrés automatiquement. | Vous devez écrire du code pour collecter des métriques sur l’exécution ou la qualité des données. |
concepts clés des tables dynamiques Delta
L’illustration suivante montre les composants importants d’un pipeline Delta Live Tables, suivis d’une explication de chacun d’eux.
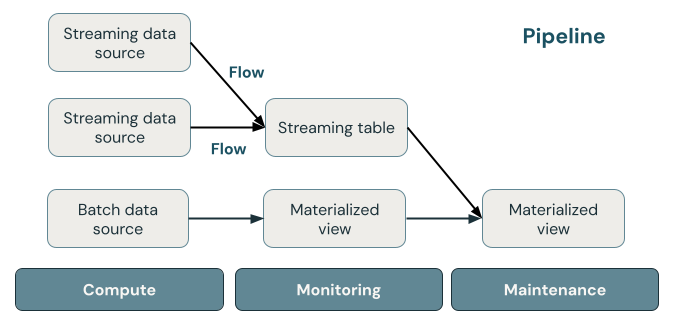
Table de diffusion en continu
Une table de diffusion en continu est une table Delta qui a un ou plusieurs flux écrits dans celui-ci. Les tables de diffusion en continu sont couramment utilisées pour l’ingestion, car elles traitent exactement une fois les données d’entrée et peuvent traiter de grands volumes de données d’ajout uniquement. Les tables de diffusion en continu sont également utiles pour la transformation à faible latence des flux de données à volume élevé.
Vue matérialisée
Une vue matérialisée est une vue qui contient des enregistrements précomputés en fonction de la requête qui définit la vue matérialisée. Les enregistrements de la vue matérialisée sont automatiquement mis à jour par Delta Live Tables selon le programme de mise à jour ou les déclencheurs du pipeline. Chaque fois qu’une vue matérialisée est mise à jour, elle est garantie d’avoir les mêmes résultats que l’exécution de la requête de définition sur les données les plus récentes disponibles. Toutefois, cela se fait souvent sans recalculer le résultat complet à partir de zéro, en utilisant l’actualisation incrémentielle. Les vues matérialisées sont couramment utilisées pour les transformations.
Les vues
Toutes les vues dans Azure Databricks calculent les résultats à partir de jeux de données sources au fur et à mesure qu’ils sont interrogés, en tirant parti des optimisations de la mise en cache lorsqu’elles sont disponibles. Delta Live Tables ne publie pas de vues dans le catalogue. Les vues peuvent donc être référencées uniquement dans le pipeline dans lequel elles sont définies. Les vues sont utiles en tant que requêtes intermédiaires qui ne doivent pas être exposées aux utilisateurs finaux ou aux systèmes. Databricks recommande d’utiliser des vues pour appliquer des contraintes de qualité des données ou transformer et enrichir des jeux de données qui alimentent plusieurs requêtes en aval.
Pipeline
Un pipeline est une collection de tables de streaming et de vues matérialisées mises à jour ensemble. Ces tables de streaming et vues matérialisées sont déclarées dans des fichiers sources Python ou SQL. Un pipeline inclut également une configuration qui définit le calcul utilisé pour mettre à jour les tables de streaming et les vues matérialisées lors de l’exécution du pipeline. Similaire à la façon dont un modèle Terraform définit l’infrastructure dans votre compte cloud, un pipeline Delta Live Tables définit les jeux de données et les transformations pour votre traitement des données.
Comment les jeux de données Delta Live Tables traitent-ils les données ?
La table suivante décrit comment les vues matérialisées, les tables de diffusion en continu et les vues traitent les données :
| Type de jeu de données | Comment les enregistrements sont-ils traités via des requêtes définies ? |
|---|---|
| Table de diffusion en continu | Chaque enregistrement est traité exactement une seule fois. Cela suppose une source avec ajout uniquement. |
| Vue matérialisée | Les enregistrements sont traités en fonction des besoins pour retourner des résultats précis pour l’état actuel des données. Les vues matérialisées doivent être utilisées pour les tâches de traitement des données telles que les transformations, les agrégations ou les requêtes lentes de pré-calcul et les calculs fréquemment utilisés. |
| Affichage | Les enregistrements sont traités chaque fois que la vue est interrogée. Utilisez des vues pour les transformations intermédiaires et les contrôles de qualité des données qui ne doivent pas être publiés dans des jeux de données publics. |
Déclarer vos premiers jeux de données dans Delta Live Tables
Delta Live Tables introduit une nouvelle syntaxe pour Python et SQL. Pour découvrir les principes de base de la syntaxe de pipeline, consultez Développer du code de pipeline avec Python et Développer du code de pipeline avec SQL.
Remarque
Delta Live Tables sépare les définitions des jeux de données du traitement des mises à jour, et les notebooks Delta Live Tables ne sont pas destinés à une exécution interactive.
Comment configurer des pipelines Delta Live Tables ?
Les paramètres des pipelines Delta Live Tables se répartissent en deux grandes catégories :
- Configurations qui définissent une collection de notebooks ou de fichiers (appelés code source) qui utilisent la syntaxe Delta Live Tables pour déclarer des jeux de données.
- Configurations qui contrôlent l’infrastructure de pipeline, la gestion des dépendances, le traitement des mises à jour et l’enregistrement des tables dans l’espace de travail.
La plupart des configurations sont facultatives, mais certaines nécessitent une attention particulière, en particulier lors de la configuration des pipelines de production. Ces options en question sont les suivantes :
- Pour rendre les données disponibles en dehors du pipeline, vous devez déclarer un schéma cible pour publier dans le metastore Hive ou un catalogue cible et un schéma cible pour publier dans Unity Catalog.
