Service de modèle MLflow hérité sur Azure Databricks
Important
Cette fonctionnalité est disponible en préversion publique.
Important
- Cette documentation a été mise hors service et peut ne pas être mise à jour. Les produits, services ou technologies mentionnés dans ce contenu ne sont plus pris en charge.
- Les conseils contenus dans cet article concernent le service de modèle MLflow hérité. Databricks vous recommande de migrer vos workflows de diffusion de modèles vers Model Serving pour un déploiement et une évolutivité améliorés des points de terminaison de modèles. Pour plus d’informations, consultez Déployer des modèles en utilisant Mosaic AI Model Serving.
L'ancien MLflow Model Serving vous permet d'héberger des modèles d'apprentissage automatique à partir de Model Registry en tant que points de terminaison REST qui sont mis à jour automatiquement en fonction de la disponibilité des versions de modèle et de leurs étapes. Il utilise un cluster à nœud unique qui s’exécute sous votre propre compte dans ce qui est maintenant appelé le plan de calcul classique. Ce plan de calcul inclut le réseau virtuel et ses ressources de calcul associées, telles que les clusters pour les notebooks et les travaux, les entrepôts SQL professionnels et classiques et les points de terminaison de service de modèle hérité.
Quand vous activez la mise en service de modèles pour un modèle inscrit donné, Azure Databricks crée automatiquement un cluster unique pour le modèle et déploie toutes les versions non archivées du modèle sur ce cluster. Azure Databricks redémarre le cluster si une erreur se produit et l’arrête quand vous désactivez la mise en service de modèles pour le modèle. La mise en service de modèles se synchronise automatiquement avec le registre de modèles et déploie toutes les nouvelles versions de modèles inscrites. Les versions de modèle déployées peuvent être interrogées avec une demande d’API REST standard. Azure Databricks authentifie les demandes adressées au modèle en utilisant son authentification standard.
Même si ce service est en préversion, Databricks recommande de l’utiliser pour des applications de faible débit et non critiques. Le débit cible est de 200 RPS et la disponibilité cible est de 99,5 %, même si aucun de ces objectifs n’est garanti. En outre, il existe une taille de charge utile limit de 16 Mo par requête.
Chaque version de modèle est déployée au moyen du déploiement de modèle MLflow et s’exécute dans un environnement Conda spécifié par ses dépendances.
Remarque
- Le cluster est conservé tant que la mise en service est activée, même s’il n’existe pas de version de modèle active. Pour arrêter le cluster de mise en service, désactivez la mise en service de modèles pour le modèle inscrit.
- Le cluster est considéré comme un cluster à usage général, soumis aux tarifs des charges de travail à usage général.
- Les scripts d'initialisation globaux ne sont pas exécutés sur les clusters de diffusion de modèles.
Important
Anaconda Inc. a mis à jour ses conditions d’utilisation du service pour les canaux anaconda.org. Les nouvelles conditions d’utilisation du service peuvent vous imposer d’avoir une licence commerciale pour utiliser une distribution et des packages Anaconda. Pour plus d’informations, consultez le Forum aux questions sur l’édition commerciale d’Anaconda. Votre utilisation des canaux Anaconda est régie par leurs conditions d’utilisation du service.
Les modèles MLflow enregistrés avant la version 1.18 (Databricks Runtime 8.3 ML ou version antérieure) étaient enregistrés par défaut avec le canal conda defaults (https://repo.anaconda.com/pkgs/) en tant que dépendance. En raison de cette modification de licence, Databricks a arrêté l’utilisation du canal defaults pour les modèles enregistrés à l’aide de MLflow v1.18 et versions ultérieures. Le canal par défaut journalisé est maintenant conda-forge, qui pointe vers https://conda-forge.org/, géré par la communauté.
Si vous avez enregistré un modèle avant MLflow v1.18 sans exclure le canal defaults de l’environnement conda pour le modèle, ce modèle peut avoir une dépendance sur le canal defaults que vous n’avez peut-être pas prévue.
