Copier des données d’une base de données SQL Server vers un stockage Blob Azure
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce tutoriel, vous allez utiliser l’interface utilisateur Azure Data Factory pour créer un pipeline Data Factory qui copie les données d’une base de données SQL Server vers un stockage Blob Azure. Vous allez créer et utiliser un runtime d’intégration auto-hébergé, qui déplace les données entre les banques de données locales et cloud.
Notes
Cet article ne fournit pas de présentation détaillée de Data Factory. Pour plus d’informations, consultez Présentation d’Azure Data Factory.
Dans ce tutoriel, vous effectuerez les étapes suivantes :
- Créer une fabrique de données.
- Créez un runtime d’intégration auto-hébergé.
- Créer des services liés SQL Server et au Stockage Azure.
- Créer des jeux de données SQL Server et Blob Azure.
- Créer un pipeline avec une activité de copie pour déplacer les données.
- Démarrer une exécution de pipeline.
- Surveiller l’exécution du pipeline.
Prérequis
Abonnement Azure
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Rôles Azure
Pour créer des instances de fabrique de données, le compte d’utilisateur que vous utilisez pour vous connecter à Azure doit avoir le rôle de Contributeur ou de Propriétaire, ou être administrateur de l’abonnement Azure.
Pour afficher les autorisations dont vous disposez dans l’abonnement, accédez au portail Azure. Dans l’angle supérieur droit, sélectionnez votre nom d’utilisateur, puis Autorisations. Si vous avez accès à plusieurs abonnements, sélectionnez l’abonnement approprié. Pour obtenir des exemples d’instructions sur l’ajout d’un utilisateur à un rôle, consultez Attribuer des rôles Azure à l’aide du portail Azure.
SQL Server 2014, 2016 et 2017
Dans le cadre de ce tutoriel, vous allez utiliser une base de données SQL Server comme magasin de données source. Le pipeline de la fabrique de données que vous allez créer dans ce tutoriel copie les données de cette base de données SQL Server (source) dans un stockage Blob (récepteur). Créez ensuite un tableau nommé emp dans votre base de données SQL Server, puis insérez-y quelques exemples d’entrées.
Exécutez SQL Server Management Studio. S’il n’est pas déjà installé sur votre machine, accédez à Télécharger SQL Server Management Studio.
Connectez-vous à votre instance SQL Server à l’aide de vos informations d’identification.
Créez un exemple de base de données. Dans l’arborescence, cliquez avec le bouton droit sur Bases de données, puis sur Nouvelle base de données.
Dans la fenêtre Nouvelle base de données, entrez un nom pour la base de données, puis cliquez sur OK.
Pour créer la table emp et y insérer quelques données d’exemple, exécutez le script de requête suivant sur la base de données. Dans l’arborescence, cliquez avec le bouton droit sur la base de données créée, puis sur Nouvelle requête.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Compte Azure Storage
Dans ce didacticiel, vous utilisez un compte de stockage Azure à usage général (stockage Blob plus spécifiquement) comme banque de données réceptrice/de destination. Si vous ne possédez pas de compte Stockage Azure à usage général, consultez Créer un compte de stockage. Le pipeline de la fabrique de données que vous créez dans ce tutoriel copie les données de la base de données SQL Server (source) dans un stockage Blob (récepteur).
Obtenir le nom de compte de stockage et la clé de compte
Dans ce didacticiel, vous utilisez le nom et la clé de votre compte de stockage. Pour obtenir le nom et la clé de votre compte de stockage, procédez comme suit :
Connectez-vous au portail Azure avec votre nom d’utilisateur et votre mot de passe Azure.
Dans le volet gauche, sélectionnez Tous les services. Filtrez à l’aide du mot-clé Stockage, puis sélectionnez Comptes de stockage.
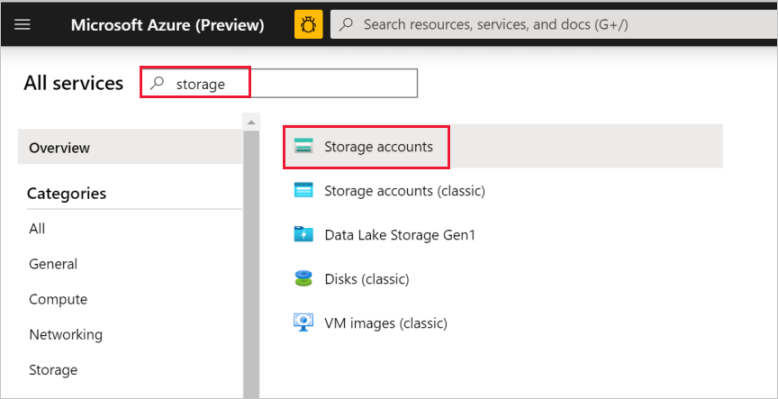
Dans la liste des comptes de stockage, appliquez un filtre pour votre compte de stockage (si nécessaire). Sélectionnez ensuite votre compte de stockage.
