Afficher les métriques de calcul
Cet article explique comment utiliser l’outil de métriques de calcul natif dans l’interface utilisateur Azure Databricks pour collecter des métriques Spark ou matérielles clés. L’interface utilisateur des métriques est disponible pour le calcul à usage général et des travaux.
Remarque
Le calcul serverless pour les notebooks et les travaux utilise des insights de requête au lieu de l’interface utilisateur des métriques. Pour plus d’informations sur les métriques de calcul serverless, consultez Afficher les insights de requête.
Les métriques sont disponibles quasiment en temps réel avec un retard normal de moins d’une minute. Les métriques sont stockées dans le stockage managé par Azure Databricks, et non dans le stockage du client.
Quelles différences existe-t-il entre ces nouvelles métriques et Ganglia ?
La nouvelle interface utilisateur des métriques de calcul offre une vue plus complète de l’utilisation des ressources de votre cluster, dont la consommation Spark et les processus Databricks internes. En revanche, l’interface utilisateur Ganglia mesure uniquement la consommation de conteneurs Spark. Cette différence peut entraîner des écarts entre les valeurs de métrique des deux interfaces.
Accéder à l’interface utilisateur des métriques de calcul
Pour afficher l’interface utilisateur des métriques de calcul :
- Cliquez sur Calcul dans la barre latérale.
- Cliquez sur la ressource de calcul pour laquelle vous souhaitez afficher les métriques.
- Cliquez sur l’onglet Métriques.
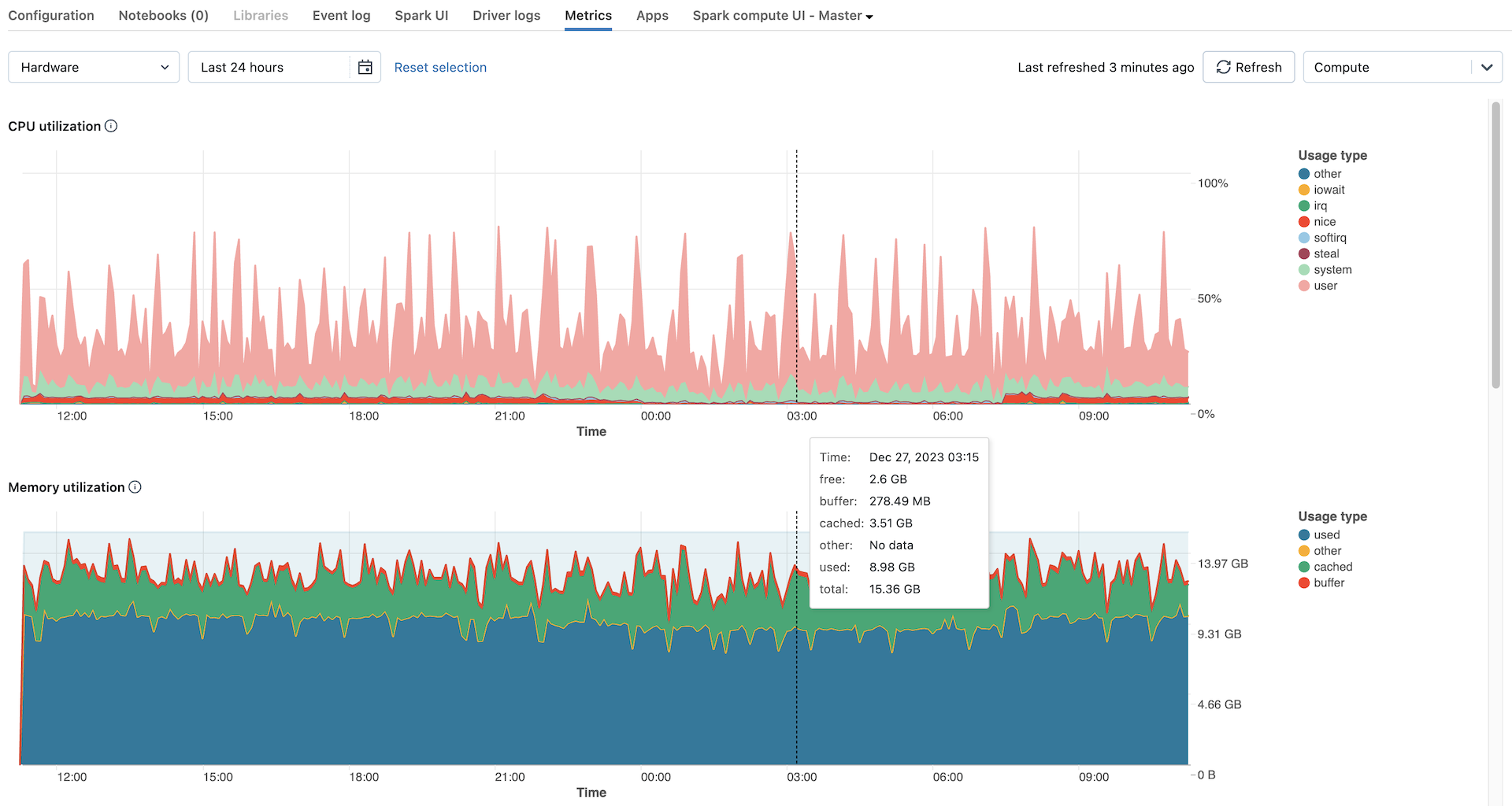
Les métriques matérielles sont affichées par défaut. Pour afficher les métriques Spark, cliquez sur le menu déroulant intitulé Matériel et sélectionnez Spark. Vous pouvez également sélectionner GPU si l’instance est activés par GPU.
