Choisir la configuration de runtime d’intégration appropriée pour votre scénario
Le runtime d’intégration est une partie importante de l’infrastructure de la solution d’intégration de données fournie par Azure Data Factory. Ceci vous oblige à réfléchir avec attention à la façon de s’adapter à la structure du réseau et à la source de données existantes au début de la conception de la solution ainsi que de prendre en compte les performances, la sécurité et le coût.
Comparaison des différents types de runtime d’intégration
Dans Azure Data Factory, nous avons trois types de runtimes d’intégration : le runtime d’intégration Azure, le runtime d’intégration auto-hébergé et le runtime d’intégration Azure-SSIS. Pour le runtime d’intégration Azure, vous pouvez également activer un réseau virtuel, ce qui rend son architecture différente de celle du runtime d’intégration Azure global.
Ce tableau répertorie les différences dans certains aspects de tous les runtimes d’intégration. Vous pouvez choisir celui approprié en fonction de vos besoins réels. Pour le runtime d’intégration Azure-SSIS, vous pouvez en savoir plus dans l’article Créer un runtime d’intégration Azure-SSIS.
| Fonctionnalité | Runtime d’intégration Azure | Runtime d’intégration Azure avec un réseau virtuel managé | Runtime d’intégration auto-hébergé |
|---|---|---|---|
| Capacité de calcul managée | O | O | N |
| Mise à l’échelle automatique | Y | Y* | N |
| Dataflow | O | O | N |
| Accès aux données locales | N | O** | O |
| Liaison privée/Point de terminaison privé | N | O*** | O |
| Composant/pilote personnalisé | N | N | O |
* Quand la durée de vie (TTL) est activée, la taille de calcul du runtime d’intégration est réservée en fonction de la configuration et ne peut pas être mise à l’échelle automatiquement.
** Les environnements locaux doivent être connectés à Azure via ExpressRoute ou un VPN. Les composants et les pilotes personnalisés ne sont pas pris en charge.
*** Les points de terminaison privés sont gérés par le service Azure Data Factory.
Il est important de choisir un type de runtime d’intégration approprié. Non seulement il doit être adapté à votre architecture existante et à vos exigences en matière d’intégration de données, mais vous devez aussi réfléchir à la façon de répondre aux besoins croissants de l’entreprise et aux augmentations futures de la charge de travail. Il n’y a cependant pas d’approche universelle. La considération suivante peut vous aider à prendre la décision :
Quels sont les emplacements du runtime d’intégration et du magasin de données ?
L’emplacement du runtime d’intégration définit l’emplacement de sa capacité de calcul back-end, et l’emplacement où le déplacement des données, la répartition des activités et la transformation des données sont effectués. Pour obtenir de meilleures performances et une meilleure efficacité de la transmission, le runtime d’intégration doit être plus proche de la source de données ou du récepteur.- Le runtime d’intégration Azure détecte automatiquement l’emplacement le plus approprié en fonction de certaines règles (également appelées « résolution automatique »). Consultez plus d’informations ici : Emplacement d’Azure Integration Runtime.
- Le runtime d’intégration Azure avec un réseau virtuel managé a la même région que votre fabrique de données. Il ne peut pas être résolu automatiquement comme le runtime d’intégration Azure.
- Le runtime d’intégration auto-hébergé se trouve dans la région de vos machines locales ou de vos machines virtuelles Azure.
Le magasin de données est-il accessible publiquement ?
Si le magasin de données est accessible publiquement, la différence entre les différents types de runtimes d’intégration n’est pas grande. Si le magasin se trouve derrière un pare-feu ou dans un réseau privé comme un réseau local ou virtuel, les meilleurs choix sont le runtime d’intégration Azure avec un réseau virtuel managé ou le runtime d’intégration auto-hébergé.- Certaines configurations supplémentaires sont nécessaires, comme le service Private Link Service et Load Balancer lors de l’utilisation du runtime d’intégration Azure avec un réseau virtuel managé pour accéder à un magasin de données derrière un pare-feu ou dans un réseau privé. Pour un exemple, vous pouvez vous reporter à Tutoriel : Accéder à un serveur SQL local à partir d’un réseau virtuel managé par Data Factory en utilisant un point de terminaison privé. Si le magasin de données se trouve dans un environnement local, celui-ci doit être connecté à Azure via ExpressRoute ou un S2S VPN.