Dans la fenêtre Compte de stockage, sélectionnez Clés d’accès.
Dans les zones Nom du compte de stockage et key1, copiez les valeurs, puis collez-les dans le bloc-notes ou un autre éditeur pour une utilisation ultérieure dans le tutoriel.
Créer le conteneur adftutorial
Dans cette section, vous allez créer un conteneur d’objets blob nommé adftutorial dans votre stockage Blob.
Dans la fenêtre Compte de stockage, accédez à Vue d’ensemble, puis sélectionnez Conteneurs.
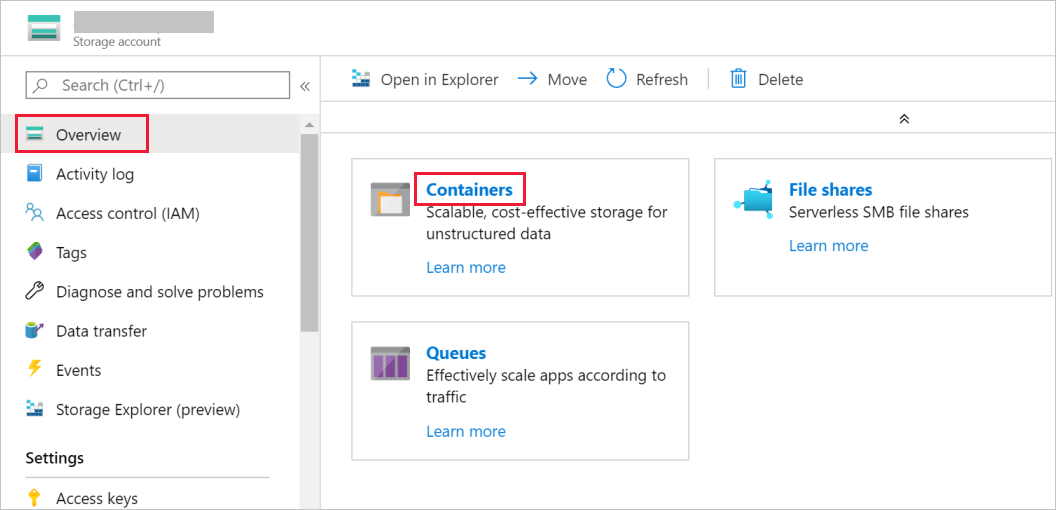
Dans la fenêtre Conteneurs, sélectionnez + Conteneur pour en créer un.
Dans la fenêtre Nouveau conteneur, sous Nom, entrez adftutorial. Sélectionnez ensuite Créer.
Dans la liste des conteneurs, sélectionnez adftutorial que vous venez de créer.
Gardez la fenêtre conteneur de adftutorial ouverte. Elle vous permet de vérifier la sortie à la fin du tutoriel. Data Factory crée automatiquement le dossier de sortie de ce conteneur, de sorte que vous n’avez pas besoin d’en créer.
Créer une fabrique de données
À cette étape, vous allez créer une fabrique de données et démarrer l’interface utilisateur de Data Factory afin de créer un pipeline dans la fabrique de données.
Ouvrez le navigateur web Microsoft Edge ou Google Chrome. L’interface utilisateur de Data Factory n’est actuellement prise en charge que par les navigateurs web Microsoft Edge et Google Chrome.
