Utilisation des attributs à l’aide de balises
Cet article explique comment utiliser des balises personnalisées et par défaut pour attribuer des charges de travail à des espaces de travail, des équipes, des projets et des utilisateurs spécifiques.
Pour superviser les coûts et attribuer avec précision l’utilisation d’Azure Databricks aux unités et équipes commerciales de votre organisation (pour les rétrofacturations, par exemple), vous pouvez étiqueter les espaces de travail (groupes de ressources) et les ressources de calcul. Ces étiquettes s’étendent aux rapports d’analyse des coûts détaillés auxquels vous pouvez accéder dans le portail Azure. Remarque : Les données d’étiquette peuvent être répliquées globalement. N’utilisez pas de noms de balise ou de valeurs susceptibles de compromettre la sécurité de vos ressources. Par exemple, n’utilisez pas de noms d’étiquettes qui contiennent des informations personnelles ou sensibles.
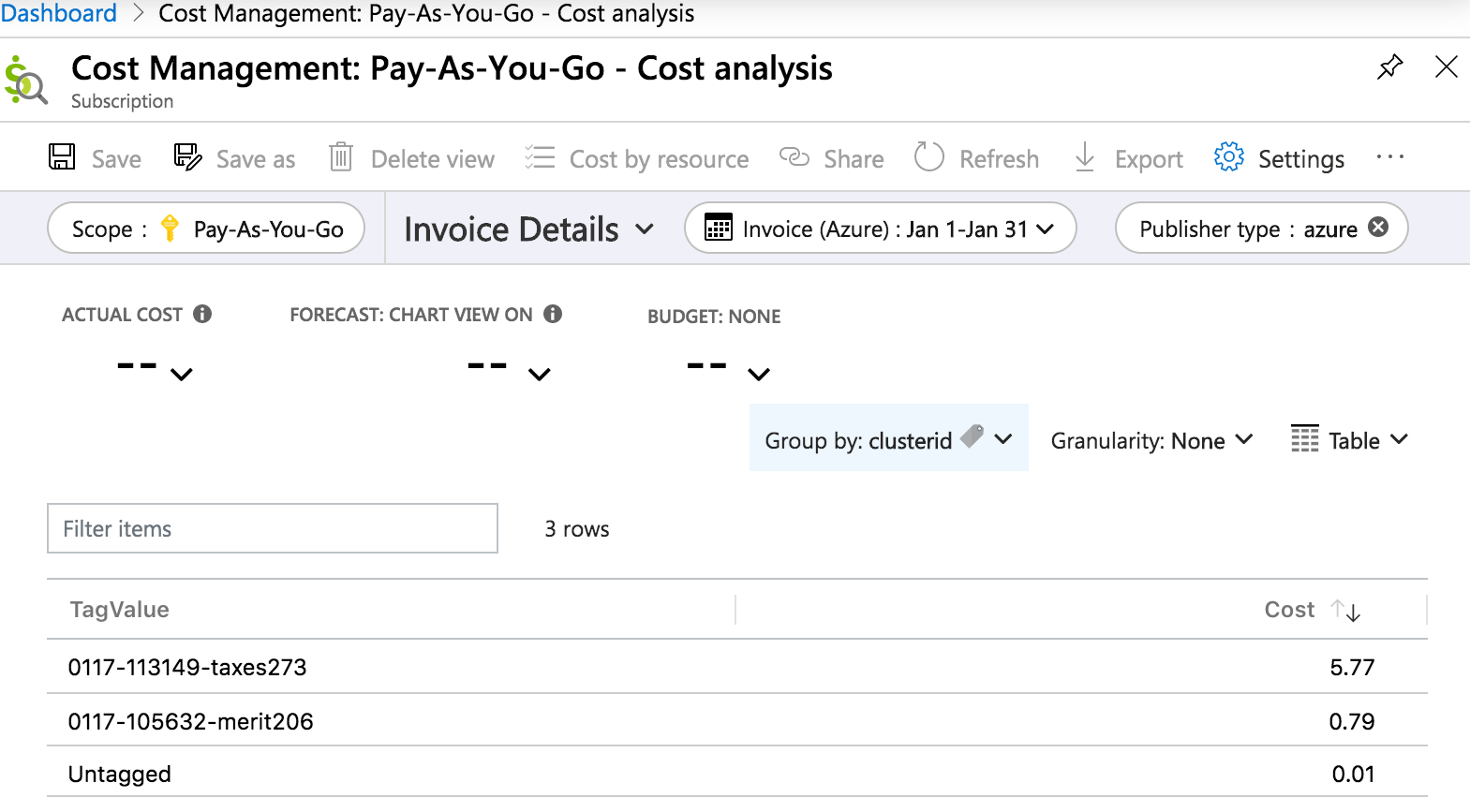
Voici un rapport des détails de la facture d’analyse des coûts dans le Portail Azure qui détaille le coût par étiquette clusterid sur une période d’un mois :
Ressources et objets étiquetés
| Object | Interface d’étiquetage (IU) | Interface d’étiquetage (API) |
|---|---|---|
| Espace de travail | Portail Azure | API des ressources Azure |
| pool | Interface utilisateur des pools dans l’espace de travail Azure Databricks | API du pool d’instances |
| Calculs polyvalents et calculs de tâches | Interface utilisateur de calcul dans l’espace de travail Azure Databricks | API Clusters |
| Entrepôt SQL | Interface utilisateur de l’entrepôt SQL dans l’espace de travail Azure Databricks | API Warehouses |
Avertissement
N’assignez pas de balise personnalisée avec la clé Name à un cluster. Chaque cluster possède une balise Name dont la valeur est définie par Azure Databricks. Si vous modifiez la valeur associée à la clé Name , le suivi du cluster ne peut plus être effectué par Azure Databricks. Par conséquent, il se peut que le cluster ne se termine pas après avoir été inactif et continue à entraîner des coûts d’utilisation.
