Formats de fichier et codecs de compression pris en charge dans Azure Data Factory et Synapse Analytics (hérité)
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article s’applique aux connecteurs suivants : Amazon S3, Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Stockage Fichier Azure, Système de fichiers, FTP, Google Cloud Storage, HDFS, HTTP et SFTP.
Important
Le service a introduit un nouveau modèle de jeu de données en fonction du format. Pour plus d’informations, consultez l’article relatif à chaque format :
-
Format Avro
-
Format binaire
-
Format de texte délimité
-
Format JSON
-
Format ORC
-
Format Parquet
Les autres configurations mentionnées dans cet article sont toujours prises en charge telles quelles pour des raisons de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Format texte (hérité)
Notes
Découvrez le nouveau modèle dans l’article Format de texte délimité. Les configurations suivantes sur les jeux de données d’un magasin de données basé sur un fichier sont toujours prises en charge telles que pour des raisons de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Si vous souhaitez lire ou écrire des données dans un fichier texte, définissez la propriété type dans la section format du jeu de données sur TextFormat. Vous pouvez également spécifier les propriétés facultatives suivantes, dans la section format. Consultez la section Exemple pour TextFormat pour en savoir plus sur la méthode de configuration à suivre.
| Propriété | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| columnDelimiter | Caractère utilisé pour séparer les colonnes dans un fichier. Vous pouvez envisager d’utiliser un caractère non imprimable rare qui n’existe pas dans vos données. Par exemple, spécifiez « \u0001 », qui représente le début d’en-tête (SOH). | Un seul caractère est autorisé. La valeur par défaut est la virgule (,) . Pour utiliser un caractère Unicode, reportez-vous à l’article sur les caractères Unicode pour obtenir le code correspondant. |
Non |
| rowDelimiter | caractère utilisé pour séparer les lignes dans un fichier. | Un seul caractère est autorisé. La valeur par défaut est l’une des suivantes : [« \r\n », « \r », « \n »] en lecture et « \r\n » en écriture. | Non |
| escapeChar | caractère spécial utilisé pour échapper un délimiteur de colonne dans le contenu du fichier d’entrée. Vous ne pouvez pas spécifier à la fois escapeChar et quoteChar pour une table. |
Un seul caractère est autorisé. Pas de valeur par défaut. Exemple : si vous avez une virgule (« , ») comme séparateur de colonnes, mais que vous souhaitez avoir le caractère virgule dans le texte (exemple : « Hello, world »), vous pouvez définir « $ » comme caractère d’échappement et utiliser la chaîne « Hello$, world » dans la source. |
Non |
| quoteChar | caractère utilisé pour mettre entre guillemets une valeur de chaîne. Les délimiteurs de colonnes et de lignes à l’intérieur des guillemets seraient considérés comme faisant partie de la valeur de chaîne. Cette propriété s’applique aux jeux de données d’entrée et de sortie. Vous ne pouvez pas spécifier à la fois escapeChar et quoteChar pour une table. |
Un seul caractère est autorisé. Pas de valeur par défaut. Par exemple, si vous avez une virgule (,) comme séparateur de colonnes mais que vous voulez avoir le caractère virgule dans le texte (par exemple : <Hello, world>), vous pouvez définir " (guillemet) comme caractère de guillemet et utiliser la chaîne "Hello, world" dans la source. |
Non |
| nullValue | un ou plusieurs caractères utilisés pour représenter une valeur Null. | Un ou plusieurs caractères. Les valeurs par défaut sont « \N » et « NULL » en lecture, et « \N » en écriture. | Non |
| encodingName | spécifiez le nom du codage. | Une liste de noms d’encodage valides. Consultez : Propriété Encoding.EncodingName. Exemple : windows-1250 ou shift_jis. La valeur par défaut est UTF-8. | Non |
| firstRowAsHeader | Spécifie si la première ligne doit être considérée comme un en-tête. Pour un jeu de données d’entrée, le service lit la première ligne comme un en-tête. Pour un jeu de données de sortie, le service écrit la première ligne comme un en-tête. Voir Scénarios d’utilisation de firstRowAsHeader et skipLineCount pour obtenir des exemples de scénarios. |
True false (valeur par défaut) |
Non |
| skipLineCount | Indique le nombre de lignes non vides à ignorer lors de la lecture des données à partir des fichiers d’entrée. Si skipLineCount et firstRowAsHeader sont spécifiés, les lignes sont d’abord ignorées, puis les informations d’en-têtes sont lues à partir du fichier d’entrée. Voir Scénarios d’utilisation de firstRowAsHeader et skipLineCount pour obtenir des exemples de scénarios. |