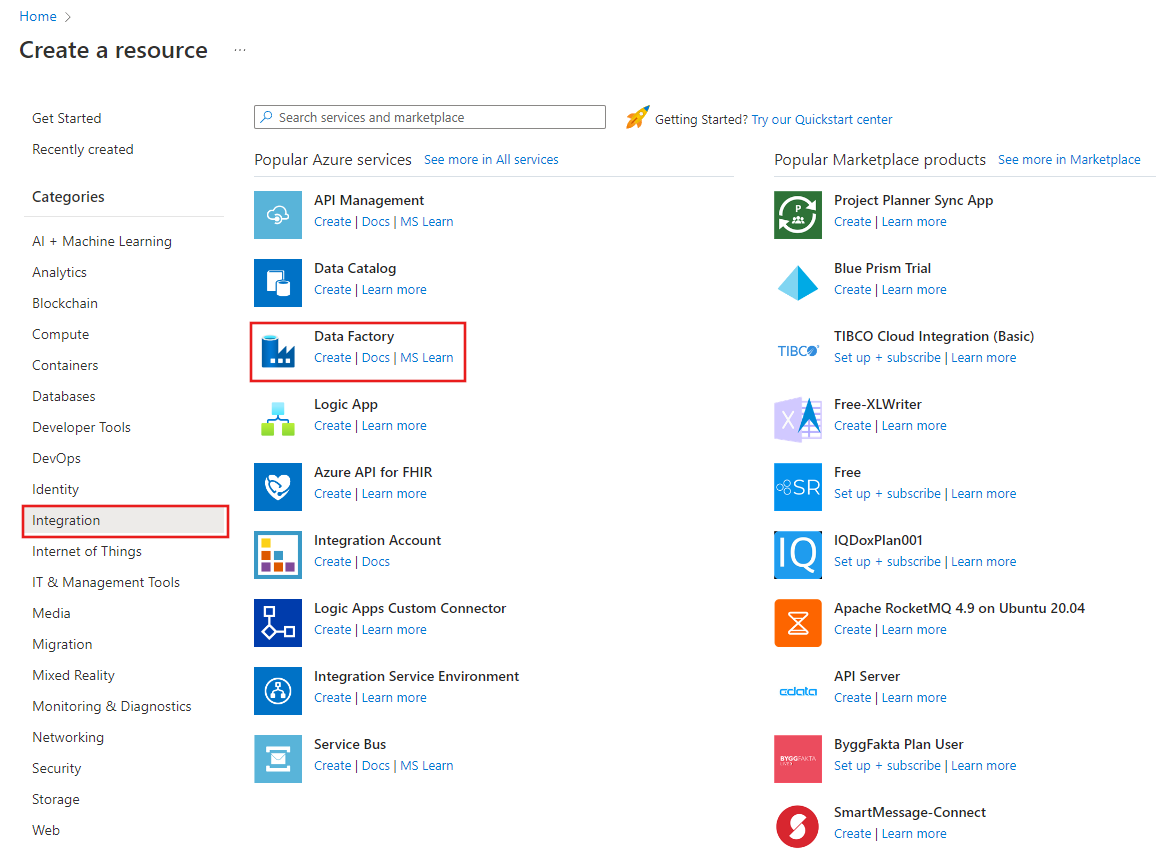
Dans le menu de gauche, sélectionnez Créer une ressource>Intégration>Data Factory :
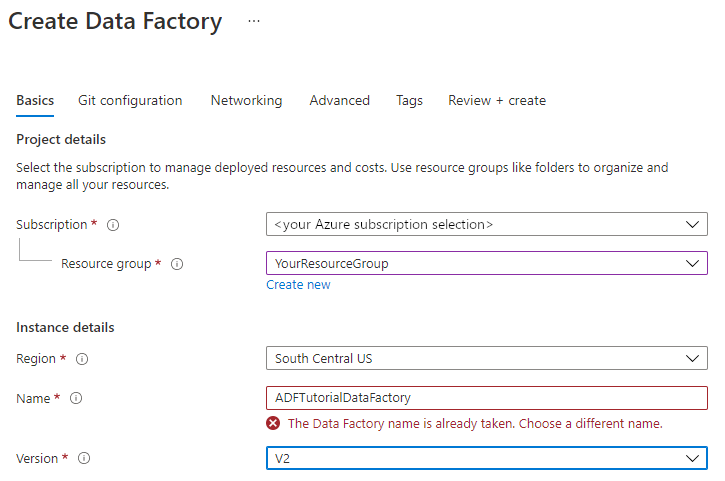
Sur la page Nouvelle fabrique de données, entrez ADFTutorialDataFactory dans le champ Nom.
Le nom de la fabrique de données doit être un nom global unique. Si le message d’erreur suivant s’affiche pour le champ du nom, modifiez le nom de la fabrique de données (par exemple, votrenomADFTutorialDataFactory). Consultez l’article Azure Data Factory - Règles d’affectation des noms pour savoir comment nommer les règles Data Factory.
Sélectionnez l’abonnement Azure dans lequel vous voulez créer la fabrique de données.
Pour Groupe de ressources, réalisez l’une des opérations suivantes :
Sélectionnez Utiliser l’existant, puis sélectionnez un groupe de ressources existant dans la liste déroulante.
Sélectionnez Créer, puis entrez le nom d’un groupe de ressources.
Pour plus d’informations sur les groupes de ressources, consultez Utilisation des groupes de ressources pour gérer vos ressources Azure.
Sous Version, sélectionnez V2.
Sous Emplacement, sélectionnez l’emplacement de la fabrique de données. Seuls les emplacements pris en charge sont affichés dans la liste déroulante. Les magasins de données (tels que le Stockage Azure et SQL Database) et les services de calcul (comme Azure HDInsight) utilisés par Data Factory peuvent se trouver dans d’autres régions.
