Tolérance de panne de l’activité de copie dans les pipelines Azure Data Factory et Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Lorsque vous copiez des données de la source vers le magasin de destination, l’activité de copie fournit un certain niveau de tolérance de panne pour éviter des interruptions dues à des défaillances survenant au beau milieu d’un déplacement de données. Par exemple, vous procédez à la copie de millions de lignes de la source vers le magasin de destination alors qu’une clé primaire a été créée dans la base de données de destination et qu’aucune clé primaire n’a été définie pour la base de données source. Lorsque vous copierez des lignes dupliquées de la source vers la destination, vous serez confronté à l’échec dû à la violation de la clé primaire sur la base de données de destination. À ce stade, l’activité de copie vous propose deux moyens de gérer ces erreurs :
- Vous pouvez abandonner l’activité de copie dès qu’un échec est rencontré.
- Vous pouvez continuer l’opération de copie en activant la tolérance de panne pour ignorer les données incompatibles. Par exemple, ignorer la ligne dupliquée dans ce cas. De plus, vous pouvez consigner les données ignorées en activant le journal de session dans l’activité de copie. Pour plus d’informations, reportez-vous au journal de session dans l’activité de copie .
Copie de fichiers binaires
Le service prend en charge les scénarios de tolérance de panne suivants au cours de la copie de fichiers binaires. Vous pouvez choisir d’abandonner l’activité de copie, ou de continuer à copier le reste des données dans les scénarios suivants :
- Les fichiers à copier par le service sont au même moment en cours de suppression par d’autres applications.
- Certains dossiers ou fichiers particuliers n’autorisent pas l’accès au service, car les listes de contrôle d’accès de ces fichiers ou dossiers nécessitent un niveau d’autorisation supérieur à celui des informations de connexion configurées.
- Un ou plusieurs fichiers ne sont pas trouvés cohérents entre les magasins source et de destination si vous activez le paramètre de vérification de cohérence des données.
Activer la tolérance de panne avec l’interface utilisateur
Pour configurer la tolérance de panne dans une activité Copy dans un pipeline avec l’interface utilisateur, procédez comme suit :
Si vous n’avez pas encore créé d’activité Copy pour votre pipeline, recherchez Copie dans le volet activités de pipeline, puis faites glisser une activité copier des données vers le canevas du pipeline.
Sélectionnez la nouvelle activité Copier des données sur le canevas si ce n’est pas déjà le cas, et son onglet Paramètres pour en configurer la tolérance de panne.
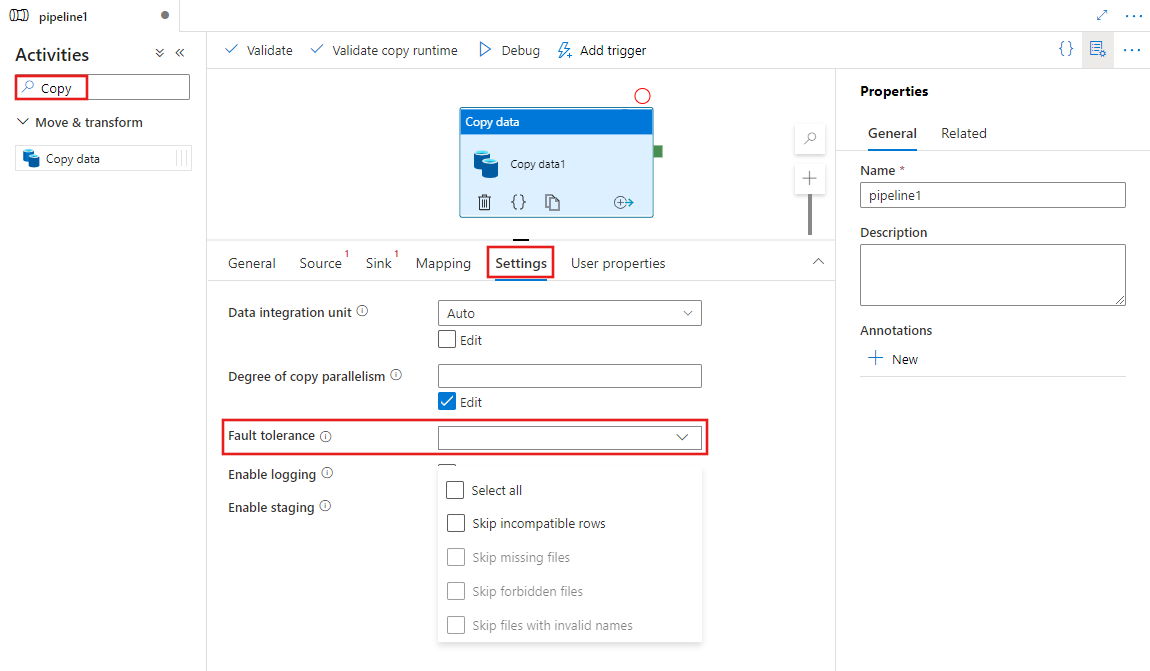
Configuration
Lorsque vous copiez des fichiers binaires entre des magasins de stockage, vous pouvez activer la tolérance de panne de la façon suivante :
{
"name": "CopyActivityFaultTolerance",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureDataLakeStoreReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureDataLakeStoreWriteSettings"
}
},
"skipErrorFile": {
"fileMissing": true,
"fileForbidden": true,
"dataInconsistency": true,
"invalidFileName": true
},
"validateDataConsistency": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
}
}
| Propriété | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| skipErrorFile | Groupe de propriétés permettant de spécifier les types de défaillances que vous souhaitez ignorer pendant le déplacement des données. | Non | |
