Transformation avec Azure Databricks
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
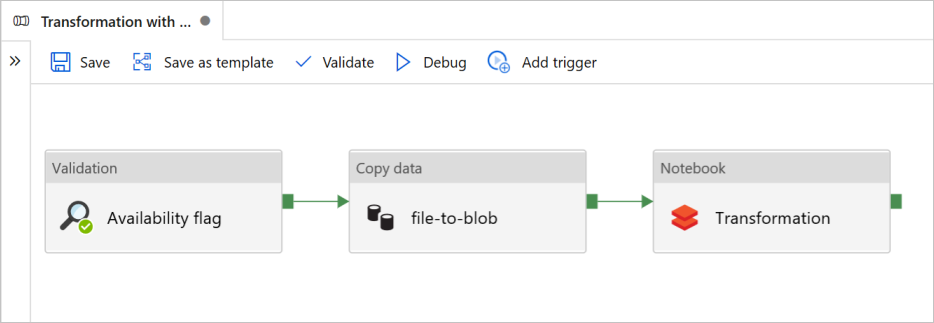
Dans ce tutoriel, vous allez créer un pipeline de bout en bout contenant des activités Validation, Copie des données et Notebook dans Azure Data Factory.
Validation garantit que le jeu de données source est prêt pour la consommation en aval avant que vous ne déclenchiez le travail de copie et d’analytique.
Copie des données duplique le jeu de données source dans le stockage récepteur, qui est monté en tant que DBFS dans le notebook Azure Databricks. De cette façon, le jeu de données peut directement être consommé par Spark.
Notebook déclenche le notebook Databricks qui transforme le jeu de données. Le jeu de données est aussi ajouté à un dossier traité ou à Azure Synapse Analytics.
Par souci de simplicité, le modèle de ce didacticiel ne crée pas de déclencheur planifié. Vous pouvez en ajouter un si nécessaire.
Prérequis
Un compte de stockage Blob Azure avec un conteneur appelé
sinkdataservant de récepteur.Notez le nom du compte de stockage, du conteneur et de la clé d’accès. Vous en aurez besoin plus loin dans le modèle.
Un espace de travail Azure Databricks.
Importer un notebook pour Transformation
Pour importer un notebook Transformation dans votre espace de travail Databricks :
Connectez-vous à votre espace de travail Azure Databricks.
Faites un clic droit sur un dossier dans votre espace de travail, puis sélectionnez Importer.
Sélectionnez Importer depuis : URL. Dans la zone de texte, entrez
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.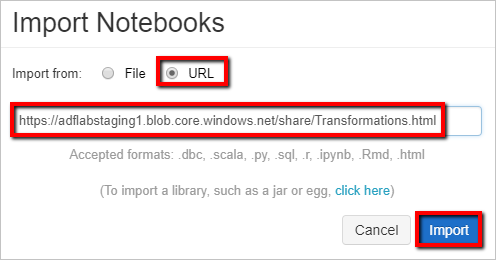
Nous allons maintenant mettre à jour le notebook Transformation avec vos informations de connexion au stockage.
Dans le notebook importé, accédez à la commande 5 comme indiqué dans l’extrait de code suivant.
- Remplacez
<storage name>et<access key>par vos propres informations de connexion au stockage. - Utilisez le compte de stockage muni du conteneur
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Remplacez
Générez un jeton d’accès Databricks pour permettre à Data Factory d’accéder à Databricks.
- Dans votre espace de travail Azure Databricks, sélectionnez votre nom d’utilisateur Azure Databricks dans la barre du haut, puis sélectionnez Paramètres dans la liste déroulante.
- Sélectionnez Développeur.
- À côté de Jetons d’accès, sélectionnez Gérer.
- Sélectionnez Générer un nouveau jeton.
- (Facultatif) Entrez un commentaire qui vous aide à identifier ce jeton à l’avenir et modifiez sa durée de vie par défaut (90 jours). Pour créer un jeton sans durée de vie (non recommandé), laissez vide la zone Durée de vie (en jours).
- Sélectionnez Générer.
- Copiez le jeton affiché dans un emplacement sécurisé, puis sélectionnez Terminé.
Enregistrez le jeton d’accès pour une utilisation ultérieure lors de la création d’un service lié à Databricks. Le jeton d’accès ressemble à dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Comment utiliser ce modèle
Accédez au modèle Transformation avec Azure Databricks et créez des services liés pour les connexions suivantes.