Sélectionnez Create (Créer).
Une fois la création terminée, la page Data Factory s’affiche comme sur l’image :

Sélectionnez Ouvrir dans la vignette Ouvrir Azure Data Factory Studio pour lancer l’interface utilisateur de Data Factory dans un onglet distinct.
Créer un pipeline
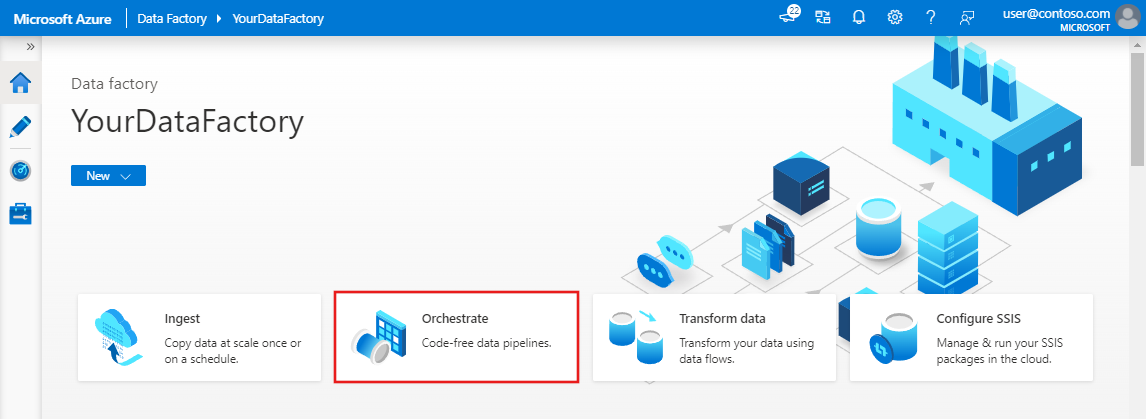
Dans la page d’accueil d’Azure Data Factory, sélectionnez Orchestrer. Un pipeline est automatiquement créé pour vous. Le pipeline apparaît dans l’arborescence et son éditeur s’ouvre.
Dans le volet Général, sous Propriétés, spécifiez SQLServerToBlobPipeline comme Nom. Réduisez ensuite le panneau en cliquant sur l’icône Propriétés en haut à droite.
Dans la boîte à outils Activités, développez Déplacer et transformer. Faites glisser et déposez l’activité Copier sur l’aire de conception du pipeline. Définissez le nom de l’activité sur CopySqlServerToAzureBlobActivity.
Dans la fenêtre Propriétés, accédez à l’onglet Source, puis sélectionnez + Nouveau.
Dans la boîte de dialogue Nouveau jeu de données, recherchez SQL Server. Sélectionnez SQL Server, puis Continuer.
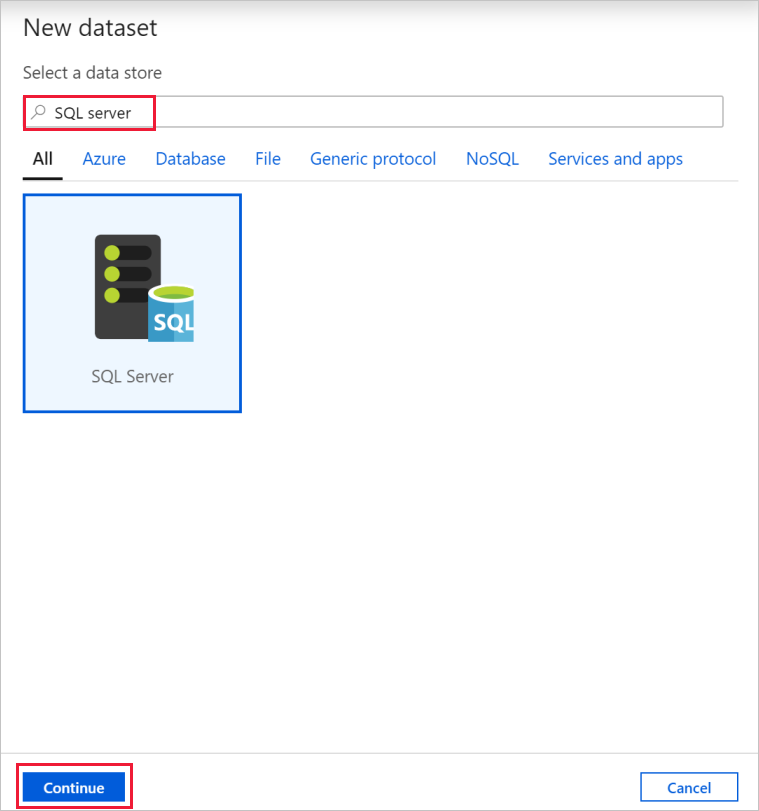
Dans la boîte de dialogue Définir les propriétés, sous Nom, entrez SqlServerDataset. Sous Service lié, sélectionnez + Nouveau. Vous créez une connexion à un magasin de données source (base de données SQL Server) dans cette étape.