Balises par défaut
Azure Databricks ajoute les balises par défaut suivantes à l’unité de calcul polyvalente :
| Clé à étiquettes | Valeur |
|---|---|
Vendor |
Valeur constante : Databricks |
ClusterId |
ID interne Azure Databricks du cluster |
ClusterName |
Nom du cluster |
Creator |
Nom d’utilisateur (adresse e-mail) de l’utilisateur qui a créé le cluster |
Sur les clusters de travail, Azure Databricks applique également les étiquettes par défaut suivantes :
| Clé à étiquettes | Valeur |
|---|---|
RunName |
Nom du travail |
JobId |
ID de travail |
Azure Databricks ajoute les étiquettes par défaut suivantes à tous les pools :
| Clé à étiquettes | Valeur |
|---|---|
Vendor |
Valeur constante : Databricks |
DatabricksInstancePoolCreatorId |
ID interne Azure Databricks de l’utilisateur qui a créé le pool |
DatabricksInstancePoolId |
ID interne Azure Databricks du pool |
Sur l’ordinateur utilisé par Lakehouse Monitoring, Azure Databricks applique également les balises suivantes :
| Clé à étiquettes | Valeur |
|---|---|
LakehouseMonitoring |
true |
LakehouseMonitoringTableId |
ID de la table surveillée |
LakehouseMonitoringWorkspaceId |
ID de l'espace de travail où le moniteur a été créé |
LakehouseMonitoringMetastoreId |
ID du métastore où existe la table surveillée |
Baliser les charges de travail de calcul serverless
Essentiel
Cette fonctionnalité est disponible en préversion publique.
Pour attribuer l’utilisation du calcul serverless aux utilisateurs, aux groupes ou aux projets, vous pouvez utiliser des stratégies budgétaires. Lorsqu’un utilisateur reçoit une stratégie budgétaire, son utilisation serverless est automatiquement marquée avec les balises de sa stratégie. Consultez l’utilisation serverless de l’attribut avec des stratégies budgétaires.