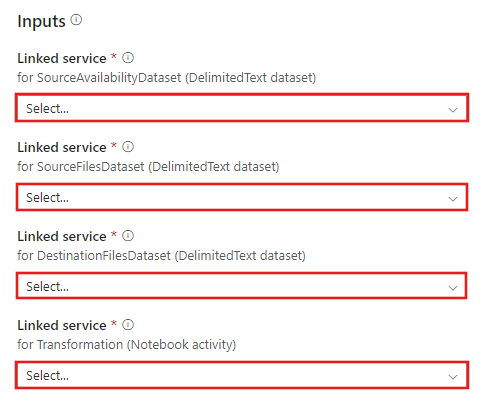
Connexion aux blobs sources : pour accéder aux données sources.
Pour cet exemple, vous pouvez utiliser le stockage de blobs public contenant les fichiers sources. Reportez-vous à la capture d’écran suivante pour la configuration. Utilisez l’URL SAS suivante pour vous connecter au stockage source (accès en lecture seule) :
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D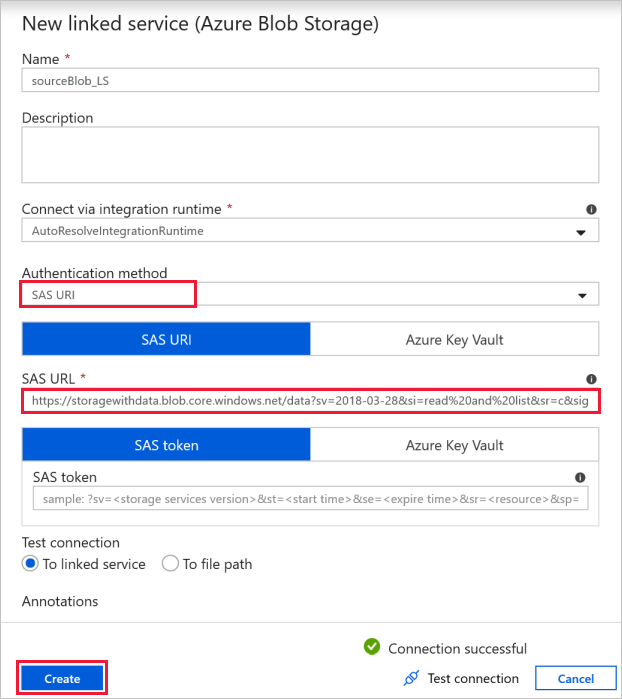
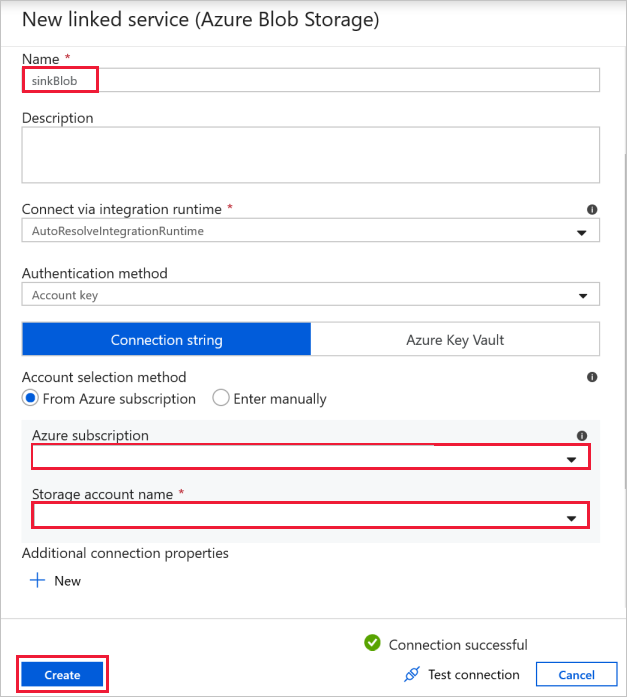
Connexion aux blobs de destination : pour stocker les données copiées.
Dans la fenêtre Nouveau service lié, sélectionnez votre blob de stockage du récepteur.