- Le runtime d’intégration auto-hébergé est plus flexible et ne nécessite pas de paramètres supplémentaires, ni Express Route ni un VPN. Vous devez cependant fournir et maintenir la machine par vous-même.
- Vous pouvez aussi ajouter les adresses IP publiques du runtime d’intégration Azure à la liste verte de votre pare-feu et lui permettre d’accéder au magasin de données, mais ce n’est pas une solution souhaitable dans des environnements de production hautement sécurisés.
De quel niveau de sécurité avez-vous besoin lors de la transmission des données ?
Si vous devez traiter des données hautement confidentielles, vous voulez vous défendre par exemple contre des attaques de l’intercepteur lors de la transmission des données. Vous pouvez ensuite choisir d’utiliser un point de terminaison privé et Private Link pour garantir la sécurité des données.- Vous pouvez créer des points de terminaison privés managés pour vos magasins de données quand vous utilisez le runtime d’intégration Azure avec un réseau virtuel managé. Les points de terminaison privés sont maintenus par le service Azure Data Factory au sein du réseau virtuel managé.
- Vous pouvez aussi créer des points de terminaison privés dans votre réseau virtuel, et le runtime d’intégration auto-hébergé peut les utiliser pour accéder aux magasins de données.
- Le runtime d’intégration Azure ne prend pas en charge les points de terminaison privés ni Private Link.
Quel niveau de maintenance pouvez-vous fournir ?
La maintenance de l’infrastructure, des serveurs et de l’équipement est une des tâches importantes du département informatique d’une entreprise. Elle demande généralement beaucoup de temps et de travail.- Vous n’avez pas besoin de vous soucier de la maintenance, comme la mise à jour, les correctifs et la version du runtime d’intégration Azure et du runtime d’intégration Azure avec un réseau virtuel managé. Le service Azure Data Factory s’occupe de tout le travail de maintenance.
- Comme le runtime d’intégration auto-hébergé est installé sur des machines des clients, la maintenance doit être prise en charge par les utilisateurs finaux. Vous pouvez cependant activer la mise à jour automatique pour obtenir automatiquement la dernière version du runtime d’intégration auto-hébergé chaque fois qu’il y a une mise à jour. Pour savoir comment activer la mise à jour automatique et gérer le contrôle de version du runtime d’intégration auto-hébergé, consultez l’article Mise à jour automatique et notification d’expiration du runtime d’intégration auto-hébergé. Nous fournissons également un outil de diagnostic pour le runtime d’intégration auto-hébergé permettant de vérifier l’intégrité dans le cas de certains problèmes courants. Pour en savoir plus sur l’outil de diagnostic, consultez l’article Outil de diagnostic du runtime d’intégration auto-hébergé. Nous recommandons aussi d’utiliser spécifiquement Azure Monitor et Azure Log Analytics pour collecter ces données et centraliser la supervision pour vos runtimes d’intégration auto-hébergés. Pour plus d’informations et des instructions sur la configuration de ces services, consultez l’article Configurer le runtime d’intégration auto-hébergé pour la collecte Log Analytics.
Quelles sont vos exigences en matière de concurrence ?
Lors du traitement de données à grande échelle, comme la migration de données à grande échelle, nous espérons améliorer autant que possible l’efficacité et la rapidité des traitements. La concurrence est souvent une exigence majeure pour l’intégration des données.- Le runtime d’intégration Azure offre la meilleure prise en charge de la concurrence parmi tous les types de runtime d’intégration. L’unité d’intégration de données (DIU, Data Integration Unit) est l’unité de capacité à exécuter sur Azure Data Factory. Vous pouvez sélectionner le nombre souhaité de DIU, par exemple pour l’activité Copy. Dans l’étendue des DIU, vous pouvez exécuter plusieurs activités en même temps. Pour différents groupes de régions, nous aurons différentes limites maximales. Découvrez les détails de ces limites dans l’article Limites de Data Factory.