Dans la boîte de dialogue Nouveau service lié, ajoutez SqlServerLinkedService comme Nom. Sous Se connecter via le runtime d’intégration sélectionnez + Nouveau. Dans cette section, vous allez créer un runtime d’intégration auto-hébergé et l’associer à un ordinateur local avec la base de données SQL Server. Le runtime d’intégration auto-hébergé est le composant qui copie les données de la base de données SQL Server sur votre machine dans le stockage Blob.
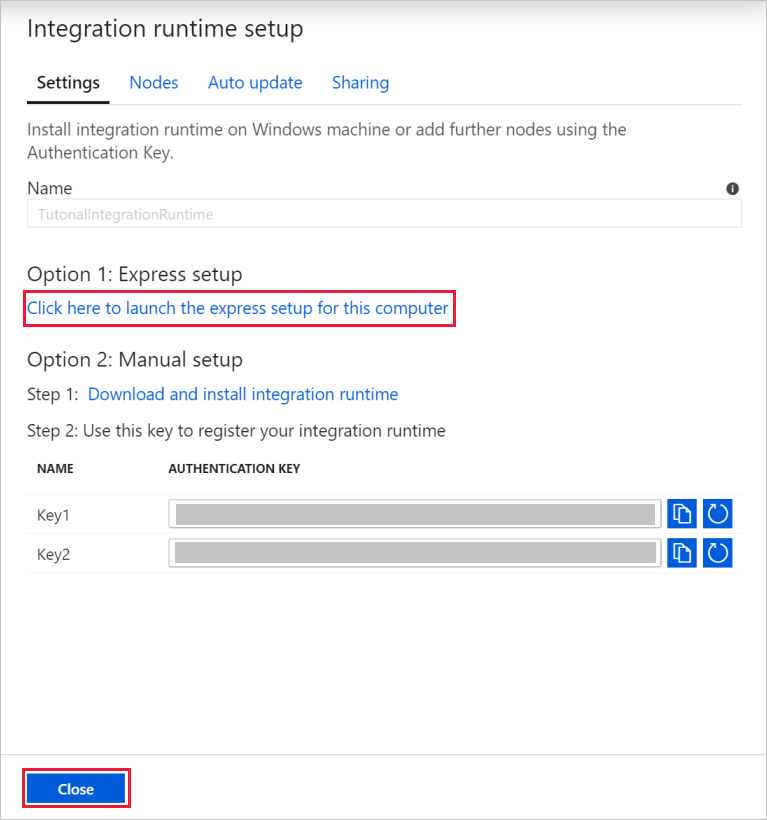
Dans la boîte de dialogue Configuration du runtime d’intégration, sélectionnez Auto-hébergé, puis Continuer.
Sous Nom, entrez TutorialIntegrationRuntime. Sélectionnez ensuite Créer.
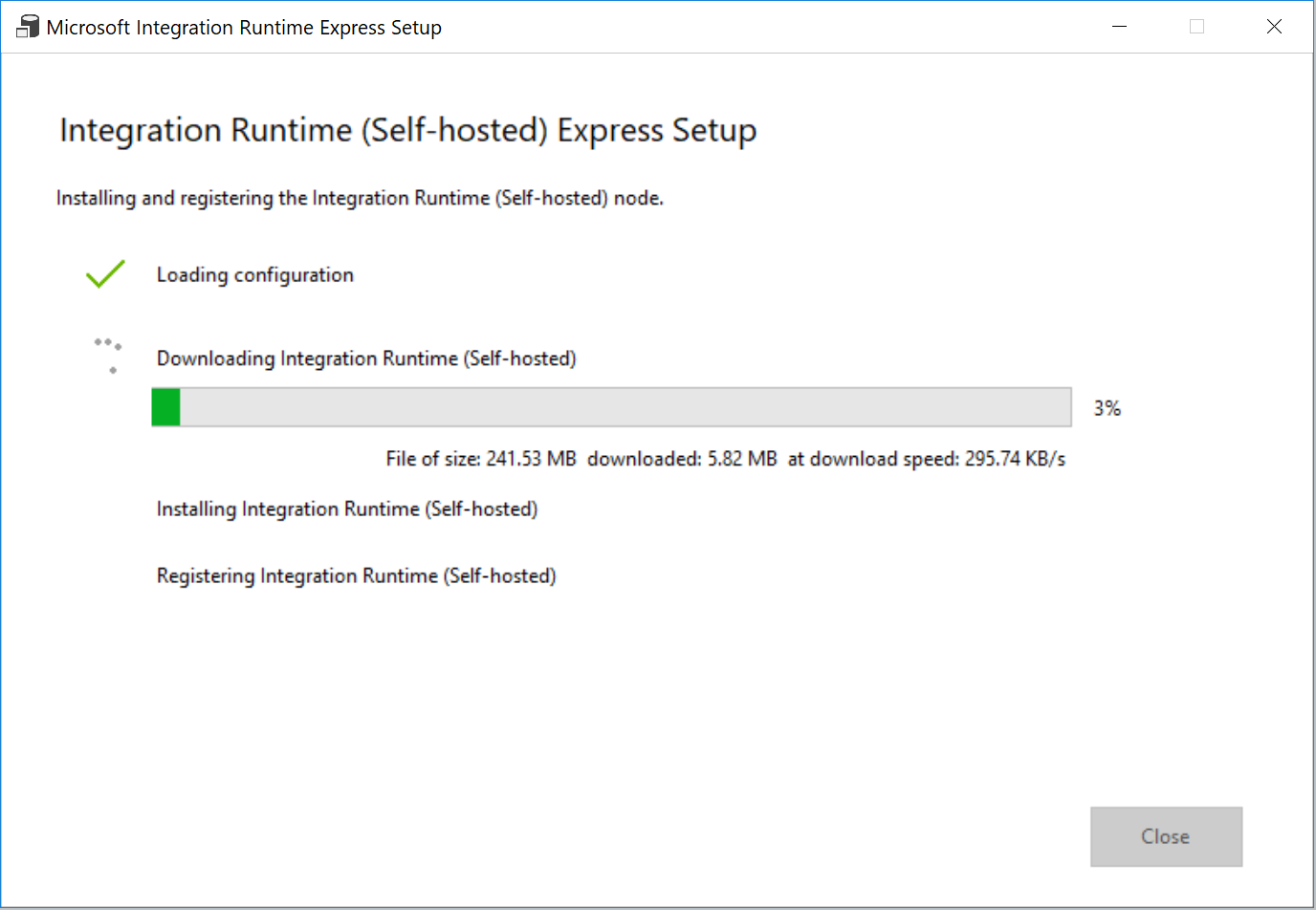