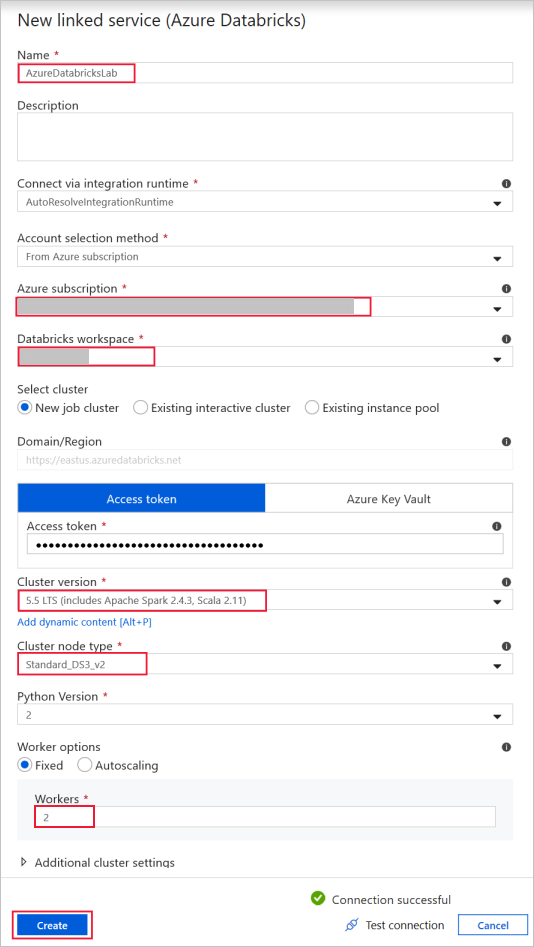
Azure Databricks : pour se connecter au cluster Databricks.
Créez un service lié à Databricks à l’aide de la clé d’accès que vous avez générée précédemment. Vous pouvez choisir de sélectionner un cluster interactif si vous en avez un. Cet exemple utilise l’option Nouveau cluster de travail.
Sélectionnez Utiliser ce modèle. Vous verrez la création d’un pipeline.
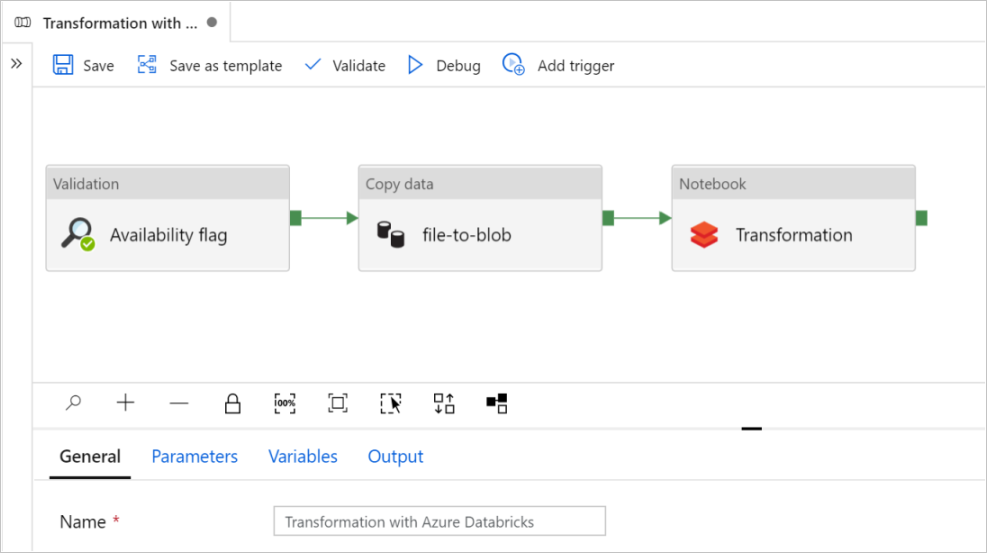
Présentation et configuration du pipeline
Dans le nouveau pipeline, la plupart des paramètres sont configurés automatiquement avec les valeurs par défaut. Passez en revue les configurations de votre pipeline et apportez les modifications nécessaires.