| fileMissing | Une des paires clé-valeur dans le jeu de propriétés skipErrorFile permettant de déterminer si vous souhaitez ignorer les fichiers qui sont en cours de suppression par d’autres applications au moment où le service effectue l’opération de copie. \- True : vous souhaitez copier les fichiers en ignorant ceux qui sont supprimés par d’autres applications. - False : vous voulez abandonner l’activité de copie lorsque des fichiers sont supprimés du magasin source au cours d’un déplacement de données. Sachez que cette propriété est définie sur True par défaut. |
True(default) False |
Non |
| fileForbidden | Une des paires clé-valeur dans le jeu de propriétés skipErrorFile permettant de déterminer si vous souhaitez ignorer des fichiers particuliers lorsque les listes de contrôle d’accès de ces fichiers ou dossiers nécessitent un niveau d’autorisation plus élevé que celui de la connexion configurée. \- True : vous souhaitez effectuer la copie en ignorant ces fichiers. - False : vous voulez abandonner l’activité de copie lorsque vous êtes confronté au problème d’autorisation sur des dossiers ou des fichiers. |
Vrai
False(default) |
Non |
| dataInconsistency | Une des paires clé-valeur dans le jeu de propriétés skipErrorFile permettant de déterminer si vous souhaitez ignorer les données incohérentes entre les magasins source et de destination. - True : vous souhaitez effectuer la copie en ignorant les données incohérentes. - False : vous souhaitez abandonner l’activité de copie lorsque des données incohérentes ont été trouvées. Sachez que cette propriété n’est valide que lorsque vous définissez validateDataConsistency sur la valeur True. |
Vrai
False(default) |
Non |
| invalidFileName | Une des paires clé-valeur dans le conteneur de propriétés skipErrorFile permettant de déterminer si vous voulez ignorer des fichiers particuliers quand les noms de fichiers ne sont pas valides pour le magasin source. \- True : vous voulez copier le reste en ignorant les fichiers qui ont des noms de fichiers non valides. - False : vous voulez abandonner l’activité de copie dès lors qu’un fichier a un nom de fichier non valide. Notez bien que cette propriété fonctionne seulement lors de la copie de fichiers binaires depuis un magasin de stockage vers ADLS Gen2 ou lors de la copie de fichiers binaires depuis AWS S3 vers n’importe quel magasin de stockage. |
Vrai
False(default) |
Non |
| logSettings | Groupe de propriétés pouvant être spécifié lorsque vous souhaitez journaliser les noms des objets ignorés. | Non | |
| linkedServiceName | Service lié de Stockage Blob Azure ou Azure Data Lake Storage Gen2 pour stocker les fichiers journaux de session. | Noms d’un service lié de type AzureBlobStorage ou AzureBlobFS faisant référence à l’instance que vous utilisez pour stocker le fichier journal. |
Non |
| path | Chemin des fichiers journaux. | Spécifiez le chemin que vous utilisez pour stocker les fichiers journaux. Si vous ne spécifiez pas le chemin d’accès, le service crée un conteneur à votre place. | Non |
Notes
Vous trouverez ci-dessous les conditions préalables à l’activation de la tolérance de panne dans l’activité de copie lors de la copie de fichiers binaires. Pour ignorer des fichiers particuliers lorsqu’ils sont supprimés du magasin source :
- Les jeux de données source et récepteur doivent être au format binaire, et le type de compression ne peut pas être spécifié.
