Copier des données de Cassandra à l’aide d’Azure Data Factory ou de Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment utiliser l’activité de copie dans un pipeline Azure Data Factory ou Synapse Analytics pour copier des données à partir d’une base de données Cassandra. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Fonctionnalités prises en charge
Ce connecteur Cassandra est pris en charge pour les capacités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | ① ② |
| Activité de recherche | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des magasins de données pris en charge en tant que sources et récepteurs, consultez le tableau Magasins de données pris en charge.
Plus précisément, ce connecteur Cassandra prend en charge :
- Cassandra versions 2.x et 3.x.
- Copie de données en utilisant une authentification De base ou Anonyme.
Notes
Pour une activité exécutée sur le runtime d’intégration auto-hébergé, Cassandra 3.x est pris en charge à partir d’Integration Runtime version 3.7 ou supérieure.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Le runtime d’intégration fournit un pilote Cassandra intégré. Ainsi, vous n’avez pas besoin d’installer manuellement un pilote lors de la copie des données vers/depuis Cassandra.
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créez un service lié à Cassandra à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Cassandra dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Cassandra et sélectionnez le connecteur Cassandra.
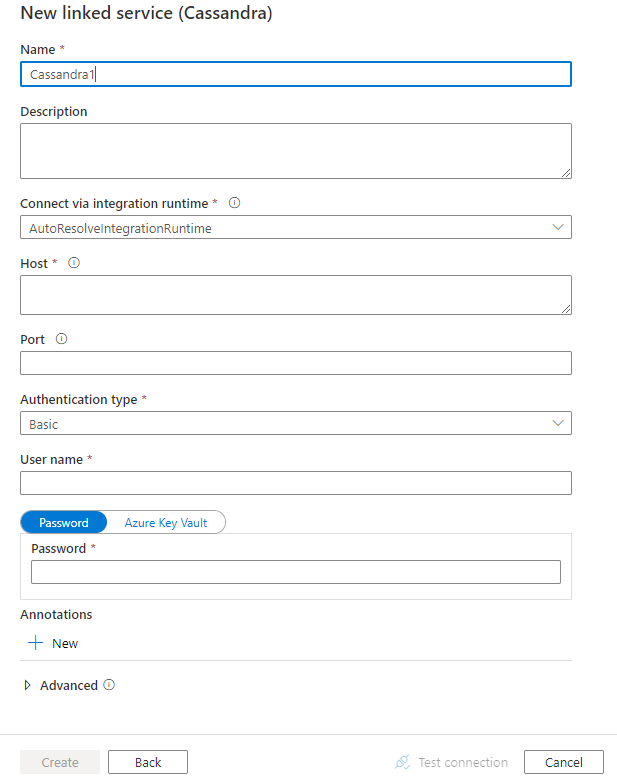
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
Détails de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory spécifiques du connecteur Cassandra.
Propriétés du service lié
Les propriétés prises en charge pour le service lié Cassandra sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur : Cassandra | Oui |
| host | Une ou plusieurs adresses IP ou noms d’hôte de serveurs Cassandra. Renseignez une liste des adresses IP ou des noms d’hôte séparée par des virgules pour vous connecter simultanément à tous les serveurs. |
Oui |
| port | Le port TCP utilisé par le serveur Cassandra pour écouter les connexions clientes. | Non (la valeur par défaut 9042) |
| authenticationType | Type d'authentification utilisé pour se connecter à la base de données Cassandra. Les valeurs autorisées sont les suivantes : De base, et Anonyme. |
Oui |
| username | Spécifiez le nom d’utilisateur du compte d’utilisateur. | Oui, si authenticationType est défini sur De base. |
| mot de passe | Spécifiez le mot de passe du compte d'utilisateur. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Oui, si authenticationType est défini sur De base. |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Notes
Actuellement, la connexion à Cassandra à l’aide de TLS n’est pas prise en charge.
Exemple :
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Cassandra.
Pour copier des données de Cassandra, affectez la valeur CassandraTable à la propriété type du jeu de données. Les propriétés prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur : CassandraTable | Oui |
| espace de clé | Nom de l’espace de clé ou du schéma dans la base de données Cassandra. | Non (si « query » pour « CassandraSource » est spécifié) |
| tableName | Nom de la table dans la base de données Cassandra. | Non (si « query » pour « CassandraSource » est spécifié) |
Exemple :
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source Cassandra.