Pour vérifier manuellement si un modèle a cette dépendance, vous pouvez examiner la valeur channel dans le fichier conda.yaml empaqueté avec le modèle journalisé. Par exemple, les modèles conda.yaml avec une dépendance de canal defaults peuvent ressembler à ceci :
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Étant donné que Databricks ne peut pas déterminer si votre utilisation du référentiel Anaconda pour interagir avec vos modèles est autorisée dans votre relation avec Anaconda, Databricks n’oblige pas ses clients à apporter des modifications. Si votre utilisation du référentiel Anaconda.com par le biais de l’utilisation de Databricks est autorisée selon les conditions d’Anaconda, vous n’avez pas besoin d’effectuer d’action.
Si vous souhaitez modifier le canal utilisé dans l’environnement d’un modèle, vous pouvez réinscrire le modèle dans le registre de modèles avec un nouveau conda.yaml. Pour ce faire, spécifiez le canal dans le paramètre conda_env de log_model().
Pour plus d’informations sur l’API log_model(), consultez la documentation MLflow pour la version de modèle que vous utilisez, par exemple, log_model pour scikit-learn.
Pour plus d’informations sur les fichiers conda.yaml, consultez la documentation MLflow.
Spécifications
- L'ancien service de modèles MLflow est disponible pour les modèles Python MLflow. Vous devez déclarer toutes les dépendances de modèle dans l’environnement Conda. Consultez Journaliser les dépendances d’un modèle.
- Pour activer la mise en service de modèles, vous devez disposer de l’autorisation de création de cluster.
Mise en service de modèles à partir du registre de modèles
La mise en service de modèles est disponible dans Azure Databricks à partir du registre de modèles.
Activer et désactiver la mise en service de modèles
Vous pouvez activer un modèle à des fins de mise en service à partir de sa page de modèle inscrit.
Cliquez sur l’onglet Mise en service. Si le modèle n’est pas déjà activé à des fins de mise en service, le bouton Activer la mise en service s’affiche.
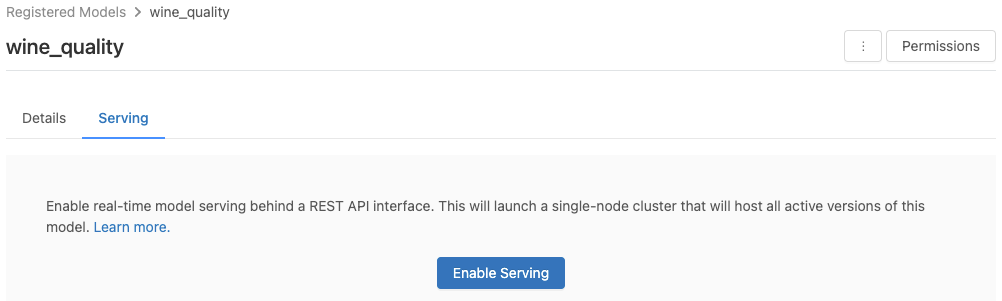
Cliquez sur Activer la mise en service. L’onglet Mise en service s’affiche avec l’état En attente. Après quelques minutes, l’état affiche Prêt.
Pour désactiver un modèle à des fins de mise en service, cliquez sur Arrêter.
