Charger des données dans Azure Data Lake Storage Gen1 à l’aide d’Azure Data Factory
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Lake Storage Gen1 (connu préalablement sous le nom Azure Data Lake Store) est un référentiel d’entreprise à très grande échelle pour les charges de travail d’analyse du Big Data. Data Lake Storage Gen1 vous permet de capturer des données de toute taille, de tout type et dont les vitesses d’ingestion sont variées. Les données sont capturées à un emplacement unique, à des fins d’analytique opérationnelle et exploratoire.
Azure Data Factory est un service informatique d’intégration de données informatique intégralement managé. Vous pouvez utiliser le service pour remplir le lac de données avec les données de votre système existant et gagner du temps lors de la création de vos solutions d’analyse.
Azure Data Factory offre les avantages suivants pour le chargement des données dans Data Lake Storage Gen1 :
- Facilité de configuration : assistant intuitif en 5 étapes. Aucun script nécessaire.
- Prise en charge étendue du magasin de données : prise en charge intégrée d’un ensemble complet de magasins de données locaux et dans le cloud. Pour une liste détaillée, consultez le tableau Banques de données prises en charge.
- Sécurité et conformité : les données sont transférées via HTTPS ou ExpressRoute. La présence globale du service garantit que vos données ne quittent jamais les limites géographiques.
- Hautes performances : la vitesse de chargement des données dans Data Lake Storage Gen1 peut atteindre 1 Gbit/s. Pour en savoir plus, voir Performances de l’activité de copie.
Cet article explique comment utiliser l’outil de copie de données Data Factory pour charger les données d’Amazon S3 dans Data Lake Storage Gen1. Vous pouvez procéder de même pour copier des données à partir d’autres types de banques de données.