- Le runtime d’intégration Azure avec un réseau virtuel managé a un mécanisme similaire au runtime d’intégration Azure, mais en raison de certaines contraintes d’architecture, la concurrence qu’il peut prendre en charge est inférieure à celle du runtime d’intégration Azure.
- Les activités concurrentes que le runtime d’intégration auto-hébergé peut exécuter dépendent de la taille de la machine et de la taille du cluster. Vous pouvez choisir une machine plus grande ou utiliser davantage de nœuds d’intégration auto-hébergés dans le cluster si vous avez besoin d’une concurrence accrue.
Avez-vous besoin de fonctionnalités spécifiques ?
Il y a quelques différences fonctionnelles entre les types de runtimes d’intégration.- Les flux de données sont pris en charge par le runtime d’intégration Azure et le runtime d’intégration Azure avec un réseau virtuel managé. Cependant, vous ne pouvez pas exécuter de flux de données en utilisant le runtime d’intégration auto-hébergé.
- Si vous devez installer des composants personnalisés, comme des pilotes ODBC, une machine virtuelle Java ou un certificat SQL Server, le runtime d’intégration auto-hébergé est votre seule option. Les composants personnalisés ne sont pas pris en charge par le runtime d’intégration Azure ni par le runtime d’intégration Azure avec un réseau virtuel managé.
Architecture pour le runtime d’intégration
En fonction des caractéristiques de chaque runtime d’intégration, des architectures différentes sont nécessaires pour répondre aux besoins métier de l’intégration des données. Voici quelques architectures classiques qui peuvent être utilisées comme référence.
Runtime d’intégration Azure
Le runtime d’intégration Azure est une capacité de calcul entièrement managée et mise à l’échelle automatiquement, que vous pouvez utiliser pour déplacer des données depuis des sources de données Azure ou non-Azure.
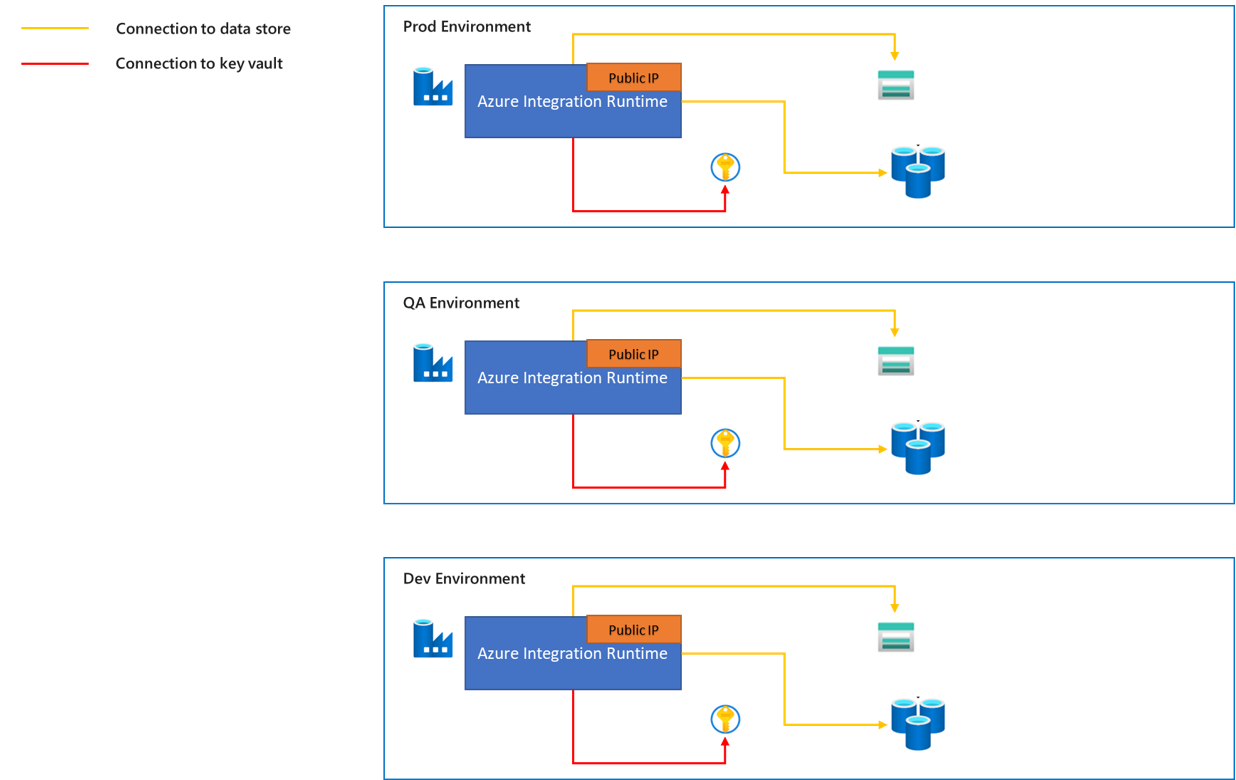
- Le trafic provenant du runtime d’intégration Azure vers les magasins de données s’effectue via un réseau public.