Pour Paramètres, sélectionnez Cliquez ici pour lancer l’installation rapide pour cet ordinateur. Cette action installe le runtime d’intégration sur votre machine et l’inscrit auprès de Data Factory. Vous pouvez également utiliser l’option d’installation manuelle pour télécharger le fichier d’installation, l’exécuter et utiliser la clé pour inscrire le runtime d’intégration.
Dans la fenêtre Installation rapide d’Integration Runtime (auto-hébergé) , sélectionnez Fermer quand le processus est terminé.
Dans la boîte de dialogue Nouveau service lié (SQL Server) , vérifiez que TutorialIntegrationRuntime est sélectionné sous Se connecter via le runtime d’intégration. Ensuite, effectuez les étapes suivantes :
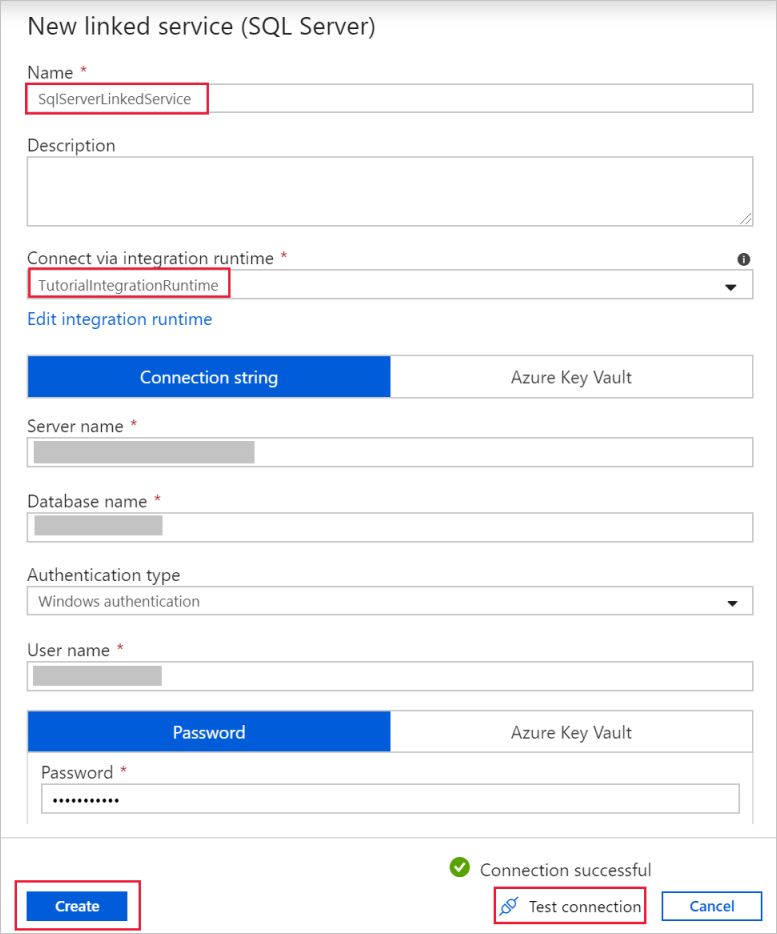
a. Dans le champ Nom, entrez SqlServerLinkedService.
