Créer un déclencheur qui exécute un pipeline en réponse à un événement de stockage
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit les déclencheurs d’événement de stockage que vous pouvez créer dans vos pipelines Azure Data Factory ou Azure Synapse Analytics.
L’architecture basée sur les événements est un modèle d’intégration de données courant qui implique la production, la détection et la consommation d’événements ainsi que la réaction aux événements. Les scénarios d’intégration de données nécessitent souvent que les clients déclenchent des pipelines à partir d’événements qui se produisent dans un compte de stockage Azure, comme l’arrivée ou la suppression d’un fichier dans un compte de stockage Blob Azure. Les pipelines Data Factory et Azure Synapse Analytics s’intègrent en mode natif à Azure Event Grid, ce qui vous permet de déclencher des pipelines à partir de ces événements.
Considérations sur les déclencheurs d’événement de stockage
Tenez compte des points suivants quand vous utilisez des déclencheurs d’événements de stockage :
- L’intégration décrite dans cet article dépend d’Azure Event Grid. Vérifiez que votre abonnement est inscrit auprès du fournisseur de ressources Event Grid. Pour plus d’informations, consultez les types et les fournisseurs de ressources. Vous devez être en mesure d'effectuer l'action
Microsoft.EventGrid/eventSubscriptions/. Cette action fait partie du rôle intégréEventGrid EventSubscription Contributor. - Si vous utilisez cette fonctionnalité dans Azure Synapse Analytics, vérifiez que vous inscrivez également votre abonnement auprès du fournisseur de ressources Data Factory. Sinon, vous recevez un message indiquant que « la création d’un abonnement à un événement a échoué ».
- Si le compte de stockage Blob réside derrière un point de terminaison privé et bloque l’accès au réseau public, vous devez configurer des règles de réseau pour autoriser les communications entre le stockage Blob et Event Grid. Vous pouvez accorder l’accès au stockage à des services Azure approuvés, comme Event Grid, conformément à la documentation du stockage, ou configurer des points de terminaison privés pour Event Grid qui correspondent à l’espace d’adressage d’un réseau virtuel, conformément à la documentation d’Event Grid.
- Le déclencheur d’événements de stockage prend actuellement en charge seulement les comptes Azure Data Lake Storage Gen2 et les comptes de stockage version 2 universel. Si vous utilisez des événements de stockage SFTP (Secure File Transfer Protocol), vous devez également spécifier l’API Données SFTP sous la section de filtrage. En raison d’une limitation d’Event Grid, Data Factory prend en charge seulement 500 déclencheurs d’événements de stockage maximum par compte de stockage.
- Pour créer un déclencheur d’événements de stockage ou en modifier un, le compte Azure utilisé pour la connexion au service et la publication du déclencheur d’événements de stockage doit avoir l’autorisation de contrôle d’accès en fonction du rôle (RBAC Azure) appropriée sur le compte de stockage. Aucune autre autorisation n’est requise. Le principal de service pour Azure Data Factory et Azure Synapse Analytics n’a pas besoin d’une autorisation spéciale sur le compte de stockage ni sur Event Grid. Pour plus d'informations sur le contrôle d'accès, consultez la section Contrôle d'accès en fonction du rôle.
- Si vous avez appliqué un verrou Azure Resource Manager à votre compte de stockage, cela peut avoir un impact sur la capacité du déclencheur de blob à créer ou à supprimer des blobs. Un verrou
ReadOnlyempêche la création et la suppression, tandis qu’un verrouDoNotDeleteempêche la suppression. Veillez à prendre en compte ces restrictions pour éviter tout problème avec vos déclencheurs. - Nous vous déconseillons d’utiliser les déclencheurs d’arrivée de fichier comme mécanisme de déclenchement à partir de récepteurs de flux de données. Les flux de données effectuent un certain nombre de tâches de renommage de fichiers et de remaniement de fichiers de partition dans le dossier cible qui peuvent déclencher accidentellement un événement d’arrivée de fichier avant le traitement complet de vos données.