- Nous fournissons une plage d’adresses IP publiques statiques pour le runtime d’intégration Azure, et ces adresses IP peuvent être ajoutées à la liste verte du pare-feu du magasin de données cible. Pour en savoir plus sur la façon d’obtenir les adresses IP publiques du runtime d’intégration Azure, consultez l’article Adresses IP d’Azure Integration Runtime.
- Le runtime d’intégration Azure peut être résolu automatiquement en fonction de la région de la source de données et du récepteur de données. Vous pouvez aussi choisir une région spécifique. Nous vous recommandons de choisir la région la plus proche de votre source ou de votre récepteur de données, car ceci peut offrir de meilleures performances d’exécution. Pour en savoir plus sur les considérations relatives aux performances, consultez l’article Résoudre les problèmes de l’activité Copy sur Azure IR.
Runtime d’intégration Azure avec un réseau virtuel managé
Si vous utilisez le runtime d’intégration Azure avec un réseau virtuel managé, vous devez utiliser des points de terminaison privés managés pour connecter vos sources de données, afin de garantir la sécurité des données pendant la transmission. Avec certains paramètres supplémentaires impliquant les services Private Link et Load Balancer, les points de terminaison privés managés peuvent également être utilisés pour accéder à des sources de données locales.
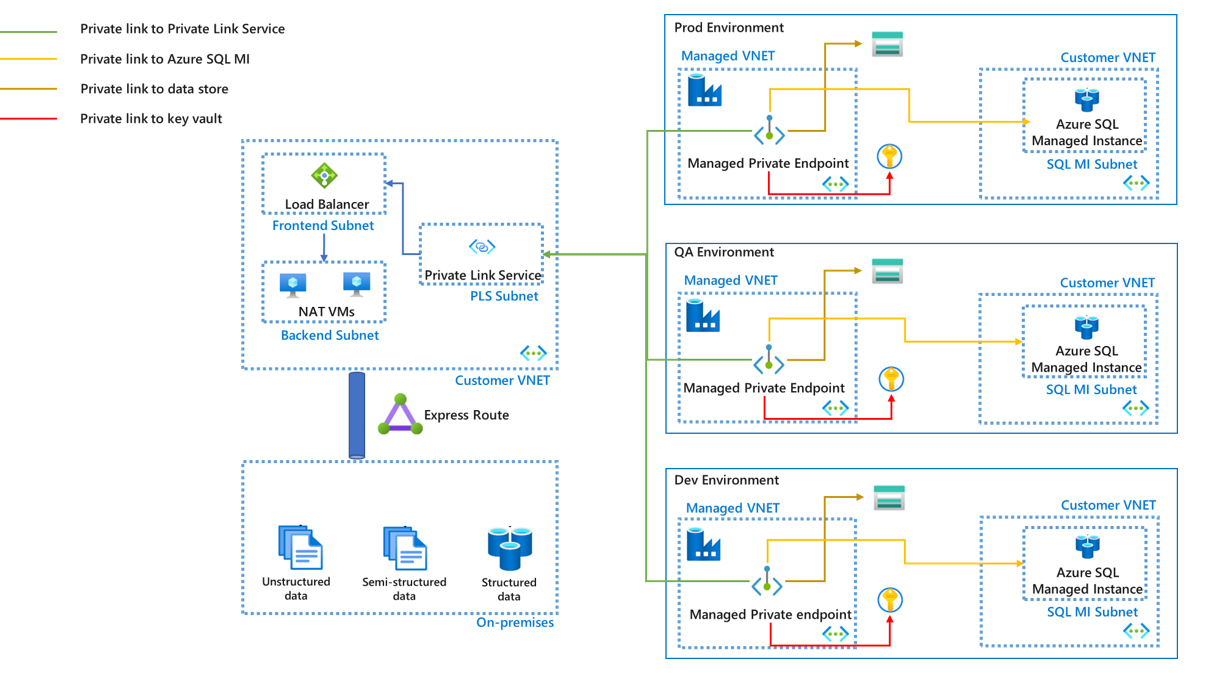
- Un point de terminaison privé managé ne peut pas être réutilisé dans différents environnements. Vous devez créer un ensemble de points de terminaison privés managés pour chaque environnement. Pour connaître toutes les sources de données prises en charge par les points de terminaison privés managés, reportez-vous à l’article Sources de données et services pris en charge.
