Utiliser Azure Data Factory pour migrer des données d’un serveur Netezza local vers Azure
S’APPLIQUE À :  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Azure Data Factory fournit un mécanisme performant, robuste et économique pour migrer des données à grande échelle d’un serveur Netezza local vers votre compte de stockage Azure ou base de données Azure Synapse Analytics.
Cet article fournit les informations suivantes à l’attention des ingénieurs et des développeurs de données :
- Performances
- Résilience de copie
- Sécurité du réseau
- Architecture de solution de haut niveau
- Meilleures pratiques en matière d’implémentation
Performances
Azure Data Factory offre une architecture serverless qui autorise le parallélisme à différents niveaux. Si vous êtes développeur, cela signifie que vous pouvez créer des pipelines pour utiliser pleinement la bande passante du réseau et de la base de données afin d’optimiser le débit du déplacement des données pour votre environnement.
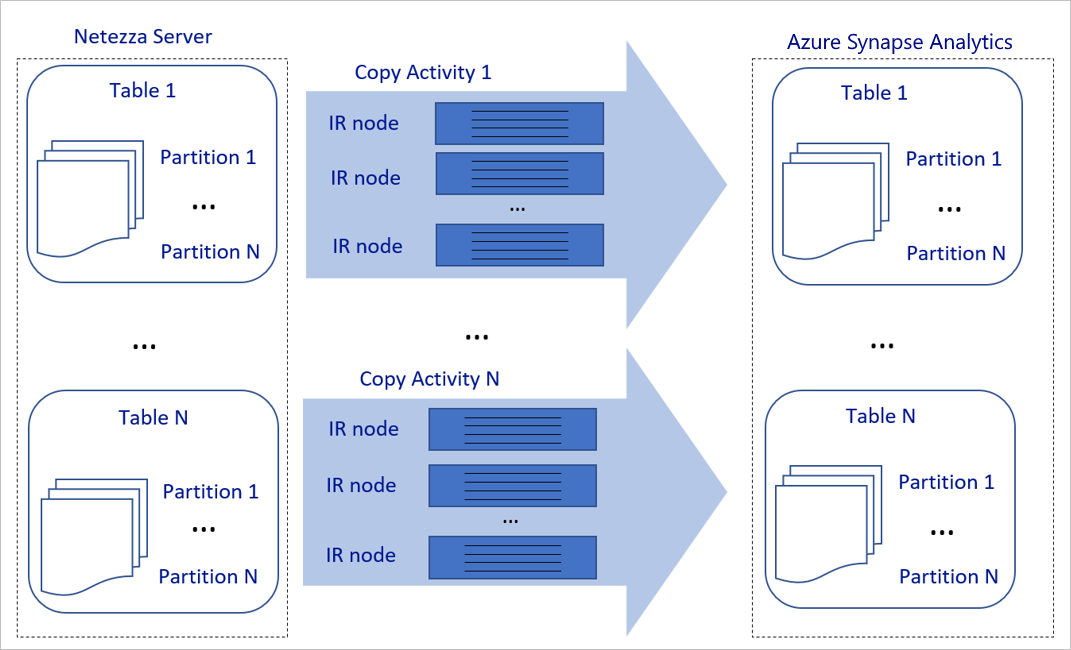
Le diagramme précédent peut être interprété comme suit :
Une seule activité de copie peut tirer parti de plusieurs ressources de calcul évolutives. Quand vous utilisez Azure Integration Runtime, vous pouvez spécifier jusqu’à 256 DIU pour chaque activité de copie de manière serverless. Avec un runtime d’intégration auto-hébergé (IR auto-hébergé), vous pouvez effectuer un scale-up manuel de votre machine ou un scale-out vers plusieurs machines (jusqu’à quatre nœuds), de sorte qu’une activité de copie unique distribue sa partition sur tous les nœuds.
Une activité de copie unique lit et écrit dans le magasin de données à l'aide de plusieurs conversations.
Le flux de contrôle Azure Data Factory peut démarrer plusieurs activités de copie en parallèle. Par exemple, il peut les démarrer à l’aide d’une boucle For Each.
Pour plus d’informations, consultez Guide sur les performances et la scalabilité de l’activité de copie.