Créer un déclencheur avec l’interface utilisateur
Cette section vous montre comment créer un déclencheur d’événements de stockage dans l’interface utilisateur des pipelines Azure Data Factory et Azure Synapse Analytics.
Passez à l’onglet Modifier de Data Factory ou à l’onglet Intégrer d’Azure Synapse Analytics.
Dans le menu, sélectionnez Déclencheur, puis sélectionnez Nouveau/Modifier.
Dans la page Ajouter des déclencheurs, sélectionnez Choisir un déclencheur, puis + Nouveau.
Sélectionnez le type de déclencheur Événements de stockage.
Sélectionnez votre compte de stockage dans la liste déroulante des abonnements Azure ou manuellement à partir de son ID de ressource de compte de stockage. Choisissez le conteneur sur lequel vous voulez que se produisent les événements. La sélection du conteneur est obligatoire, mais si vous sélectionnez tous les conteneurs, vous risquez obtenir un grand nombre d’événements.
Les propriétés
Blob path begins withetBlob path ends withvous permettent de spécifier les conteneurs, dossiers et noms de blob pour lesquels vous voulez recevoir des événements. Votre déclencheur d’événements de stockage requiert la définition d’au moins une de ces propriétés. Vous pouvez utiliser différents modèles pour les propriétésBlob path begins withetBlob path ends with, comme illustré dans les exemples plus loin dans cet article.-
Blob path begins with: le chemin du blob doit commencer par un chemin de dossier. Les valeurs autorisées comprennent2018/et2018/april/shoes.csv. Ce champ ne peut pas être sélectionné si aucun conteneur n’est sélectionné. -
Blob path ends with: le chemin du blob doit se terminer par un nom de fichier ou une extension. Les valeurs autorisées comprennentshoes.csvet.csv. Les noms du conteneur et du dossier, s’ils sont spécifiés, doivent être séparés par un segment/blobs/. Par exemple, un conteneur nomméorderspeut avoir la valeur/orders/blobs/2018/april/shoes.csv. Pour spécifier un dossier dans n’importe quel conteneur, omettez le caractère/de début. Par exemple,april/shoes.csvdéclenche un événement sur tout fichier nomméshoes.csvdans un dossier appeléaprildans n’importe quel conteneur.
Notez que
Blob path begins withetBlob path ends withsont les seuls critères spéciaux autorisés dans un déclencheur d’événements de stockage. Les autres types de correspondance par caractères génériques ne sont pas pris en charge pour le type de déclencheur.-
Indiquez si votre déclencheur doit répondre à un événement Blob créé, Blob supprimé, ou les deux. Dans l’emplacement de stockage spécifié, chaque événement déclenche les pipelines Data Factory et Azure Synapse Analytics associés au déclencheur.
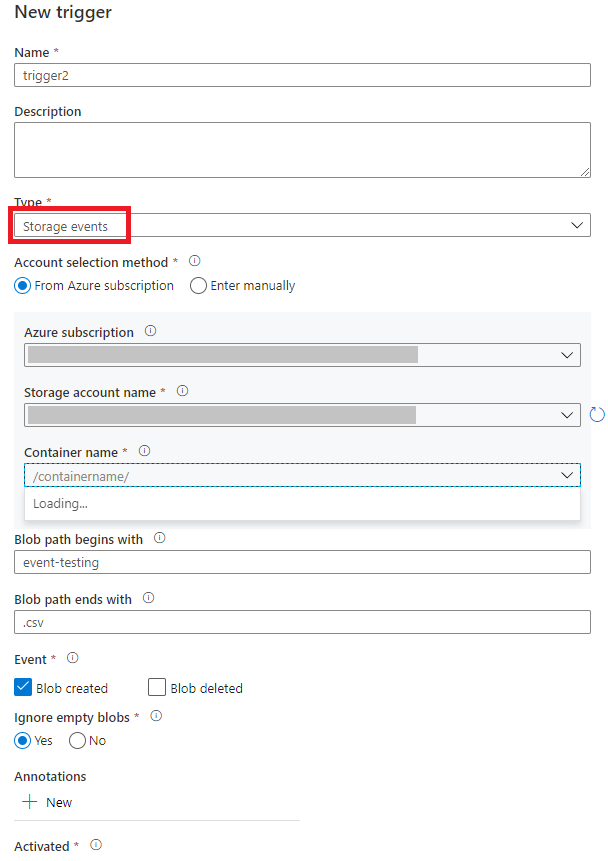
Indiquez si votre déclencheur ignore ou non les objets blob de zéro octet.
