Configurer l’ingestion en streaming dans votre cluster Azure Data Explorer
L’ingestion en streaming permet de charger des données lorsque vous avez besoin d’une faible latence entre l’ingestion et l’interrogation. Vous pouvez utiliser l’ingestion en streaming dans les scénarios suivants :
- Lorsqu’une latence inférieure à une seconde est nécessaire.
- Pour optimiser le traitement opérationnel d’un grand nombre de tables, lorsque le flux de données de chaque table est relativement faible (quelques enregistrements par seconde), mais que le volume global d’ingestion de données est élevé (des milliers d’enregistrements par seconde).
Si le flux de données dans chaque table est élevé (plus de 4 Go par heure), envisagez d’utiliser l’ingestion mise en file d’attente.
Pour plus d’informations sur les méthodes d’ingestion, consultez Vue d’ensemble de l’ingestion des données.
Pour obtenir des exemples de code fondés sur les versions précédentes du kit de développement logiciel (SDK), consultez l’article archivé.
Choisir le type d’ingestion de streaming approprié
Deux types d’ingestion de streaming sont pris en charge :
| Type d’ingestion | Description |
|---|---|
| Connexion de données | Les connexions de données Event Hubs, IoT Hub et Event Grid peuvent utiliser l’ingestion de streaming, à condition qu’elles soient activées au niveau du cluster. La décision d’utiliser l’ingestion de streaming est effectuée en fonction de la stratégie d’ingestion de streaming configurée sur la table cible. Pour plus d’informations sur la gestion des connexions de données, consultez Event Hub, IoT Hub et Event Grid. |
| Ingestion personnalisée | L’ingestion personnalisée vous oblige à écrire une application qui utilise l’une des bibliothèques clientes Azure Data Explorer. Utilisez les informations de cette rubrique pour configurer l’ingestion personnalisée. Vous pouvez également trouver l’exemple d’application d’ingestion en streaming C ?view=azure-data-explorer&preserve-view=true#. |
Aidez-vous du tableau suivant pour choisir le type d’ingestion le mieux adapté à votre environnement :
| Critère | Connexion de données | Ingestion personnalisée |
|---|---|---|
| Délai de données entre le lancement de l’ingestion et le moment où les données sont disponibles pour une requête | Délai plus long | Délai plus court |
| Surcharge de développement | Installation rapide et facile, aucune surcharge de développement | Frais de développement élevés pour créer une application, ingérer des données, gérer les erreurs et garantir la cohérence des données |
Remarque
Vous pouvez gérer le processus d’activation et de désactivation de l’ingestion en streaming dans votre cluster avec le portail Azure, ou par programmation avec le langage C#. Si vous utilisez déjà le langage C# pour votre application personnalisée, il peut s’avérer plus pratique d’utiliser l’approche programmatique.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
Considérations relatives aux performances et aux opérations
Les contributeurs principaux qui peuvent impacter l’ingestion en streaming sont les suivants :
- Taille de la machine virtuelle et du cluster : la capacité et les performances de l’ingestion en streaming évoluent à mesure que la taille des clusters et des machines virtuelles augmente. Le nombre de demandes d’ingestion simultanées est limité à six par cœur. Par exemple, pour les références SKU 16 cœurs telles que D14 et L16, la charge maximale prise en charge est de 96 demandes d’ingestion simultanées. Pour les références SKU 2 cœurs telles que D11, la charge maximale prise en charge est de 12 demandes d’ingestion simultanées.
- Limite de taille des données : la taille limite des données par demande d’ingestion en streaming est de 4 Mo. Cela comprend toutes les données créées pour les stratégies de mise à jour lors de l’ingestion.
- Mises à jour des schémas : les mises à jour des schémas, telles que la création et la modification des tables et des mappages d’ingestion, peuvent prendre jusqu’à cinq minutes pour le service d’ingestion de streaming. Pour plus d’informations, consultez Ingestion de streaming et changements de schéma.
- Capacité du disque SSD : l’activation de l’ingestion de streaming sur un cluster, même lorsque les données ne sont pas ingérées via streaming, utilise une partie du disque SSD local des machines du cluster pour les données d’ingestion en streaming et réduit le stockage disponible pour le cache chaud.
Activer l’ingestion de streaming sur votre cluster
Avant de pouvoir utiliser l’ingestion en streaming, vous devez activer cette fonctionnalité sur votre cluster et définir une stratégie d’ingestion en streaming. Vous pouvez activer cette fonctionnalité lors de la création du cluster, ou l’ajouter à un cluster existant.
Avertissement
Avant d’activer l’ingestion en streaming, passez en revue les limitations.