Résilience
Dans une exécution d’activité de copie unique, Azure Data Factory intègre un mécanisme de nouvelle tentative qui lui permet de gérer un certain niveau d’échecs temporaires dans les magasins de données ou dans le réseau sous-jacent.
Avec l’activité de copie dans Azure Data Factory, quand vous copiez des données entre les magasins de données source et récepteur, vous avez deux moyens de traiter les lignes incompatibles. Vous pouvez abandonner et laisser en échec l’activité de copie ou continuer à copier le reste des données en ignorant les lignes de données incompatibles. En outre, pour déterminer la cause de l’échec, vous pouvez consigner les lignes incompatibles dans le stockage d’objets blob Azure ou Azure Data Lake Store, corriger les données sur la source de données et retenter l’activité de copie.
Sécurité du réseau
Par défaut, Azure Data Factory transfère les données du serveur Netezza local vers un compte de stockage Azure ou une base de données Azure Synapse Analytics en utilisant une connexion chiffrée via HTTPS (Hypertext Transfer Protocol Secure). Le protocole HTTPS assure le chiffrement des données en transit et empêche les écoutes clandestines et les attaques de l’intercepteur.
Sinon, si vous ne souhaitez pas que les données soient transférées via l’Internet public, vous pouvez contribuer à obtenir une sécurité accrue en transférant les données via un lien d’appairage privé et via Azure Express Route.
La section suivante explique comment obtenir une sécurité plus élevée.
Architecture de solution
Cette section présente deux façons de migrer vos données.
Migrer des données sur l’Internet public
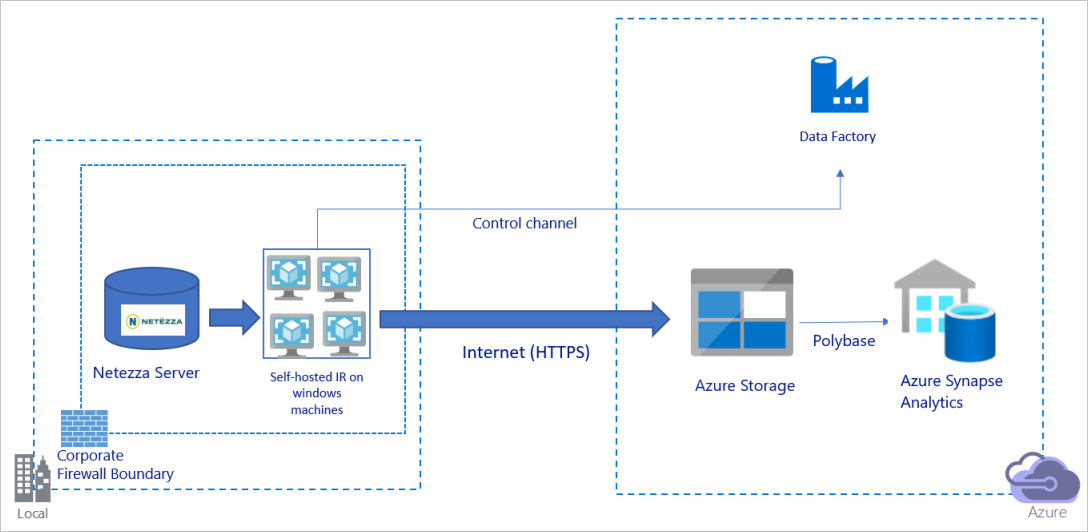
Le diagramme précédent peut être interprété comme suit :
Dans cette architecture, vous transférez les données de manière sécurisée en utilisant HTTPS via l’Internet public.
Pour obtenir cette architecture, vous devez installer le runtime d’intégration Azure Data Factory (auto-hébergé) sur une machine Windows derrière un pare-feu d’entreprise. Assurez-vous que ce runtime d’intégration peut accéder directement au serveur Netezza. Pour utiliser pleinement votre bande passante réseau et la bande passante des magasins de données afin de copier les données, vous pouvez effectuer un scale-up manuel de votre machine ou un scale-out vers plusieurs machines.
À l’aide de cette architecture, vous pouvez migrer des données d’instantanés initiales et des données delta.