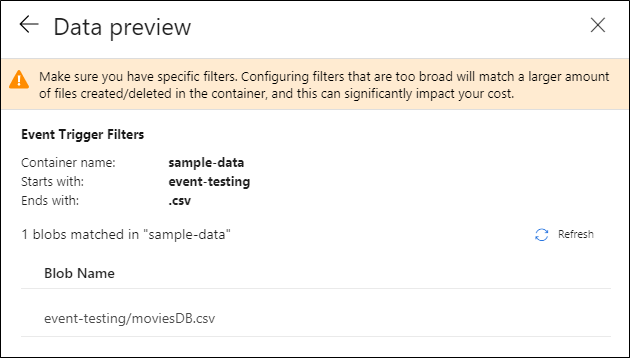
Après avoir configuré votre déclencheur, sélectionnez Suivant : Aperçu des données. Cet écran affiche les blobs existants correspondant à la configuration de votre déclencheur d’événements de stockage. Veillez à avoir des filtres spécifiques. La configuration de filtres trop larges peut correspondre à un grand nombre de fichiers créés ou supprimés, et peut avoir un impact significatif sur vos coûts. Une fois que vos conditions de filtre sont vérifiées, sélectionnez Terminer.
Pour attacher un pipeline à ce déclencheur, accédez au canevas du pipeline et sélectionnez Déclencheur>Nouveau/Modifier. Quand le volet latéral s’affiche, sélectionnez la liste déroulante Choisir un déclencheur et sélectionnez le déclencheur que vous avez créé. Sélectionnez Suivant : Aperçu des données pour vérifier que la configuration est correcte. Sélectionnez ensuite Suivant pour vérifier que l’aperçu des données est correct.
Si votre pipeline a des paramètres, vous pouvez les spécifier dans le volet latéral Paramètres d’exécution du déclencheur. Le déclencheur d’événements de stockage capture le chemin de dossier et le nom de fichier du blob dans les propriétés
@triggerBody().folderPathet@triggerBody().fileName. Pour utiliser les valeurs de ces propriétés dans un pipeline, vous devez mapper les propriétés aux paramètres de pipeline. Après le mappage des propriétés aux paramètres, vous pouvez accéder aux valeurs capturées par le déclencheur avec l’expression@pipeline().parameters.parameterNametout au long du pipeline. Pour une explication détaillée, consultez Référencer des métadonnées de déclencheur dans des pipelines.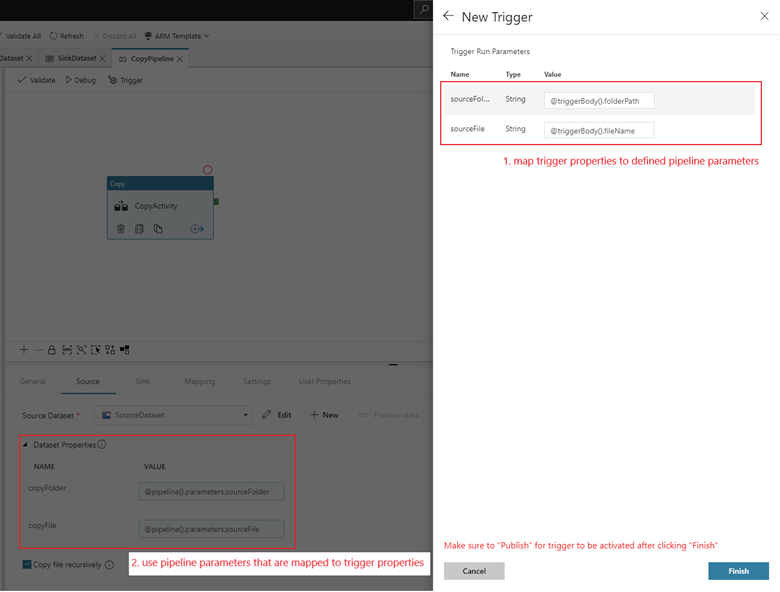
Dans l’exemple précédent, le déclencheur est configuré pour se déclencher lorsqu’un chemin d’accès à un objet Blob se terminant par .csv est créé dans le dossier event-testing du conteneur sample-data. Les propriétés
folderPathetfileNamecapturent l’emplacement du nouveau blob. Par exemple, quand MoviesDB.csv est ajouté au chemin sample-data/event-testing,@triggerBody().folderPatha la valeursample-data/event-testing, et@triggerBody().fileNamea la valeurmoviesDB.csv. Ces valeurs sont mappées, dans l’exemple, aux paramètres de pipelinesourceFolderetsourceFile, qui peuvent être utilisés dans l’ensemble du pipeline en tant que@pipeline().parameters.sourceFolderet@pipeline().parameters.sourceFilerespectivement.Dès que vous avez fini, sélectionnez Terminer.


