Affecter des ressources de calcul à un groupe
Cet article explique comment créer une ressource de calcul affectée à un groupe à l’aide du mode d’accès dédié
Le mode d’accès de groupe dédié permet aux utilisateurs d’obtenir l’efficacité opérationnelle d’un cluster en mode d’accès standard, tout en prenant en charge en toute sécurité les langages et charges de travail qui ne sont pas pris en charge par le mode d’accès standard, tels que Databricks Runtime pour ML, Spark Machine Learning Library (MLlib), les API RDD et R.
En activant la préversion publique du cluster de groupe dédié, votre espace de travail aura également accès à la nouvelle interface utilisateur de calcul simplifiée. Cette nouvelle interface utilisateur met à jour les noms des modes d’accès et simplifie les paramètres de calcul. Consultez Utiliser le formulaire simple pour gérer le calcul.
Exigences
Pour utiliser le mode d’accès de groupe dédié :
- Un administrateur d’espace de travail doit activer la préversion Calcul : groupes de clusters dédiés à l’aide de l’interface utilisateur Préversions. Consultez Gérer les préversions d’Azure Databricks.
- L’espace de travail doit être activé pour le catalogue Unity.
- Vous devez utiliser Databricks Runtime 15.4 ou version ultérieure.
- Le groupe affecté doit disposer d’autorisations
CAN MANAGEsur un dossier d’espace de travail où ils peuvent conserver des notebooks, des expériences ML et d’autres artefacts d’espace de travail utilisés par le cluster de groupe.
Qu’est-ce que le mode d’accès dédié ?
Le mode d’accès dédié est la dernière version du mode d’accès utilisateur unique. Avec l’accès dédié, une ressource de calcul peut être affectée à un seul utilisateur ou groupe, ce qui permet uniquement à l’utilisateur affecté d’utiliser la ressource de calcul.
Lorsqu’un utilisateur est connecté à une ressource de calcul dédiée à un groupe (un cluster de groupe), les permissions de l'utilisateur sont automatiquement réduites aux permissions du groupe, ce qui permet à l'utilisateur de partager la ressource de manière sécurisée avec les autres membres du groupe.
Créer une ressource de calcul dédiée à un groupe
- Dans votre espace de travail Azure Databricks, accédez à Compute, puis cliquez sur Create Compute.
- Développez la section Avancé.
- Sous mode Accès, cliquez sur Manuel, puis sélectionnez Dédié (anciennement : mono-utilisateur) dans le menu déroulant.
- Dans le champ utilisateur unique ou groupe, sélectionnez le groupe que vous souhaitez affecter à cette ressource.
- Configurez les autres paramètres de calcul souhaités, puis cliquez sur Créer.
Meilleures pratiques pour la gestion des clusters de groupe
Étant donné que les autorisations utilisateur sont limitées au groupe lors de l’utilisation de clusters de groupe, Databricks recommande de créer un dossier /Workspace/Groups/<groupName> pour chaque groupe que vous envisagez d’utiliser avec un cluster de groupe. Ensuite, accordez les autorisations CAN MANAGE sur le dossier au groupe. Cela permet aux groupes d’éviter les erreurs d’autorisation. Tous les blocs-notes et ressources d’espace de travail du groupe doivent être gérés dans le dossier du groupe.
Vous devez également modifier les charges de travail suivantes pour qu’elles s’exécutent sur des clusters de groupe :
- MLflow : vérifiez que vous exécutez le notebook à partir du dossier de groupe ou exécutez
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>"). - AutoML : définissez le paramètre de
experiment_dirfacultatif sur“/Workspace/Groups/<groupName>”pour vos exécutions AutoML. dbutils.notebook.run: vérifiez que le groupe dispose d’une autorisationREADsur le notebook en cours d’exécution.
Exemples d’autorisations de groupe
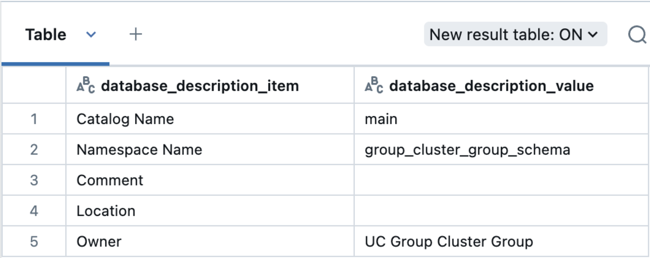
Lorsque vous créez un objet de données à l’aide du cluster de groupe, le groupe est affecté en tant que propriétaire de l’objet.
Par exemple, si vous avez un bloc-notes attaché à un cluster de groupe et exécutez la commande suivante :
use catalog main;
create schema group_cluster_group_schema;
Exécutez ensuite cette requête pour vérifier le propriétaire du schéma :
describe schema group_cluster_group_schema;
Groupe d’audit dédié à l'activité informatique
Il existe deux identités clés impliquées lorsqu’un cluster de groupe exécute une charge de travail :
- Utilisateur qui exécute la charge de travail sur le cluster de groupe
- Groupe dont les autorisations sont utilisées pour effectuer les actions de charge de travail réelles
La table système du journal d’audit enregistre ces identités sous les paramètres suivants :
identity_metadata.run_by: utilisateur d’authentification qui effectue l’actionidentity_metadata.run_as: groupe d’autorisation dont les autorisations sont utilisées pour l’action.
L’exemple de requête suivant extrait les métadonnées d’identité pour une action effectuée avec le cluster de groupe :
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
Consultez la référence de la table système du journal d’audit pour obtenir d’autres exemples de requêtes. Consultez Référence de table système du journal d’audit.
Problèmes connus
- Les fichiers et les dossiers d’espace de travail créés à partir de clusters de groupe ont pour résultat que le propriétaire de l’objet assigné est
Unknown. Les opérations suivantes sur ces objets, telles queread,writeetdelete, échouent avec des erreurs de refus d’autorisation.
Limitations de
La préversion publique du mode d’accès de groupe dédié présente les limitations connues suivantes :
- Les tables système de traçabilité n’enregistrent pas les identités
identity_metadata.run_as(le groupe d’autorisation) ouidentity_metadata.run_by(l’utilisateur authentifié) pour les charges de travail exécutées sur un cluster de groupe. - Les journaux d’audit remis au stockage client n’enregistrent pas les identités
identity_metadata.run_as(le groupe d’autorisation) ouidentity_metadata.run_by(l’utilisateur authentifiant) pour les charges de travail exécutées sur un cluster de groupe. Vous devez utiliser la tablesystem.access.auditpour afficher les métadonnées d’identité. - Lorsqu’il est attaché à un cluster de groupe, l’Explorateur de catalogues ne filtre pas par ressources uniquement accessibles au groupe.
- Les gestionnaires de groupes qui ne sont pas des membres de groupe ne peuvent pas créer, modifier ou supprimer des clusters de groupe. Seuls les administrateurs de l’espace de travail et les membres du groupe peuvent le faire.
- Si un groupe est renommé, vous devez mettre à jour manuellement toutes les stratégies de calcul qui référencent le nom du groupe.
- Les clusters de groupe ne sont pas pris en charge pour les espaces de travail avec des listes de contrôle d’accès désactivées (isWorkspaceAclsEnabled == false) en raison du manque inhérent de contrôles de sécurité et d’accès aux données lorsque les listes de contrôle d’accès aux espaces de travail sont désactivées.
- La commande
%runutilise actuellement les autorisations de l’utilisateur au lieu des autorisations du groupe lorsqu’elle est exécutée sur un cluster de groupe. Les alternatives telles quedbutils.notebook.run()utilisent correctement les autorisations du groupe.