Transformation d’assertions dans le flux de données de mappage
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Les flux de données sont disponibles à la fois dans les pipelines Azure Data Factory et Azure Synapse. Cet article s’applique aux flux de données de mappage. Si vous débutez dans le domaine des transformations, consultez l’article d’introduction Transformer des données avec un flux de données de mappage.
La transformation d’instruction d’assertion vous permet de créer des règles personnalisées dans vos flux de données de mappage, pour évaluer la qualité des données et les valider. Vous pouvez créer des règles qui déterminent si les valeurs correspondent à un domaine de valeurs attendu. Vous pouvez aussi créer des règles qui vérifient si les lignes sont uniques. La transformation des instructions d’assertion vous aide à déterminer si chaque ligne de vos donnée correspond à un jeu de critères. La transformation des instructions d’assertion vous permet aussi de définir des messages d’erreur personnalisés lorsque les règles de validation des données ne sont pas respectées.
Configuration
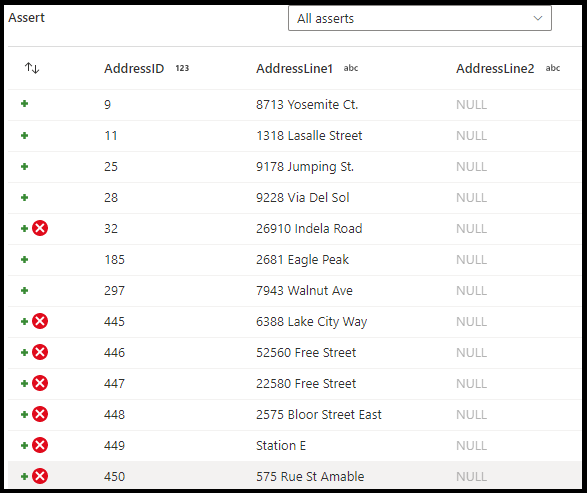
Dans le panneau de configuration de la transformation des instructions d’assertion, vous choisissez le type d’instruction d’assertion, le nom unique de cette instruction d’assertion, une description facultative et vous définissez l’expression et le filtre facultatif. Le volet d’aperçu des données indique les lignes qui ont échoué pour vos instructions d’assertion. Vous pouvez aussi tester chaque étiquette de ligne en aval à l’aide de isError() et de hasError() pour les lignes qui ont échoué à vos instructions d’assertion.
Type d’assertion
- Expect true : le résultat de votre expression doit correspondre à un résultat booléen vrai. Utilisez ce paramètre pour valider les plages de valeurs de domaine dans vos données.
- Expect unique : définissez une colonne ou une expression comme règle unique dans vos données. Utilisez ce paramètre pour baliser les lignes dupliquées.
- Expect exists : cette option est uniquement disponible lorsque vous avez sélectionné un deuxième flux entrant. Exists examine les deux flux et détermine si les lignes existent dans les deux flux en fonction des colonnes ou des expressions que vous avez spécifiées. Pour ajouter un deuxième flux pour les existants, sélectionnez
Additional streams.