Schéma JSON
Le tableau suivant fournit une vue d’ensemble des éléments de schéma associés aux déclencheurs d’événements de stockage.
| Élément JSON | Description | Type | Valeurs autorisées | Requis |
|---|---|---|---|---|
| scope | ID de ressource Azure Resource Manager du compte de stockage. | String | ID d’Azure Resource Manager | Oui. |
| événements | Type des événements qui entraîne l’activation de ce déclencheur. | Tableau |
Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Oui, n’importe quelle combinaison de ces valeurs. |
blobPathBeginsWith |
Le chemin d’accès de l’objet blob doit commencer par le modèle fourni pour activer le déclencheur. Par exemple, /records/blobs/december/ active uniquement le déclencheur pour les objets blob du dossier december sous le conteneur records. |
String | Vous devez indiquer une valeur pour l’une de ces propriétés au moins : blobPathBeginsWith ou blobPathEndsWith. |
|
blobPathEndsWith |
Le chemin d’accès de l’objet blob doit se terminer par le modèle fourni pour activer le déclencheur. Par exemple, december/boxes.csv active uniquement le déclencheur pour les objets blob nommés boxes dans un dossier december. |
String | Vous devez indiquer une valeur pour l’une de ces propriétés au moins : blobPathBeginsWith ou blobPathEndsWith. |
|
ignoreEmptyBlobs |
Indique si des blobs de zéro octet déclenchent ou non l’exécution d’un pipeline. Par défaut, il a la valeur true. |
Booléen | True ou False | Non. |
Exemples de déclencheurs d’événements de stockage
Cette section fournit des exemples de paramètres de déclencheur d’événements de stockage.
Important
Vous devez inclure le segment /blobs/ du chemin, comme indiqué dans les exemples suivants, chaque fois que vous spécifiez conteneur et dossier, conteneur et fichier, ou conteneur, dossier et fichier. Pour blobPathBeginsWith, l’interface utilisateur ajoute automatiquement /blobs/ entre les noms de dossier et de conteneur dans le JSON du déclencheur.