Notes
Pour en savoir plus, consultez Copier des données vers ou depuis Azure Data Lake Storage Gen1 à l’aide d’Azure Data Factory.
Prérequis
- Abonnement Azure : Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Compte Data Lake Storage Gen1 : si vous n’avez pas de compte Data Lake Storage Gen1, consultez les instructions décrites dans la section Créer un compte Data Lake Storage Gen1.
- Amazon S3 : Cet article explique comment copier des données à partir d’Amazon S3. Vous pouvez utiliser d’autres magasins de données en procédant de la même façon.
Créer une fabrique de données
Si vous n’avez pas encore créé votre fabrique de données, suivez les étapes de démarrage rapide : Créer une fabrique de données à l’aide du Portail Azure et Azure Data Factory Studio pour en créer une. Après la création, accédez à la fabrique de données dans le Portail Azure.

Sélectionnez Ouvrir dans la mosaïque Ouvrir Azure Data Factory Studio pour lancer l’application d’intégration de données dans un onglet distinct.
Charger des données dans Data Lake Storage Gen1
Sur la page d’accueil, sélectionnez la mosaïque Ingérer pour lancer l’outil Copier des données :
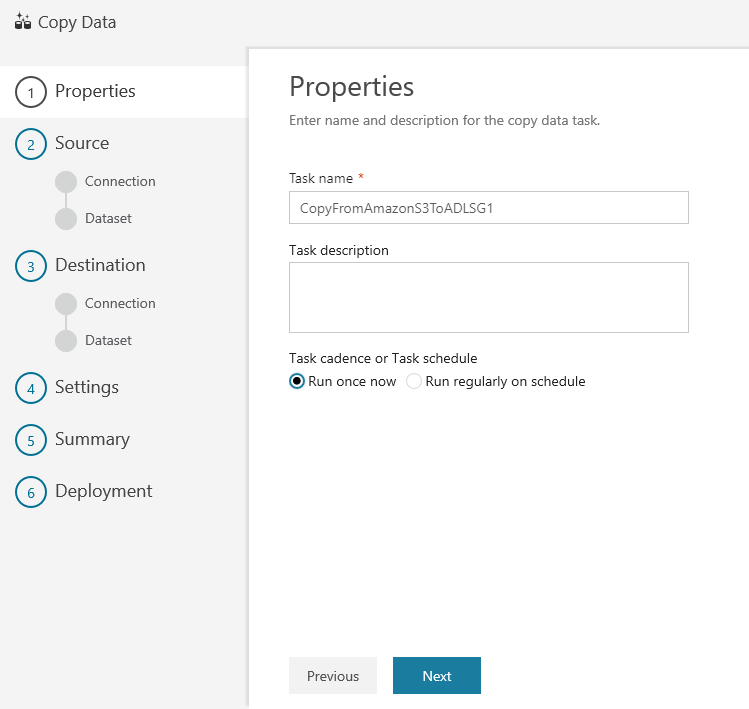
Dans la page Propriétés, spécifiez CopyFromAmazonS3ToADLS dans le champ Nom de tâche, puis cliquez sur Suivant :
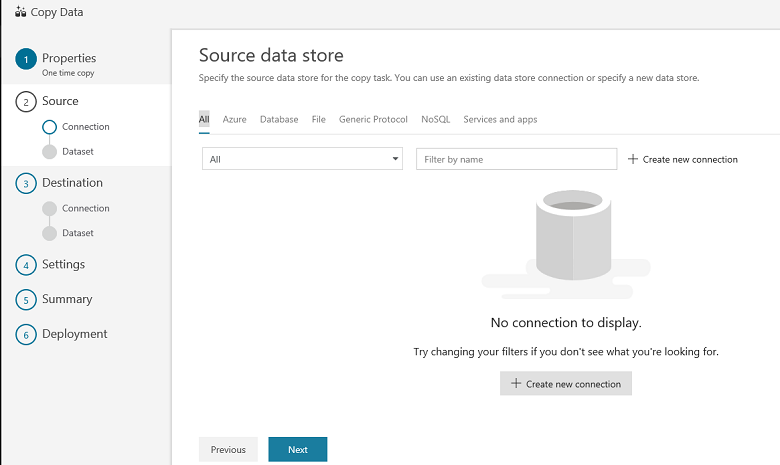
Dans la page Banque de données sources, sélectionnez + Créer une connexion.
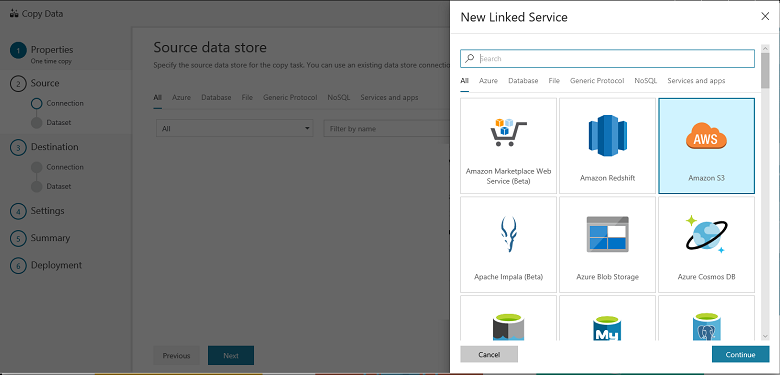
Sélectionnez Amazon S3, puis sélectionnez Continuer.
Sur la page Spécifier la connexion Amazon S3, procédez comme suit :
Spécifiez la valeur du champ ID de clé d’accès.
Spécifiez la valeur Clé d’accès secrète.
Sélectionnez Terminer.