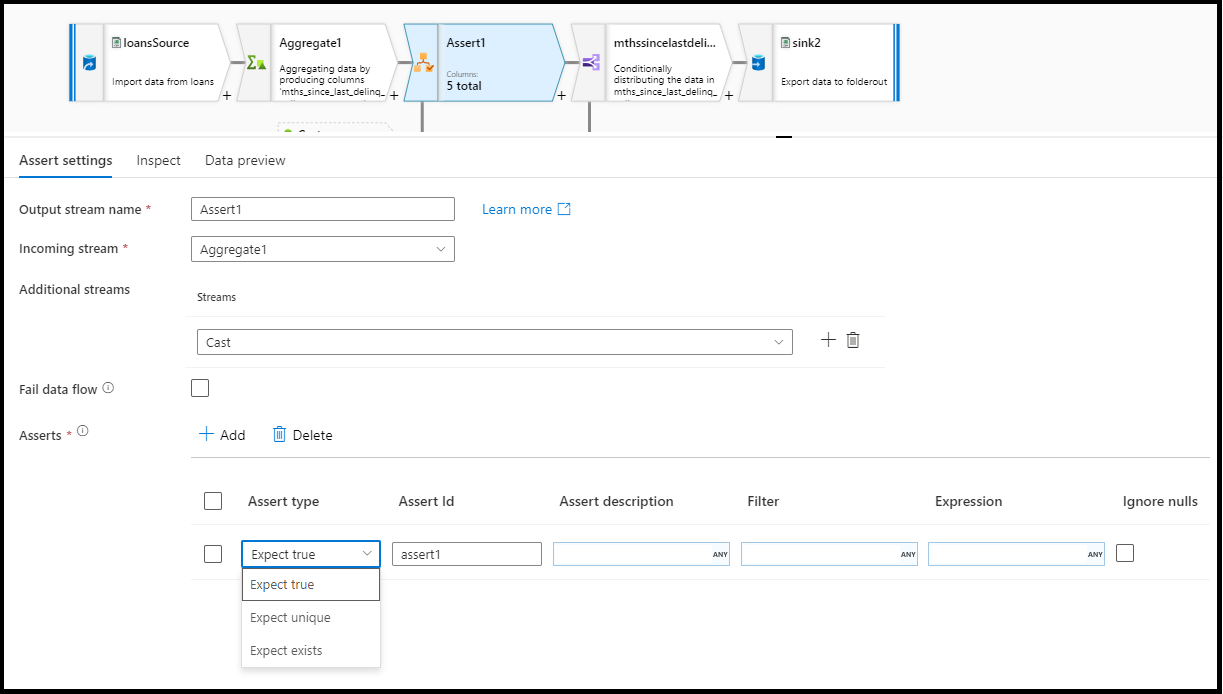
Échec du flux de données
Sélectionnez fail data flow si vous souhaitez que votre activité de flux de données échoue immédiatement dès que votre règle d’instruction d’assertion échoue.
Assert ID
Assert ID est une propriété dans laquelle vous entrez un nom (chaîne) pour votre instruction d’assertion. Vous pouvez utiliser cet identifiant plus tard dans votre flux de données à l’aide de hasError() ou pour produire le code d’échec de l’instruction d’assertion. Les ID d’assertion doivent être uniques dans chaque flux de données.
Description de l’assertion
Entrez une chaîne de description de votre instruction d’assertion ici. Vous pouvez utiliser des expressions et des valeurs de colonne de contexte de ligne ici aussi.
Filtrer
Le filtre est une propriété facultative qui permet de filtrer l’instruction d’assertion uniquement d’un sous-ensemble de lignes en fonction de la valeur de votre expression.
Expression
Entrez une expression pour l’évaluation de chacune de vos instructions d’assertion. Vous pouvez avoir plusieurs instructions d’assertion pour chaque transformation d’instruction d’assertion. Chaque type d’instruction d’assertion exige une expression qu’ADF utilise pour évaluer si l’instruction d’assertion a réussi.
Ignorer les valeurs NULL
Par défaut, la transformation de l’instruction d’assertion comprend des lignes NULL dans l’évaluation de l’instruction d’assertion. Vous pouvez choisir d’ignorer les valeurs NULL avec cette propriété.
Échecs de ligne d’assertion directe
Lorsqu’une assertion échoue, vous pouvez éventuellement diriger ces lignes d’erreur vers un fichier dans Azure à l’aide de l’onglet « Erreurs » de la transformation du récepteur. Vous disposez également d’une option sur la transformation du récepteur pour ne pas générer de lignes avec des échecs d’assertion du tout en ignorant les lignes d’erreur.
Exemples
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Script de flux de données
Exemples
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Contenu connexe
- Utilisez Sélectionner la transformation pour sélectionner et valider des colonnes.
- Utilisez la Transformation de colonne dérivée pour transformer des valeurs de colonnes.