| Propriété | Exemple | Description |
|---|---|---|
Blob path begins with |
/containername/ |
Reçoit les événements de tout objet blob du conteneur. |
Blob path begins with |
/containername/blobs/foldername/ |
Reçoit les événements de tout objet blob du conteneur containername et du dossier foldername. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
Vous pouvez également référencer un sous-dossier. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Reçoit les événements d’un objet blob nommé file.txt dans le dossier foldername, sous le conteneur containername. |
Blob path ends with |
file.txt |
Reçoit les événements d’un objet blob nommé file.txt dans n’importe quel chemin d’accès. |
Blob path ends with |
/containername/blobs/file.txt |
Reçoit les événements d’un blob nommé file.txt sous le conteneur containername. |
Blob path ends with |
foldername/file.txt |
Reçoit les événements d’un blob nommé file.txt dans le dossier foldername sous n’importe quel conteneur. |
Contrôle d’accès basé sur les rôles
Les pipelines Data Factory et Azure Synapse Analytics utilisent le contrôle d’accès en fonction du rôle Azure (RBAC Azure) afin d’interdire strictement l’accès non autorisé pour écouter, s’abonner à des mises à jour et déclencher des pipelines liés aux événements blob.
- Pour créer un déclencheur d’événements de stockage ou en mettre un à jour, le compte Azure connecté au service doit avoir un accès approprié au compte de stockage concerné. Sinon, l’opération échoue avec le message « Accès refusé ».
- Data Factory et Azure Synapse Analytics n’ont besoin d’aucune autorisation spéciale sur votre instance Event Grid, et vous n’avez pas besoin d’attribuer une autorisation RBAC spéciale au principal de service Data Factory ou Azure Synapse Analytics pour l’opération.
Tous les paramètres RBAC suivants fonctionnent pour les déclencheurs d’événements de stockage :
- Rôle de propriétaire pour le compte de stockage
- Rôle de contributeur au compte de stockage
- Autorisation
Microsoft.EventGrid/EventSubscriptions/Writesur le compte de stockage/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Plus précisément :