Integer | Non |
| treatEmptyAsNull | spécifie s’il faut traiter une chaîne Null ou vide comme une valeur Null lors de la lecture des données à partir d’un fichier d’entrée. |
True (valeur par défaut) False |
Non |
Exemple pour TextFormat
Dans la définition JSON suivante d’un jeu de données, certaines propriétés facultatives sont spécifiées.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Pour utiliser un caractère escapeChar au lieu de quoteChar, remplacez la ligne par quoteChar, avec le caractère escapeChar suivant :
"escapeChar": "$",
Scénarios d’utilisation de firstRowAsHeader et skipLineCount
- Vous copiez à partir d’une source hors fichier vers un fichier texte et vous souhaitez ajouter une ligne d’en-tête qui contient les métadonnées de schéma (par exemple : schéma SQL). Définissez le paramètre
firstRowAsHeadersur true dans le jeu de données de sortie pour ce scénario. - Vous copiez à partir d’un fichier texte contenant une ligne d’en-tête vers un récepteur hors fichier et souhaitez supprimer cette ligne. Définissez le paramètre
firstRowAsHeadersur true dans le jeu de données d’entrée. - Vous copiez à partir d’un fichier texte et souhaitez ignorer quelques lignes au début, qui ne contiennent ni données, ni informations d’en-tête. Spécifiez le paramètre
skipLineCountpour indiquer le nombre de lignes à ignorer. Si le reste du fichier contient une ligne d’en-tête, vous pouvez également spécifierfirstRowAsHeader. Si les paramètresskipLineCountetfirstRowAsHeadersont tous deux spécifiés, les lignes sont d’abord ignorées, puis les informations d’en-tête sont lues à partir du fichier d’entrée.
Format JSON (hérité)
Notes
Découvrez le nouveau modèle dans l’article Format JSON. Les configurations suivantes sur les jeux de données d’un magasin de données basé sur un fichier sont toujours prises en charge telles que pour des raisons de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Pour en savoir plus sur l’importation ou l’exportation de fichiers JSON en l’état dans ou à partir d’Azure Cosmos DB, consultez la section Importation/exportation de documents JSON de l’article Déplacer des données vers et depuis Azure Cosmos DB.
Si vous souhaitez analyser des fichiers JSON ou écrire des données au format JSON, définissez la propriété type de la section format sur JsonFormat. Vous pouvez également spécifier les propriétés facultatives suivantes, dans la section format. Consultez la section Exemple pour JsonFormat pour en savoir plus sur la méthode de configuration à suivre.
| Propriété | Description | Obligatoire |
|---|---|---|
| filePattern | Indiquez le modèle des données stockées dans chaque fichier JSON. Les valeurs autorisées sont les suivantes : setOfObjects et arrayOfObjects. La valeur par défaut est setOfObjects. Consultez la section Modèles de fichiers JSON pour en savoir plus sur ces modèles. | Non |
| jsonNodeReference | Si vous souhaitez effectuer une itération et extraire des données à partir des objets situés à l’intérieur d’un champ de tableau présentant le même modèle, spécifiez le chemin d’accès JSON de ce tableau. Cette propriété est uniquement prise en charge lors de la copie de données à partir de fichiers JSON. | Non |
| jsonPathDefinition | Spécifiez l’expression de chemin JSON pour chaque mappage de colonne avec un nom de colonne personnalisé (commencez par une lettre minuscule). Cette propriété est uniquement prise en charge lors de la copie de données à partir de fichiers JSON, et vous pouvez extraire des données d’un objet ou d’un tableau. Pour les champs situés sous l’objet racine, commencez par $ racine ; pour ceux qui se trouvent dans le tableau sélectionné par la propriété jsonNodeReference, commencez par l’élément de tableau. Consultez la section Exemple pour JsonFormat pour en savoir plus sur la méthode de configuration à suivre. |
Non |
| encodingName | spécifiez le nom du codage. Pour obtenir la liste des noms de codage valides, consultez : Propriété Encoding.EncodingName. Par exemple : windows-1250 ou shift_jis. La valeur par défaut est : UTF-8. | Non |
| nestingSeparator | Caractère utilisé pour séparer les niveaux d'imbrication. La valeur par défaut est . (point). | Non |
Notes
Pour une application croisée de données de tableau dans plusieurs lignes (cas 1 -> exemple 2 dans les exemples JsonFormat), vous pouvez uniquement choisir de développer un tableau unique à l’aide de la propriété jsonNodeReference.
