Créer et utiliser des tables de sortie dans databricks Clean Rooms
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article présente les tables de sortie, qui sont des tables en lecture seule temporaire générées par une exécution de notebook et partagées avec le metastore du catalogue Unity de l’exécuteur de notebooks. Cet article explique comment utiliser un notebook pour créer des tables de sortie et comment les collaborateurs peuvent lire ces tables de sortie dans leur metastore du catalogue Unity.
Vue d’ensemble des tables de sortie
Les tables de sortie vous permettent d’enregistrer temporairement la sortie des blocs-notes exécutés dans une salle propre dans un catalogue de sortie dans votre metastore Du catalogue Unity, où vous pouvez mettre les données à la disposition des membres de votre équipe qui n’ont pas la possibilité d’exécuter eux-mêmes les blocs-notes. Vous pouvez également utiliser des travaux Azure Databricks pour exécuter des notebooks et effectuer des tâches sur des tables de sortie. Combinées au type de tâche de bloc-notes Clean Room et à la prise en charge des valeurs des tâches, les tables de sortie vous permettent de créer des flux de travail complexes qui dépendent des blocs-notes De salle propre.
Les tables de sortie sont en lecture seule.
Seul le principal spécifique (utilisateur, groupe ou principal de service) qui exécute le notebook dispose d’un accès en lecture par défaut à la table de sortie. Il n’y a pas d’accès en écriture. Un administrateur de metastore peut accorder l’accès en lecture à d’autres principaux dans leur compte Azure Databricks, à l’aide de privilèges de catalogue Unity standard.
Les tables de sortie sont stockées pendant 30 jours dans l’emplacement de stockage par défaut de la salle propre centrale et partagées avec le metastore du collaborateur à l’aide du partage Delta. Si vous souhaitez conserver une table de sortie pendant plus de 30 jours, vous devez la copier dans le stockage local.
Chaque exécution de notebook crée un schéma dans le catalogue de sorties. Les nouvelles exécutions ne peuvent pas ajouter une table de sortie existante.
Important
Les tables de sortie sont prises en charge uniquement lorsque la salle propre centrale est hébergée sur AWS. Toutefois, les collaborateurs de Databricks sur les trois clouds (AWS, Azure et Google Cloud) peuvent partager des notebooks qui créent des tables de sortie et peuvent lire les tables de sortie générées lors de l’exécution de notebooks partagés. Les collaborateurs Google Cloud doivent être participants à la préversion privée des salles propres.
Créer une table de sortie
Pour créer une table de sortie, utilisez les paramètres cr_output_catalog et cr_output_schema dans l’espace de noms de table en trois parties. Chaque exécution du notebook produit un nouveau schéma.
Dans l’exemple suivant, la cellule de bloc-notes crée une table de sortie appelée overlapping_users dans le catalogue de sortie du collborator qui répertorie les utilisateurs dont l’adresse e-mail s’affiche dans les tables et creator.publisher.profiles les collaborator.advertiser.profiles tables.
CREATE TABLE identifier(:cr_output_catalog || '.' || :cr_output_schema || '.overlapping_users') AS
SELECT collab_profiles.*
FROM collaborator.advertiser.profiles AS collab_profiles
JOIN creator.publisher.profiles AS creator_profiles
ON collab_profiles.email = creator_profiles.email
Lire une table de sortie
Les tables de sortie apparaissent dans un catalogue partagé dans le metastore de l’exécuteur de notebooks. Dans le volet Catalogue de l’Explorateur de catalogues, ils apparaissent dans la liste des catalogues partagés.
La lecture d’une table de sortie ressemble à la lecture d’une autre table dans le catalogue Unity. Vous devez disposer SELECT sur la table, USE CATALOG dans le catalogue de sorties partagés et USE SCHEMA sur le schéma généré automatiquement. L’utilisateur qui a exécuté le notebook qui a créé la table dispose de ces autorisations par défaut.
Avant de commencer
Cette section décrit les exigences en matière de cloud, de configuration et de calcul pour la lecture des tables de sortie.
Conditions préalables requises du cloud
Bien que la salle propre centrale soit sur AWS pour prendre en charge les tables de sortie, les espaces de travail de collaborateur peuvent se trouver sur l’un des trois clouds : AWS, Azure ou Google Cloud. Les collaborateurs Google Cloud doivent être participants à la préversion privée des salles propres.