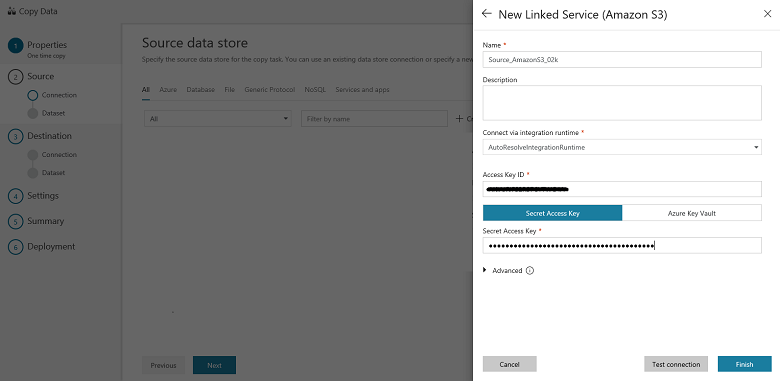
Vous voyez une nouvelle connexion. Sélectionnez Suivant.
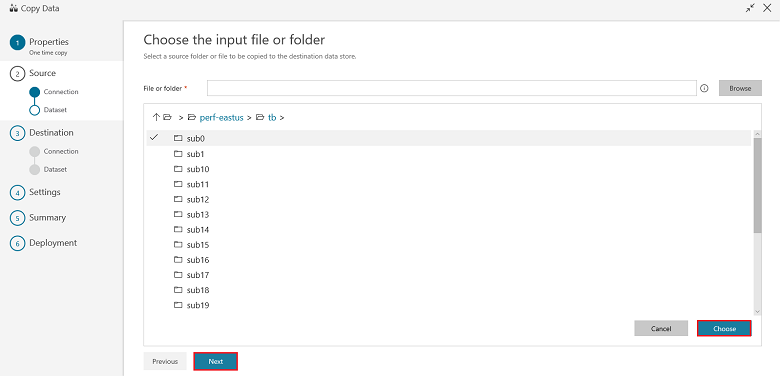
Sur la page de sélection du fichier ou dossier d’entrée, accédez au dossier et au fichier sur lesquels effectuer la copie. Sélectionnez le dossier ou le fichier ; cliquez sur Choisir, puis sur Suivant :
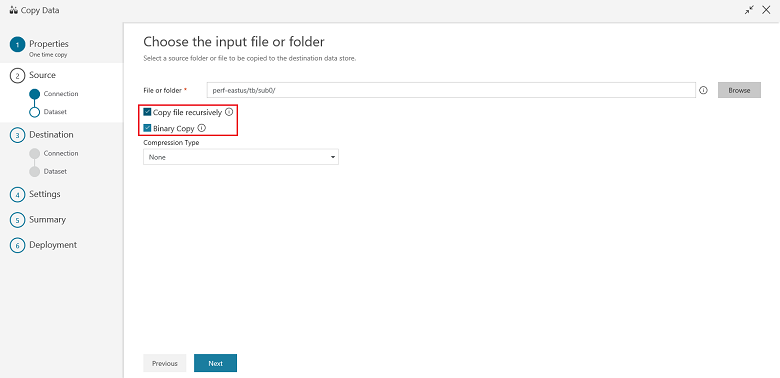
Choisissez le comportement de copie en sélectionnant les options de copie récursive des fichiers et de copie binaire (copie des fichiers en l’état). Sélectionnez Suivant :
Sur la page Banque de données de destination, cliquez sur + Créer une connexion, puis sélectionnez Azure Data Lake Storage Gen1 et sélectionnez Continuer :
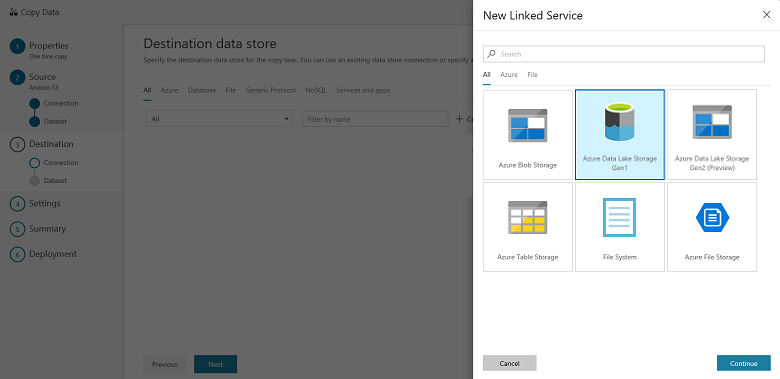
Sur la page New Linked Service (Azure Data Lake Storage Gen1) (Nouveau service lié (Azure Data Lake Storage Gen1)), effectuez les étapes suivantes :
- Sélectionnez votre compte Data Lake Storage Gen1 pour Nom du compte Data Lake Store.