Filtrer les métriques par période
Vous pouvez afficher les métriques historiques en sélectionnant une plage de temps à l’aide du filtre du sélecteur de dates. Les métriques sont collectées chaque minute. Vous pouvez ainsi les filtrer par n’importe quelle plage de jour, d’heure ou de minute dans les 30 derniers jours. Cliquez sur l’icône de calendrier pour sélectionner parmi des plages de données prédéfinies, ou cliquez à l’intérieur de la zone de texte pour définir des valeurs personnalisées.
Remarque
Les intervalles de temps affichés dans les graphiques s’ajustent en fonction de la durée d’affichage. La plupart des métriques sont des moyennes basées sur l’intervalle de temps que vous affichez actuellement.
Vous pouvez également obtenir les dernières métriques en cliquant sur le bouton Actualiser.
Afficher les métriques au niveau du nœud
Vous pouvez afficher les métriques des nœuds individuels en cliquant sur le menu déroulant Calcul et en sélectionnant le nœud dont vous souhaitez afficher les métriques. Les métriques GPU ne sont disponibles qu’au niveau du nœud individuel. Les métriques Spark ne sont pas disponibles pour les nœuds individuels.
Remarque
Si vous ne sélectionnez aucun nœud spécifique, le résultat est une moyenne de tous les nœuds d’un cluster (y compris le pilote).
Graphiques de métriques du matériel
Les graphiques de métriques du matériel suivants sont disponibles dans l’interface utilisateur des métriques de calcul :
- Distribution de la charge du serveur : ce graphique montre l’utilisation du processeur au cours de la dernière minute pour chaque nœud.
