Connecteur Azure Data Explorer pour Apache Spark
Apache Spark est un moteur d’analytique unifié pour le traitement des données à grande échelle. Azure Data Explorer est un service d’analytique données rapide et entièrement managé dédié à l’analyse en temps réel de volumes importants de données de streaming.
Le connecteur Kusto pour Spark est un projet open source qui peut s’exécuter sur n’importe quel cluster Spark. Il implémente la source de données et le récepteur de données pour déplacer les données entre les clusters Azure Data Explorer et Spark. À l’aide d’Azure Data Explorer et d’Apache Spark, vous pouvez rapidement créer des applications scalables ciblant des scénarios basés sur les données. Par exemple, les scénarios de machine learning (ML), les scénarios ETL et les scénarios Log Analytics. Avec le connecteur, Azure Data Explorer devient un magasin de données valide pour les opérations de source et de réception Spark standard, telles que write, read et writeStream.
Vous pouvez écrire dans Azure Data Explorer via l’ingestion en file d’attente ou l’ingestion de streaming. La fonctionnalité de lecture dans Azure Data Explorer prend en charge le nettoyage des colonnes et le pushdown des prédicats, ce qui filtre les données d’Azure Data Explorer et réduit le volume de données transférées.
Remarque
Pour plus d’informations sur l’utilisation du connecteur Synapse Spark pour Azure Data Explorer, consultez Connexion à Azure Data Explorer à l’aide d’Apache Spark pour Azure Synapse Analytics.
Cette rubrique explique comment installer et configurer le connecteur Azure Data Explorer pour Spark, et comment déplacer des données entre Azure Data Explorer et les clusters Apache Spark.
Remarque
Bien que certains des exemples ci-dessous fassent référence à un cluster Spark Azure Databricks, le connecteur Spark Azure Data Explorer ne dépend pas directement de ce cluster, ni d’aucune autre distribution Spark.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Un cluster Spark
- Installer la bibliothèque de connecteurs :
- Bibliothèques prédéfinies pour Spark 2.4+Scala 2.11 ou Spark 3+scala 2.12
- Dépôt Maven
- Installation de Maven 3.x
Conseil
Les versions 2.3.x de Spark sont également prises en charge, mais il peut s’avérer nécessaire de modifier certaines dépendances du fichier pom.xml.
Comment créer un connecteur Spark
À partir de la version 2.3.0, nous introduisons de nouveaux ID d’artefact qui remplacent spark-kusto-connector : kusto-spark_3.0_2.12 ciblant Spark 3.x et Scala 2.12.
Remarque
Les versions antérieures à la version 2.5.1 ne fonctionnent plus pour l’ingestion dans une table existante, effectuez une mise à jour vers une version ultérieure. Cette étape est facultative. Si vous utilisez des bibliothèques prédéfinies, par exemple Maven, consultez Configuration des clusters Spark.
Configuration requise
Reportez-vous à cette source pour la création du connecteur Spark.
Pour les applications Scala/Java utilisant des définitions de projet Maven, liez votre application au dernier artefact. Recherchez l’artefact le plus récent sur Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Si vous n’utilisez pas de bibliothèques prédéfinies, vous devez installer les bibliothèques répertoriées dans dépendances, y compris les bibliothèques de SDK Kusto Java suivantes. Pour trouver la bonne version à installer, regardez dans le fichier pom de la version appropriée :
Pour générer un fichier jar et exécuter tous les tests :
mvn clean package -DskipTestsPour générer un fichier jar, exécutez tous les tests et installez le fichier jar dans votre référentiel Maven local :
mvn clean install -DskipTests
Pour en savoir plus, consultez la section relative à l’utilisation des connecteurs.
Configuration du cluster Spark
Remarque
Il est recommandé d’utiliser la dernière version du connecteur Spark Kusto lorsque vous effectuez les étapes suivantes.