Modèles de fichiers JSON
L’activité de copie peut analyser les modèles de fichiers JSON ci-dessous :
Type I : setOfObjects
Chaque fichier contient un objet unique, ou plusieurs objets concaténés/délimités par des lignes. Quand cette option est sélectionnée dans un jeu de données de sortie, l’activité de copie produit un seul fichier JSON contenant un objet par ligne (format délimité par des lignes).
Exemple de fichier JSON à un seul objet
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Exemple de fichier JSON incluant des objets délimités par des lignes
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Exemple de fichier JSON incluant des objets concaténés
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Type II : arrayOfObjects
Chaque fichier contient un tableau d’objets.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Exemple pour JsonFormat
Cas 1 : Copie de données à partir de fichiers JSON
Exemple 1 : Extraire des données d’objet et de tableau
Dans cet exemple, un objet JSON racine doit correspondre à un seul enregistrement dans la table de résultats. Prenons un fichier JSON avec le contenu suivant :
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
Vous voulez copier ce contenu dans un tableau SQL Azure au format suivant, en extrayant les données des objets et du tableau :
| id | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 13/01/2017 11:24:37 |
Le jeu de données d’entrée présentant le type JsonFormat est défini comme suit : (définition partielle présentant uniquement les éléments pertinents). Plus précisément :
- La section
structuredéfinit les noms de colonne personnalisés et le type de données correspondant lors de la conversion des données au format tabulaire. Cette section est facultative, sauf si vous avez besoin d’effectuer un mappage de colonne. Pour plus d’informations, consultez Mapper des colonnes d’un jeu de données source sur des colonnes d’un jeu de données de destination. - Le paramètre
jsonPathDefinitionindique le chemin JSON de chaque colonne indiquant l’emplacement à partir duquel les données sont extraites. Pour copier les données d’un tableau, vous pouvez utiliserarray[x].propertyafin d’extraire la valeur de la propriété spécifiée de l’objetxth, ou vous pouvez utiliserarray[*].propertyafin de trouver la valeur de tout objet contenant cette propriété.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Exemple 2 : application croisée de plusieurs objets avec le même modèle à partir d’un tableau
Dans cet exemple, vous voulez transformer un objet JSON racine en plusieurs enregistrements dans la table de résultats. Prenons un fichier JSON avec le contenu suivant :
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
Vous souhaitez copier ce fichier dans une table SQL Azure au format suivant, en mettant à plat les données se trouvant dans le tableau et en effectuant une jointure croisée avec les informations racines communes :
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
Le jeu de données d’entrée présentant le type JsonFormat est défini comme suit : (définition partielle présentant uniquement les éléments pertinents). Plus précisément :
- La section
structuredéfinit les noms de colonne personnalisés et le type de données correspondant lors de la conversion des données au format tabulaire. Cette section est facultative, sauf si vous avez besoin d’effectuer un mappage de colonne. Pour plus d’informations, consultez Mapper des colonnes d’un jeu de données source sur des colonnes d’un jeu de données de destination. -
jsonNodeReferenceindique que les données doivent être itérées et extraites des objets présentant le même modèle sousorderlinesdans le tableau. - Le paramètre
jsonPathDefinitionindique le chemin JSON de chaque colonne indiquant l’emplacement à partir duquel les données sont extraites. Dans cet exemple, les élémentsordernumber,orderdateetcityse trouvent sous l’objet racine associé au chemin JSON commençant par$., tandis que les élémentsorder_pdetorder_pricesont définis avec le chemin dérivé de l’élément de tableau sans$..
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Notez les points suivants :
- Si les éléments
structureetjsonPathDefinitionne sont pas définis dans le jeu de données, l’activité de copie détecte le schéma à partir du premier objet et aplatit l’objet entier. - Si l’entrée JSON contient un tableau, l’activité de copie convertit la valeur du tableau entier en une chaîne, par défaut. Vous pouvez choisir d’extraire des données de cette dernière à l’aide de
jsonNodeReferenceet/oujsonPathDefinition, ou ignorer cette opération en ne la spécifiant pas dansjsonPathDefinition. - S’il y a plusieurs noms identiques au même niveau, l’activité de copie sélectionne le dernier nom.