Dans l’indicateur de disponibilité de l’activité Validation, vérifiez que la valeur Jeu de données source est définie sur
SourceAvailabilityDatasetque vous avez créée précédemment.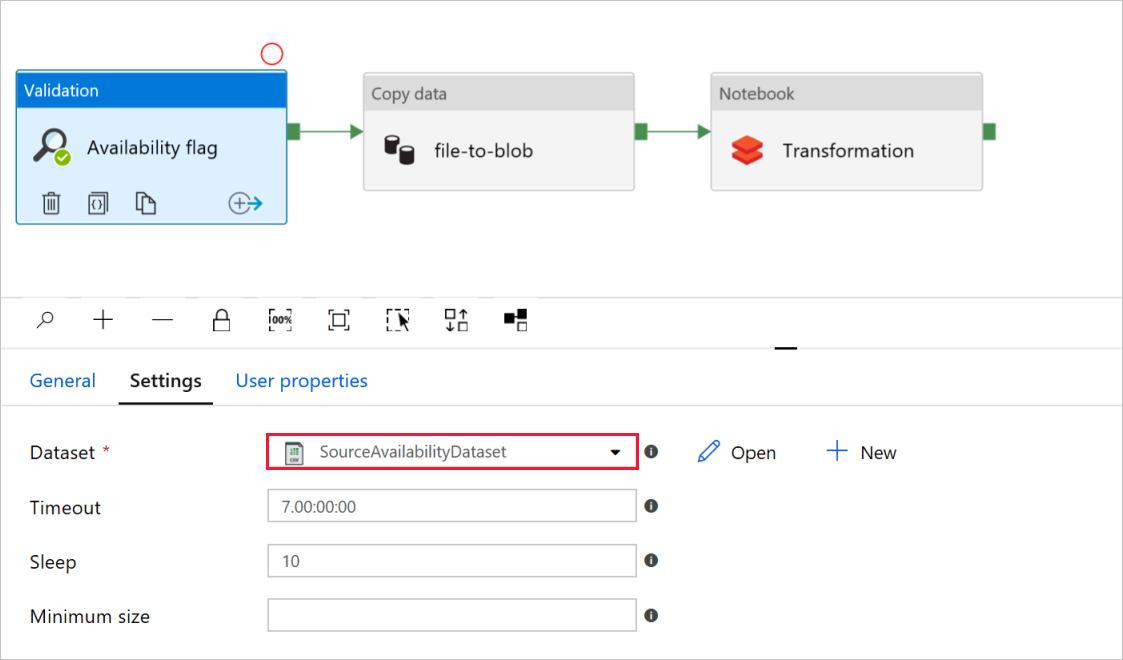
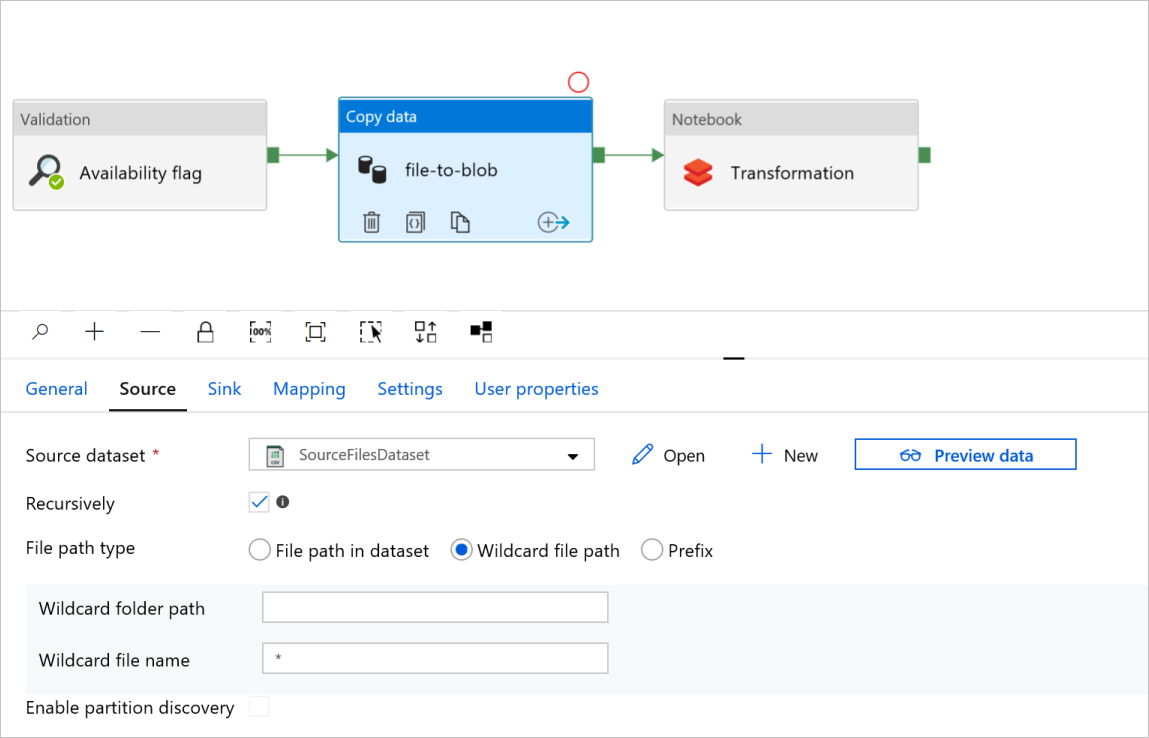
Dans le transfert fichier à blob de l’activité Copie des données, vérifiez les onglets Source et Récepteur. Modifiez les paramètres si nécessaire.
