Mode de débogage du mappage de flux de données
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Vue d’ensemble
Le mode de débogage du flux de données de mappage d’Azure Data Factory et de Synapse Analytics permet de suivre de manière interactive la transformation de la forme des données à mesure que vous générez et déboguez vos flux de données. La session de débogage peut être utilisée à la fois lors des sessions de conception des flux de données et lors de l'exécution du débogage du pipeline des flux de données. Pour activer le mode débogage, utilisez le bouton Débogage du flux de données dans la barre supérieure du canevas de flux de données ou du canevas de pipeline quand vous avez des activités de flux de données.

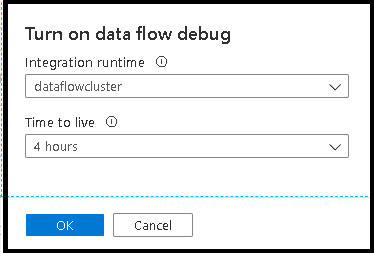
Une fois le curseur activé, vous serez invité à sélectionner la configuration de runtime d'intégration que vous souhaitez utiliser. Si vous choisissez AutoResolveIntegrationRuntime, un cluster comprenant 8 cœurs de calcul général avec une durée de vie par défaut de 60 minutes est lancé. Si vous souhaitez autoriser un plus grand nombre d’équipes inactives avant l’expiration de votre session, vous pouvez choisir un paramètre TTL plus élevé. Pour plus d’informations sur les runtimes d’intégration de flux de données, consultez Performances de runtime d'intégration.
Lorsque le mode débogage est activé, vous allez générer de manière interactive votre flux de données avec un cluster Spark actif. La session se ferme une fois que vous avez désactivé le débogage. Prenez connaissance des frais horaires engendrés par Data Factory pendant la durée d’activation de la session de débogage.
Dans la plupart des cas, nous vous recommandons de créer vos flux de données en mode débogage pour que vous puissiez valider votre logique métier et afficher vos transformations de données avant de publier votre travail. Utilisez le bouton « Débogage » sur le panneau du pipeline pour tester votre flux de données dans un pipeline.