Migrer des données sur un réseau privé
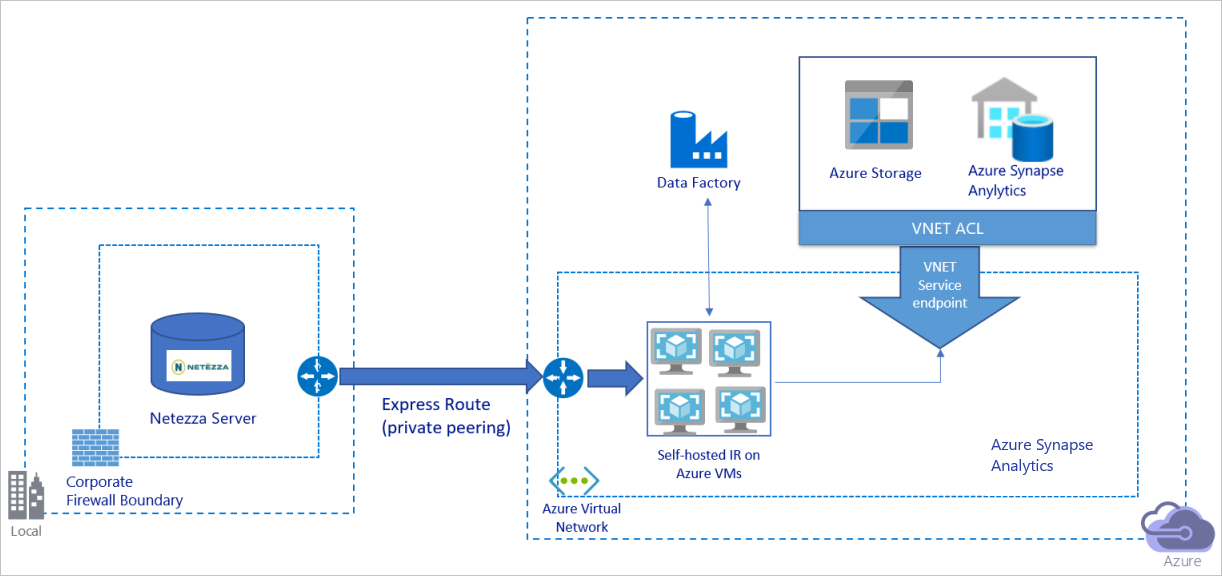
Le diagramme précédent peut être interprété comme suit :
Dans cette architecture, vous migrez les données via un lien d’appairage privé et via Azure Express Route ; les données ne transitent jamais par l’Internet public.
Pour réaliser cette architecture, vous devez installer le runtime d’intégration Azure Data Factory (auto-hébergé) sur une machine virtuelle Windows au sein de votre réseau virtuel Azure. Pour utiliser pleinement votre bande passante réseau et la bande passante des magasins de données afin de copier les données, vous pouvez effectuer un scale-up manuel de votre machine virtuelle ou un scale-out vers plusieurs machines virtuelles.
À l’aide de cette architecture, vous pouvez migrer des données d’instantanés initiales et des données delta.
Mettre en œuvre les bonnes pratiques
Gérer l’authentification et les informations d’identification
Pour vous authentifier auprès de Netezza, vous pouvez utiliser l’authentification ODBC via une chaîne de connexion.
Pour vous authentifier auprès du stockage d’objets blob Azure :
Nous vous recommandons vivement d'utiliser des identités managées pour les ressources Azure. Basées sur une identité Azure Data Factory automatiquement managée dans Microsoft Entra ID, les identités managées vous permettent de configurer des pipelines sans avoir à fournir d’informations d’identification dans la définition du service lié.
Vous pouvez également vous authentifier auprès de Stockage Blob Azure à l’aide du principal de service, d’une signature d’accès partagé ou d’une clé de compte de stockage.
Pour vous authentifier auprès d’Azure Data Lake Storage Gen2 :
Nous vous recommandons vivement d'utiliser des identités managées pour les ressources Azure.
Vous pouvez également utiliser le principal de service ou une clé de compte de stockage.
Pour s’authentifier auprès d’Azure Synapse Analytics :
Nous vous recommandons vivement d'utiliser des identités managées pour les ressources Azure.
Vous pouvez également utiliser le principal de service ou l’authentification SQL.
Quand vous n’utilisez pas d’identités managées pour les ressources Azure, nous vous recommandons vivement de stocker les informations d’identification dans Azure Key Vault pour faciliter la gestion centralisée et la rotation des clés sans avoir à modifier les services liés Azure Data Factory. Il s’agit également de l'une des meilleures pratiques pour CI/CD.