- Les noms de propriété respectent la casse. Quand deux propriétés de même nom ont une casse différente, elles sont considérées comme deux propriétés distinctes.
Cas 2 : Écriture de données dans un fichier JSON
Vous disposez de la table suivante dans votre base de données SQL :
| id | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3 500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
Pour chaque enregistrement, vous voulez écrire des données dans un objet JSON, en utilisant le format suivant :
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
Le jeu de données de sortie présentant le type JsonFormat est défini comme suit : (définition partielle présentant uniquement les éléments pertinents). Plus précisément, la section structure définit les noms de propriété personnalisés dans le fichier de destination ; le paramètre nestingSeparator (valeur par défaut : «. ») vous permet d’identifier la couche d’imbrication à partir du nom. Cette section est facultative, sauf si vous souhaitez modifier le nom de propriété par rapport au nom de la colonne source, ou imbriquer certaines propriétés.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Format Parquet (hérité)
Notes
Découvrez le nouveau modèle dans l’article Format Parquet. Les configurations suivantes sur les jeux de données d’un magasin de données basé sur un fichier sont toujours prises en charge telles que pour des raisons de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Si vous souhaitez analyser les fichiers Parquet ou écrire les données au format Parquet, définissez la propriété formattype sur ParquetFormat. Il est inutile de spécifier des propriétés dans la partie Format de la section typeProperties. Exemple :
"format":
{
"type": "ParquetFormat"
}
Notez les points suivants :
- Les types de données complexes ne sont pas pris en charge (MAP, LIST).
- Les espaces blancs dans le nom de colonne ne sont pas pris en charge.
- Le fichier Parquet a les options liées à la compression suivantes : NONE, SNAPPY, GZIP et LZO. Le service prend en charge la lecture des données à partir de fichier Parquet dans tous ces formats compressés sauf LZO ; il utilise le codec de compression dans les métadonnées pour lire les données. Toutefois, lors de l’écriture dans un fichier Parquet, le service choisit SNAPPY, qui est la valeur par défaut pour le format Parquet. Actuellement, il n’existe aucune option permettant de remplacer ce comportement.
Important
Dans le cas de copies permises par Integration Runtime (auto-hébergé), par exemple, entre des magasins de données locaux et cloud, si vous ne copiez pas les fichiers Parquet tels quels, vous devez installer JRE 8 64 bits (Java Runtime Environment) ou OpenJDK sur votre machine de runtime d’intégration. Consultez le paragraphe suivant pour plus de détails.
Dans le cas de copies s’exécutant sur l’IR auto-hébergé avec sérialisation/désérialisation des fichiers Parquet, le service localise le runtime Java en vérifiant d’abord le registre (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) pour JRE puis, s’il ne le trouve pas, en vérifiant la variable système JAVA_HOME pour OpenJDK.
- Pour utiliser JRE : Le runtime d’intégration de 64 bits requiert la version 64 bits de JRE. Vous pouvez la récupérer ici.
- Pour utiliser OpenJDK : il est pris en charge depuis la version 3.13 du runtime d’intégration. Empaquetez jvm.dll avec tous les autres assemblys requis d’OpenJDK dans la machine d’IR auto-hébergé et définissez la variable d’environnement système JAVA_HOME en conséquence.
Conseil
Si, en copiant des données au format Parquet avec le runtime d’intégration auto-hébergé, vous obtenez une erreur indiquant « An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space », vous pouvez ajouter une variable d’environnement _JAVA_OPTIONS sur l’ordinateur qui héberge le runtime d’intégration auto-hébergé afin d’ajuster la taille de segment de mémoire minimale/maximale nécessaire pour que la machine virtuelle Java puisse effectuer une copie de ce type, puis réexécuter le pipeline.
