Qu’est-ce que le data wrangling ?
S’APPLIQUE À :  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Data wrangling implique la transformation et la reformatage des données à partir de sa source d’origine afin de la rendre plus appropriée et utile pour diverses applications en aval.
Les organisations doivent avoir la possibilité d’explorer leurs données métier critiques pour la préparation des données et le data wrangling afin de fournir une analyse précise de données complexes qui continuent à croître quotidiennement. La préparation des données est nécessaire pour que les organisations puissent utiliser les données dans différents processus d’entreprise et accélérer la rentabilité.
Data Factory vous permet d’effectuer une préparation de données sans code à l’échelle du cloud de manière itérative à l’aide de Power Query. Data Factory s’intègre à Power Query Online et rend les fonctions Power Query M disponibles en tant qu’activité de pipeline.
Data Factory convertit le M généré par l’éditeur mashup Power Query Online en code Spark pour l’exécution à l’échelle du cloud en convertissant M en flux de données Azure Data Factory. Le data wrangling avec Power Query et les flux de données sont particulièrement utiles pour les ingénieurs de données ou les « intégrateurs de données citoyen ».
Cas d'utilisation
Exploration et préparation rapide des données interactives
Plusieurs ingénieurs de données et intégrateurs de données citoyen peuvent explorer et préparer de manière interactive les jeux de données à l’échelle du cloud. Avec l’augmentation du volume, de la variété et de la vélocité des données dans les lacs de données, les utilisateurs ont besoin d’un moyen efficace pour explorer et préparer les jeux de données. Par exemple, vous pourriez avoir à créer un jeu de données qui contient toutes les informations démographiques des nouveaux clients depuis 2017. Vous n’effectuez pas de mappage vers une cible connue. Vous explorez, effectuez le wrangling et préparez les jeux de données pour répondre à une exigence avant de les publier dans le lac. Le wrangling est souvent utilisé dans des scénarios analytiques moins formels. Les jeux de données préparés peuvent être utilisés pour exécuter des transformations et des opérations d’apprentissage automatique en aval.
Préparation agile des données sans code
Les intégrateurs de données citoyen consacrent plus de 60 % de leur temps à la recherche et à la préparation des données. Ils cherchent à le faire sans code pour améliorer la productivité opérationnelle. Permettre aux intégrateurs de données citoyen d’enrichir, de mettre en forme et de publier des données à l’aide d’outils connus comme Power Query Online de façon évolutive améliore considérablement leur productivité. Le wrangling dans Azure Data Factory permet à l’éditeur mashup Power Query Online de donner les moyens aux intégrateurs de données citoyen de corriger les erreurs rapidement, de normaliser les données et de produire des données de haute qualité pour appuyer les décisions commerciales.
Validation et exploration des données
Analysez visuellement vos données sans code pour supprimer les valeurs hors norme et les anomalies, et les rendre aptes à une analyse rapide.
Sources prises en charge
| Connecteur | Format de données | Type d'authentification |
|---|---|---|
| Stockage Blob Azure | CSV, Parquet, Excel | Clé de compte, principal de service, MSI |
| Azure Data Lake Storage Gen1 | CSV, Parquet, Excel | Principal du service, MSI |
| Azure Data Lake Storage Gen2 | CSV, Parquet, Excel | Clé de compte, principal de service, MSI |
| Azure SQL Database | - | Authentification SQL, MSI, Principal de service |
| Azure Synapse Analytics | - | Authentification SQL, MSI, Principal de service |
Editeur de mashup
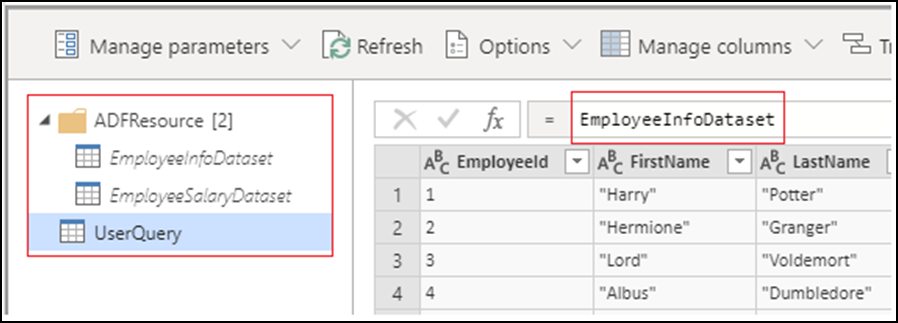
Quand vous créez une activité Power Query, tous les jeux de données sources deviennent des requêtes de jeu de données et sont placés dans le dossier ADFResource. Par défaut, la requête utilisateur pointe vers la première requête de jeu de données. Toutes les transformations doivent être effectuées sur la requête utilisateur, car les modifications apportées aux requêtes de jeu de données ne sont pas prises en charge et ne sont pas rendues persistantes. Le renommage, l’ajout et la suppression de requêtes ne sont pas pris en charge.
Actuellement, toutes les fonctions Power Query M ne sont pas prises en charge pour le rassemblement de données brutes à l’analyse, bien qu’elles soient disponibles pendant la création. Lors de la génération de vos activités Power Query, le message d’erreur suivant s’affiche si une fonction n’est pas prise en charge :
The Power Query Spark Runtime does not support the function
Pour plus d’informations sur les transformations prises en charge, consultez Fonctions de data wrangling Power Query.
Contenu connexe
Découvrez comment créer une composition (mash-up) de data wrangling Power Query.