Calculatrice de prix Azure Data Explorer
Azure Data Explorer fournit une calculatrice de prix pour estimer le coût de votre cluster. L’estimation est basée sur des spécifications telles que l’ingestion de données estimée et la charge de travail du moteur. Lorsque vous apportez des modifications à la configuration, l’estimation des prix change également afin de comprendre les implications du coût de vos choix de configuration.
Cet article explique chacun des composants de la calculatrice et fournit des conseils pour vous aider à prendre de meilleures décisions sur la configuration de votre cluster.
Fonctionnement
Vous définissez la région, l’environnement et l’ingestion estimée des données de votre cluster. Ensuite, la calculatrice estime un coût mensuel en fonction des spécifications sélectionnées automatiquement ou sélectionnées manuellement dans chacun des composants suivants :
- Instances du moteur
- Instances de gestion des données
- Stockage et transactions
- Mise en réseau
- Majoration Azure Data Explorer
En bas du formulaire, les estimations des composants individuels sont ajoutées ensemble pour créer une estimation mensuelle totale. Les estimations du composant et la mise à jour totale à mesure que vous apportez des modifications de configuration.
Démarrage
- Accédez à la calculatrice de prix.
- Faites défiler la page jusqu’à ce qu’un onglet intitulé Votre estimation s’affiche.
- Vérifiez qu’Azure Data Explorer s’affiche sous l’onglet. Si ce n’est pas le cas, procédez comme suit :
- Faites défiler vers le haut de la page.
- Dans la zone de recherche, tapez « Azure Data Explorer ».
- Sélectionnez le widget Azure Data Explorer .
- Démarrez la configuration.
Les sections de cet article correspondent aux composants de la calculatrice et mettent en évidence ce que vous devez savoir.
Région et environnement
La région et l’environnement que vous choisissez pour votre cluster affectent le coût de chaque composant. Cela est dû au fait que les différentes régions et environnements ne fournissent pas exactement les mêmes services ou capacités.
Sélectionnez la région souhaitée pour votre cluster.
Utilisez le guide de décision des régions pour trouver la bonne région pour vous. Votre choix peut dépendre des exigences telles que :
Choisissez l’environnement de votre cluster.
Les clusters de production contiennent deux nœuds ou plus pour la gestion des moteurs et des données et fonctionnent sous le contrat SLA Azure Data Explorer.
Les clusters de développement/test sont l’option de coût la plus faible, ce qui les rend idéales pour l’évaluation du service, la réalisation de poCs et les validations de scénarios. Ils sont limités en taille et ne peuvent pas croître au-delà d’un seul nœud. Il n’existe aucun coût de balisage Azure Data Explorer ni contrat SLA produit pour ces clusters.
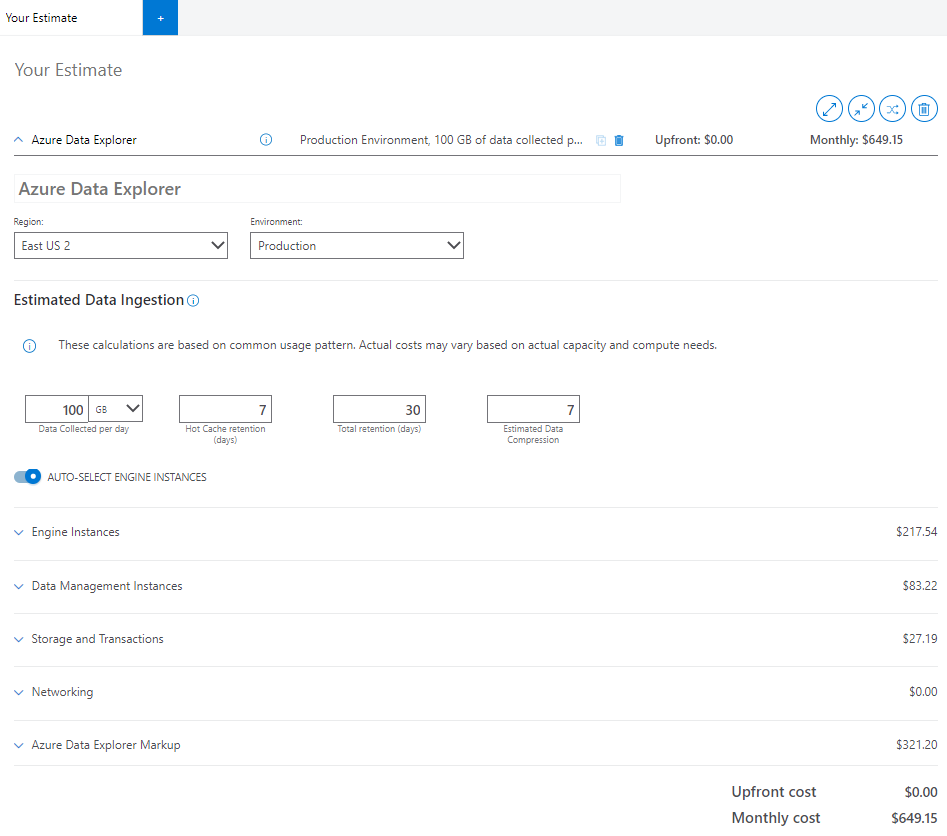
Ingestion estimée des données
Les informations fournies dans la section Estimation de l’ingestion des données de la calculatrice influencent le prix de tous les composants de votre cluster.