Valider la mise en service de modèles
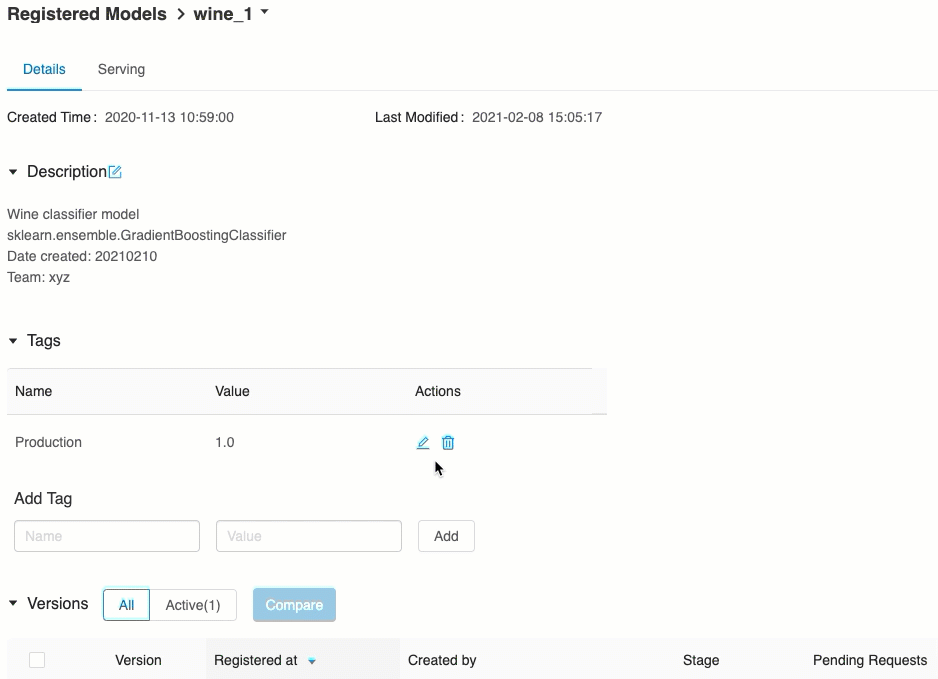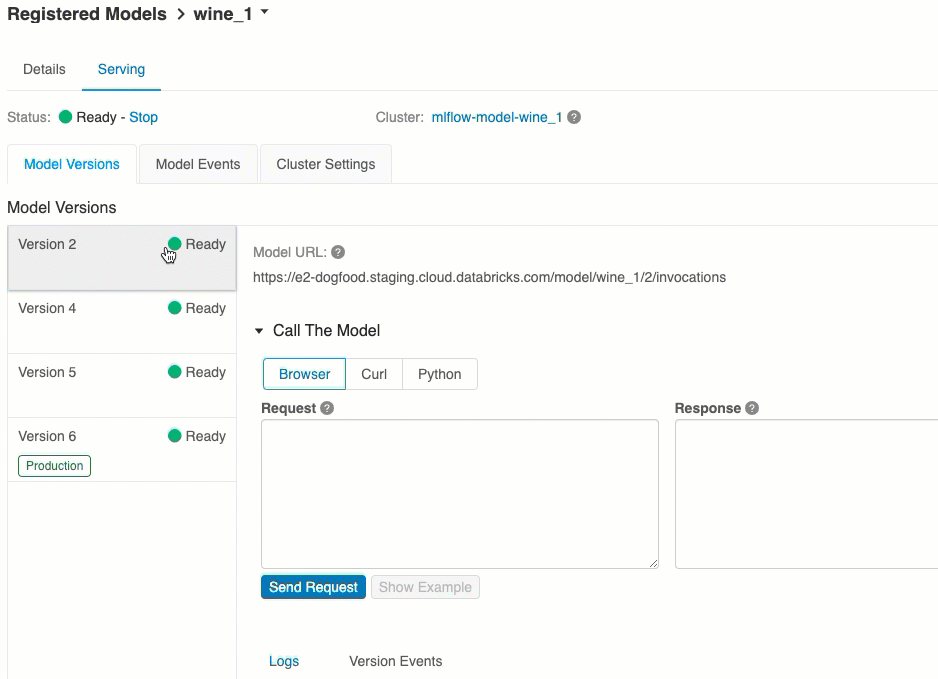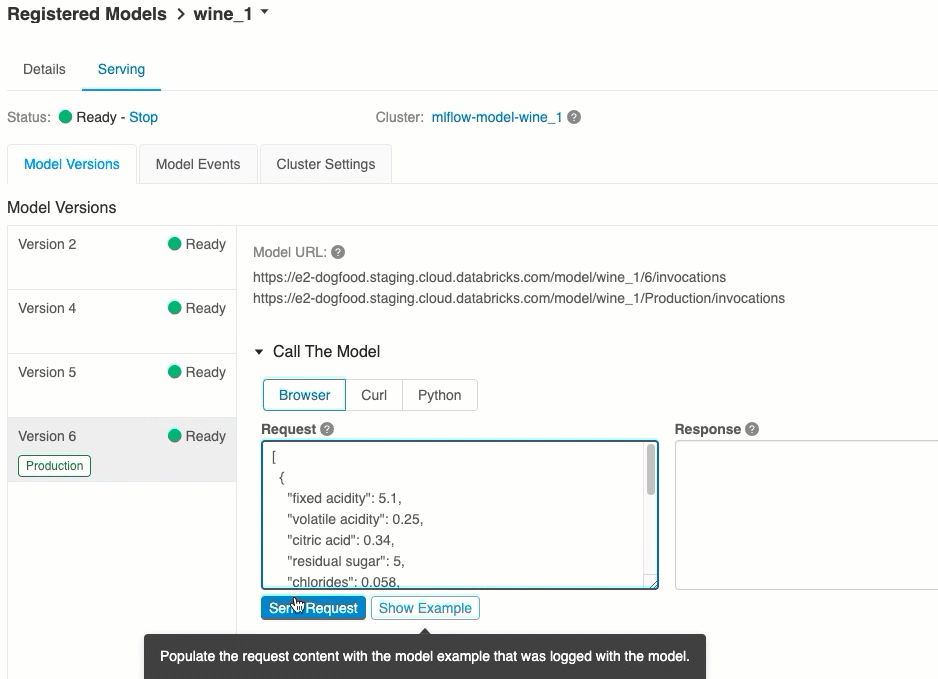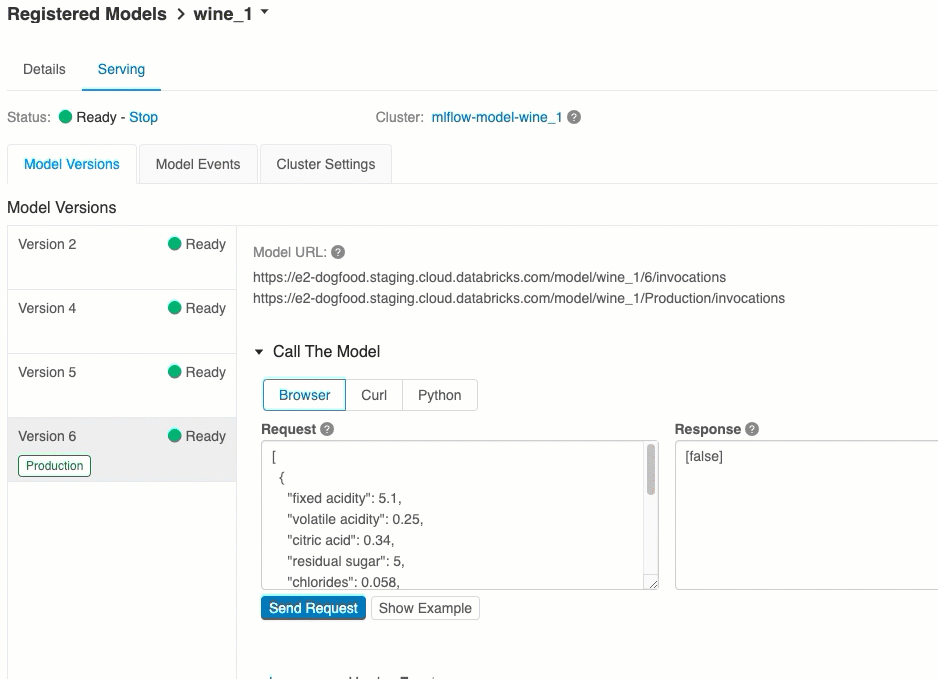
À partir de l’onglet Mise en service, vous pouvez envoyer une demande au modèle servi et afficher la réponse.
URI de version de modèle
Chaque version de modèle déployée se voit affecter un ou plusieurs URI uniques. Au minimum, chaque version de modèle se voit assigner un URI construit comme suit :
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Par exemple, pour appeler la version 1 d’un modèle enregistré en tant que iris-classifier, utilisez l’URI suivant :
https://<databricks-instance>/model/iris-classifier/1/invocations
Vous pouvez également appeler une version de modèle par sa phase. Par exemple, si la version 1 se trouve dans la phase Production, elle peut également être évaluée avec l’URI suivant :
https://<databricks-instance>/model/iris-classifier/Production/invocations
La list des URI de modèle disponibles apparaît en haut de l’onglet Versions de modèle dans la page de mise en service.