OngletSource
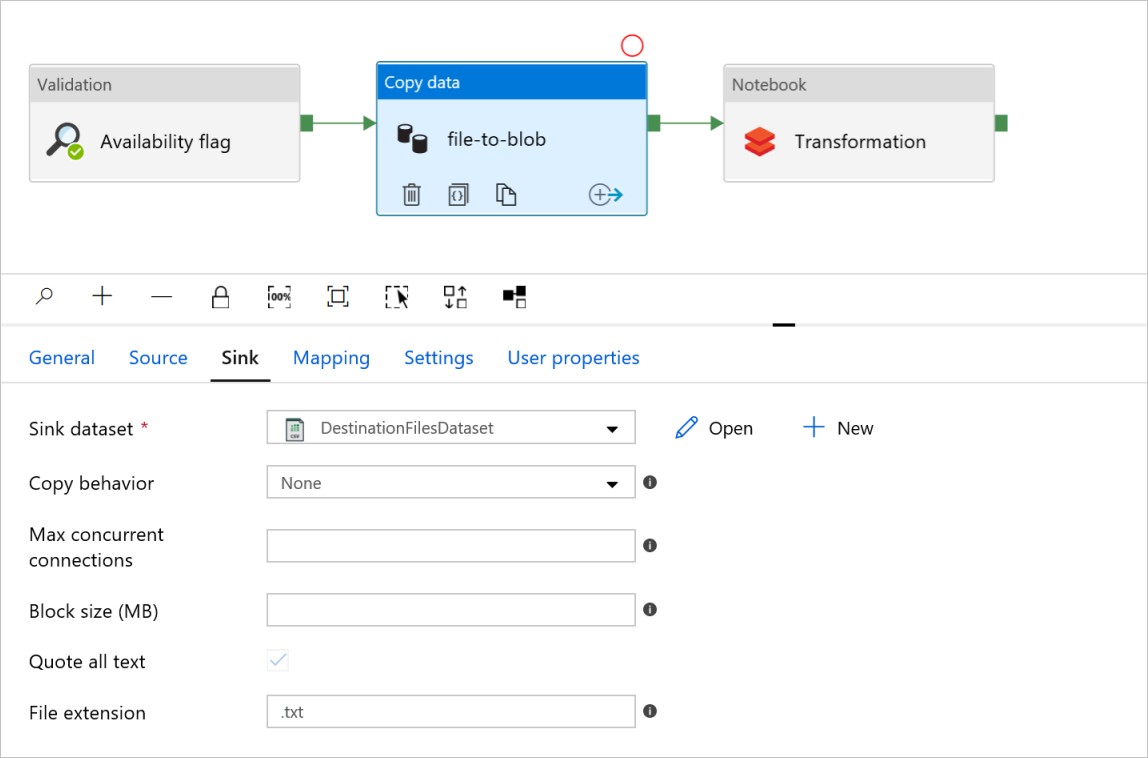
Onglet récepteur
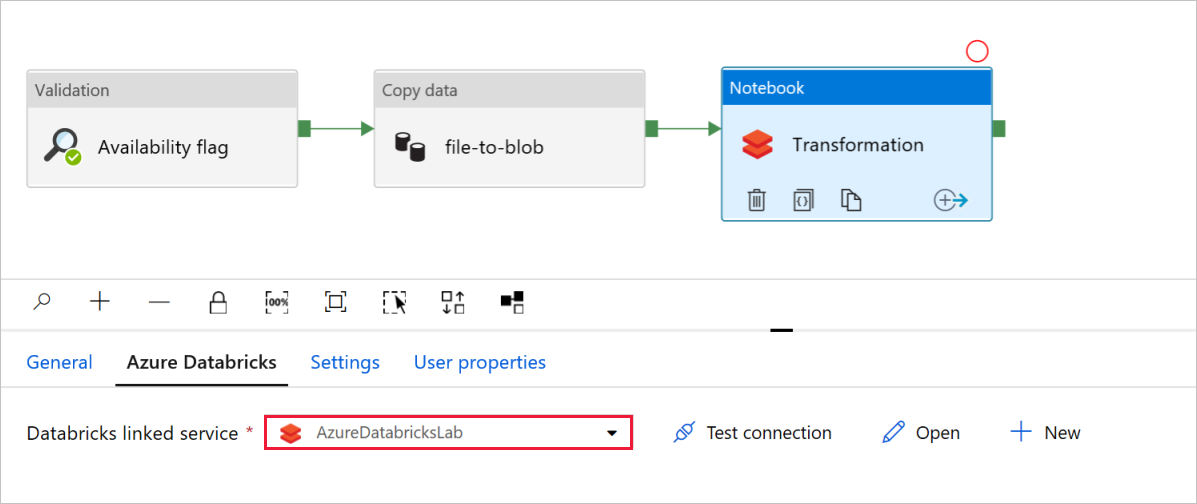
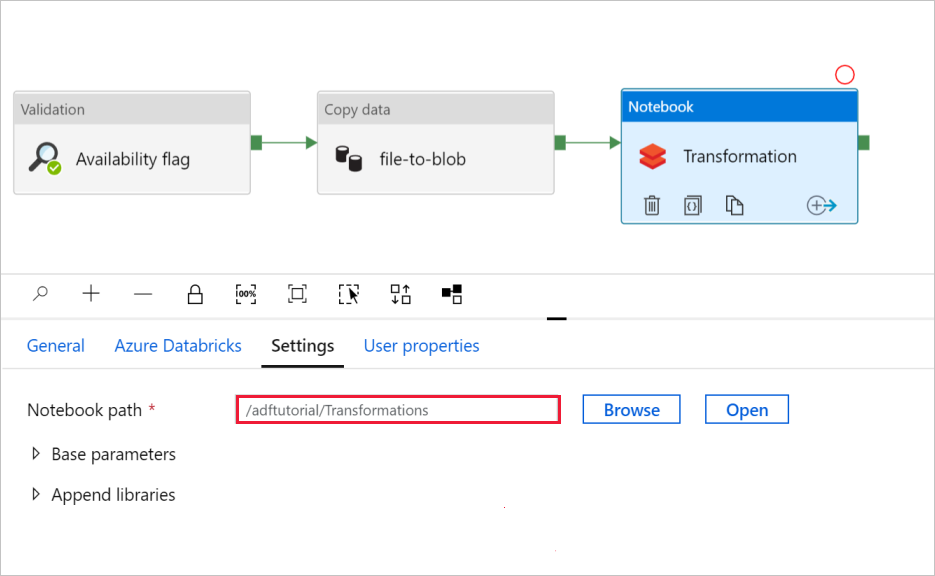
Dans Transformation de l’activité Notebook, passez en revue et mettez à jour les chemins d’accès et les paramètres selon vos besoins.
Le service lié Databricks doit être prérempli avec la valeur d’une étape précédente, comme indiqué dans :
Pour vérifier les paramètres de Notebook :