Migrer les données d’instantané initiales
Pour les petites tables (c’est-à-dire, celle dont le volume est inférieur à 100 Go ou peut peuvent être migrées vers Azure en deux heures), vous pouvez faire en sorte que chaque tâche de copie charge les données par table. Afin d’obtenir un meilleur débit, vous pouvez exécuter plusieurs tâches de copie Azure Data Factory pour charger des tables distinctes simultanément.
Pour chaque tâche de copie, afin d’exécuter des requêtes parallèles et de copier les données par partition, vous pouvez également atteindre un certain niveau de parallélisme en utilisant le paramètre de propriété parallelCopies avec l’une des options de partition de données suivantes :
Pour une meilleure efficacité, nous vous encourageons à démarrer à partir d’une tranche de données. Assurez-vous que la valeur du paramètre
parallelCopiesest inférieure au nombre total de partitions de la tranche de données dans votre table sur le serveur Netezza.Si le volume de chaque partition de la tranche de données est toujours volumineux (par exemple, 10 Go ou plus), nous vous encourageons à basculer vers une partition par spécification de plages de valeurs dynamique. Cette option offre une plus grande souplesse pour définir le nombre de partitions et le volume de chaque partition par colonne de partition, la limite supérieure et la limite inférieure.
Pour les tables plus grandes (c’est-à-dire, les tables dont le volume est de 100 Go ou plus, ou qui ne peuvent pas être migrées vers Azure dans un délai de deux heures), nous vous recommandons de partitionner les données par requête personnalisée, puis de faire en sorte que chaque tâche de copie copie une partition à la fois. Pour un meilleur débit, vous pouvez exécuter plusieurs tâches de copie Azure Data Factory simultanément. Pour que chaque cible de tâche de copie charge une partition par requête personnalisée, vous pouvez augmenter le débit en activant le parallélisme via une tranche de données ou une plage dynamique.
Si une tâche de copie échoue en raison d’un problème temporaire de réseau ou de magasin de données, vous pouvez réexécuter la tâche de copie ayant échoué pour recharger cette partition spécifique à partir de la table. Les autres tâches de copie qui chargent d’autres partitions ne sont pas affectées.
Quand vous chargez des données dans une base de données Azure Synapse Analytics, nous vous suggérons d’activer PolyBase dans la tâche de copie avec le stockage d’objets blob Azure en guise de préproduction.
Migrer des données delta
Pour identifier les lignes nouvelles ou mises à jour de votre table, utilisez une colonne timestamp ou une clé d’incrémentation dans le schéma. Vous pouvez ensuite stocker la valeur la plus récente en tant que limite supérieure dans une table externe, puis l’utiliser pour filtrer les données delta la prochaine fois que vous chargez des données.
Chaque table peut utiliser une colonne de limite différente pour identifier ses lignes nouvelles ou mises à jour. Nous vous suggérons de créer une table de contrôle externe. Dans la table, chaque ligne représente une table sur le serveur Netezza avec son nom de colonne de limite spécifique et sa valeur de limite supérieure.
Configurer un runtime d’intégration auto-hébergé
Si vous migrez des données à partir du serveur Netezza vers Azure, que le serveur soit local derrière votre pare-feu d’entreprise ou dans un environnement de réseau virtuel, vous devez installer un runtime d’intégration auto-hébergé sur une machine Windows ou une machine virtuelle, qui est le moteur utilisé pour le déplacement des données. Quand vous installez le runtime d’intégration auto-hébergé, nous vous recommandons l’approche suivante :
Pour chaque machine Windows ou machine virtuelle, commencez avec une configuration de 32 processeurs virtuels et de 128 Go de mémoire. Vous pouvez continuer à superviser l’utilisation du processeur et de la mémoire de la machine de runtime d’intégration pendant la migration des données afin de déterminer si vous devez continuer le scale-up de la machine pour améliorer les performances ou effectuer un scale-down de la machine pour réduire les coûts.
Vous pouvez également effectuer un scale-out en associant jusqu’à quatre nœuds à un seul runtime d’intégration auto-hébergé. Une seule tâche de copie exécutée sur un runtime d’intégration auto-hébergé applique automatiquement tous les nœuds de machine virtuelle pour copier les données en parallèle. Pour une haute disponibilité, commencez par quatre nœuds de machine virtuelle afin d’éviter un point de défaillance unique pendant la migration des données.