b. Entrez le nom de votre instance SQL Server dans le champ Nom du serveur.
c. Spécifiez le nom de la base de données avec la table emp dans le champ Nom de la base de données.
d. Sous Type d’authentification, sélectionnez le type d’authentification approprié que Data Factory doit utiliser pour se connecter à votre base de données SQL Server.
e. Dans les champs Nom d’utilisateur et Mot de passe, entrez le nom d’utilisateur et le mot de passe. Utilisez mondomaine\monutilisateur comme nom d’utilisateur si nécessaire.
f. Sélectionnez Tester la connexion. Cette étape permet de confirmer que Data Factory peut se connecter à votre base de données SQL Server à l’aide du runtime d’intégration auto-hébergé que vous avez créé.
g. Pour enregistrer le service lié, sélectionnez Créer.
Après la création du service lié, vous revenez à la page Définir les propriétés pour le jeu de données SqlServer. Procédez comme suit :
a. Vérifiez que vous voyez SqlServerLinkedService dans le champ Service lié.
b. Sous Nom de la table, sélectionnez [dbo].[emp] .
c. Sélectionnez OK.
Accédez à l’onglet avec SQLServerToBlobPipeline ou sélectionnez SQLServerToBlobPipeline dans l’arborescence.
Accédez à l’onglet Récepteur au bas de la fenêtre Propriétés, puis sélectionnez + Nouveau.
Dans la boîte de dialogue Nouveau jeu de données, sélectionnez Stockage Blob Azure. Sélectionnez Continuer.
Dans la boîte de dialogue Sélectionner le format, choisissez le type de format de vos données. Sélectionnez Continuer.

Dans la boîte de dialogue Définir les propriétés, entrez AzureBlobDataset comme nom. En regard de la zone de texte Service lié, sélectionnez + Nouveau.
Dans la boîte de dialogue Nouveau service lié (Stockage Blob Azure) , entrez AzureStorageLinkedService comme nom, puis sélectionnez votre compte de stockage dans la liste Nom du compte de stockage. Testez la connexion, puis sélectionnez Créer pour déployer le service lié.
Après la création du service lié, vous revenez à la page Définir les propriétés. Sélectionnez OK.
Ouvrez le jeu de données récepteur. Sous l’onglet Connexion, procédez comme suit :
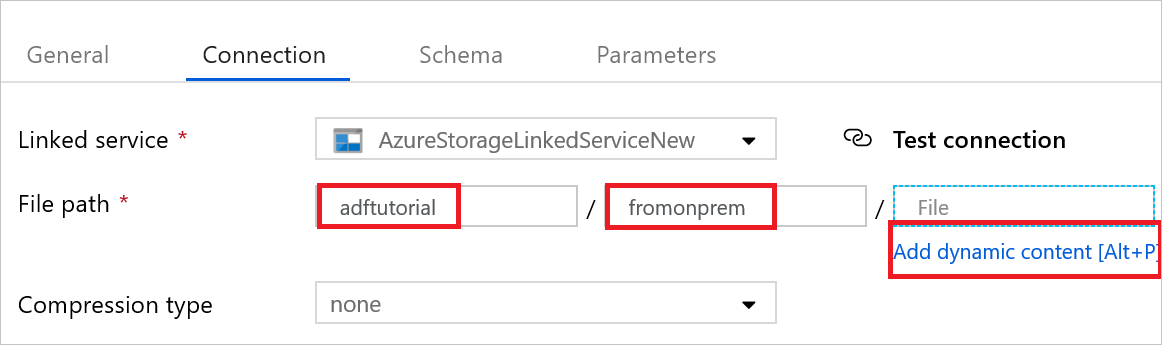
a. Vérifiez que AzureStorageLinkedService est sélectionné dans le champ Service lié.