Activer l’ingestion de streaming lors de la création d’un cluster
Vous pouvez activer l’ingestion en streaming lors de la création d’un cluster avec le portail Azure, ou par programmation avec le langage C#.
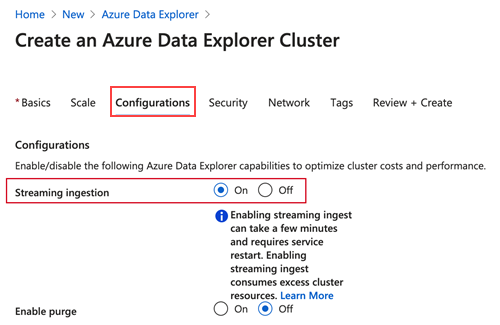
Lors de la création d’un cluster à l’aide des étapes décrites dans Créer un cluster et une base de données Azure Data Explorer, sous l’onglet Configurations, sélectionnez Ingestion en streaming>Activé.
Activer l’ingestion de streaming dans un cluster existant
Si vous disposez déjà d’un cluster, vous pouvez activer l’ingestion en streaming à l’aide du portail Azure, ou par programmation à l’aide du langage C#.
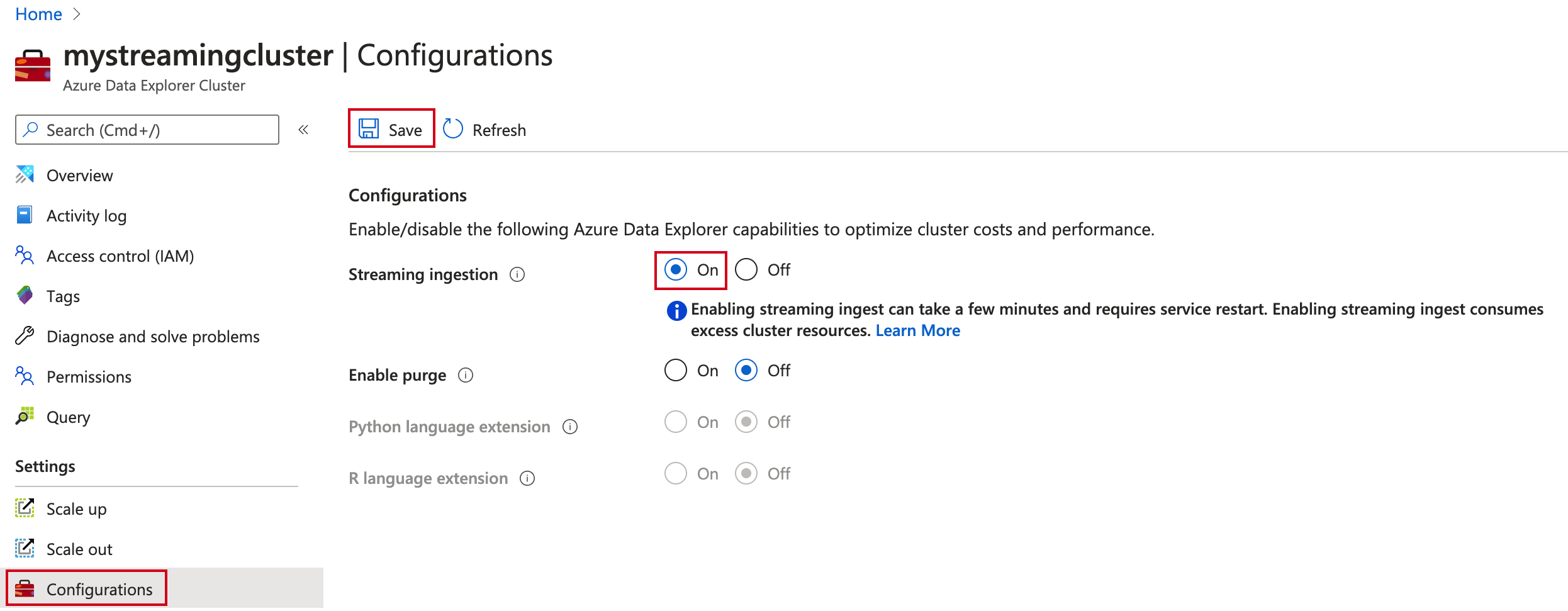
Dans le portail Azure, accédez à votre cluster Azure Data Explorer.
Dans Paramètres, sélectionnez Configurations.
Dans le volet Configurations, sélectionnez Activé pour activer Ingestion de streaming.
Cliquez sur Enregistrer.