- Spécifiez le Locataire, puis cliquez sur Terminer.
- Sélectionnez Suivant.
Important
Dans cette procédure pas à pas, vous utilisez une identité managée pour les ressources Azure, afin d’authentifier votre compte Data Lake Storage Gen1. Veillez à accorder à la fonctionnalité MSI les autorisations appropriées dans Data Lake Storage Gen1, en suivant ces instructions.
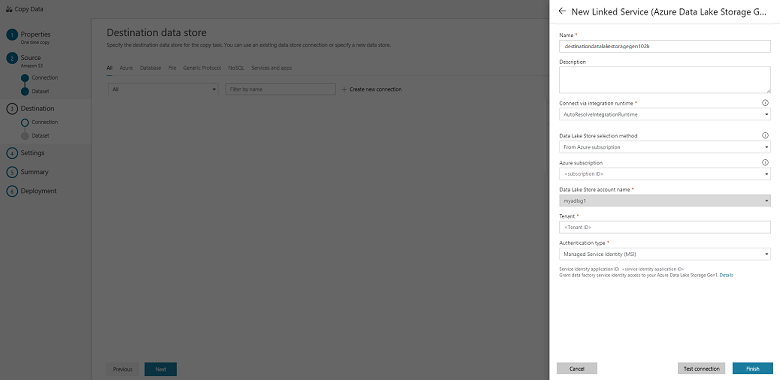
Dans la page de sélection du fichier ou dossier de sortie, saisissez copyfroms3 dans le champ du nom du dossier de sortie, puis sélectionnez Suivant :
Sur la page Paramètres, cliquez sur Suivant :
Dans la page Résumé, vérifiez les paramètres, puis cliquez sur Suivant :
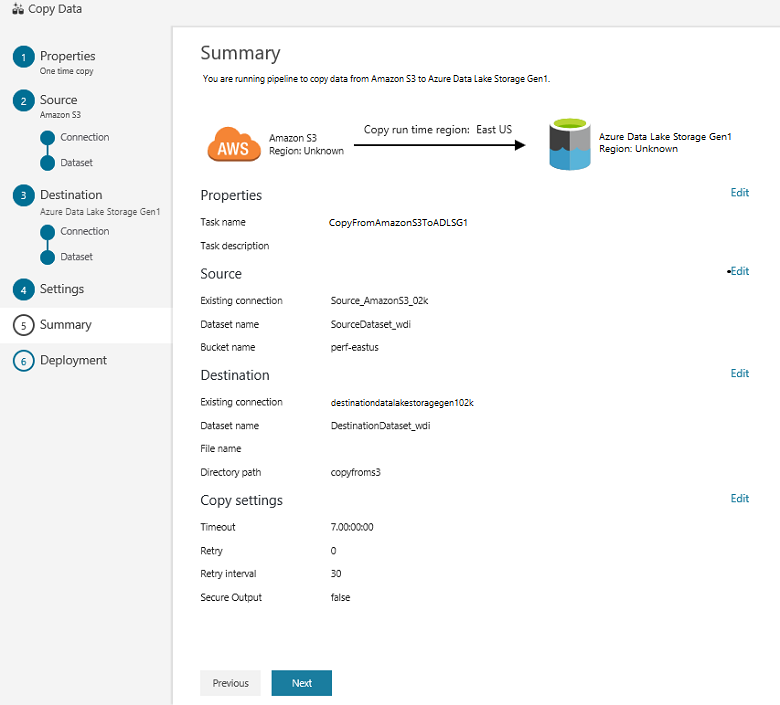
Dans la page Déploiement, sélectionnez Surveiller pour surveiller le pipeline (tâche) :