- Quand vous créez dans la fabrique de données (par exemple, dans l’environnement de développement), le compte Azure connecté doit avoir l’autorisation précédente.
- Quand vous publiez avec l’intégration continue et la livraison continue, le compte utilisé pour publier le modèle Azure Resource Manager dans la fabrique de test ou de production doit avoir l’autorisation précédente.
Pour comprendre comment le service remplit les deux promesses, revenons en arrière et jetons un coup d’œil en coulisses. Voici les workflows généraux pour l’intégration entre Data Factory/Azure Synapse Analytics, le Stockage et Event Grid.
Créer un déclencheur d’événements de stockage
Ce workflow général décrit comment Data Factory interagit avec Event Grid pour créer un déclencheur d’événements de stockage. Le flux de données est le même dans Azure Synapse Analytics, les pipelines Azure Synapse Analytics prenant le rôle de fabrique de données dans le diagramme suivant.
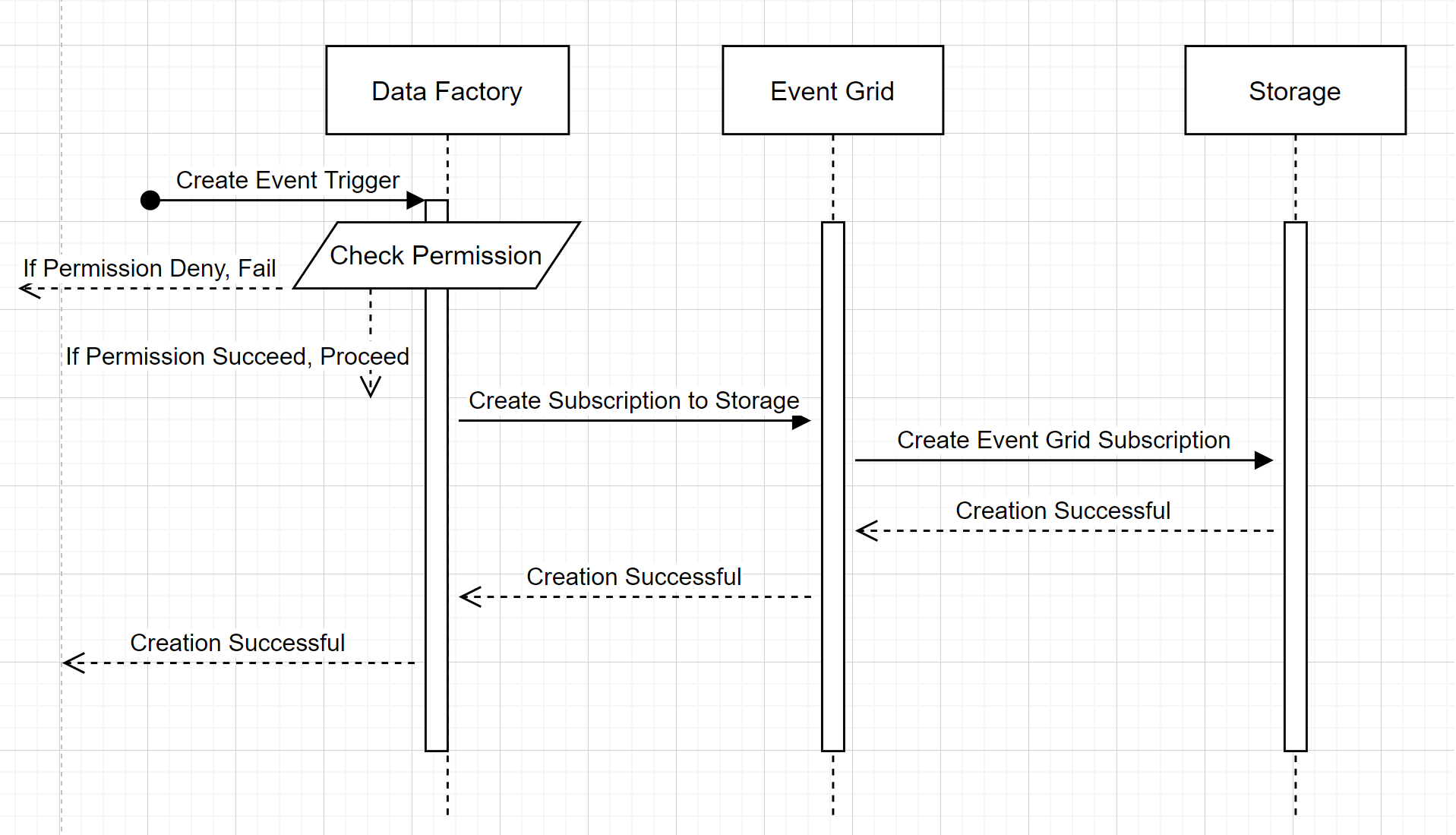
Deux éléments notables dans les workflows :
- Data Factory et Azure Synapse Analytics n’ont aucun contact direct avec le compte de stockage. À la place, la demande de création d’un abonnement est relayée et traitée par Event Grid. Le service n’a besoin d’aucune autorisation sur le compte de stockage pour cette étape.
- Le contrôle d’accès et la vérification des autorisations se produisent au sein du service. Avant que le service n’envoie une demande d’abonnement à un événement de stockage, il vérifie l’autorisation de l’utilisateur. Plus précisément, il vérifie si le compte Azure connecté qui tente de créer le déclencheur d’événements de stockage a un accès approprié au compte de stockage concerné. En cas d’échec de la vérification de l’autorisation, la création du déclencheur échoue également.
Exécution de pipeline du déclencheur d’événements de stockage
Ce workflow général décrit comment les pipelines de déclencheur d’événements de stockage s’exécutent dans Event Grid. Pour Azure Synapse Analytics, le flux de données est le même, les pipelines Azure Synapse Analytics prenant le rôle de fabrique de données dans le diagramme suivant.