- Vous pouvez aussi utiliser des points de terminaison privés managés pour les connexions aux ressources de calcul externes que vous voulez orchestrer, comme Azure Databricks et Azure Functions. Pour voir la liste complète des ressources de calcul externes prises en charge, reportez-vous à l’article Sources de données et services pris en charge.
- Le réseau virtuel managé est géré par le service Azure Data Factory. Le peering de réseaux virtuels n’est pas pris en charge entre un réseau virtuel managé et un réseau virtuel d’un client.
- Les clients ne peuvent pas modifier directement des configurations comme la règle de groupe de sécurité réseau sur un réseau virtuel managé.
- Si une propriété d’un point de terminaison privé managé est différente d’un environnement à l’autre, vous pouvez la remplacer en paramétrant cette propriété et en fournissant la valeur correspondante lors du déploiement. Découvrez plus d’informations dans l’article Bonnes pratiques pour CI/CD.
Runtime d’intégration auto-hébergé
Pour empêcher les données de différents environnements d’interférer entre elles et garantir la sécurité de l’environnement de production, nous devons créer un runtime d’intégration auto-hébergé correspondant pour chaque environnement. Ceci garantit une isolation suffisante entre les différents environnements.
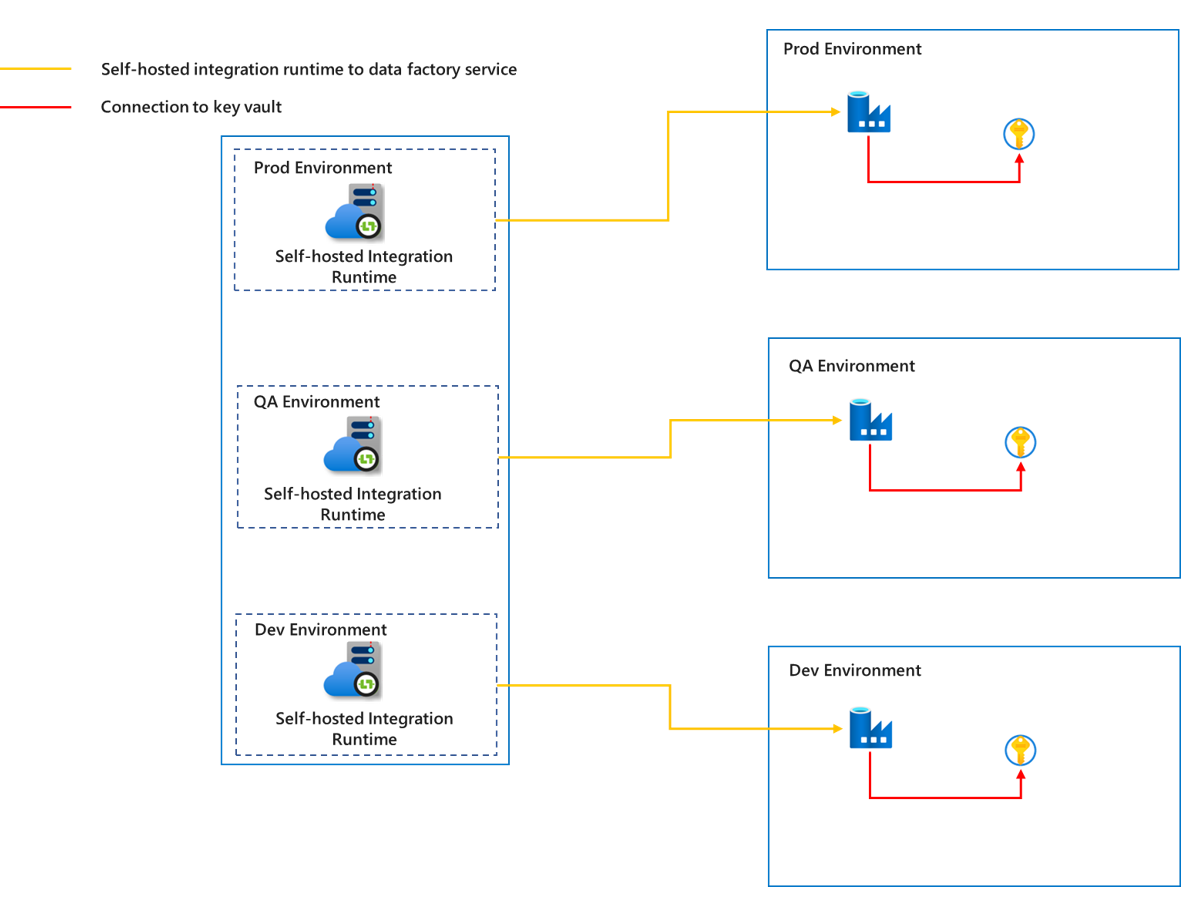
Comme le runtime d’intégration auto-hébergé s’exécute sur une machine gérée par le client, afin de réduire autant que possible les coûts, la maintenance et le travail lié à la mise à niveau, nous pouvons utiliser les fonctions partagées du runtime d’intégration auto-hébergé pour différents projets dans le même environnement. Pour plus d’informations sur le partage du runtime d’intégration