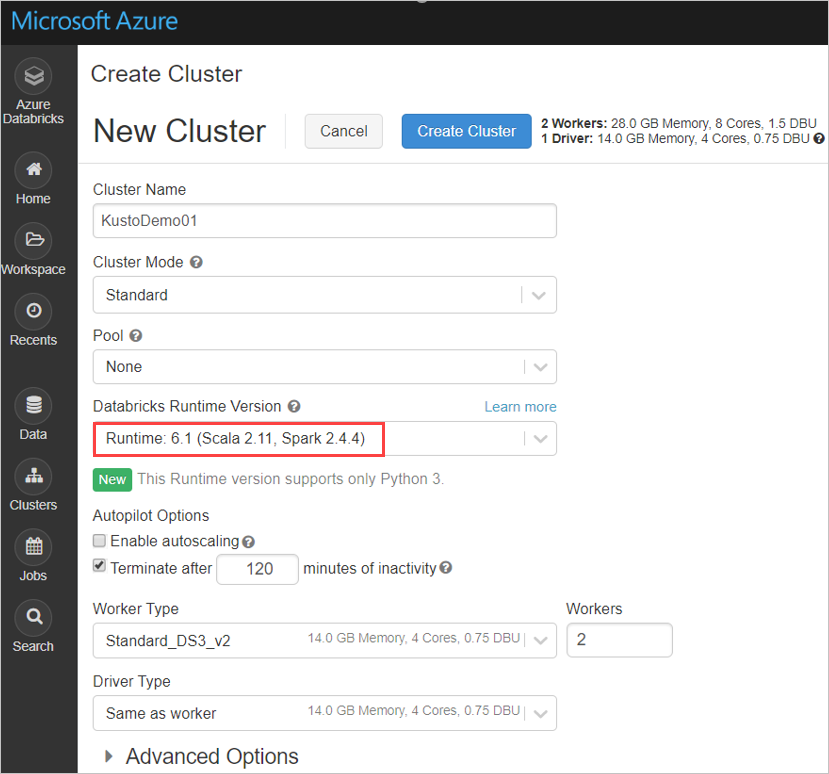
Configurez les paramètres suivants du cluster Spark en fonction du cluster Azure Databricks Spark 3.0.1 et Scala 2.12 :
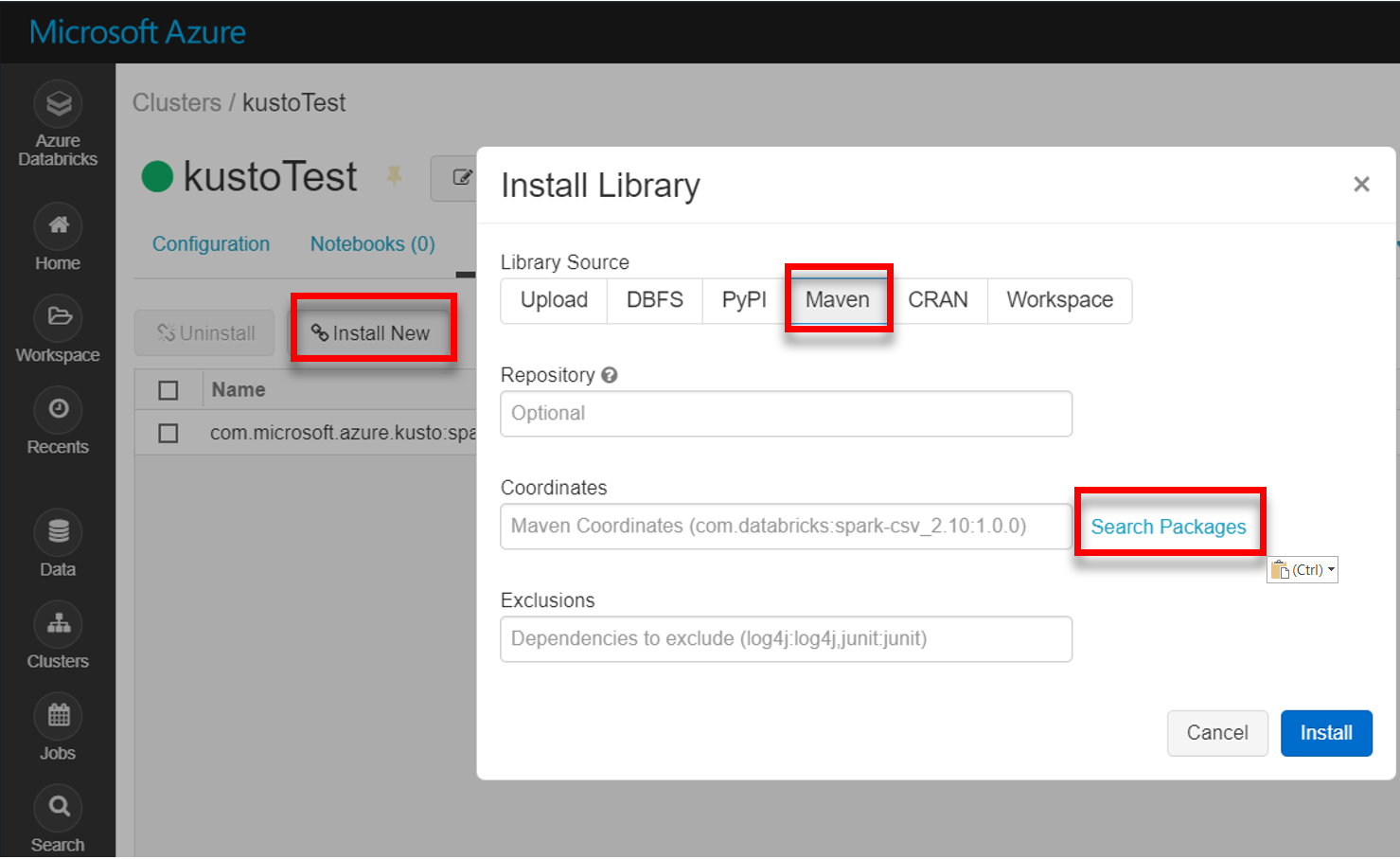
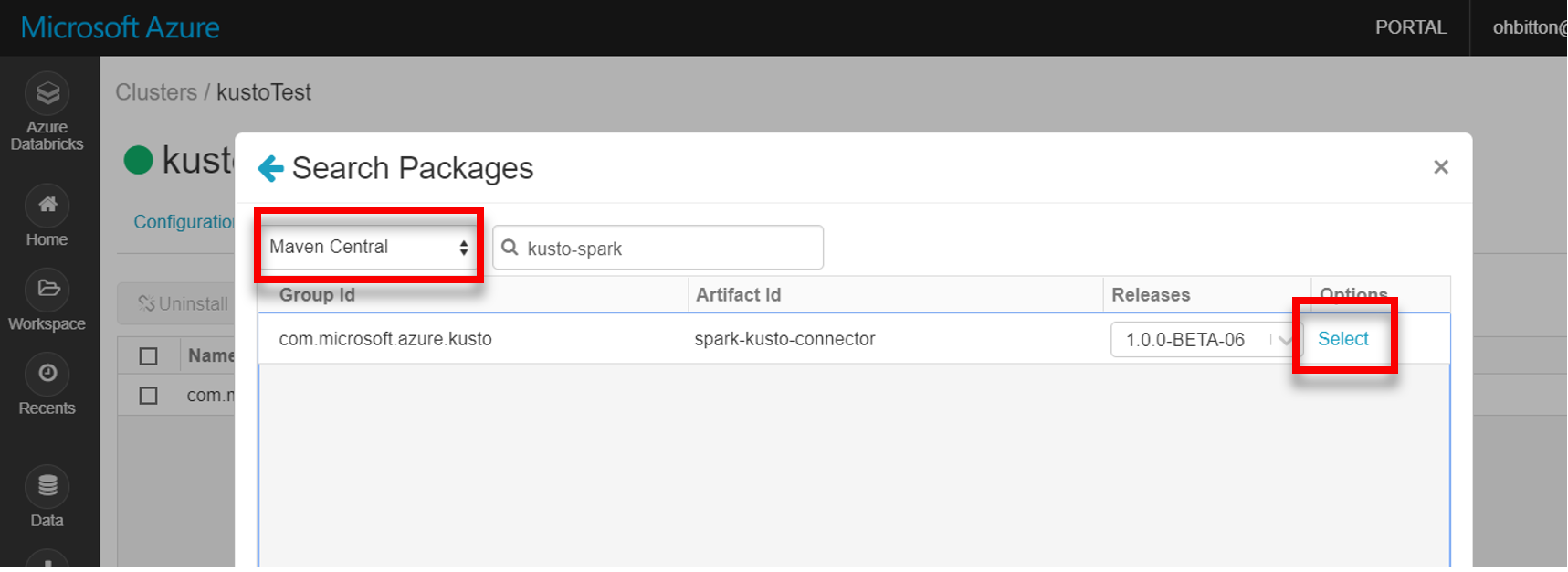
Installez la dernière bibliothèque spark-kusto-connector à partir de Maven :
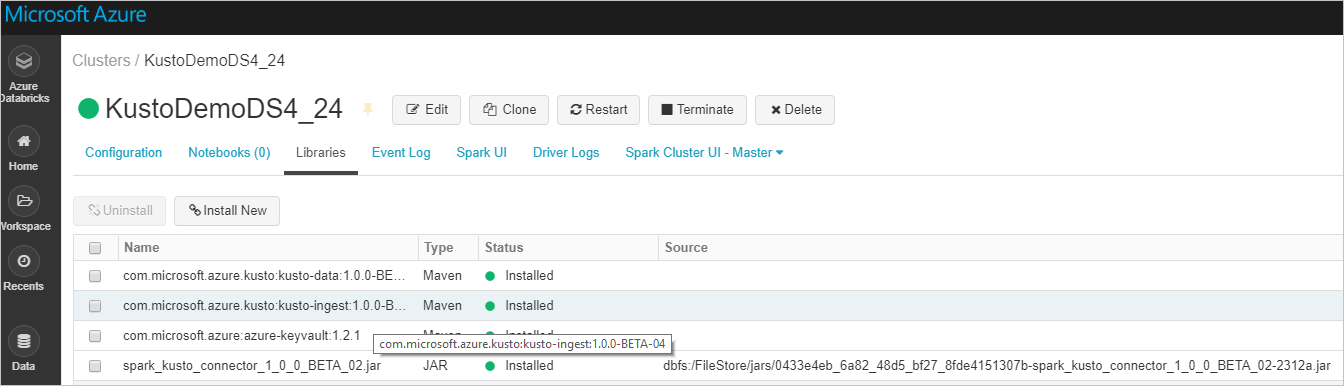
Vérifiez que toutes les bibliothèques requises sont installées :
Si vous souhaitez effectuer une installation à l’aide d’un fichier JAR, vérifiez que d’autres dépendances ont été installées :
Authentification
Le connecteur Kusto Spark vous permet de vous authentifier auprès de Microsoft Entra ID à l’aide de l’une des méthodes suivantes :
- Une application Microsoft Entra
- Un jeton d’accès Microsoft Entra
- Authentification de l’appareil (pour les scénarios autres que les scénarios de production)
- Un coffre de clés Azure Key Vault Pour accéder à la ressource Key Vault, installez le package azure-keyvault et entrez les informations d’identification de l’application.