- Les types de magasins de données pris en charge sont Stockage Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, Système de fichiers, FTP, SFTP, Amazon S3, Google Cloud Storage et HDFS.
- Si vous spécifiez plusieurs fichiers dans le jeu de données source, qui peut être un dossier, un caractère générique ou une liste de fichiers, l’activité de copie peut ignorer les fichiers d’erreur particuliers. Si un seul fichier est spécifié dans le jeu de données source à copier vers la destination, l’activité de copie échoue si une erreur s’est produite.
Pour ignorer des fichiers particuliers lorsqu’ils ne sont plus accessibles du magasin source :
- Les jeux de données source et récepteur doivent être au format binaire, et le type de compression ne peut pas être spécifié.
- Les types de magasins de données pris en charge sont Stockage Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, SFTP, Amazon S3 et HDFS.
- Si vous spécifiez plusieurs fichiers dans le jeu de données source, qui peut être un dossier, un caractère générique ou une liste de fichiers, l’activité de copie peut ignorer les fichiers d’erreur particuliers. Si un seul fichier est spécifié dans le jeu de données source à copier vers la destination, l’activité de copie échoue si une erreur s’est produite.
Pour ignorer des fichiers particuliers lorsqu’ils sont vérifiés comme étant incohérents entre la source et le magasin de destination :
- Vous pouvez obtenir plus de détails à partir du document de cohérence des données ici.
Surveillance
Sortie de l’activité de copie
Vous pouvez obtenir le nombre de fichiers lus, écrits et ignorés par le biais de la sortie de chaque exécution de l’activité de copie.
"output": {
"dataRead": 695,
"dataWritten": 186,
"filesRead": 3,
"filesWritten": 1,
"filesSkipped": 2,
"throughput": 297,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "Skipped"
}
}
Journal de session depuis l’activité de copie
Si vous configurez de manière à consigner les noms des fichiers ignorés, vous pouvez trouver le fichier journal à l’emplacement suivant : https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Les fichiers journaux doivent être les fichiers CSV. Le schéma du fichier journal est le suivant :
| Colonne | Description |
|---|---|
| Timestamp | Timestamp lorsque le fichier a été ignoré. |
| Level | Niveau de journalisation de cet élément. Il sera au niveau « Avertissement » pour l’élément indiquant que le fichier est ignoré. |
| NomOpération | Comportement opérationnel de l’activité de copie sur chaque fichier. Le fichier à ignorer sera indiqué par la mention « FileSkip ». |
| OperationItem | Noms des fichiers à ignorer. |
| Message | Informations supplémentaires permettant d’expliquer la raison pour laquelle le fichier est ignoré. |
Voici un exemple de fichier journal :
Timestamp,Level,OperationName,OperationItem,Message
2020-03-24 05:35:41.0209942,Warning,FileSkip,"bigfile.csv","File is skipped after read 322961408 bytes: ErrorCode=UserErrorSourceBlobNotExist,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=The required Blob is missing. ContainerName: https://transferserviceonebox.blob.core.windows.net/skipfaultyfile, path: bigfile.csv.,Source=Microsoft.DataTransfer.ClientLibrary,'."
2020-03-24 05:38:41.2595989,Warning,FileSkip,"3_nopermission.txt","File is skipped after read 0 bytes: ErrorCode=AdlsGen2OperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'Forbidden'. Account: 'adlsgen2perfsource'. FileSystem: 'skipfaultyfilesforbidden'. Path: '3_nopermission.txt'. ErrorCode: 'AuthorizationPermissionMismatch'. Message: 'This request is not authorized to perform this operation using this permission.'. RequestId: '35089f5d-101f-008c-489e-01cce4000000'..,Source=Microsoft.DataTransfer.ClientLibrary,''Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Operation returned an invalid status code 'Forbidden',Source=,''Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message='Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code 'Forbidden',Source=Microsoft.DataTransfer.ClientLibrary,',Source=Microsoft.DataTransfer.ClientLibrary,'."