Créer une table cible et définir la stratégie
Créez une table pour recevoir les données d’ingestion en streaming et définissez la stratégie associée à l’aide du portail Azure ou par programmation à l’aide du langage C#.
Dans le portail Azure, accédez à votre cluster.
Sélectionnez Requête.
Pour créer la table qui recevra les données par le biais de l’ingestion de streaming, copiez la commande suivante dans le volet de requête, puis sélectionnez Exécuter.
.create table TestTable (TimeStamp: datetime, Name: string, Metric: int, Source:string)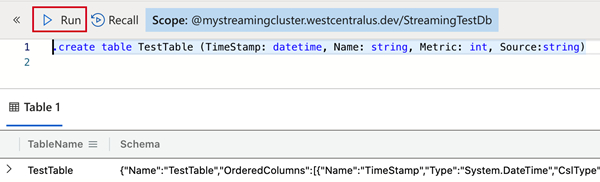
Copiez l’une des commandes suivantes dans le volet de requête, puis sélectionnez Exécuter. Cela définit la stratégie d’ingestion en streaming pour la table que vous avez créée ou la base de données qui contient cette table.
Conseil
Une stratégie qui est définie au niveau de la base de données s’applique à toutes les tables existantes et futures de la base de données. Lorsque vous activez la stratégie au niveau de la base de données, il n’est pas nécessaire de l’activer par table.
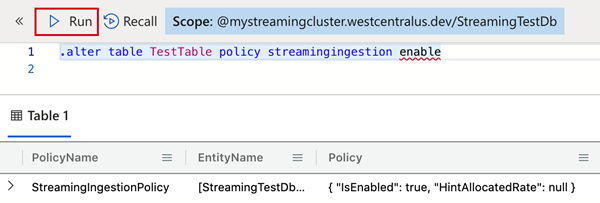
Pour définir la stratégie de la table que vous avez créée, utilisez ceci :
.alter table TestTable policy streamingingestion enablePour définir la stratégie de la base de données contenant la table que vous avez créée, utilisez ceci :
.alter database StreamingTestDb policy streamingingestion enable
Créer une application d’ingestion en streaming pour ingérer des données dans votre cluster
Créez votre application pour ingérer des données dans votre cluster à l’aide de votre langage préféré.
using System.IO;
using System.Threading.Tasks;
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Ingest; // Requires Package Microsoft.Azure.Kusto.Ingest
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.windows.net";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
// Create a disposable client that will execute the ingestion
using var client = KustoIngestFactory.CreateStreamingIngestClient(connectionStringBuilder);
// Ingest from a compressed file
var fileStream = File.Open("MyFile.gz", FileMode.Open);
// Initialize client properties
var ingestionProperties = new KustoIngestionProperties(databaseName: "<databaseName>", tableName: "<tableName>");
// Create source options
var sourceOptions = new StreamSourceOptions { CompressionType = DataSourceCompressionType.gzip, };
// Ingest from stream
await client.IngestFromStreamAsync(fileStream, ingestionProperties, sourceOptions);
}
}
Désactiver l’ingestion de streaming sur votre cluster
Avertissement
La désactivation de l’ingestion de streaming peut prendre plusieurs heures.
Avant de désactiver l’ingestion de streaming dans votre cluster Azure Data Explorer, supprimez la stratégie d’ingestion de streaming pour toutes les tables et bases de données concernées. La suppression de la stratégie d’ingestion de streaming déclenche la réorganisation des données au sein de votre cluster Azure Data Explorer. Les données d’ingestion de streaming sont déplacées du stockage initial vers le stockage permanent dans la banque de colonnes (étendues ou partitions). Ce processus peut prendre de quelques secondes à quelques heures, selon la quantité de données qui se trouvent dans le stockage initial.
Supprimer la stratégie d’ingestion en streaming
Vous pouvez supprimer la stratégie d’ingestion en streaming à l’aide du portail Azure, ou par programmation à l’aide du langage C#.
Dans le portail Azure, accédez à votre cluster Azure Data Explorer, puis sélectionnez Requête.
Pour supprimer la stratégie d’ingestion de streaming de la table, copiez la commande suivante dans le volet de requête, puis sélectionnez Exécuter.