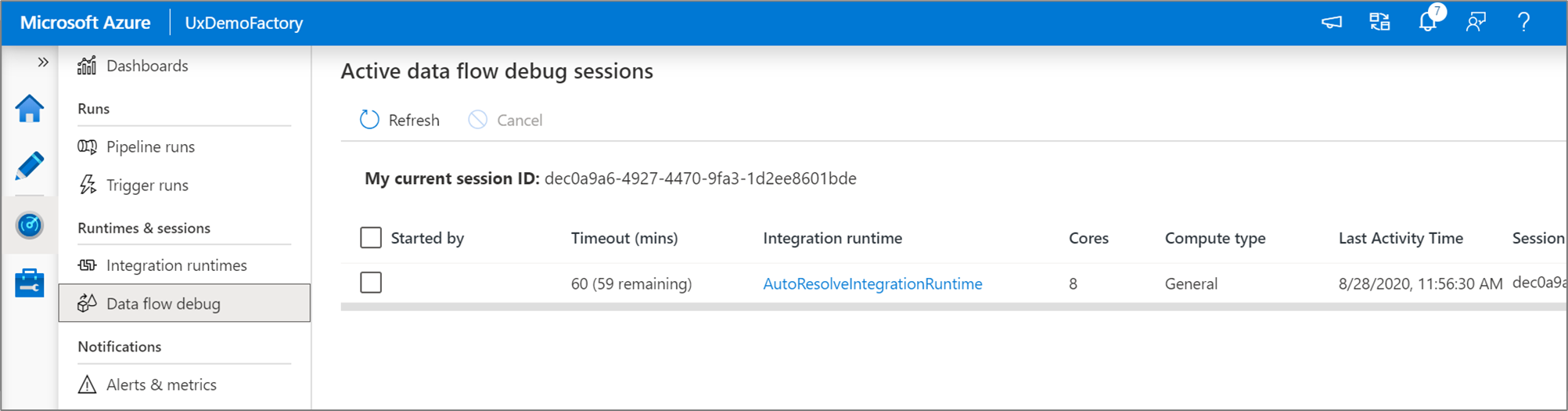
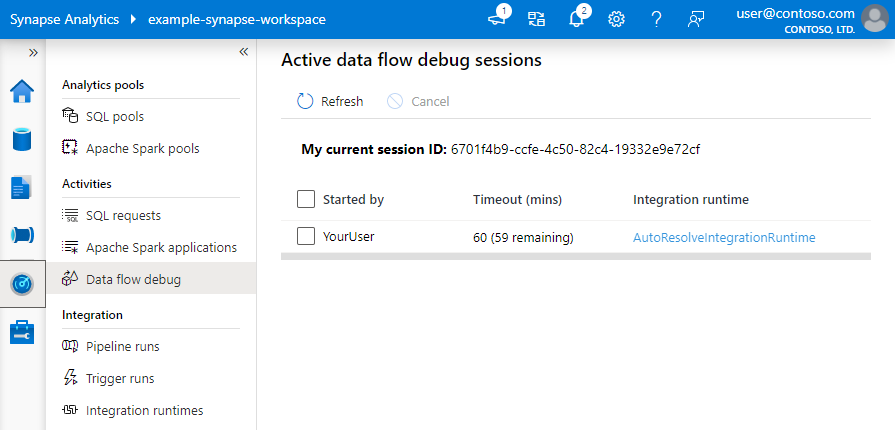
Notes
Chaque session de débogage qu’un utilisateur démarre à partir de l’interface utilisateur de son navigateur est une nouvelle session avec son propre cluster Spark. Vous pouvez utiliser la vue d'analyse des sessions de débogage présentée dans les images précédentes pour afficher et gérer les sessions de débogage. Vous êtes facturé pour chaque heure d’exécution de chaque session de débogage, y compris la durée de vie.
Ce clip vidéo présente des conseils, des astuces et des bonnes pratiques pour le mode débogage du flux de données.
État du cluster
L’indicateur d’état du cluster en haut de l’aire de conception devient vert quand le cluster est prêt pour le débogage. Si votre cluster est déjà chaud, l'indicateur vert apparaît presque instantanément. Si votre cluster n'était pas déjà en cours d'exécution lorsque vous êtes entré dans le mode débogage, le cluster Spark effectue un démarrage à froid. L'indicateur tourne jusqu'à ce que l'environnement soit prêt pour le débogage interactif.
Lorsque vous avez terminé votre débogage, désactivez le commutateur de débogage afin que votre cluster Spark puisse se terminer et que vous ne soyez plus facturé pour l'activité de débogage.
Paramètres de débogage
Une fois que vous activez le mode débogage, vous pouvez modifier la façon dont un flux de données affiche un aperçu des données. Les paramètres de débogage peuvent être modifiés en cliquant sur « Paramètres de débogage » sur la barre d’outils du canevas Flux de données. Vous pouvez sélectionner la limite de ligne ou la source de fichier à utiliser pour chacune de vos transformations Source ici. Les limites de lignes de ce paramètre s’appliquent uniquement à la session de débogage actuelle. Vous pouvez aussi sélectionner le service lié intermédiaire à utiliser pour une source Azure Synapse Analytics.
