Format de fichier Excel dans Azure Data Factory et Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Suivez cet article lorsque vous souhaitez analyser les fichiers Excel. Le service prend en charge à la fois « .xls » et « .xlsx ».
Le format Excel est pris en charge pour les connecteurs suivants : Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage et SFTP. Il est pris en charge en tant que source mais pas en tant que récepteur.
Remarque
Le format « .xls » n’est pas pris en charge lors de l’utilisation du protocole HTTP.
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Excel.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur Excel. | Oui |
| location | Paramètres d’emplacement du ou des fichiers. Chaque connecteur basé sur un fichier possède ses propres type d’emplacement et propriétés prises en charge sous location. |
Oui |
| sheetName | Nom de la feuille de calcul Excel pour lire les données. | Spécifiez sheetName ou sheetIndex. |
| sheetIndex | Index de feuille de calcul Excel pour lire les données, à partir de 0. | Spécifiez sheetName ou sheetIndex. |
| range | Plage de cellules dans la feuille de calcul donnée pour localiser les données sélectives, par exemple : - Non spécifiée : lit l’intégralité de la feuille de calcul en tant que table à partir des premières ligne et colonne non vides - A3 : lit une table en commençant à la cellule donnée, détecte de façon dynamique toutes les lignes situées en dessous et toutes les colonnes à droite- A3:H5 : lit cette plage fixe en tant que table- A3:A3 : lit cette cellule unique |
Non |
| firstRowAsHeader | Spécifie s’il faut considérer la première ligne dans la feuille de calcul/plage donnée comme une ligne d’en-tête avec les noms des colonnes. Les valeurs autorisées sont True et False (par défaut). |
Non |
| nullValue | Spécifie la représentation sous forme de chaîne de la valeur null. La valeur par défaut est une chaîne vide. |
Non |
| compression | Groupe de propriétés pour configurer la compression de fichier. Configurez cette section lorsque vous souhaitez effectuer la compression/décompression lors de l’exécution de l’activité. | Non |
| type (sous compression ) |
Le codec de compression utilisé pour lire/écrire des fichiers JSON. Les valeurs autorisées sont bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy et lz4. La valeur par défaut n’est pas compressée. Remarque : L’activité de copie ne prend pas en charge « snappy » ni « lz4 ». Le flux de données de mappage ne prend pas en charge « ZipDeflate », « TarGzip » ni « Tar ». Remarque lorsque vous utilisez l’activité de copie pour décompresser un ou plusieurs fichiers ZipDeflate et écrire dans le magasin de données du récepteur basé sur fichier, les fichiers sont extraits dans le dossier : <path specified in dataset>/<folder named as source zip file>/. |
Non. |
| level (sous compression ) |
Le taux de compression. Les valeurs autorisées sont Optimal ou Fastest. - Le plus rapide : l’opération de compression doit se terminer le plus rapidement possible, même si le fichier résultant n’est pas compressé de façon optimale. - Optimal : l’opération de compression doit aboutir à une compression optimale, même si elle prend plus de temps. Pour plus d’informations, consultez la rubrique Niveau de compression . |
Non |
Voici un exemple de jeu de données Excel sur Stockage Blob Azure :
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source Excel.
Excel en tant que source
Les propriétés prises en charge dans la section *source* de l’activité de copie sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité de copie doit être définie sur ExcelSource. | Oui |
| storeSettings | Un groupe de propriétés sur la façon de lire les données d’un magasin de données. Chaque connecteur basé sur un fichier possède ses propres paramètres de lecture pris en charge sous storeSettings. |
Non |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Propriétés du mappage de flux de données
Dans les flux de données de mappage, vous pouvez lire des données au format Excel dans les magasins de données suivants : Stockage Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 et SFTP. Vous pouvez pointer vers des fichiers Excel à l’aide d’un jeu de données Excel ou d’un jeu de données Inline.
Propriétés de source
Le tableau ci-dessous répertorie les propriétés prises en charge par une source Excel. Vous pouvez modifier ces propriétés sous l’onglet Options de la source. Lorsque vous utilisez un jeu de données en ligne, vous verrez des paramètres de fichier supplémentaires, qui sont les mêmes que les propriétés décrites dans la section propriétés du jeu de données.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Chemins génériques | Tous les fichiers correspondant au chemin générique seront traités. Remplace le chemin du dossier et du fichier défini dans le jeu de données. | non | String[] | wildcardPaths |
| Chemin racine de la partition | Pour les données de fichier qui sont partitionnées, vous pouvez entrer le chemin racine d’une partition pour pouvoir lire les dossiers partitionnés comme des colonnes. | non | String | partitionRootPath |
| Liste de fichiers | Si votre source pointe ou non vers un fichier texte qui liste les fichiers à traiter | non |
true ou false |
fileList |
| Colonne où stocker le nom du fichier | Crée une colonne avec le nom et le chemin du fichier source | non | String | rowUrlColumn |
| Après l’exécution | Supprime ou déplace les fichiers après le traitement. Le chemin du fichier commence à la racine du conteneur | non | Supprimer : true ou false Déplacer : ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrer par date de dernière modification | Pour filtrer les fichiers en fonction de leur date de dernière modification | non | Timestamp | modifiedAfter modifiedBefore |
| N’autoriser aucun fichier trouvé | Si la valeur est true, aucune erreur n’est levée si aucun fichier n’est trouvé | non |
true ou false |
ignoreNoFilesFound |
Exemple de source
L’image ci-dessous est un exemple de configuration de source Excel dans des flux de données de mappage utilisant le mode du jeu de données.