b. Dans Chemin d’accès du fichier, entrez adftutorial/fromonprem pour la partie Conteneur/répertoire. Si le dossier de sortie n’existe pas dans le conteneur adftutorial, Data Factory crée automatiquement le dossier de sortie.
c. Pour la partie Fichier, sélectionnez Ajouter du contenu dynamique.
d. Ajoutez
@CONCAT(pipeline().RunId, '.txt'), puis sélectionnez Terminer. Cette action a pour effet de renommer le fichier PipelineRunID.txt.Accédez à l’onglet avec le pipeline ouvert ou sélectionnez le pipeline dans l’arborescence. Vérifiez que AzureBlobDataset est sélectionné dans le champ Jeu de données récepteur.
Pour valider les paramètres du pipeline, cliquez sur Valider dans la barre d’outils du pipeline. Pour fermer Sortie de validation de pipeline, sélectionnez l’icône >>.
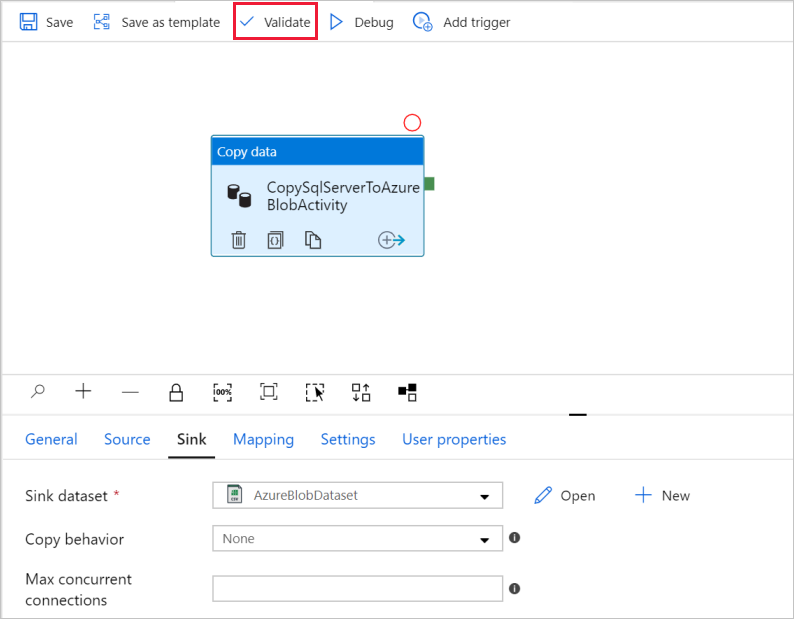
Pour publier les entités que vous avez créées sur Data Factory, sélectionnez Publier tout.
Patientez jusqu’à l’affichage de la fenêtre contextuelle Publishing completed (Publication terminée). Pour vérifier l’état de la publication, sélectionnez le lien Afficher les notifications en haut de la fenêtre. Pour fermer la fenêtre de notification, sélectionnez Fermer.
Déclencher une exécution du pipeline
Sélectionnez Ajouter un déclencheur dans la barre d’outils du pipeline, puis Déclencher maintenant.
Surveiller l’exécution du pipeline.
Accédez à l’onglet Surveiller. Vous voyez le pipeline que vous avez déclenché manuellement à l’étape précédente.
Pour afficher les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien SQLServerToBlobPipeline sous NOM DU PIPELINE.

Dans la page Exécutions d’activités, sélectionnez le lien Détails (image en forme de lunettes) pour afficher des détails sur l’opération de copie. Pour revenir à la vue des exécutions de pipelines, sélectionnez Toutes les exécutions de pipelines en haut.
Vérifier la sortie
Le pipeline crée automatiquement le dossier de sortie nommé fromonprem dans le conteneur d’objets blob adftutorial. Vérifiez que le fichier [pipeline().RunId].txt se trouve dans le dossier de sortie.
Contenu connexe
Dans cet exemple, le pipeline copie les données d’un emplacement vers un autre dans un stockage Blob. Vous avez appris à :
- Créer une fabrique de données.
- Créez un runtime d’intégration auto-hébergé.
- Créez des services liés SQL Server et de stockage.
- Créez des jeux de données SQL Server et de stockage Blob.
- Créer un pipeline avec une activité de copie pour déplacer les données.
- Démarrer une exécution de pipeline.
- Surveiller l’exécution du pipeline.
Pour obtenir la liste des magasins de données pris en charge par Data Factory, consultez l’article sur les magasins de données pris en charge.
Pour découvrir comment copier des données en bloc d’une source vers une destination, passez au didacticiel suivant :