Sélectionnez l’onglet Paramètres. Pour Chemin d’accès du notebook, vérifiez que le chemin d’accès par défaut est correct. Vous devrez peut-être parcourir et sélectionner le chemin d’accès approprié du notebook.
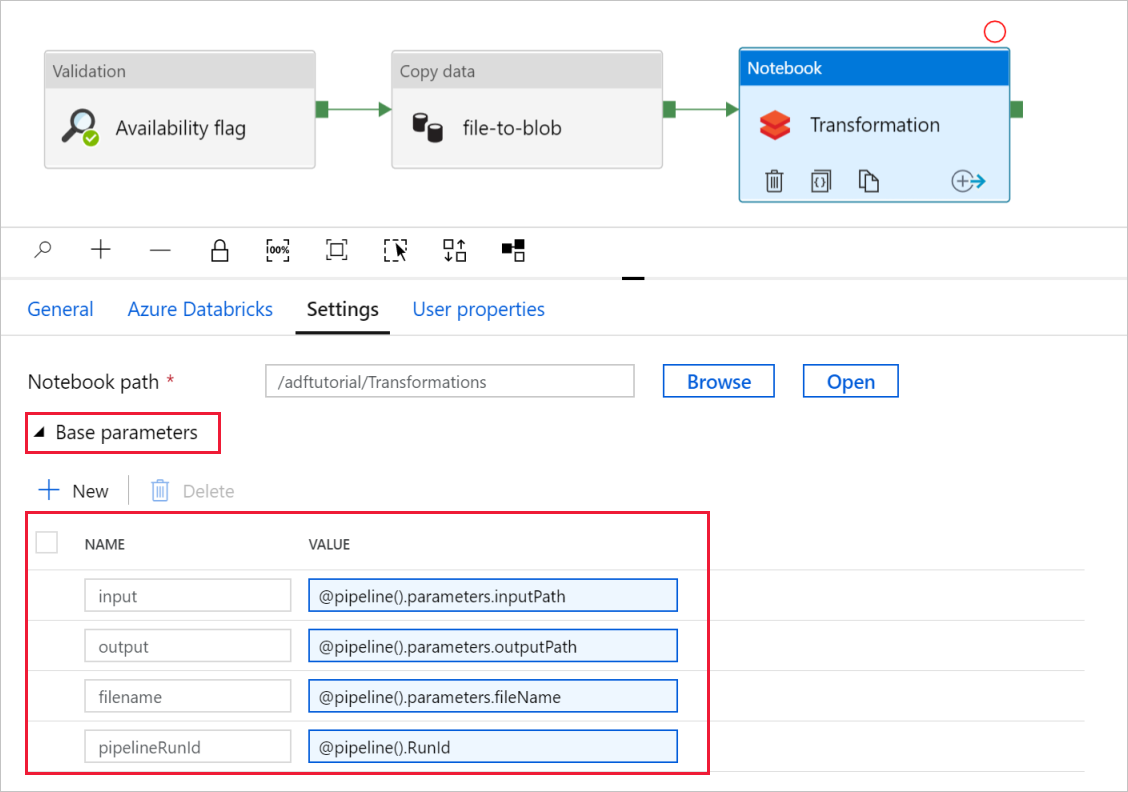
Développez le sélecteur Paramètres de base et vérifiez que les paramètres correspondent à ce qui est illustré dans la capture d’écran suivante. Ces paramètres sont transmis au notebook Databricks à partir de Data Factory.