- Utilisation du processeur : le pourcentage de temps utilisé par le processeur dans chaque mode, en fonction du coût total du processeur en secondes. La métrique est calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique. Voici les modes suivis :
- guest : si vous exécutez des machines virtuelles, le processeur utilisé par ces machines virtuelles
- iowait : temps passé en attente d’E/S
- idle : temps que le processeur n’avait rien à faire
- irq : temps consacré aux demandes d’interruption
- nice : temps utilisé par les processus « nice » positifs, ce qui signifie qu’ils ont une priorité inférieure à d’autres tâches
- softirq : temps consacré aux demandes d’interruption logicielle
- steal : si vous êtes une machine virtuelle, le temps que d’autres machines virtuelles « volent » à vos processeurs
- system : temps passé dans le noyau
- user : temps passé dans le userland
- Utilisation de la mémoire : utilisation totale de la mémoire par chaque mode, mesurée en octets et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique. Les types d’utilisation suivants font l’objet d’un suivi :
- used : mémoire utilisée (y compris la mémoire utilisée par les processus en arrière-plan s’exécutant sur un calcul)
- free : mémoire inutilisée
- buffer : mémoire utilisée par les tampons du noyau
- cached : mémoire utilisée par le cache du système de fichiers au niveau du système d'exploitation
- Utilisation de l’échange de mémoire : utilisation totale de l’échange de mémoire par chaque mode, mesurée en octets et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Espace libre du système de fichiers : utilisation totale du système de fichiers par chaque point de montage, mesurée en octets et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Reçu via le réseau : nombre d’octets reçus via le réseau par chaque appareil, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Transmis via le réseau : nombre d’octets transmis via le réseau par chaque appareil, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Nombre de nœuds actifs : indique le nombre de nœuds actifs à chaque timestamp pour le calcul donné.
Graphiques de métriques Spark
Les graphiques de métriques Spark suivants sont disponibles dans l’interface utilisateur des métriques de calcul :
- Distribution de la charge du serveur : ce graphique montre l’utilisation du processeur au cours de la dernière minute pour chaque nœud.
- Tâches actives : nombre total de tâches exécutées à un moment donné, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Total des tâches ayant échoué : nombre total de tâches ayant échoué dans les exécuteurs, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Total des tâches terminées : nombre total de tâches qui se sont terminées dans les exécuteurs, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Nombre total de tâches : nombre total de toutes les tâches (en cours d’exécution, ayant échoué et terminées) dans les exécuteurs, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Lecture aléatoire totale : taille totale des données de lecture aléatoire, mesurée en octets et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
Shuffle readdésigne la somme des données de lecture sérialisées sur tous les exécuteurs au début d’une phase. - Écriture aléatoire totale : taille totale des données d’écriture aléatoire, mesurée en octets et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
Shuffle Writeest la somme de toutes les données sérialisées écrites sur tous les exécuteurs avant la transmission (normalement à la fin d’une phase). - Durée totale des tâches : durée totale utilisée par la machine virtuelle Java pour exécuter des tâches sur les exécuteurs, mesurée en secondes et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
Graphiques de métriques GPU
Remarque
Les métriques GPU sont disponibles uniquement sur Databricks Runtime ML 13.3 et versions ultérieures.
Les graphiques de métriques GPU suivants sont disponibles dans l’interface utilisateur des métriques de calcul :
- Distribution de la charge du serveur : ce graphique montre l’utilisation du processeur au cours de la dernière minute pour chaque nœud.
- Utilisation du décodeur par GPU : pourcentage d’utilisation du décodeur GPU, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Utilisation de l’encodeur par GPU : pourcentage d’utilisation de l’encodeur GPU, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Octets d’utilisation de la mémoire tampon de trame par GPU : utilisation de la mémoire tampon de trame, mesurée en octets et calculée en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Utilisation de la mémoire par GPU : pourcentage d’utilisation de la mémoire GPU, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
- Utilisation par GPU : pourcentage d’utilisation du GPU, calculé en moyenne en fonction de l’intervalle de temps affiché dans le graphique.
Dépannage
Si vous voyez des métriques incomplètes ou manquantes pendant une certaine période, il peut s’agir de l’un des problèmes suivants :
- Panne du service Databricks responsable de l’interrogation et du stockage des métriques.
- Problèmes réseau côté client.
- Le calcul est ou était dans un état non sain.