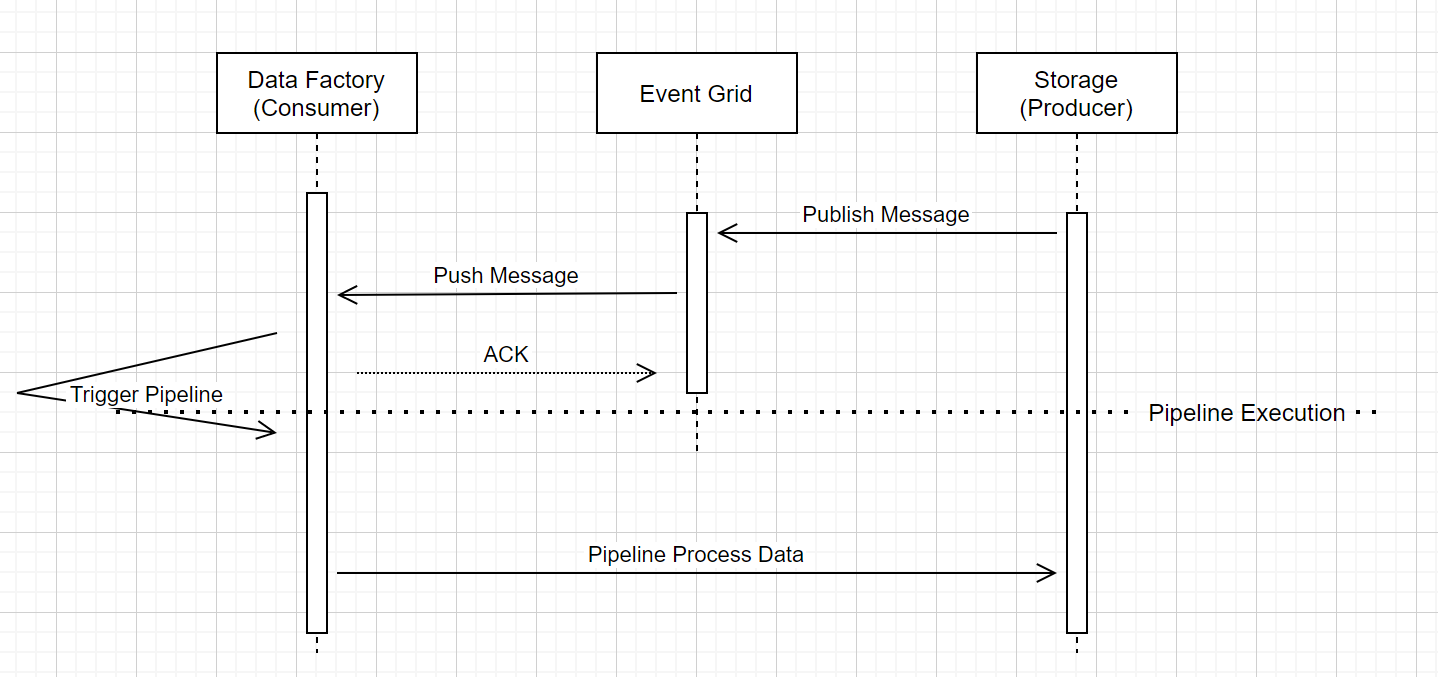
Trois éléments importants dans le workflow sont liés aux pipelines de déclenchement d’événements dans le service :
Event Grid utilise un modèle de transmission de type push qui relaie le message le plus rapidement possible lorsque le stockage dépose le message dans le système. Cette approche diffère des systèmes de messagerie, comme Kafka, qui utilisent un système d’extraction.
Le déclencheur d’événements sert d’écouteur actif du message entrant et déclenche le pipeline associé.
Le déclencheur d’événements de stockage lui-même n’a pas de contact direct avec le compte de stockage.
- Si vous avez une activité Copy ou une autre activité dans le pipeline pour traiter les données dans le compte de stockage, le service entre en contact directement avec le compte de stockage, en utilisant les informations d’identification stockées dans le service lié. Vérifiez que le service lié est correctement configuré.
- Si vous n’avez pas de référence au compte de stockage dans le pipeline, vous n’avez pas besoin d’accorder au service l’autorisation d’accéder au compte de stockage.
Contenu connexe
- Pour plus d’informations sur les déclencheurs, consultez Exécution de pipelines et déclencheurs.
- Pour référencer les métadonnées d’un déclencheur dans un pipeline, consultez Référencer des métadonnées de déclencheur dans des exécutions de pipeline.