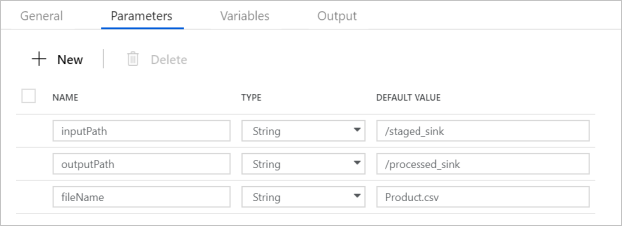
Vérifiez que les paramètres du pipeline correspondent à ce qui est illustré dans la capture d’écran suivante :
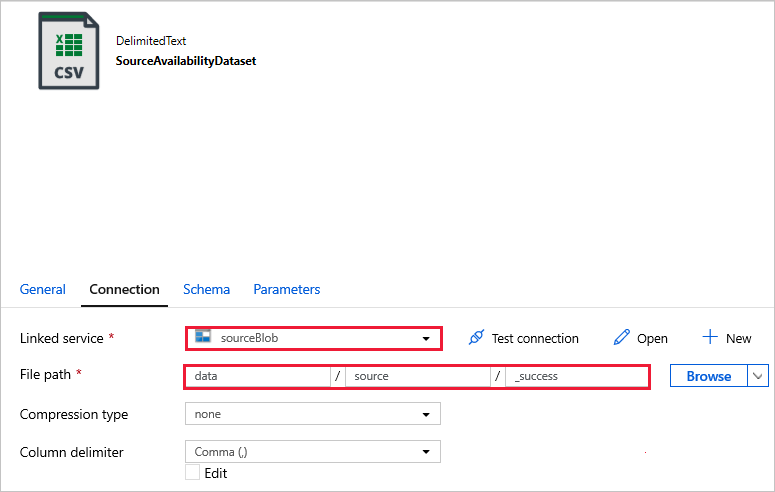
Connectez-vous à vos jeux de données.
Notes
Dans les jeux de données ci-dessous, le chemin d’accès du fichier a été automatiquement spécifié dans le modèle. Si des modifications sont nécessaires, veillez à spécifier le chemin d’accès pour conteneur et répertoire en cas d’erreur de connexion.
SourceAvailabilityDataset : pour vérifier si les données sources sont disponibles.
SourceFilesDataset : pour accéder aux données sources.