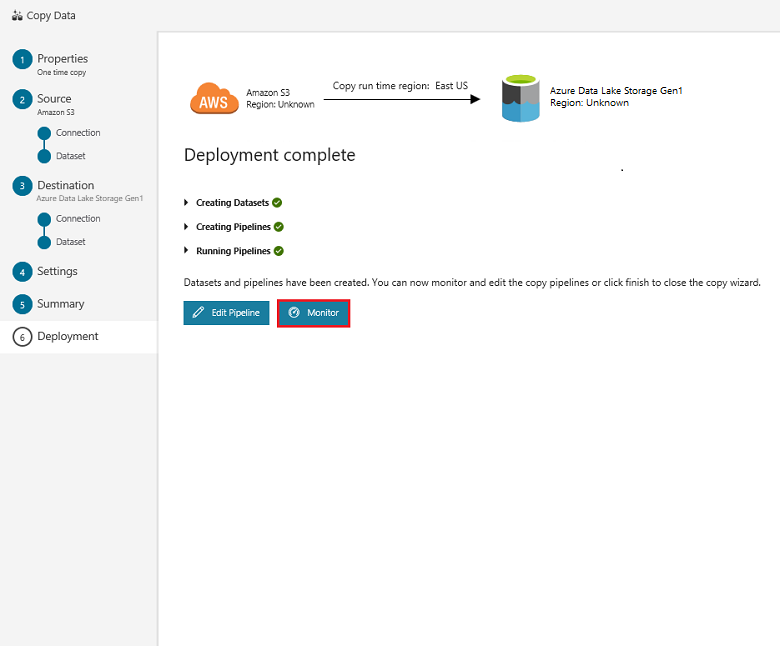
Notez que l’onglet Surveiller sur la gauche est sélectionné automatiquement. La colonne Actions comprend les liens permettant d’afficher les détails de l’exécution de l’activité et de réexécuter le pipeline :
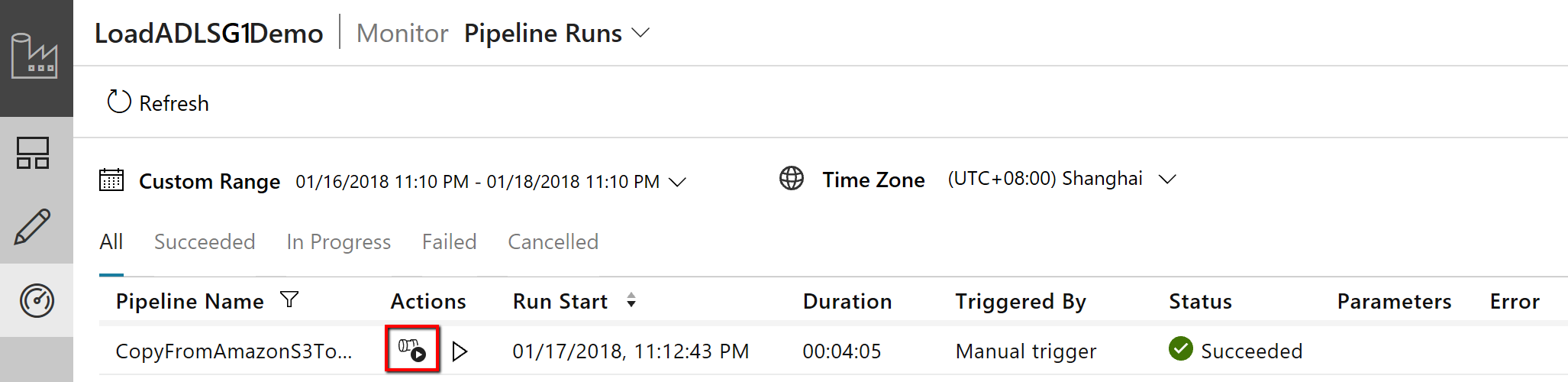
Pour afficher les exécutions d’activités associées à l’exécution du pipeline, sélectionnez le lien Afficher les exécutions d’activités dans la colonne Actions. Il n’y a qu’une seule activité (activité de copie) dans le pipeline ; vous ne voyez donc qu’une seule entrée. Pour revenir à l’affichage des exécutions du pipeline, sélectionnez le lien Pipelines affiché en haut de la fenêtre. Sélectionnez Actualiser pour actualiser la liste.