Limiter vos partitions
La bonne pratique est de mener une preuve de concept (POC) par rapport aux performances avec un exemple de jeu de données représentatif, afin de déterminer une taille de partition appropriée pour chaque activité de copie. Nous vous suggérons de charger chaque partition sur Azure dans un délai de deux heures.
Pour copier une table, commencez par une seule activité de copie avec une seule machine de runtime d’intégration auto-hébergé. Augmentez progressivement le paramètre parallelCopies en fonction du nombre de partitions de tranche de données dans votre table. Déterminez si la totalité de la table peut être chargée sur Azure dans un délai de deux heures, en fonction du débit qui résulte de la tâche de copie.
Si elle ne peut pas être chargée sur Azure dans un délai de deux heures et que la capacité du nœud de runtime d’intégration auto-hébergé et du magasin de données n’est pas entièrement utilisée, augmentez progressivement le nombre d’activités de copie simultanées jusqu’à atteindre la limite de votre réseau ou la bande passante limite des magasins de données.
Poursuivez la supervision de l’utilisation du processeur et de la mémoire sur la machine de runtime d’intégration auto-hébergé et préparez-vous à effectuer un scale-up de la machine ou un scale-out vers plusieurs machines quand vous voyez que le processeur et la mémoire sont entièrement utilisées.
Quand vous rencontrez des erreurs de limitation, telles que signalées par l’activité de copie d’Azure Data Factory, réduisez le paramètre d’accès simultané ou parallelCopies dans Azure Data Factory, ou envisagez d’augmenter les limites de bande passante ou IOPS (opérations d’E/S par seconde) des magasins de données et du réseau.
Estimer vos tarifs
Considérez le pipeline suivant, construit pour migrer des données à partir du serveur Netezza local vers une base de données Azure Synapse Analytics :
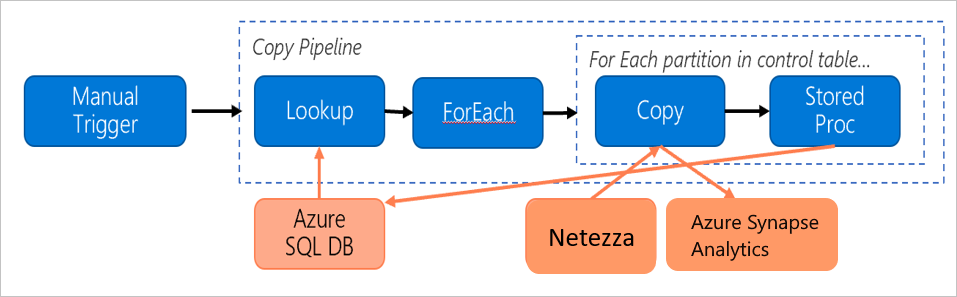
Supposons que les affirmations suivantes sont vraies :
Le volume total de données est de 50 téraoctets (to).
Nous migrons des données à l’aide de la première architecture de solution (le serveur Netezza local derrière le pare-feu).
Le volume de 50 To est divisé en 500 partitions et chaque activité de copie déplace une partition.
Chaque activité de copie est configurée avec un runtime d’intégration auto-hébergé sur quatre machines et atteint un débit de 20 mégaoctets par seconde (Mo/s). (Dans l’activité de copie,
parallelCopiesa pour valeur 4 et chaque thread de chargement de données à partir de la table atteint un débit de 5 Mbits/s.)L’accès concurrentiel ForEach est défini sur 3 et le débit agrégé est de 60 Mbits/s.
Au total, il faut 243 heures pour réaliser la migration.