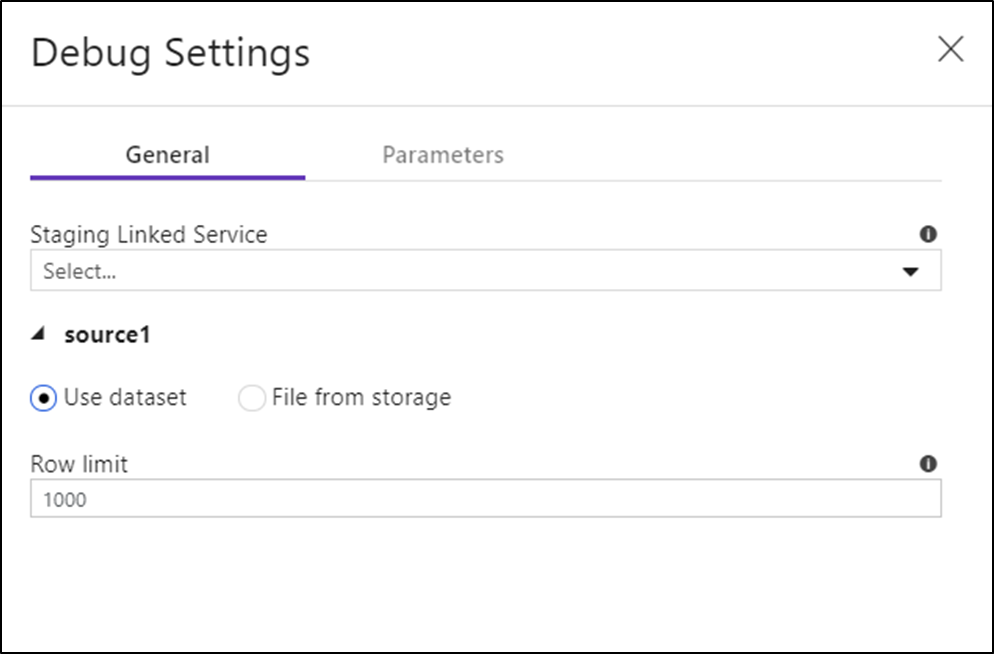
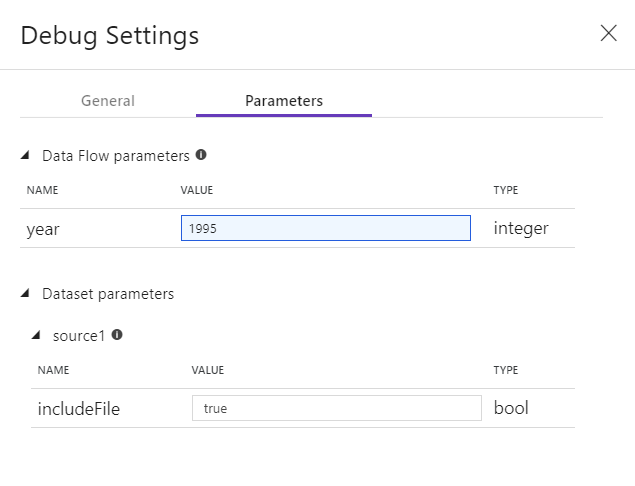
Si vous avez des paramètres dans votre flux de données ou dans l’un de ses jeux de données référencés, vous pouvez spécifier les valeurs à utiliser pendant le débogage en sélectionnant l'onglet Paramètres.
Utilisez les paramètres d'échantillonnage ici pour pointer vers des fichiers ou des tables de données échantillons afin de ne pas avoir à modifier vos ensembles de données sources. À l’aide d’un exemple de fichier ou de table disponible ici, vous pouvez conserver les mêmes paramètres de logique et de propriété dans votre flux de données, sans quitter le sous-ensemble de données.
Le runtime d’intégration par défaut utilisé pour le mode débogage dans les flux de données est un petit nœud Worker à 4 cœurs avec un nœud de pilote unique à 4 cœurs. Ceci fonctionne correctement avec des échantillons de données réduits quand vous testez la logique de votre flux de données. Si vous développez les limites de lignes dans vos paramètres de débogage pendant la prévisualisation des données ou si vous définissez un nombre plus élevé de lignes échantillonnées dans votre source pendant le débogage du pipeline, vous pouvez alors envisager de définir un environnement Compute plus important dans un nouvel Azure Integration Runtime. Vous pouvez ensuite redémarrer votre session de débogage et utiliser l’environnement de calcul agrandi.
Aperçu des données
Lorsque le débogage est activé, l'onglet Prévisualisation des données s'allume dans le panneau inférieur. Si le mode débogage n'est pas activé, Data Flow n'affiche que les métadonnées actuelles en entrée et en sortie de chacune de vos transformations dans l'onglet Inspecter. L’aperçu des données interroge uniquement le nombre de lignes que vous avez défini comme limite dans vos paramètres de débogage. Sélectionnez Actualiser pour mettre à jour la prévisualisation des données en fonction de vos transformations actuelles. Si vos données sources ont été modifiées, sélectionnez l'option Actualiser > Rechercher les données de la source.