auto-hébergé, reportez-vous à l’article Créer un runtime d’intégration auto-hébergé partagé dans Azure Data Factory. Dans le même temps, pour sécuriser davantage les données pendant la transmission, nous pouvons choisir d’utiliser une liaison privée pour connecter les sources de données et le coffre de clés, et connecter la communication entre le runtime d’intégration auto-hébergé et le service Azure Data Factory.
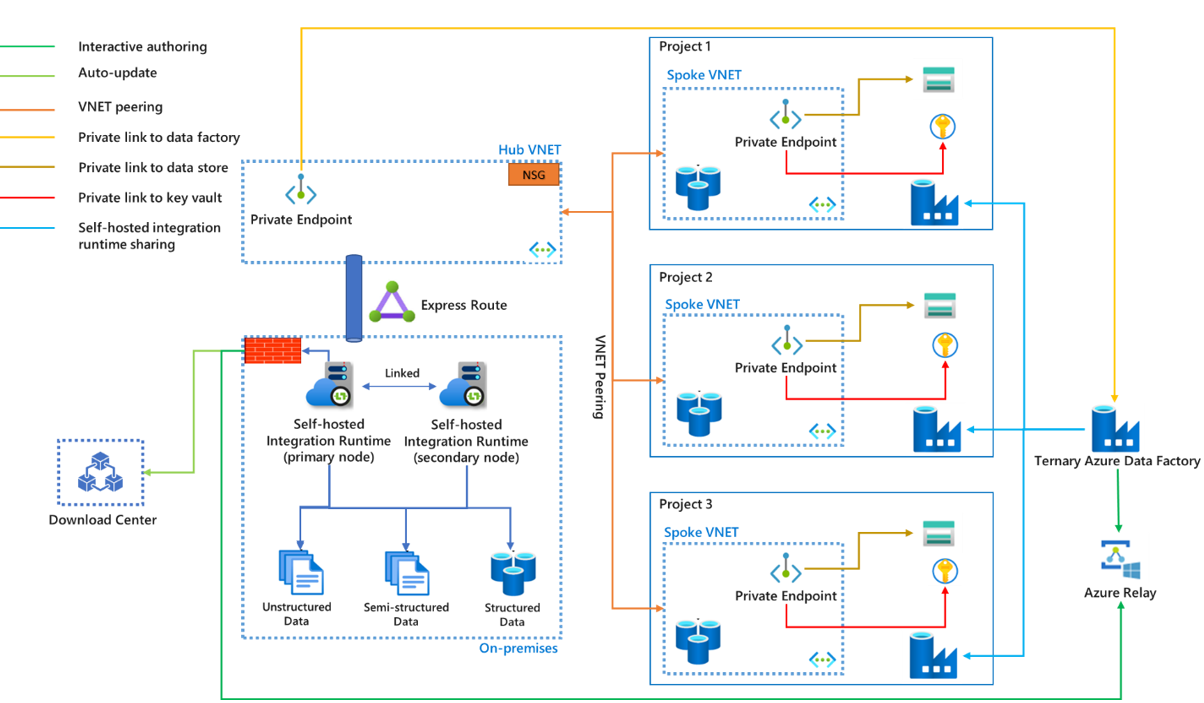
- Express Route n’est pas obligatoire. Sans Express Route, les données n’atteignent pas le récepteur via des réseaux privés comme un réseau virtuel ou une liaison privée, mais bien via le réseau public.
- Si le réseau local est connecté au réseau virtuel Azure via ExpressRoute ou un VPN, le runtime d’intégration auto-hébergé peut être installé sur des machines virtuelles dans un réseau virtuel de hub.
- L’architecture de réseau virtuel en étoile peut être utilisée non seulement pour des projets différents, mais aussi pour des environnements différents (Production, Assurance qualité et Développement).
- Le runtime d’intégration auto-hébergé peut être partagé avec plusieurs fabriques de données. La fabrique de données principale le référence en tant que runtime d’intégration auto-hébergé partagé, tandis que d’autres produits le désignent sous le nom de runtime d’intégration auto-hébergé lié. Un runtime d’intégration auto-hébergé physique peut avoir plusieurs nœuds dans un cluster. La communication se produit seulement entre le runtime d’intégration auto-hébergé principal et le nœud principal, le travail étant distribué aux nœuds secondaires à partir du nœud principal.
- Les informations d’identification des magasins de données locaux peuvent être stockées sur la machine locale ou dans un coffre Azure Key Vault. Azure Key Vault est fortement recommandé.