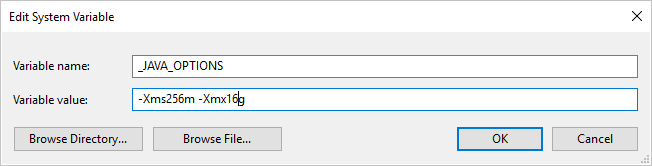
Exemple : donnez la valeur -Xms256m -Xmx16g à la variable _JAVA_OPTIONS. L’indicateur Xms spécifie le pool d’allocation de mémoire initial pour une Machine virtuelle Java (JVM), tandis que Xmx spécifie le pool d’allocation de mémoire maximal. En d’autres termes, JVM démarrera avec la quantité de mémoire Xms et pourra au maximum utiliser la quantité de mémoire Xmx. Par défaut, le service applique un minimum de 64 Mo et un maximum de 1 Go.
Mappage de type de données pour les fichiers Parquet
| Type de données de service intermédiaire | Type primitif Parquet | Type d’origine Parquet (désérialiser) | Type d’origine Parquet (sérialiser) |
|---|---|---|---|
| Boolean | Boolean | N/A | N/A |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/binaire | UInt64 | Decimal |
| Unique | Float | N/A | N/A |
| Double | Double | N/A | N/A |
| Decimal | Binary | Decimal | Decimal |
| String | Binary | Utf8 | Utf8 |
| DateTime | Int96 | N/A | N/A |
| TimeSpan | Int96 | N/A | N/A |
| DateTimeOffset | Int96 | N/A | N/A |
| ByteArray | Binary | N/A | N/A |
| Guid | Binary | Utf8 | Utf8 |
| Char | Binary | Utf8 | Utf8 |
| CharArray | Non pris en charge | N/A | N/A |
Format ORC (hérité)
Notes
Découvrez le nouveau modèle dans l’article Format ORC. Les configurations suivantes sur les jeux de données d’un magasin de données basé sur un fichier sont toujours prises en charge telles que pour des raisons de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Si vous souhaitez analyser les fichiers ORC ou écrire les données au format ORC, définissez la propriété formattype sur OrcFormat. Il est inutile de spécifier des propriétés dans la partie Format de la section typeProperties. Exemple :
"format":
{
"type": "OrcFormat"
}
Notez les points suivants :
- Les types de données complexes ne sont pas pris en charge (STRUCT, MAP, LIST, UNION).
- Les espaces blancs dans le nom de colonne ne sont pas pris en charge.
- Le fichier ORC a trois options liées à la compression : NONE, ZLIB, SNAPPY. Le service prend en charge la lecture des données du fichier ORC dans tous ces formats compressés. Il utilise le codec de compression se trouvant dans les métadonnées pour lire les données. Toutefois, lors de l’écriture dans un fichier ORC, le service choisit ZLIB, qui est la valeur par défaut pour ORC. Actuellement, il n’existe aucune option permettant de remplacer ce comportement.
Important
Dans le cas de copies permises par Integration Runtime (auto-hébergé), par exemple, entre des magasins de données locaux et cloud, si vous ne copiez pas les fichiers ORC tels quels, vous devez installer JRE 8 64 bits (Java Runtime Environment) ou OpenJDK sur votre machine de runtime d’intégration. Consultez le paragraphe suivant pour plus de détails.
Dans le cas de copies s’exécutant sur l’IR auto-hébergé avec sérialisation/désérialisation des fichiers ORC, le service localise le runtime Java en vérifiant d’abord le registre (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) pour JRE puis, s’il ne le trouve pas, en vérifiant la variable système JAVA_HOME pour OpenJDK.
- Pour utiliser JRE : Le runtime d’intégration de 64 bits requiert la version 64 bits de JRE. Vous pouvez la récupérer ici.
- Pour utiliser OpenJDK : il est pris en charge depuis la version 3.13 du runtime d’intégration. Empaquetez jvm.dll avec tous les autres assemblys requis d’OpenJDK dans la machine d’IR auto-hébergé et définissez la variable d’environnement système JAVA_HOME en conséquence.
Mappage de type de données pour fichiers Oracle
| Type de données de service intermédiaire | Types ORC |
|---|---|
| Boolean | Boolean |
| SByte | Byte |
| Byte | Court |
| Int16 | Court |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | String |
| Unique | Float |
| Double | Double |
| Decimal | Decimal |
| String | String |
| DateTime | Timestamp |
| DateTimeOffset | Timestamp |
| TimeSpan | Timestamp |
| ByteArray | Binary |
| Guid | String |
| Char | Char (1) |
Format Avro (hérité)
Notes
Découvrez le nouveau modèle dans l’article Format Avro. Les configurations suivantes sur les jeux de données d’un magasin de données basé sur un fichier sont toujours prises en charge telles que pour des raisons de compatibilité descendante. Nous vous suggérons d’utiliser le nouveau modèle à l’avenir.