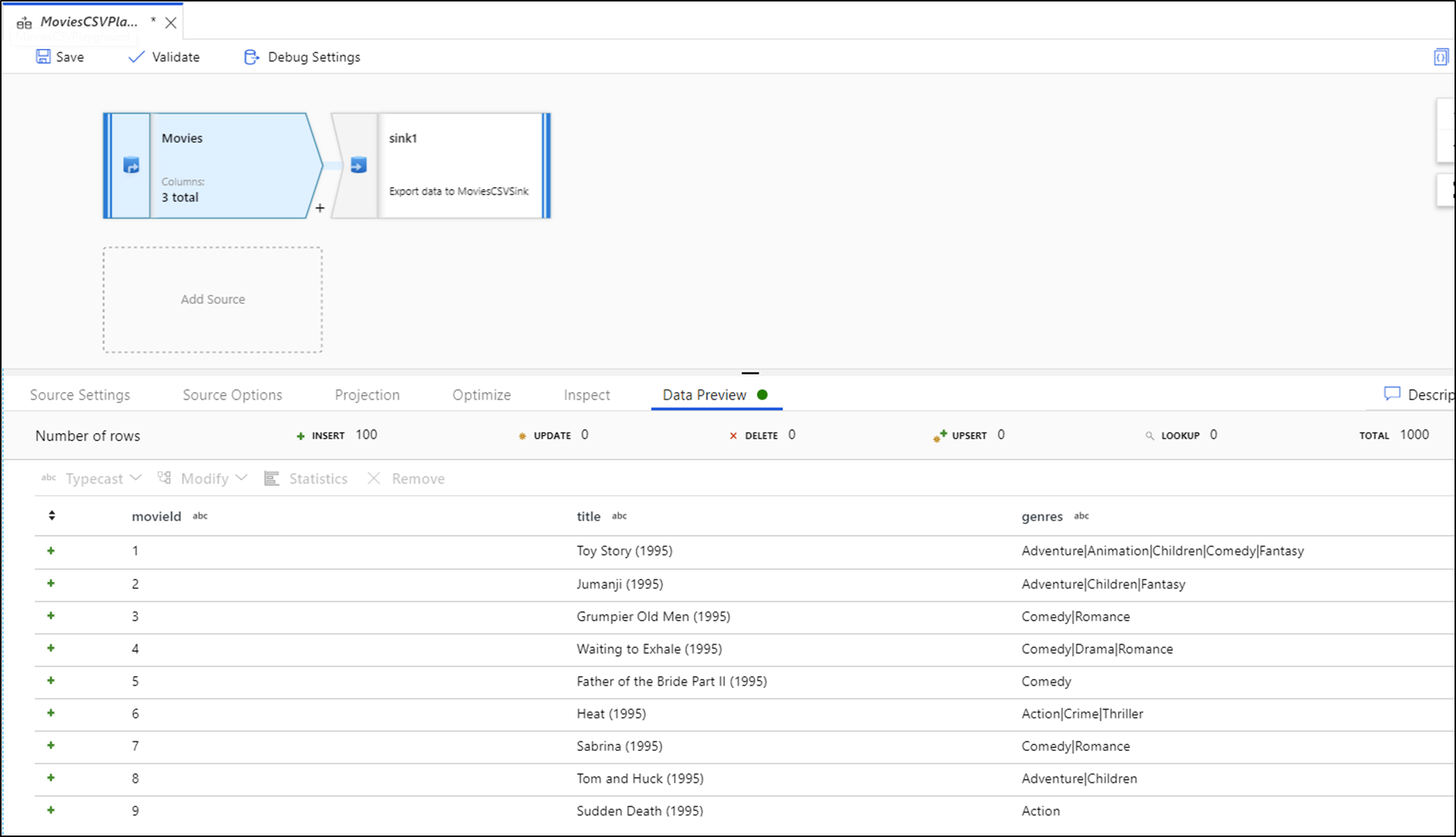
Vous pouvez trier les colonnes dans l’aperçu des données et réorganiser les colonnes par glisser-déplacer. En outre, un bouton d'exportation situé dans le coin supérieur du panneau de prévisualisation des données permet d'exporter les données de prévisualisation vers un fichier CSV pour une exploration des données hors ligne. Vous pouvez utiliser cette fonctionnalité pour exporter jusqu’à 1 000 lignes de données d’aperçu.