Propagation des étiquettes
Les étiquettes d’espace de travail, de pool et de cluster sont agrégées par Azure Databricks et propagées aux machines virtuelles Azure à des fins de création de rapports d’analyse des coûts. Toutefois, les balises du pool et du cluster sont propagées différemment les uns des autres.
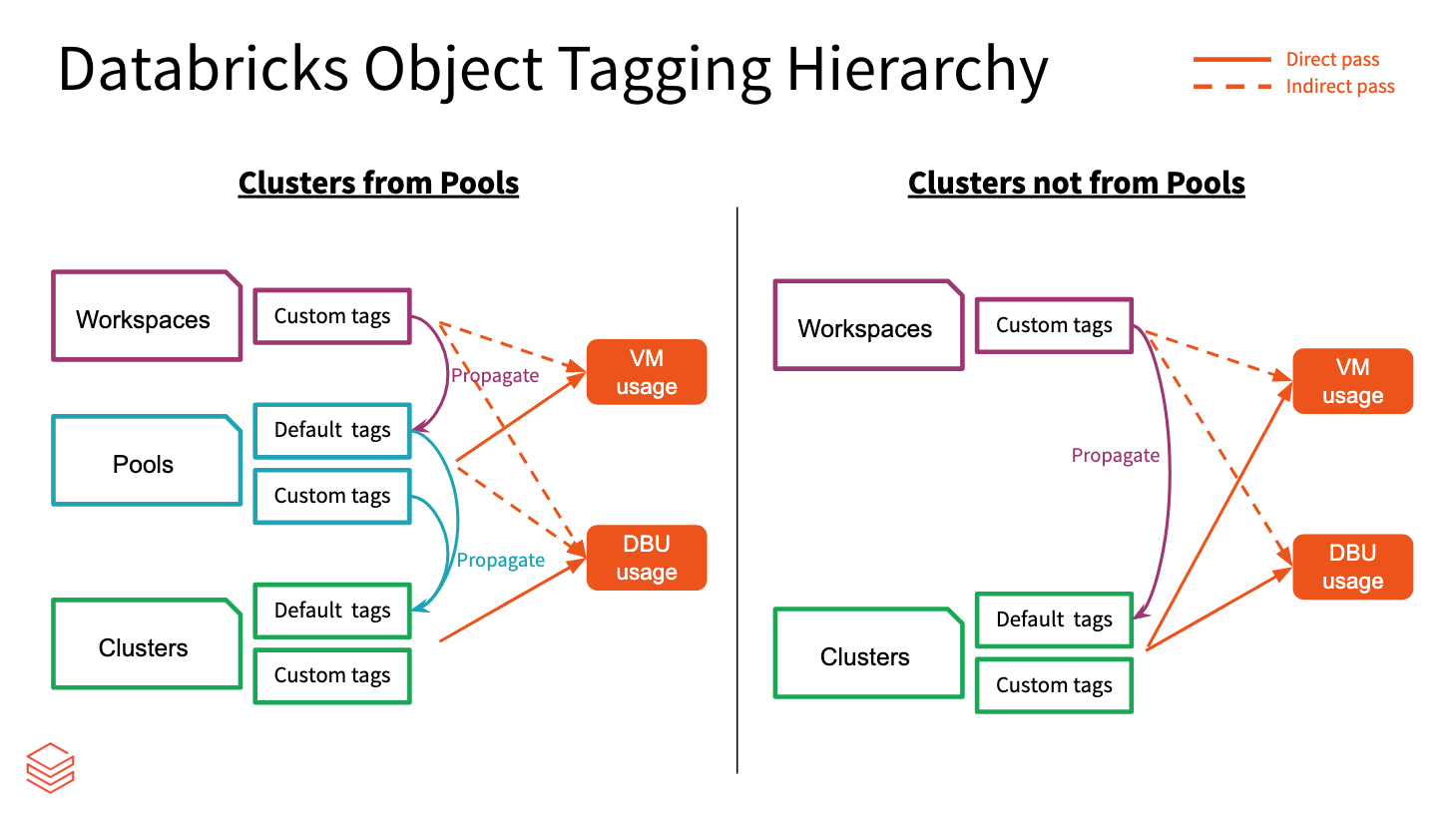
Les étiquettes d’espace de travail et de pool sont agrégées et affectées en tant qu’étiquettes de ressource des machines virtuelles Azure qui hébergent les pools.