.delete table TestTable policy streamingingestion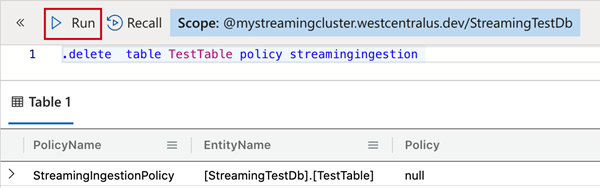
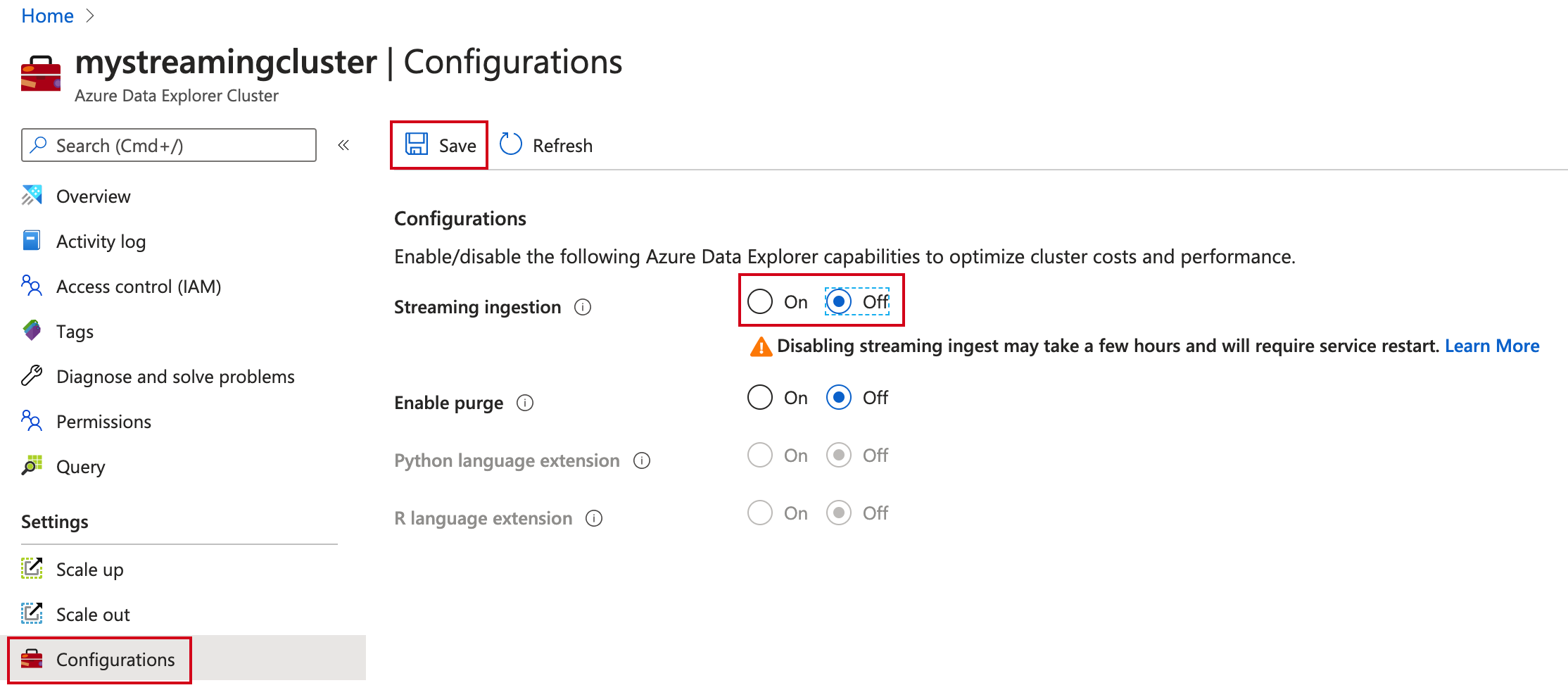
Dans Paramètres, sélectionnez Configurations.
Dans le volet Configurations, sélectionnez Désactivé pour désactiver Ingestion de streaming.
Cliquez sur Enregistrer.
Limites
- Les mappages de données doivent être précréés pour être utilisés dans une ingestion de streaming. Les demandes d’ingestion en streaming individuelles ne prennent pas en charge les mappages de données inline.
- Les étiquettes d’étendue ne peuvent pas être définies dans les données d’ingestion de streaming.
- Stratégie de mise à jour. La stratégie de mise à jour ne peut référencer que les données nouvellement ingérées dans la table source et aucune autre donnée ou table de la base de données.
- Lorsqu’une stratégie de mise à jour avec une stratégie transactionnelle échoue, les nouvelles tentatives revient à l’ingestion par lots.
- Si l’ingestion de streaming est activée sur un cluster utilisé comme leader pour des bases de données de follower, l’ingestion de streaming doit également être activée sur les clusters suivants pour suivre les données d’ingestion de streaming. Cela s’applique également si les données du cluster sont partagées via Data Share.