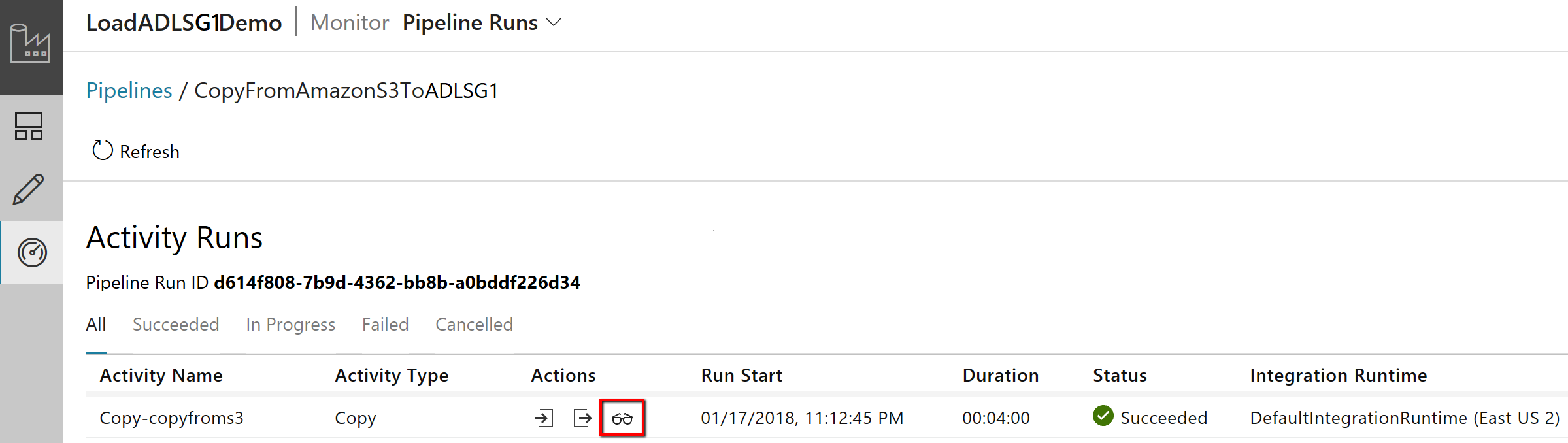
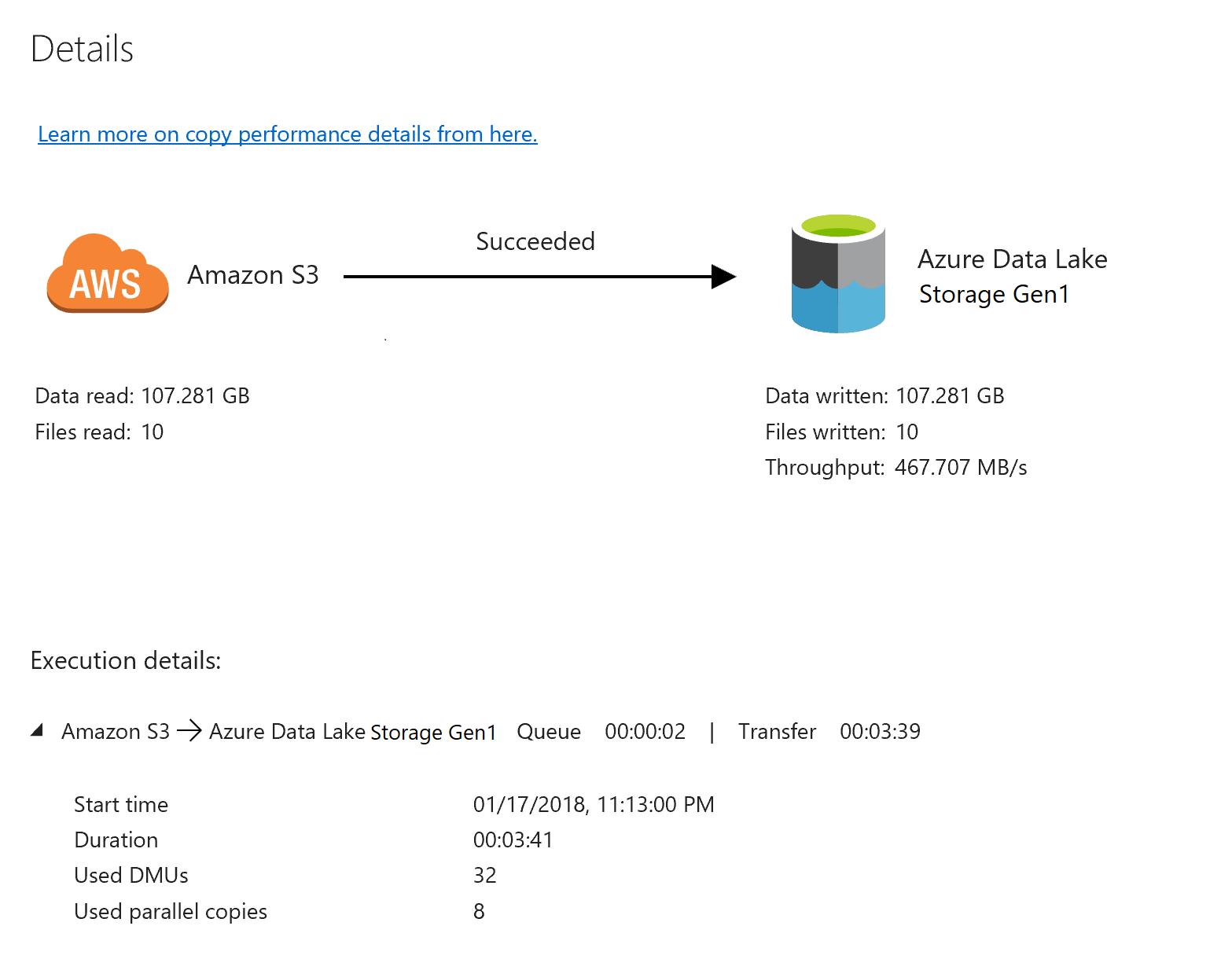
Pour surveiller l’exécution de chaque activité de copie, cliquez sur le lien Détails sous Actions dans la page de surveillance des activités. Vous pouvez suivre les informations détaillées comme le volume de données copiées à partir de la source dans le récepteur, le débit des données, les étapes d’exécution avec une durée correspondante et les configurations utilisées :
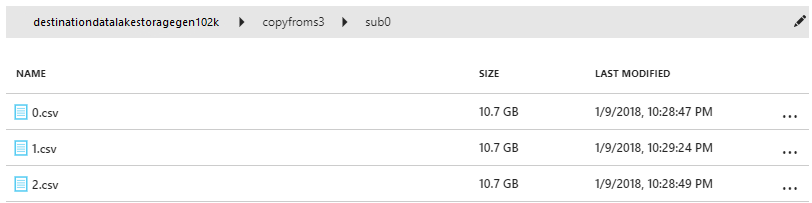
Vérifiez que les données sont copiées dans votre compte Data Lake Store Gen1 :
Contenu connexe
Lisez l’article suivant pour en savoir plus sur la prise en charge de Data Lake Storage Gen1 :