Authentification de l’application Microsoft Entra
L’authentification de l’application Microsoft Entra est la méthode d’authentification la plus simple et la plus courante recommandée pour le connecteur Spark Kusto.
Connectez-vous à votre abonnement Azure via Azure CLI. Authentifiez-vous ensuite dans le navigateur.
az loginChoisissez l’abonnement pour héberger le principal. Cette étape est nécessaire quand vous avez plusieurs abonnements.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCréez le principal de service. Dans cet exemple, le principal de service est appelé
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}À partir des données JSON retournées, copiez le
appId,passwordettenantpour une utilisation ultérieure.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Vous avez créé votre application Microsoft Entra et votre principal de service.
Le connecteur Spark utilise les propriétés d’application Entra suivantes pour l’authentification :
| Propriétés | Chaîne d’option | Description |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Identificateur( client) de l’application Microsoft Entra. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Autorité d’authentification Microsoft Entra. ID (de locataire) du répertoire Microsoft Entra. Facultatif - La valeur par défaut est microsoft.com. Pour plus d’informations, consultez Autorité Microsoft Entra. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Clé d’application Microsoft Entra pour le client. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Si vous disposez déjà d’un accessToken créé avec l’accès à Kusto, il peut être utilisé également pour l’authentification. |
Remarque
Les anciennes versions d’API (inférieures à 2.0.0) ont le nommage suivant : "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Privilèges Kusto
Accordez les privilèges suivants côté Kusto en fonction de l’opération Spark que vous souhaitez effectuer.
| Opération Spark | Privilèges |
|---|---|
| Lire – Mode Unique | Lecteur |
| Lire – Mode Force distribuée | Lecteur |
| Écrire – Mode file d’attente avec l’option de création de table CreateTableIfNotExist | Administrateur |
| Écrire – Mode file d’attente avec l’option de création de table FailIfNotExist | Ingestion |
| Écrire – TransactionalMode | Administrateur |
Pour plus d’informations sur les rôles principaux, consultez Contrôle d’accès en fonction du rôle. Pour savoir comment gérer les rôles de sécurité, consultez la section relative à la gestion des rôles de sécurité.
Récepteur Spark : écriture dans Kusto
Configurez les paramètres du récepteur :
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Écrivez un DataFrame Spark dans un cluster Kusto en tant que lot :
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Ou utilisez la syntaxe simplifiée :
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Écrivez les données de diffusion en continu :
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Source Spark : lecture à partir de Kusto
Lors de la lecture de petites quantités de données, définissez la requête de données :
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Facultatif : si c’est vous qui fournissez le stockage des objets blob temporaires (et non Kusto), les objets blob seront créés sous la responsabilité de l’appelant. Cela comprend le provisionnement du stockage, la rotation des clés d’accès et la suppression des artefacts temporaires. Le module KustoBlobStorageUtils contient des fonctions d’assistance permettant de supprimer des objets blob en fonction des coordonnées du compte et du conteneur, et des informations d’identification du compte, ou en fonction d’une URL SAS complète disposant d’autorisations d’écriture, de lecture et de liste. Lorsque le jeu de données RDD correspondant n’est plus nécessaire, chaque transaction stocke les artefacts d’objets blob temporaires dans un répertoire distinct. Ce répertoire est capturé dans les journaux des transactions de lecture signalés sur le nœud du pilote Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")Dans l’exemple ci-dessus, le coffre de clés n’est pas accessible à l’aide de l’interface du connecteur. Pour l’utilisation des secrets Databricks, une méthode plus simple est utilisée.
Lire à partir de Kusto.
Si c’est vous qui fournissez le stockage des objets blob temporaires, lisez les données à partir de Kusto de la manière suivante :
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Si Kusto fournit le stockage d’objets blob temporaires, lisez à partir de Kusto de la manière suivante :
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)