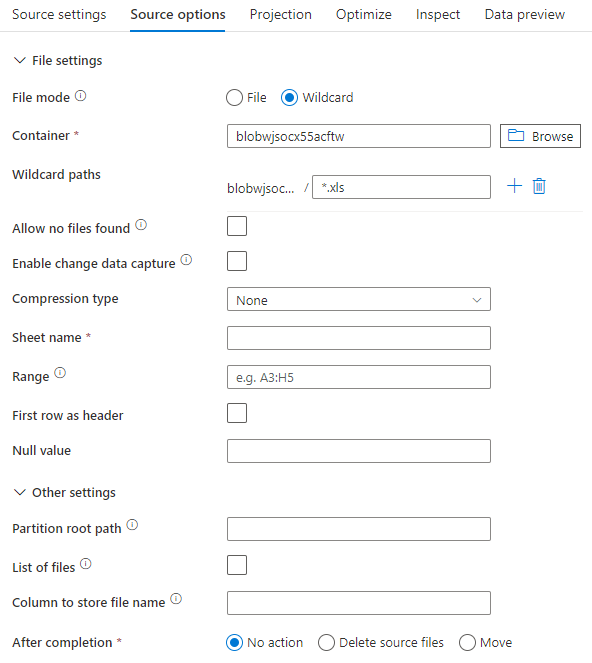
Le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Si vous utilisez un jeu de données Inline, les options de source suivantes s’affichent dans le flux de données de mappage.
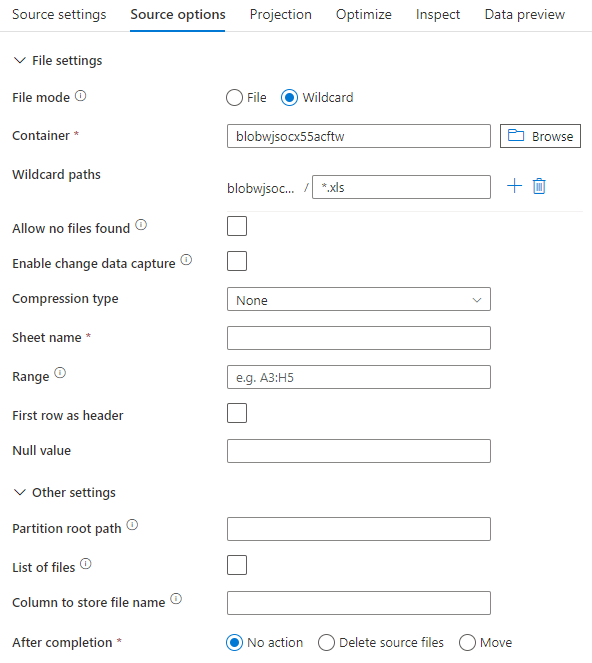
Le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Remarque
Le flux de données de mappage ne permet pas de lire les fichiers Excel protégés, car ces fichiers peuvent contenir des avis de confidentialité ou appliquer des restrictions d’accès spécifiques qui limitent l’accès à leur contenu.
Gestion des très gros fichiers Excel
Le connecteur Excel ne prend pas en charge la lecture en continu pour l’activité Copier et doit charger l’intégralité du fichier en mémoire avant de pouvoir lire les données. Pour importer un schéma, afficher un aperçu des données ou actualiser un jeu de données Excel, les données doivent être retournées avant le délai d’expiration de la requête HTTP (100s). Pour les gros fichiers Excel, ces opérations peuvent ne pas se terminer dans ce laps de temps, provoquant une erreur de délai d’attente. Si vous souhaitez déplacer de gros fichiers Excel (>100 Mo) dans un autre magasin de données, vous pouvez utiliser l’une des options suivantes pour contourner cette limitation :
- Utilisez le runtime d’intégration auto-hébergé (SHIR), puis utilisez l’activité Copy pour déplacer le gros fichier Excel dans un autre magasin de données avec le runtime SHIR.
- Divisez le gros fichier Excel en plusieurs fichiers plus petits, puis utilisez l’activité Copy pour déplacer le dossier contenant les fichiers.
- Utilisez une activité de flux de données pour déplacer le gros fichier Excel dans un autre magasin de données. Le flux de données prend en charge la lecture en streaming pour Excel et peut déplacer/transférer rapidement les gros fichiers.
- Convertissez manuellement le gros fichier Excel au format CSV, puis utilisez une activité Copy pour déplacer le fichier.