Les étiquettes d’espace de travail et de cluster sont agrégées et affectées en tant qu’étiquettes de ressource des machines virtuelles Azure qui hébergent les clusters.
Lorsque les clusters sont créés à partir de pools, seules les étiquettes d’espace de travail et les étiquettes de pool sont propagées aux machines virtuelles. Les étiquettes de cluster ne sont pas propagées afin de conserver les performances de démarrage du cluster de pool.
Résolution des conflits d’étiquettes
Si une étiquette personnalisée de cluster, de pool ou d’espace de travail porte le même nom qu’une étiquette de pool ou de cluster par défaut Azure Databricks, l’étiquette personnalisée est dotée du préfixe x_ quand elle est propagée.
Par exemple, si un espace de travail est étiqueté avec vendor = Azure Databricks, cette étiquette est en conflit avec l’étiquette de cluster par défaut vendor = Databricks. Les étiquettes sont donc propagées en tant que x_vendor = Azure Databricks et vendor = Databricks.
Limites
- Il peut falloir jusqu’à une heure pour que les étiquettes d’espace de travail personnalisées se propagent à Azure Databricks après toute modification.
- Vous ne pouvez pas assigner plus de 50 étiquettes à une ressource Azure. Si le nombre total d’étiquettes agrégées dépasse cette limite, les étiquettes dotées du préfixe
x_sont évaluées dans l’ordre alphabétique et celles qui dépassent la limite sont ignorées. Si toutes les étiquettes dotées du préfixex_sont ignorées et que le nombre dépasse toujours la limite, les étiquettes restantes sont évaluées dans l’ordre alphabétique et celles qui dépassent la limite sont ignorées. - Les touches de balise et les valeurs ne peuvent contenir que des lettres, des espaces, des chiffres ou des caractères
+, ,-,=,._,:,/,@. Les balises contenant d’autres caractères ne sont pas valides. - Si vous modifiez les noms ou les valeurs de clé d’étiquette, ces modifications s’appliquent uniquement après le redémarrage du cluster ou le développement du pool.
- Si les étiquettes personnalisées du cluster sont en conflit avec les étiquettes personnalisées d’un pool, le cluster ne peut pas être créé.
- Les balises d'espace de travail nouvellement ajoutées ne se propagent pas automatiquement aux ressources de calcul existantes. Pour propager les nouvelles balises, ouvrez la page de détails de la ressource de calcul, cliquez sur Modifier, puis Confirmer et redémarrer.
Meilleures pratiques en matière de balisage
- Étant donné que les étiquettes peuvent être entrées manuellement, votre organisation doit normaliser ses paires clé-valeur. Databricks recommande de développer une politique d'entreprise pour le nommage des clés et valeurs que vous pouvez partager avec tous les utilisateurs.
- Toutes les ressources doivent être marquées avec des clés générales qui attribuent l’utilisation à une unité commerciale ou à un projet. Par exemple, une ressource de calcul de travail créée par l’équipe financière pour son budget annuel peut inclure les balises
business-unit:financeetproject:annual-budget. - Pour obtenir des insights plus granulaires, affectez des étiquettes à l’aide de clés de haute spécificité. Par exemple, vous pouvez créer des clés basées sur des rôles, des produits, des services ou des clients.
- Le cas échéant, les administrateurs d’espace de travail doivent appliquer des balises à l’aide de stratégies de calcul et de stratégies budgétaires. Consultez Mise en application des balises personnalisées.