Dans la calculatrice, entrez des estimations pour les champs suivants :
Données collectées par jour (Go/To) : données que vous envisagez d’ingérer sans compression dans le cluster Azure Data Explorer tous les jours. Calculez cette estimation en fonction du nombre de fichiers et de la taille moyenne d’un fichier ingéré. Si vous diffusez en continu les données à l’aide de messages, passez en revue la taille moyenne d’un message unique et le nombre de messages que vous ingérerez.
Conservation du cache à chaud (jours) : période pendant laquelle vos données sont stockées dans le cache pour un accès rapide aux requêtes. Données ingérées mises en cache en fonction de notre stratégie de cache sur le disque SSD local du service moteur. Vos besoins en matière de performances de requête déterminent la quantité de nœuds de calcul et le stockage SSD local nécessaire.
Rétention totale (jours) : période pendant laquelle vos données sont stockées et disponibles pour la requête. Après la fenêtre de rétention, vos données seront automatiquement supprimées. Choisissez la fenêtre de rétention des données en fonction de la conformité ou d’autres exigences réglementaires. Appliquez la fonctionnalité de fenêtre chaude pour chauffer les données en fonction de la fenêtre de temps pour des requêtes plus rapides.
Compression estimée des données : rapport entre la taille de données non compressée et la taille compressée. La compression des données varie en fonction de la cardinalité des valeurs et de sa structure. Par exemple, les données ingérées dans des colonnes structurées ont une compression plus élevée par rapport aux colonnes dynamiques ou au GUID. Toutes les données ingérées sont compressées par défaut.
Sélectionner automatiquement les instances du moteur
Si vous souhaitez configurer individuellement les composants restants, désactivez les instances DU MOTEUR AUTO-SELECT. Quand elle est activée, la calculatrice sélectionne la référence SKU la plus optimale en fonction des entrées d’ingestion.
Instances du moteur
Les instances de moteur sont responsables de l’indexation, de la mise en cache des données sur des disques SSD locaux, du stockage Premium en tant que disques managés et de la distribution de requêtes. Le service moteur nécessite un minimum de deux instances de calcul.
Options de la charge de travail
Voici les options de charge de travail du moteur :
- Tout : sélectionne automatiquement la référence SKU optimale en fonction de l’entrée que vous fournissez
- Références SKU optimisées pour le calcul :
- Fournit des cœurs élevés au rapport de cache chaud
- Adapté aux taux de requête élevés
- SSD local pour les E/S à faible latence
- Références SKU optimisées pour le stockage :
- Fournit des options de stockage plus volumineuses de 1 To à 4 To par nœud moteur
- Adapté aux charges de travail qui nécessitent la mise en cache de grandes tailles de données
- Dans certaines références SKU, le stockage de disque managé Premium est attaché au nœud du moteur au lieu de SSD local pour le stockage de données à chaud
Pour obtenir une estimation pour les instances de moteur :
- Choisissez entre les options de charge de travail. L’instance du moteur s’ajuste en conséquence. Si vous avez désactivé les instances du moteur AUTO-SELECT, choisissez l’instance de moteur spécifique et la série de machines virtuelles.
- Spécifiez le nombre d’heures, de jours ou de mois que vous souhaitez exécuter le moteur.
- (Facultatif) Sélectionnez un plan Options d’épargne .
Le composant Disque managé Premium est basé sur la référence SKU sélectionnée.
Remarque
Toutes les séries de machines virtuelles ne sont pas proposées dans chaque région. Si vous recherchez une référence SKU qui n’est pas répertoriée dans la région sélectionnée, choisissez une autre région.
Instances de gestion des données
Le service de gestion des données (DM) est responsable de l’ingestion des données à partir de pipelines de données managés tels que stockage Blob Azure, Event Hubs, IoT Hub et d’autres services tels qu’Azure Data Factory, Azure Stream Analytics et Kafka. Le service nécessite un minimum de deux instances de calcul qui sont automatiquement configurées et gérées en fonction de la taille de l’instance du moteur.