Exigence de catalogue de sortie partagée
Avant de pouvoir lire les tables de sortie, un utilisateur doit créer le catalogue qui les contient. Vous n’avez besoin que d’effectuer cette opération une seule fois par chambre propre.
Autorisations requises : EXECUTE_CLEAN_ROOM_TASK
- Dans votre espace de travail Azure Databricks, cliquez sur
 Catalogue.
Catalogue. - Sur la page Accès rapide, cliquez sur le bouton Salles blanches >.
- Sélectionnez la salle blanche dans la liste.
- Dans le volet droit, sous Sortie, cliquez sur Créer un catalogue.
- Entrez un nom de catalogue de sortie ou acceptez la valeur par défaut, c’est-à-dire
<clean-room-name>_output.
Le catalogue de sortie apparaît dans la liste des catalogues partagés dans le volet Catalogue de l’Explorateur de catalogues . Chaque salle propre que vous participez peut avoir un catalogue de sortie partagé dans votre metastore.
Exigences de calcul
Les requêtes sur les tables de sortie nécessitent un calcul serverless. Voir Se connecter à un calcul serverless.
Autorisations requises pour lire une table de sortie
L’utilisateur qui a exécuté le notebook qui a créé la table de sortie a l’autorisation de lire à partir de la table de sortie par défaut. Tous les autres utilisateurs doivent disposer des autorisations suivantes qui leur sont accordées :
SELECTsur la tableUSE CATALOGsur le catalogue de sortieUSE SCHEMAsur le schéma de sortie
Exécuter le bloc-notes
Pour générer des tables de sortie partagées dans votre catalogue de sorties, un utilisateur ayant accès à la salle propre doit exécuter le bloc-notes. Consultez Exécuter des blocs-notes dans des salles propres. Chaque exécution de notebook crée un schéma et une table de sortie.