Gérer les versions servies
Toutes les versions de modèle actives (non archivées) sont déployées et vous pouvez les interroger avec les URI. Azure Databricks déploie automatiquement les nouvelles versions de modèle quand elles sont inscrites et supprime automatiquement les anciennes versions quand elles sont archivées.
Remarque
Toutes les versions déployées d’un modèle inscrit partagent le même cluster.
Gérer les droits d’accès au modèle
Les droits d’accès au modèle sont hérités du registre de modèles. L’activation ou la désactivation de la fonctionnalité de mise en service nécessite l’autorisation « Gérer » sur le modèle inscrit. Toute personne disposant de droits de lecture peut évaluer toutes les versions déployées.
Noter les versions de modèles déployées
Pour évaluer un modèle déployé, vous pouvez utiliser l’interface utilisateur ou envoyer une demande d’API REST à l’URI du modèle.
Évaluer par le biais de l’interface utilisateur
Il s’agit de la méthode la plus simple et la plus rapide pour tester le modèle. Vous pouvez insert les données d’entrée du modèle au format JSON, puis cliquer sur Envoyer la requête. Si le modèle a été journalisé avec un exemple d’entrée (comme indiqué dans le graphique ci-dessus), cliquez sur Charger l’exemple pour charger l’exemple d’entrée.
Évaluer par le biais d’une demande d’API REST
Vous pouvez envoyer une demande de scoring par le biais de l’API REST en utilisant l’authentification Databricks standard. Les exemples ci-dessous illustrent l’authentification à l’aide d’un jeton d’accès personnel avec MLflow 1.x.
Remarque
En guise de bonne pratique de sécurité, quand vous vous authentifiez avec des outils, systèmes, scripts et applications automatisés, Databricks recommande d’utiliser des jetons d’accès personnels appartenant à des principaux de service et non des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Étant donné un MODEL_VERSION_URI comme https://<databricks-instance>/model/iris-classifier/Production/invocations (where<databricks-instance> est le nom de votre instance Databricks) et un jeton d’API REST Databricks appelé DATABRICKS_API_TOKEN, les exemples suivants montrent comment interroger un modèle servi :
Les exemples suivants reflètent le format de scoring pour les modèles créés avec MLflow 1.x. Si vous préférez utiliser MLflow 2.0, vous devez update le format de votre charge utile de demande.
Bash
Extrait pour interroger un modèle acceptant les entrées de dataframe.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Extrait pour interroger un modèle acceptant les entrées de tenseur. Les entrées de tenseur doivent être mises en forme conformément à la documentation de l’API de TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
PowerBI
Vous pouvez évaluer un jeu de données dans Power BI Desktop en procédant comme suit :
Ouvrez le jeu de données à évaluer.
Accédez à Transformer les données.
Cliquez avec le bouton droit dans le volet gauche et selectCréer une requête.
Accédez à Afficher > Éditeur avancé.
Remplacez le corps de la requête par l’extrait de code ci-dessous, après avoir fourni un
DATABRICKS_API_TOKENapproprié et unMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNommez la requête avec le nom de modèle de votre choix.
Ouvrez l’éditeur de requête avancé pour votre jeu de données et appliquez la fonction de modèle.