Pour obtenir une estimation pour les instances Gestion des données :
- Spécifiez le nombre d’heures, de jours ou de mois que vous souhaitez exécuter l’instance.
- (Facultatif) Sélectionnez un plan Options d’épargne .
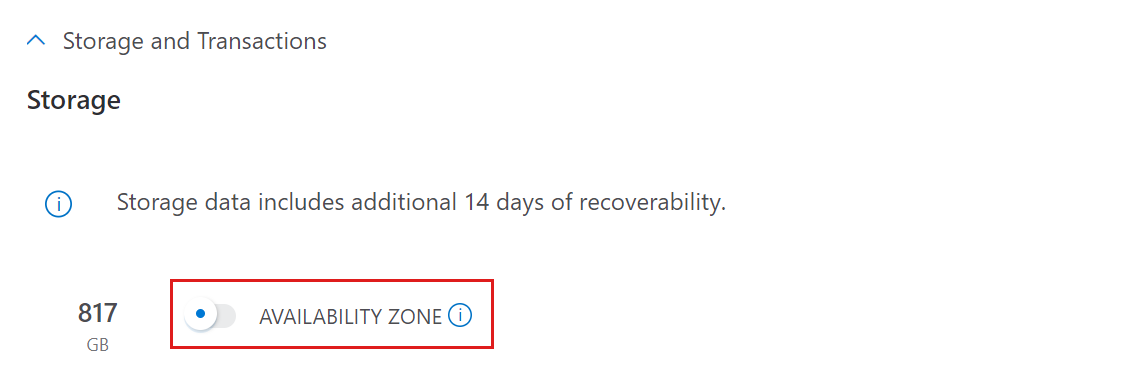
Stockage et transactions
Le composant de stockage est la couche persistante dans laquelle toutes les données sont stockées compressées et facturées en tant que LRS Standard ou ZRS Standard. Le stockage est calculé en fonction de la quantité de données collectées, du nombre total de jours de rétention et de la compression estimée des données.
Pour obtenir une estimation pour le stockage et les transactions :
- Si vous avez besoin de la prise en charge de la zone de disponibilité, activez LA ZONE DE DISPONIBILITÉ. Lorsqu’il est activé, le stockage est déployé en tant que ZRS. Sinon, le stockage sera déployé en tant que LRS.
Mise en réseau
Ce composant est configuré à l’aide du service de bande passante.
Pour obtenir une estimation du service de bande passante :
- Faire défiler vers le haut de la page
- Dans la zone de recherche, tapez « bande passante »
- Sélectionner le widget de produit de bande passante
- Faites défiler jusqu’au composant Bande passante de l’estimation
- Sélectionner un type de transfert de données
- Sélectionner une région source
- Sélectionner une région de destination
- Entrez la quantité estimée de données sortantes en Go
Remarque
Sélectionnez la même région dans laquelle les journaux sont générés pour éviter les coûts interrégions et réduire la latence. Il n’existe aucun coût de transfert de données entre les services Azure déployés dans la même région.
Majoration Azure Data Explorer
Le balisage Azure Data Explorer est facturé pour l’option de prise en charge Premium fournie avec vos clusters d’ingestion et de moteur de données. Il est facturé en fonction du nombre de processeurs virtuels du moteur dans le cluster et n’est pas facturé pour les clusters de développement. Vos coûts changent en fonction du nombre d’heures, de jours ou de mois configurés dans le composant instances du moteur. Sélectionnez éventuellement un plan Options d’épargne. Pour plus d’informations, consultez la tarification d’Azure Data Explorer - FAQ.
Support
Choisissez un plan de support :
Développeur : sélectionnez cette option lors de la configuration d’Azure Data Explorer dans un environnement hors production ou pour une évaluation et une évaluation. Pour plus d’informations, consultez la page Support Azure : Développeur .
Standard : sélectionnez cette option lors de la configuration d’Azure Data Explorer lorsque vous avez besoin d’une dépendance critique pour l’entreprise minimale. Pour plus d’informations, consultez la page Support Azure : Standard .
Professionnel Direct : sélectionnez cette option lorsque vous avez besoin d’une utilisation importante critique pour l’entreprise d’Azure Data Explorer. Pour plus d’informations, consultez la page Support Azure : Professionnel Direct .
Que faire avec votre estimation
- Exporter l’estimation vers Excel
- Enregistrer l’estimation pour une référence future
- Partager l’estimation : la connexion est requise