Notes
Les sources de fichier limitent uniquement les lignes que vous voyez et non celles qui sont en cours de lecture. Pour les jeux de données très volumineux, il est recommandé de prendre une petite partie de ce fichier et de l’utiliser pour votre test. Vous pouvez sélectionner un fichier temporaire dans les paramètres de débogage pour chaque source correspondant à un type de jeu de données de fichier.
En mode Débogage dans Data Flow, les données ne sont pas écrites dans la transformation de récepteur. Le but d’une session de débogage est de servir d’atelier de test pour vos transformations. Les récepteurs ne sont pas nécessaires pendant le débogage et sont ignorés dans votre flux de données. Si vous souhaitez tester l’écriture des données dans votre récepteur, exécutez le Data Flow à partir d’un pipeline et utilisez l’exécution Débogage à partir d’un pipeline.
L’aperçu des données est un instantané de vos données transformées qui utilise les limites du nombre de lignes et l’échantillonnage des données provenant des trames de données dans la mémoire Spark. Par conséquent, les pilotes de récepteur ne sont pas utilisés ou testés dans ce scénario.
Remarque
Les données en préversion affichent l’heure selon les paramètres régionaux du navigateur.
Test des conditions de jointure
Lors du test unitaire des transformations de jointure, de recherche ou Exists, veillez à utiliser un petit ensemble de données connues pour votre test. Vous pouvez utiliser l'option Paramètres de débogage décrite précédemment pour définir un fichier temporaire à utiliser pour vos tests. Cette opération est nécessaire, car lors de la limitation ou de l'échantillonnage des lignes d'un grand ensemble de données, il est impossible de prévoir quelles lignes et quelles clés seront lues dans le flux pour les tests. Le résultat est non déterministe, ce qui signifie que vos conditions de jointure peuvent échouer.
Actions rapides
Une fois que vous voyez l’aperçu des données, vous pouvez générer une transformation rapide pour convertir en typecast, supprimer ou modifier une colonne. Sélectionnez l'en-tête de la colonne, puis l'une des options de la barre d'outils de prévisualisation des données.
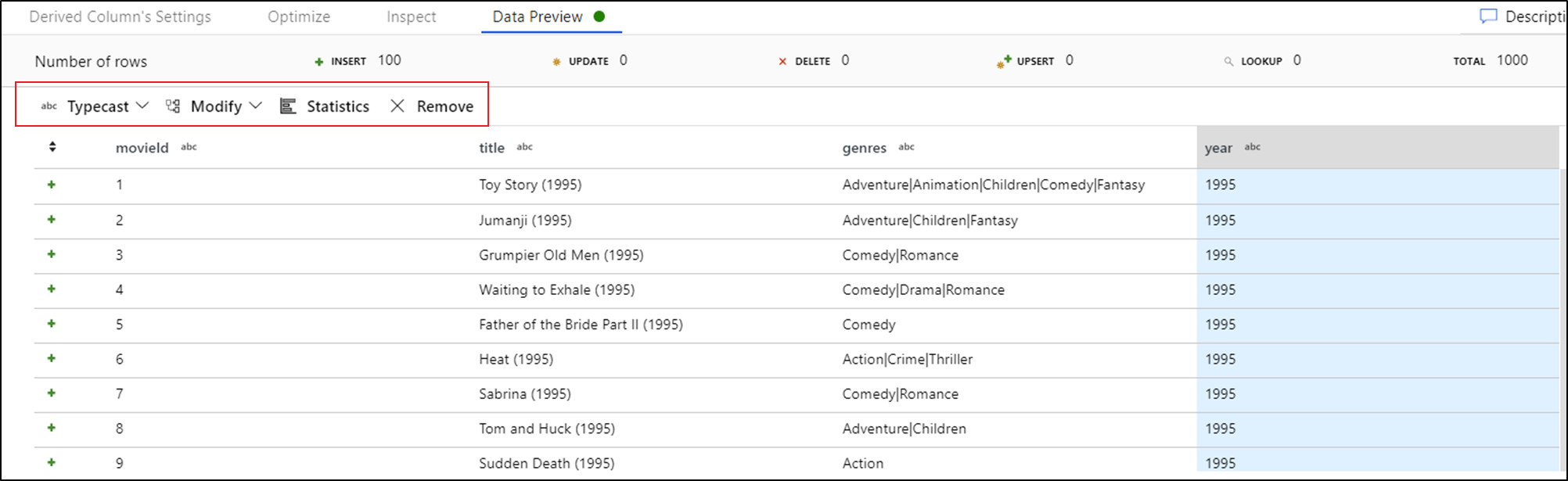
Une fois que vous avez sélectionné une modification, l’aperçu des données est immédiatement actualisé. Sélectionnez Confirmer dans le coin supérieur droit pour générer une nouvelle transformation.
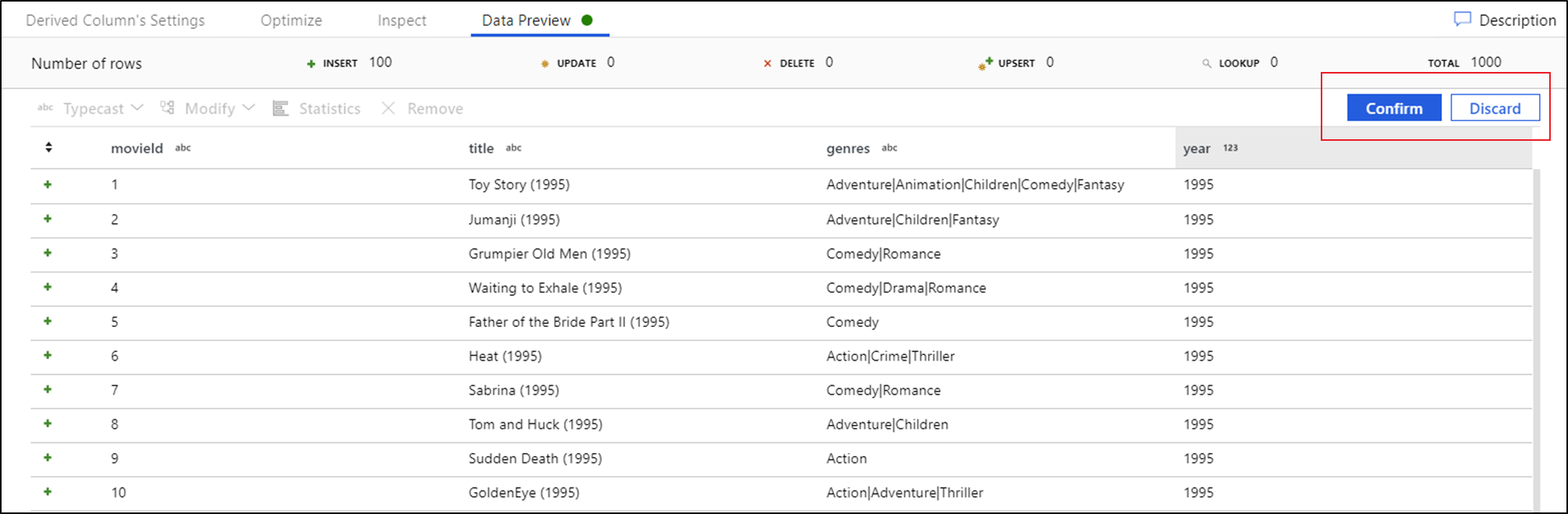
Typecast et Modifier génèrent une transformation de colonne dérivée et Supprimer génère une transformation Select.