- La communication entre le runtime d’intégration auto-hébergé et la fabrique de données peut passer par une liaison privée. Cependant, la création interactive via Azure Relay et la mise à jour automatique vers la dernière version à partir du centre de téléchargement ne prennent actuellement pas en charge une liaison privée. Le trafic passe par le pare-feu de l’environnement local. Pour plus d’informations, consultez l’article Azure Private Link pour Azure Data Factory.
- La liaison privée est nécessaire seulement pour la fabrique de données principale. Tout le trafic passe par la fabrique de données principale, puis vers d’autres fabriques de données.
- Le nom du runtime d’intégration auto-hébergé doit être identique pour toutes les phases de CI/CD. Vous pouvez envisager d’utiliser une fabrique ternaire seulement pour contenir les runtimes d’intégration auto-hébergés partagés, et utiliser le runtime d’intégration auto-hébergé lié dans les différentes phases de production. Pour plus d’informations, consultez l’article Intégration et livraison continues.
- Vous pouvez contrôler la façon dont le trafic est acheminé vers le centre de téléchargement et Azure Relay en utilisant des configurations de votre réseau local et ExpressRoute, via un proxy local ou d’un réseau virtuel de hub. Vérifiez que le trafic est autorisé par les règles de proxy ou de groupe de sécurité réseau.
- Si vous souhaitez sécuriser la communication entre les nœuds du runtime d’intégration auto-hébergé, vous pouvez activer l’accès à distance depuis l’intranet avec un certificat TLS/SSL. Pour plus d’informations, consultez l’article Activer l’accès à distance à partir d’un intranet avec un certificat TLS/SSL (avancé).