Conseil
Vous pouvez utiliser des travaux Azure Databricks pour exécuter des notebooks et effectuer des tâches sur des tables de sortie, ce qui permet des flux de travail complexes. Consultez Utiliser les flux de travail Azure Databricks pour exécuter des notebooks de salle propre.
Rechercher et afficher une table de sortie
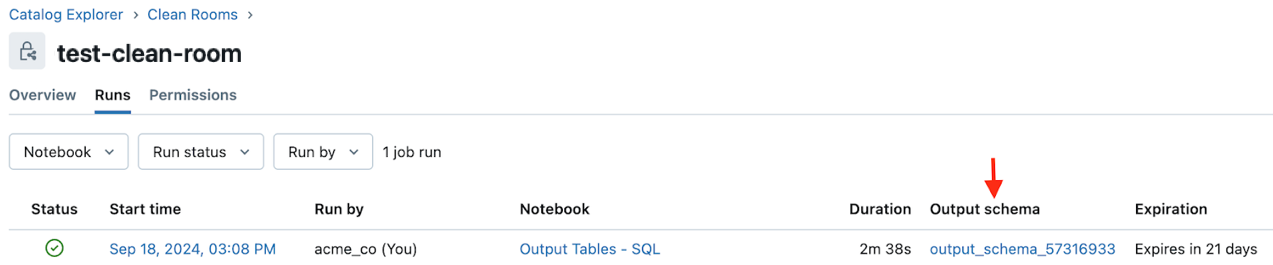
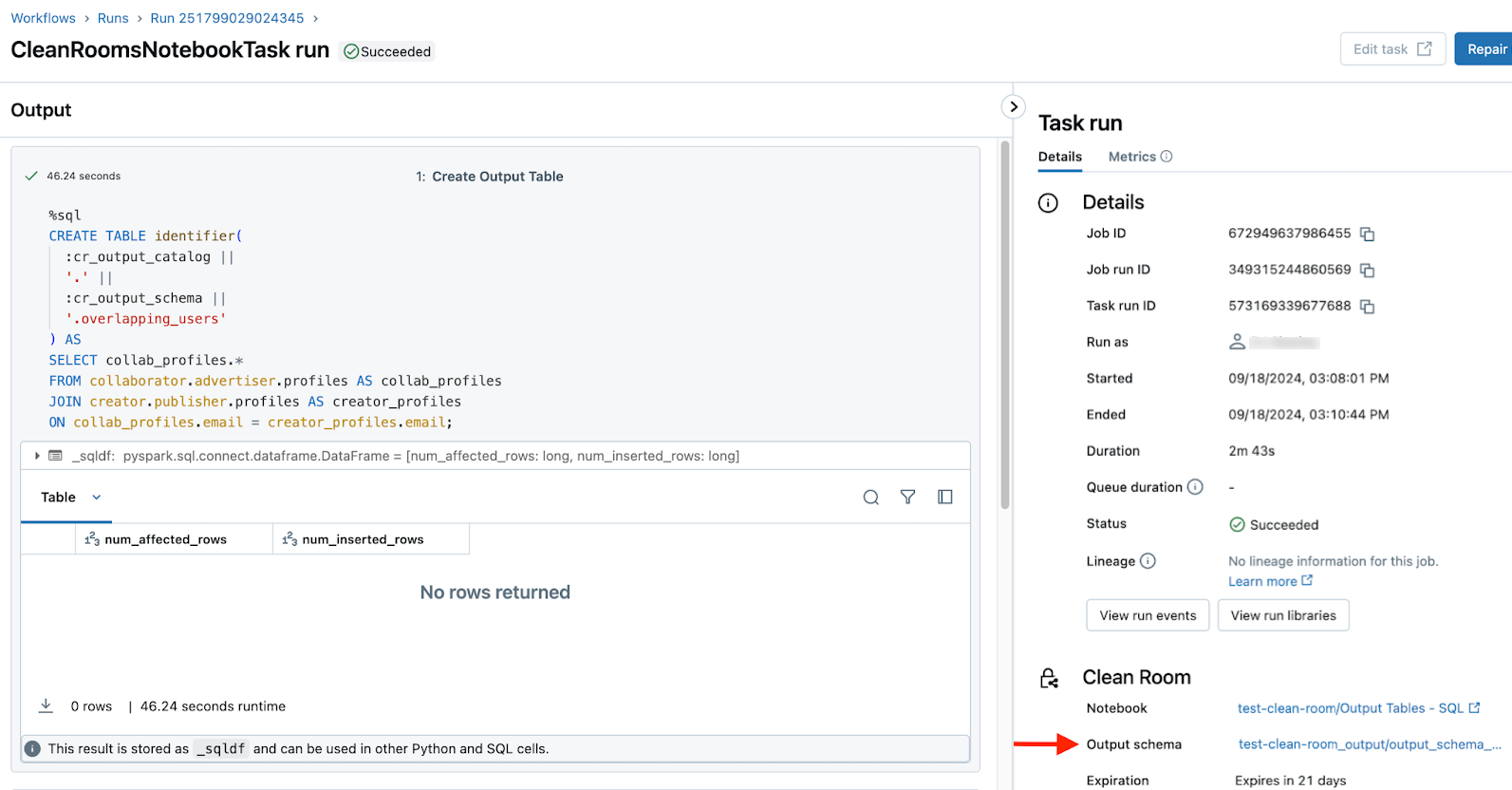
L’utilisateur qui exécute le bloc-notes qui crée la table de sortie peut trouver un lien vers la table de sortie sur l’historique des exécutions du bloc-notes et exécuter des pages de détails dans l’interface utilisateur des salles propres. Dans les deux cas, le lien se trouve dans le champ de schéma de sortie. Consultez Surveiller les exécutions du bloc-notes de salle propre.
Historique des exécutions :
Détails de l’exécution :
Vous pouvez également trouver le catalogue de sortie dans la liste des catalogues partagés dans le volet Catalogue de l’Explorateur de catalogues.
Limites
Outre les exigences répertoriées dans Vue d’ensemble des tables de sortie et avant de commencer, les tables de sortie présentent les limitations suivantes :
- Les tables de sortie ne sont prises en charge que lorsque la salle propre centrale est hébergée sur AWS et lorsque la salle propre a été créée après la publication de la fonctionnalité de table de sortie.
- Seules les tables sont prises en charge. Les volumes et les vues, par exemple, ne sont pas.
- Vous pouvez créer jusqu’à 100 tables de sortie par notebook.