Notes
Si vous modifiez votre flux de données, vous devez extraire à nouveau l’aperçu des données avant d’ajouter une transformation rapide.
Profilage des données
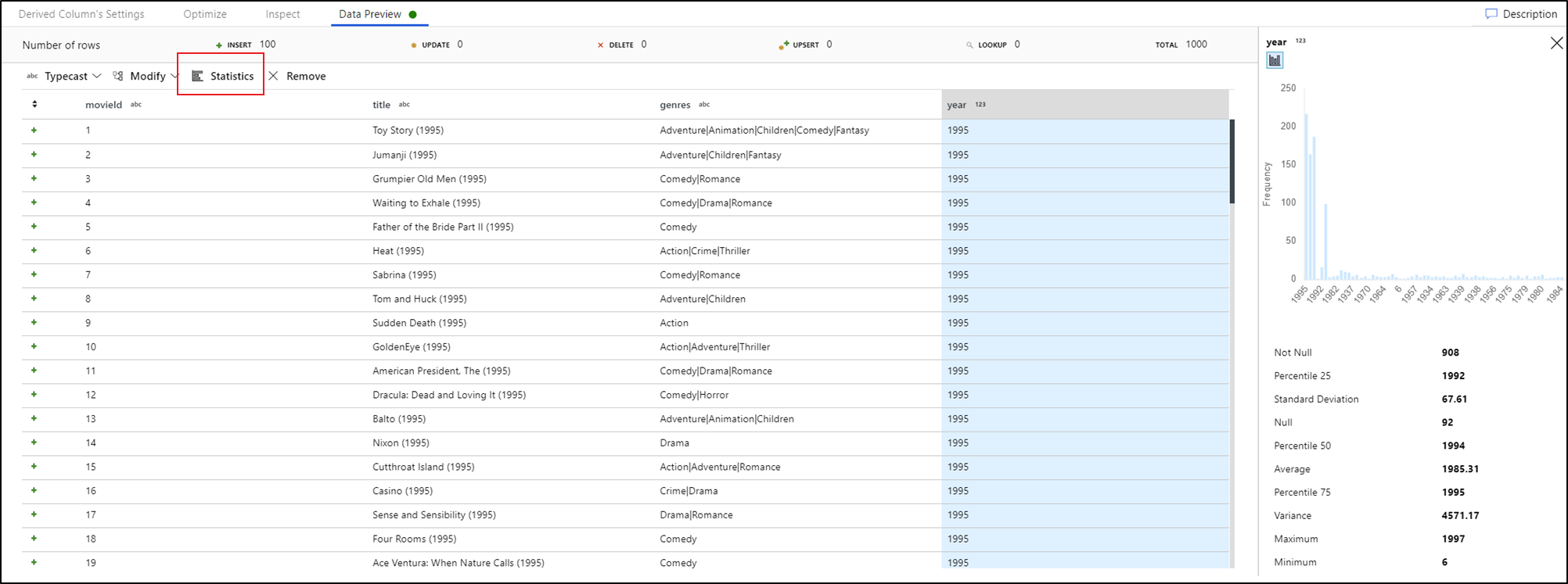
En sélectionnant une colonne dans l'onglet Prévisualisation des données et en cliquant sur Statistiques dans la barre d'outils de prévisualisation des données, un graphique s'affiche à l'extrême droite de votre grille de données, avec des statistiques détaillées sur chaque champ. Le service détermine, sur la base de l'échantillonnage des données, le type de graphique à afficher. Les champs à cardinalité élevée affichent par défaut des diagrammes NULL/NOT NULL, tandis que les données catégorielles et numériques à cardinalité faible affichent des graphiques à barres montrant la fréquence des valeurs des données. Vous pouvez également voir la longueur max./len. des champs de chaîne, les valeurs min./max. des champs numériques, l'écart-type, les percentiles, les effectifs et la moyenne.
Contenu connexe
- Une fois que vous avez terminé la création et le débogage de votre flux de données, exécutez-le depuis un pipeline.
- Lors du test de votre pipeline avec un flux de données, utilisez l’option Exécution du débogage du pipeline.