- Les autorisations d’accès aux données sont configurées via le cluster utilisé pour l’exécution. Vérifiez que votre cluster dispose des autorisations appropriées configurées pour les sources de données et l'emplacement de stockage cible , si spécifié.
Pour plus d’informations sur l’utilisation de Python et SQL pour écrire du code source pour les pipelines, consultez Informations de référence sur le langage SQL dans Delta Live Tables et Informations de référence sur le langage Python dans Delta Live Tables.
Pour plus d’informations sur les paramètres et configurations de pipeline, consultez Configurer un pipeline Delta Live Tables.
Déployer votre premier pipeline et déclencher des mises à jour
Avant de traiter des données avec Delta Live Tables, vous devez configurer un pipeline. Une fois qu’un pipeline est configuré, vous pouvez déclencher une mise à jour pour calculer les résultats de chaque jeu de données de votre pipeline. Pour commencer à utiliser les pipelines Delta Live Tables, consultez le Tutoriel : Exécuter votre premier pipeline Delta Live Tables.
Qu’est-ce qu’une mise à jour de pipeline ?
Les pipelines déploient l’infrastructure et recalculent l’état des données lorsque vous démarrez une mise à jour. Une mise à jour effectue les actions suivantes :
- démarre un cluster avec la bonne configuration ;
- Découvre toutes les tables et vues définies et vérifie toutes les erreurs d’analyse telles que les noms de colonnes non valides, les dépendances manquantes et les erreurs de syntaxe.
- crée ou met à jour les tables et vues avec les données disponibles les plus récentes.
Les pipelines peuvent être exécutés en continu ou selon une planification en fonction des exigences de coût et de latence de votre cas d’usage. Consultez Exécuter une mise à jour sur un pipeline Delta Live Tables.
Ingérer des données avec Delta Live Tables
Delta Live Tables prend en charge toutes les sources de données disponibles dans Azure Databricks.
Databricks recommande d’utiliser des tables de diffusion en continu pour la plupart des cas d’usage d’ingestion. Pour les fichiers arrivant dans le stockage d’objets cloud, Databricks recommande Auto Loader. Vous pouvez ingérer directement des données avec Delta Live Tables à partir de la plupart des bus de messages.
Pour plus d’informations sur la configuration de l’accès au stockage cloud, consultez Configuration du stockage cloud.
Pour les formats non pris en charge par Auto Loader, vous pouvez utiliser Python ou SQL pour interroger n’importe quel format pris en charge par Apache Spark. Consultez Charger des données avec Delta Live Tables.
Surveiller et appliquer la qualité des données
Vous pouvez utiliser des attentes pour spécifier les contrôles de qualité des données sur le contenu d’un jeu de données. Contrairement à une contrainte CHECK dans une base de données traditionnelle qui empêche l’ajout d’enregistrements qui ne respectent pas la contrainte, les attentes offrent une certaine flexibilité lors du traitement des données qui ne répondent pas aux exigences de qualité des données. Cette flexibilité vous permet de traiter et de stocker les données dont vous vous attendez à ce qu’elles soient désordonnées et celles qui doivent respecter des exigences strictes en matière de qualité. Voir Gérer la qualité des données avec les attentes de pipeline.
Comment Delta Live Tables et Delta Lake sont-ils liés ?
Delta Live Tables étend les fonctionnalités de Delta Lake. Étant donné que les tables créées et gérées par Delta Live Tables sont des tables Delta, elles ont les mêmes garanties et fonctionnalités fournies par Delta Lake. Consultez Présentation de Delta Lake.
Delta Live Tables ajoute plusieurs propriétés de table en plus des nombreuses propriétés de table qui peuvent être définies dans Delta Lake. Consultez Informations de référence sur les propriétés Delta Live Tables et Informations de référence sur les propriétés de table Delta.
Comment les tables sont créées et gérées par Delta Live Tables
Azure Databricks gère automatiquement les tables créées avec Delta Live Tables, en déterminant comment les mises à jour doivent être traitées pour calculer correctement l’état actuel d’une table et effectuer un certain nombre de tâches de maintenance et d’optimisation.
Pour la plupart des opérations, vous devez autoriser Delta Live Tables à traiter toutes les mises à jour, insertions et suppressions dans une table cible. Pour plus d’informations et connaître les limitations, consultez Conserver les suppressions ou mises à jour manuelles.
Tâches de maintenance effectuées par Delta Live Tables
Delta Live Tables effectue des tâches de maintenance dans les 24 heures suivant la mise à jour d’une table. La maintenance peut améliorer les performances de requête et réduire les coûts en supprimant les anciennes versions des tables. Par défaut, le système effectue une opération de OPTIMIZE complète suivie de VACUUM. Vous pouvez désactiver OPTIMIZE pour une table en définissant pipelines.autoOptimize.managed = false dans les propriétés de la table pour la table. Les tâches de maintenance sont effectuées uniquement si une mise à jour de pipeline s’est exécutée dans les 24 heures précédant la planification des tâches de maintenance.
Limites
Pour obtenir la liste des limitations, consultez Limitations Delta Live Tables.
Pour obtenir la liste des exigences et limitations spécifiques à l’utilisation de Delta Live Tables avec le catalogue Unity, consultez Utiliser le catalogue Unity avec vos pipelines Delta Live Tables
Ressources supplémentaires
- Delta Live Tables bénéficie d’une prise en charge complète dans l’API REST Databricks. Consultez l’API DLT.
- Pour connaître les paramètres de pipeline et de table, consultez Informations de référence sur les propriétés Delta Live Tables.
- Informations de référence sur le langage SQL dans Delta Live Tables.
- Informations de référence sur le langage Python dans Delta Live Tables.