En fonction des hypothèses précédentes, voici les tarifs estimés :
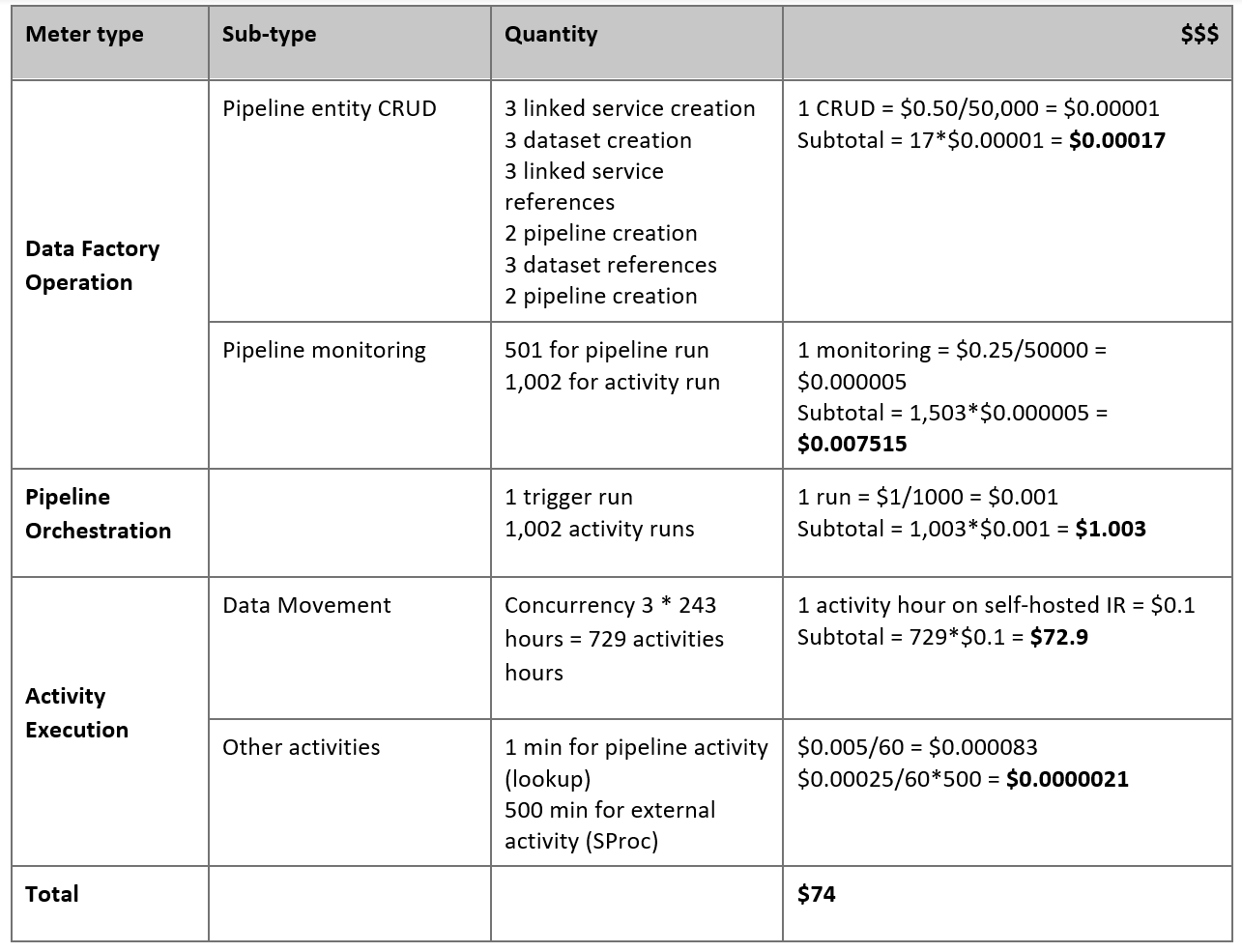
Notes
Les tarifs indiqués dans le tableau précédent sont hypothétiques. Vos tarifs réels dépendent du débit réel dans votre environnement. Le prix pour la machine Windows (avec le runtime d’intégration auto-hébergé installé) n’est pas inclus.
Références supplémentaires
Pour plus d’informations, consultez les articles et guides suivants :
- Connecteur Netezza
- Connecteur ODBC
- Connecteur de stockage Blob Azure
- Connecteur Azure Data Lake Storage Gen2
- Connecteur Azure Synapse Analytics
- Guide sur les performances et le réglage de l’activité de copie
- Créer et configurer un runtime d’intégration auto-hébergé
- Extensibilité et haute disponibilité du runtime d’intégration auto-hébergé
- Considérations relatives à la sécurité des déplacements de données
- Stocker les informations d’identification dans Azure Key Vault
- Copier de façon incrémentielle des données d’une table
- Copier de façon incrémentielle des données de plusieurs tables
- Page de tarification d’Azure Data Factory