Dans le journal ci-dessus, vous pouvez voir que bigfile.csv a été ignoré, car une autre application supprimait ce fichier lors de sa copie par le service. 3_nopermission.txt a été ignoré, car il n’est pas accessible au service en raison d’un problème d’autorisation.
Copie de données tabulaires
Scénarios pris en charge
L’activité de copie offre trois possibilités de détecter, d’ignorer et de journaliser les incompatibilités de données tabulaires suivantes :
Incompatibilité entre le type de données sources et le type natif récepteur
Par exemple : Copier des données d’un fichier CSV dans Stockage Blob vers une base de données SQL avec une définition de schéma contenant trois colonnes de type INT. Les lignes du fichier CSV qui contiennent des données numériques, telles que 123 456 789, sont correctement copiées dans le magasin récepteur. En revanche, les lignes qui contiennent des valeurs non numériques, telles que 123 456, abc, sont considérées comme incompatibles et ignorées.
Incompatibilité du nombre de colonnes entre la source et le récepteur
Par exemple : Copier des données d’un fichier CSV dans Stockage Blob vers une base de données SQL avec une définition de schéma contenant six colonnes. Les lignes du fichier CSV qui contiennent six colonnes sont correctement copiées dans le magasin récepteur. Les lignes du fichier CSV qui contiennent plus de six colonnes sont considérées comme incompatibles et ignorées.
Violation de clé primaire lors de l’écriture dans SQL Server/Azure SQL Database/Azure Cosmos DB.
Par exemple : Copier des données d’un serveur SQL vers une base de données SQL. Il existe une clé primaire définie dans la base de données SQL réceptrice, mais aucune clé primaire correspondante n’est définie dans le serveur SQL source. Les lignes en double qui peuvent exister dans la source ne sont pas copiées dans le récepteur. L’activité de copie ne copie que la première ligne des données sources dans le récepteur. Toutes les lignes sources suivantes contenant une valeur de clé primaire en double sont considérées comme incompatibles et ignorées.
Notes
- Pour charger des données dans Azure Synapse Analytics avec PolyBase, configurez les paramètres natifs de la tolérance de panne de PolyBase en spécifiant des règles de rejet via « polyBaseSettings » dans l’activité de copie. Vous pouvez toujours activer la redirection des lignes PolyBase incompatibles vers Blob ou ADLS normalement, comme indiqué ci-dessous.
- Cette fonctionnalité ne s’applique pas lorsque l’activité de copie est configurée de sorte à appeler Amazon Redshift Unload.
- Cette fonctionnalité ne s’applique pas quand l’activité de copie est configurée pour appeler une procédure stockée à partir d’un récepteur SQL ou pour utiliser Upsert pour écrire des données dans un récepteur SQL.
Configuration
L’exemple suivant fournit une définition JSON pour configurer l’omission des lignes incompatibles dans le cadre de l’activité de copie :
"typeProperties": {
"source": {
"type": "AzureSqlSource"
},
"sink": {
"type": "AzureSqlSink"
},
"enableSkipIncompatibleRow": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
},
| Propriété | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| enableSkipIncompatibleRow | Indique s’il faut ignorer ou non les lignes incompatibles durant la copie. | True false (valeur par défaut) |
Non |
| logSettings | Groupe de propriétés qui peuvent être spécifiées lorsque vous souhaitez journaliser les lignes incompatibles. | Non | |
| linkedServiceName | Service lié de Stockage Blob Azure ou Azure Data Lake Storage Gen2 pour stocker le journal contenant les lignes ignorées. | Noms d’un service lié de type AzureBlobStorage ou AzureBlobFS faisant référence à l’instance que vous utilisez pour stocker le fichier journal. |
Non |
| path | Chemin des fichiers journaux contenant les lignes ignorées. | Spécifiez le chemin que vous souhaitez utiliser pour journaliser les données incompatibles. Si vous ne spécifiez pas le chemin d’accès, le service crée un conteneur à votre place. | Non |
Effectuer le monitoring des lignes ignorées
Une fois l’activité de copie exécutée, vous pouvez voir le nombre de lignes ignorées dans la sortie de l’activité de copie :
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Si vous configurez de manière à consigner les lignes incompatibles, vous pouvez trouver le fichier journal à l’emplacement suivant : https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Les fichiers journaux seront les fichiers CSV. Le schéma du fichier journal est le suivant :