Cassandra en tant que source
Pour copier des données de Cassandra, définissez Source comme type source de l’activité de copie. Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur : CassandraSource | Oui |
| query | Utilise la requête personnalisée pour lire des données. Requête SQL-92 ou requête CQL. Reportez-vous à référence CQL. Lorsque vous utilisez la requête SQL, indiquez keyspace name.table name pour représenter la table que vous souhaitez interroger. |
Non (si « tableName » et « keyspace » sont spécifiés dans le jeu de données). |
| Niveau de cohérence | Le niveau de cohérence spécifie le nombre de réplicas devant répondre à une demande de lecture avant de renvoyer des données à l’application cliente. Cassandra vérifie le nombre de réplicas spécifié pour permettre aux données de répondre à la demande de lecture. Reportez-vous à Configuring data consistency (Configuration de la cohérence des données) pour plus d’informations. Les valeurs autorisées sont les suivantes : ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM et LOCAL_ONE. |
Non (la valeur par défaut est ONE) |
Exemple :
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mappage de type de données pour Cassandra
Lors de la copie de données à partir de Cassandra, les mappages suivants sont utilisés entre les types de données Cassandra et les types de données intermédiaires utilisés en interne dans le service. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, voir Mappages de schémas et de types de données.
| Type de données Cassandra | Type de données de service intermédiaire |
|---|---|
| ASCII | String |
| bigint | Int64 |
| BLOB | Byte[] |
| BOOLEAN | Boolean |
| DECIMAL | Decimal |
| DOUBLE | Double |
| FLOAT | Unique |
| INET | String |
| INT | Int32 |
| TEXT | String |
| TIMESTAMP | DateTime |
| TIMEUUID | Guid |
| UUID | Guid |
| VARCHAR | String |
| VARINT | Decimal |
Notes
Pour les types de collections (mappages, ensembles, listes, etc.), reportez-vous à la section Work with Cassandra collection types using virtual table (Travailler avec les types de collections Cassandra à l’aide d’une table virtuelle) .
Les types définis par l’utilisateur ne sont pas pris en charge.
La longueur des colonnes binaires et des colonnes de chaîne ne peut pas être supérieure à 4 000.
Travailler avec des collections à l’aide d’une table virtuelle
Le service utilise un pilote ODBC intégré pour assurer la connexion à votre base de données Cassandra et copier des données à partir de cette dernière. Pour les types de collection, notamment les cartes, ensembles et listes, le pilote renormalise les données dans des tables virtuelles correspondantes. En particulier, si une table contient des colonnes de n’importe quelle collection, le pilote génère les tables virtuelles suivantes :
- Une table de base, qui contient les mêmes données que la table réelle, à l’exception des colonnes de collection. La table de base utilise le même nom que la table réelle qu’elle représente.
- Une table virtuelle pour chaque colonne de collection, qui étend les données imbriquées. Le nom des tables virtuelles qui représentent des collections est composé du nom de la table réelle, du séparateur « vt » et du nom de la colonne.
Les tables virtuelles font référence aux données présentées dans la table réelle, de manière à permettre au pilote d’accéder aux données dénormalisées. Consultez la section Exemple pour plus d’informations. Vous pouvez accéder au contenu des collections Cassandra en interrogeant et en joignant les tables virtuelles.
Exemple
Par exemple, « ExampleTable » ci-après est une table de base de données Cassandra qui contient une colonne de clé primaire entière nommée « pk_int », une colonne de texte nommée value, une colonne de liste, une colonne de mappage et une colonne de jeu (nommée « StringSet »).
| pk_int | Valeur | List | Mappage | StringSet |
|---|---|---|---|---|
| 1 | « exemple de valeur 1 » | [« 1 », « 2 », « 3 »] | {« S1 » : « a », « S2 » : « b »} | {« A », « B », « C »} |
| 3 | « exemple de valeur 3 » | [« 100 », « 101 », « 102 », « 105 »] | {« S1 » : « t »} | {« A », « E »} |
Le pilote génère plusieurs tables virtuelles pour représenter cette table. Les colonnes de clés étrangères dans les tables virtuelles font référence aux colonnes de clés primaires dans la table réelle, et indiquent à quelles lignes de la table réelle les lignes de la table virtuelle correspondent.
La première table virtuelle est la table de base nommée « ExampleTable » affichée dans le tableau suivant :
| pk_int | Valeur |
|---|---|
| 1 | « exemple de valeur 1 » |
| 3 | « exemple de valeur 3 » |
La table de base contient les mêmes données que la table de base de données d’origine, à l’exception des collections, qui sont omises de cette table et développées dans d’autres tables virtuelles.
Les tableaux suivants montrent les tables virtuelles qui renormalisent les données des colonnes Liste, Mappage et StringSet. Les colonnes portant des noms se terminant par « _index » ou « _key » indiquent la position des données dans la liste ou le mappage d’origine. Les colonnes portant des noms se terminant par « _value » contiennent les données étendues de la collection.
Table « ExampleTable_vt_List » :
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Table « ExampleTable_vt_Map » :
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | Un |
| 1 | S2 | b |
| 3 | S1 | t |
Table « ExampleTable_vt_StringSet » :
| pk_int | StringSet_value |
|---|---|
| 1 | Un |
| 1 | B |
| 1 | C |
| 3 | Un |
| 3 | E |
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Contenu connexe
Pour obtenir une liste des magasins de données pris en charge comme sources et récepteurs par l’activité de copie, consultez la section sur les magasins de données pris en charge.