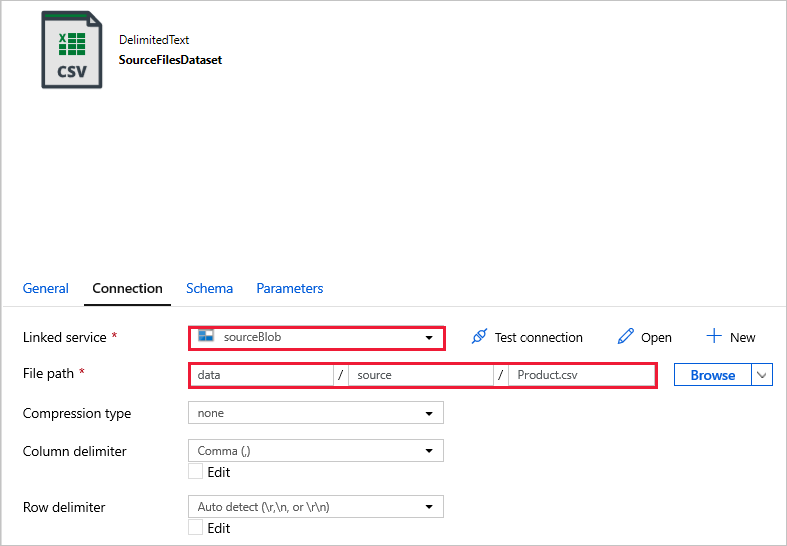
DestinationFilesDataset : pour copier les données dans l’emplacement de destination du récepteur. Utilisez les valeurs suivantes :
Service lié -
sinkBlob_LS, créé au cours d’une étape précédente.Chemin d’accès du fichier -
sinkdata/staged_sink.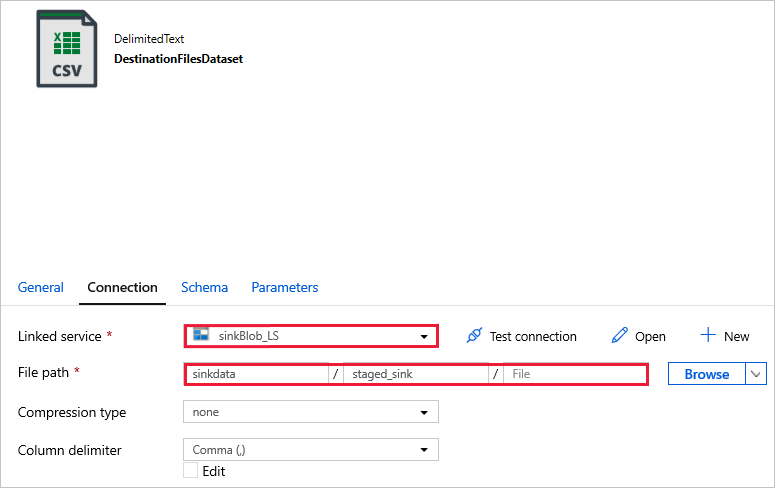
Sélectionnez Déboguer pour exécuter le pipeline. Vous trouverez le lien vers les journaux Databricks permettant d’obtenir des journaux Spark plus détaillés.
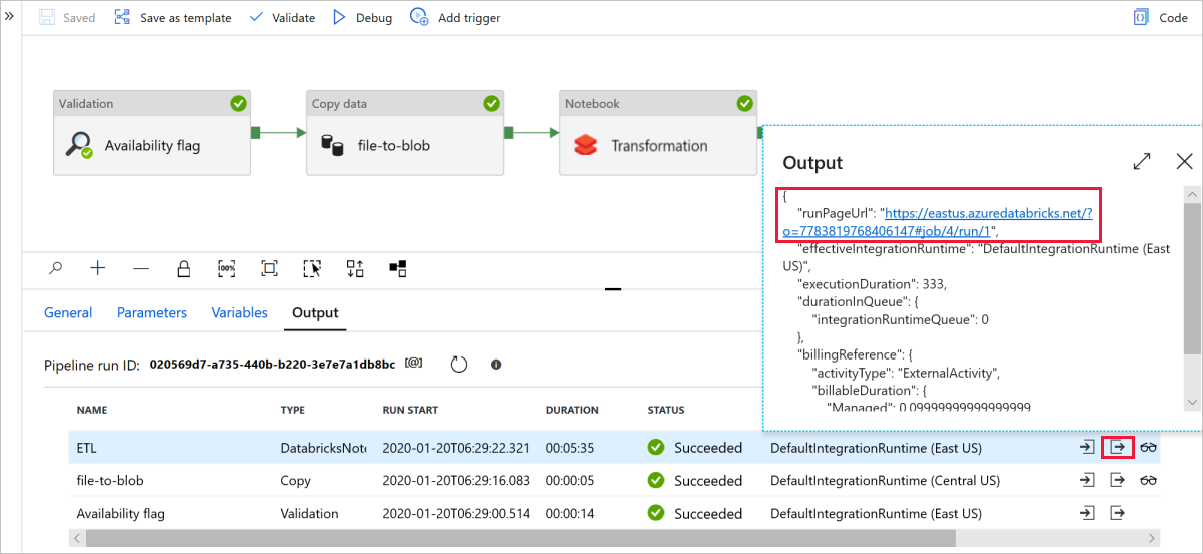
Vous pouvez également vérifier le fichier de données à l’aide d’Explorateur Stockage Azure.
Notes
Pour la corrélation avec les exécutions de pipeline Data Factory, cet exemple ajoute l’ID d’exécution de pipeline de la fabrique de données au dossier de sortie. Cela permet le suivi des fichiers générés par chaque exécution.