| Colonne | Description |
|---|---|
| Timestamp | Timestamp lorsque les lignes incompatibles ont été ignorées. |
| Level | Niveau de journalisation de cet élément. Il sera au niveau « Avertissement » si cet élément affiche les lignes ignorées |
| NomOpération | Comportement opérationnel de l’activité de copie sur chaque ligne. Il sera « TabularRowSkip » pour indiquer que la ligne incompatible spécifique a été ignorée |
| OperationItem | Lignes ignorées depuis le magasin de données source. |
| Message | Informations supplémentaires permettant d’expliquer la raison de l’incompatibilité de cette ligne particulière. |
Voici un exemple de contenu de fichier journal :
Timestamp, Level, OperationName, OperationItem, Message
2020-02-26 06:22:32.2586581, Warning, TabularRowSkip, """data1"", ""data2"", ""data3""," "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
2020-02-26 06:22:33.2586351, Warning, TabularRowSkip, """data4"", ""data5"", ""data6"",", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Dans l’exemple de fichier journal ci-dessus, vous pouvez voir qu’une ligne « data1, data2, data3 » a été ignorée de la source vers le magasin de destination en raison d’un problème de conversion de type. Une autre ligne « data4, data5, data6 » a été ignorée de la source vers le magasin de destination en raison d’un problème de violation de clé primaire.
Copie des données tabulaires (héritées) :
Voici l’approche héritée permettant d’activer la tolérance de panne pour la copie de données tabulaires uniquement. Si vous créez un pipeline ou une activité, nous vous conseillons de démarrer plutôt à partir d’ici.
Configuration
L’exemple suivant fournit une définition JSON pour configurer l’omission des lignes incompatibles dans le cadre de l’activité de copie :
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
},
"enableSkipIncompatibleRow": true,
"redirectIncompatibleRowSettings": {
"linkedServiceName": {
"referenceName": "<Azure Storage or Data Lake Store linked service>",
"type": "LinkedServiceReference"
},
"path": "redirectcontainer/erroroutput"
}
}
| Propriété | Description | Valeurs autorisées | Obligatoire |
|---|---|---|---|
| enableSkipIncompatibleRow | Indique s’il faut ignorer ou non les lignes incompatibles durant la copie. | True false (valeur par défaut) |
Non |
| redirectIncompatibleRowSettings | Groupe de propriétés qui peuvent être spécifiées lorsque vous souhaitez journaliser les lignes incompatibles. | Non | |
| linkedServiceName | Service lié de Stockage Azure ou Azure Data Lake Store pour stocker le journal contenant les lignes ignorées. | Noms d’un service lié de type AzureStorage ou AzureDataLakeStore faisant référence à l’instance que vous souhaitez utiliser pour stocker le fichier journal. |
Non |
| path | Chemin d’accès du fichier journal contenant les lignes ignorées. | Spécifiez le chemin que vous souhaitez utiliser pour journaliser les données incompatibles. Si vous ne spécifiez pas le chemin d’accès, le service crée un conteneur à votre place. | Non |
Effectuer le monitoring des lignes ignorées
Une fois l’activité de copie exécutée, vous pouvez voir le nombre de lignes ignorées dans la sortie de l’activité de copie :
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"redirectRowPath": "https://myblobstorage.blob.core.windows.net//myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Si vous effectuez la configuration de manière à enregistrer les lignes incompatibles, vous pouvez trouver le fichier journal sous le chemin d’accès suivant : https://[your-blob-account].blob.core.windows.net/[path-if-configured]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Les fichiers journaux peuvent être uniquement les fichiers csv. Les données d’origine ignorées seront enregistrées avec la virgule comme délimiteur de colonne si nécessaire. Nous ajoutons deux colonnes supplémentaires « ErrorCode » et « ErrorMessage » en plus des données sources d’origine dans le fichier journal, où vous pouvez voir la cause racine de l’incompatibilité. Les valeurs ErrorCode et ErrorMessage figurent entre guillemets doubles.
Voici un exemple de contenu de fichier journal :
data1, data2, data3, "UserErrorInvalidDataValue", "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
data4, data5, data6, "2627", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Contenu connexe
Consultez les autres articles relatifs à l’activité de copie :