Superviser les modèles servis
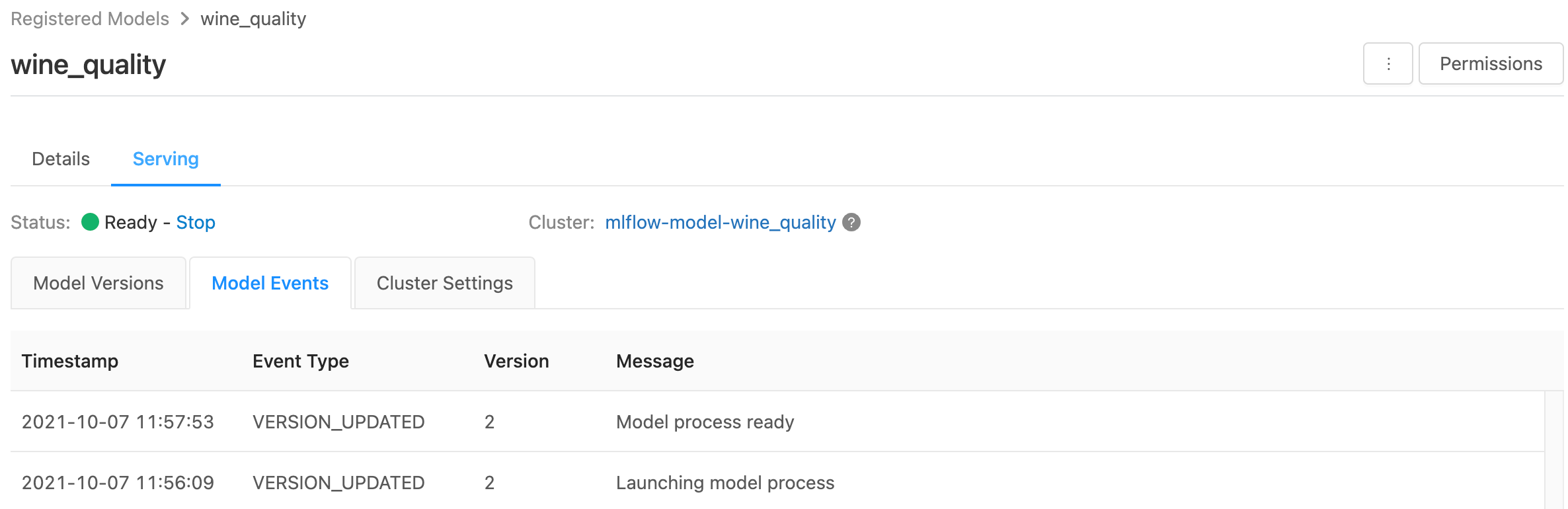
La page de mise en service affiche des indicateurs d’état pour le cluster de mise en service et les différentes versions de modèle.
- Pour inspecter l’état du cluster de mise en service, utilisez l’onglet Événements de modèle, qui affiche une list de tous les événements de mise en service pour ce modèle.
- Pour inspecter l’état d’une version de modèle spécifique, cliquez sur l’onglet Versions de modèle et faites défiler l’écran pour afficher les onglets Journaux ou Événements de version.
Personnaliser le cluster de mise en service
Pour personnaliser le cluster de mise en service, utilisez l’onglet Paramètres de cluster sous l’onglet Mise en service.
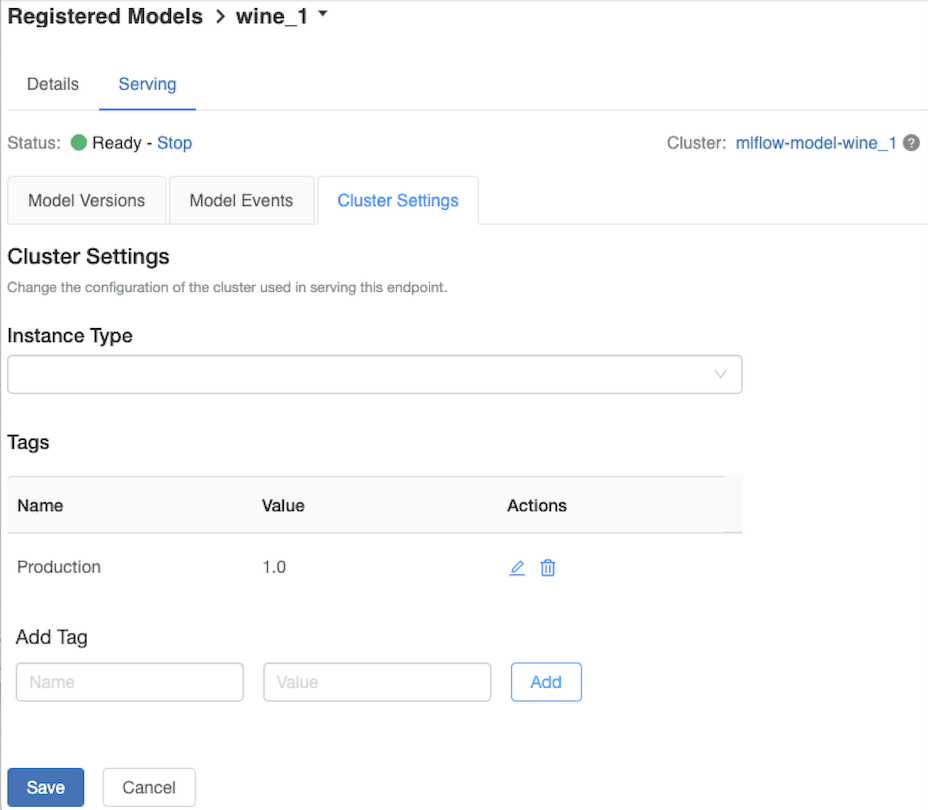
- Pour modifier la taille de mémoire et le nombre de cœurs d’un cluster de service, utilisez le menu déroulant type d’instance
pour la configuration de cluster souhaitée. Quand vous cliquez sur Enregistrer, le cluster existant est arrêté et un cluster est créé avec les paramètres spécifiés. - Pour ajouter une étiquette, tapez le nom et la valeur dans les champs Ajouter une étiquette, puis cliquez sur Ajouter.
- Pour modifier ou supprimer une balise existante, cliquez sur l’une des icônes de l'Actionscolumn des balises table.
Intégration du magasin de fonctionnalités
La diffusion de modèles hérités peut rechercher automatiquement les values des fonctionnalités des magasins en ligne publiés.
.. aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Erreurs connues
ResolvePackageNotFound: pyspark=3.1.0
Cette erreur peut se produire si un modèle dépend de pyspark et est journalisé avec Databricks Runtime 8.x.
Si vous voyez cette erreur, spécifiez la version pyspark explicitement lors de la journalisation du modèle, en utilisant le paramètre conda_env.
Unrecognized content type parameters: format