Si vous souhaitez analyser les fichiers Avro ou écrire les données au format Avro, définissez la propriété formattype sur AvroFormat. Il est inutile de spécifier des propriétés dans la partie Format de la section typeProperties. Exemple :
"format":
{
"type": "AvroFormat",
}
Pour utiliser le format Avro dans une table Hive, vous pouvez faire référence au didacticiel Apache Hive.
Notez les points suivants :
- Les types de données complexes ne sont pas pris en charge (enregistrements, enums, tables, cartes, unions et fixes).
Prise en charge de la compression (hérité)
Le service prend en charge la compression/décompression des données pendant la copie. Quand vous spécifiez la propriété compression dans un jeu de données d’entrée, l’activité de copie lit les données compressées à partir de la source, puis les décompresse. Quand vous spécifiez la propriété dans un jeu de données de sortie, l’activité de copie compresse les données, puis les écrit dans le récepteur. Voici quelques exemples de scénarios :
- Lire les données compressées GZIP à partir d’un objet blob Azure, les décompresser et écrire des données du résultat dans une Azure SQL Database. Le jeu de données Azure Blob d’entrée est défini avec la propriété
compressiontypeGZip. - Lire les données d’un fichier de texte brut dans le système de fichiers local, les compresser en utilisant le format GZIP et écrire les données compressées dans un objet blob Azure. Un jeu de données Azure Blob de sortie est défini avec la propriété
compressiontypeGZip. - Lire le fichier .zip à partir du serveur FTP, le décompresser pour accéder aux fichiers qu’il contient et placer ces derniers dans Azure Data Lake Store. Le jeu de données FTP d’entrée est défini avec la propriété
compressiontypeZipDeflate. - Lire les données compressées au format GZIP à partir d’un objet blob Azure, les décompresser, les compresser en utilisant le format BZIP2 et écrire les données résultantes dans un objet blob Azure. Le jeu de données Azure Blob d’entrée est défini avec
compressiontypeégal à GZip et le jeu de données de sortie aveccompressiontypeégal à BZIP2.
Pour spécifier la compression pour un jeu de données, utilisez la propriété compression du jeu de données JSON, comme dans l'exemple suivant :
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
La section compression a deux propriétés :
Type : le codec de compression, qui peut être GZIP, Deflate, BZIP2 ou ZipDeflate. Notez que lorsque vous utilisez l’activité de copie pour décompresser un ou plusieurs fichiers ZipDeflate et écrire dans le magasin de données du récepteur basé sur des fichiers, les fichiers sont extraits dans le dossier :
<path specified in dataset>/<folder named as source zip file>/.Level : le taux de compression, qui peut être Optimal ou Fastest.
Fastest (Le plus rapide) : l’opération de compression doit se terminer le plus rapidement possible, même si le fichier résultant n’est pas compressé de façon optimale.
Optimal : l’opération de compression doit aboutir à une compression optimale, même si elle prend plus de temps.
Pour plus d’informations, consultez la rubrique Niveau de compression .
Notes
Les paramètres de compression ne sont pas pris en charge pour les données au format AvroFormat, OrcFormat ou ParquetFormat. Le service détecte et utilise le codec de compression se trouvant dans les métadonnées pour lire des fichiers présentant ces formats. Lors de l’écriture dans des fichiers présentant ces formats, le service choisit le code de la compression par défaut pour ce format. Par exemple, ZLIB pour OrcFormat et SNAPPY pour ParquetFormat.
Types de fichiers et formats de compression non pris en charge
Vous pouvez utiliser les fonctionnalités d’extensibilité pour transformer les fichiers non pris en charge. Parmi les deux options disponibles figurent Azure Functions et les tâches personnalisées par Azure Batch.
Vous pouvez consulter un exemple utilisant une fonction Azure pour extraire le contenu d’un fichier tar. Pour plus d’informations, consultez Activité Azure Functions.
Vous pouvez également créer cette fonctionnalité à l’aide d’une activité dotnet personnalisée. Des informations supplémentaires sont disponibles ici
Contenu connexe
Découvrez les derniers formats de fichiers et compressions pris en charge dans Formats de fichiers et compressions pris en charge.