Cette erreur peut se produire en raison du nouveau format de protocole de scoring MLflow 2.0. Si vous voyez cette erreur, vous utilisez probablement un format de demande de scoring obsolète. Pour résoudre l’erreur, vous pouvez :
Update le format de votre demande de scoring vers le protocole le plus récent.
Remarque
Les exemples suivants reflètent le format de scoring introduit dans MLflow 2.0. Si vous préférez utiliser MLflow 1.x, vous pouvez modifier vos appels d’API
log_model()pour inclure la dépendance de version MLflow souhaitée dans le paramètreextra_pip_requirements. Cela garantit que le format de scoring approprié est utilisé.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Interrogez un modèle acceptant les entrées de dataframe pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Interrogez un modèle acceptant les entrées de tenseur. Les entrées de tenseur doivent être mises en forme conformément à la documentation de l’API de TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)PowerBI
Vous pouvez évaluer un jeu de données dans Power BI Desktop en procédant comme suit :
Ouvrez le jeu de données à évaluer.
Accédez à Transformer les données.
Cliquez avec le bouton droit dans le volet gauche et selectCréer une requête.
Accédez à Afficher > Éditeur avancé.
Remplacez le corps de la requête par l’extrait de code ci-dessous, après avoir fourni un
DATABRICKS_API_TOKENapproprié et unMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNommez la requête avec le nom de modèle de votre choix.
Ouvrez l’éditeur de requête avancé pour votre jeu de données et appliquez la fonction de modèle.
Si votre demande de scoring utilise le client MLflow, comme
mlflow.pyfunc.spark_udf(), mettez à niveau votre client MLflow vers la version 2.0 ou ultérieure pour utiliser le format le plus récent. Apprenez-en plus sur le protocole de scoring de modèle MLflow mis à jour dans MLflow 2.0.
Pour plus d’informations sur les formats de données d’entrée acceptés par le serveur (par exemple, format pandas orienté division), consultez la documentation MLflow.