Ingérer des données Apache Kafka dans Azure Data Explorer
Apache Kafka est une plateforme de diffusion en continu distribuée qui permet la création de pipelines de données de diffusion en continu en temps réel, qui déplacent les données de façon fiable entre des systèmes ou des applications. Kafka Connect est un outil pour le streaming de données scalable et fiable entre Apache Kafka et d’autres systèmes de données. Le Kusto Kafka Sink sert de connecteur à partir de Kafka et ne requiert aucune utilisation de code. Téléchargez le fichier jar du connecteur de récepteur depuis le référentie Git ou depuis Confluent Connector Hub.
Cet article montre comment ingérer des données avec Kafka en utilisant une configuration Docker autonome pour simplifier la configuration du cluster Kafka et du cluster de connecteur Kafka.
Pour plus d’informations, consultez le dépôt Git et les spécificités des versions du connecteur.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer avec les stratégies de cache et de rétention par défaut.
- Azure CLI.
- Docker et Docker Compose.
Créer un principal de service Microsoft Entra
Le principal de service Microsoft Entra peut être créé dans le portail Azure ou programmatiquement, comme dans l’exemple suivant.
Ce principal de service est l’identité utilisée par le connecteur pour écrire des données dans votre table dans Kusto. Vous accorderez ultérieurement des autorisations pour ce principal de service afin d’accéder à des ressources Kusto.
Connectez-vous à votre abonnement Azure via Azure CLI. Authentifiez-vous ensuite dans le navigateur.
az loginChoisissez l’abonnement pour héberger le principal. Cette étape est nécessaire quand vous avez plusieurs abonnements.
az account set --subscription YOUR_SUBSCRIPTION_GUIDCréez le principal de service. Dans cet exemple, le principal de service est appelé
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}À partir des données JSON retournées, copiez le
appId,passwordettenantpour une utilisation ultérieure.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Vous avez créé votre application Microsoft Entra et votre principal de service.
Créer une table cible
Depuis votre environnement de requête, créez une table appelée
Stormsen utilisant la commande suivante :.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Créez le mappage de table correspondant
Storms_CSV_Mappingpour les données ingérées en utilisant la commande suivante :.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Créez une stratégie d’ingestion par lot sur la table pour la latence d’ingestion mise en fille d’attente configurable.
Conseil
La stratégie d’ingestion par lot est un optimiseur de performances et comprend trois paramètres. La premier conditions satisfaite déclenche l’ingestion dans la table.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Utilisez le principal de service de Créer un principal de service Microsoft Entra pour accorder l’autorisation d’utiliser la base de données.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Exécuter le labo
Le labo suivant est conçu pour vous permettre de commencer à créer des données, à configurer le connecteur Kafka et à diffuser en streaming ces données. Vous pouvez ensuite examiner les données ingérées.
Cloner le dépôt Git
Clonez le dépôt Git du labo.
Créez un répertoire local sur votre machine.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holClonez le dépôt.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Contenu du dépôt cloné
Exécutez la commande suivante pour lister le contenu du dépôt cloné :
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Le résultat de cette recherche est le suivant :
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Examiner les fichiers dans le dépôt cloné
Les sections suivantes expliquent les parties importantes des fichiers dans l’arborescence des fichiers.
adx-sink-config.json
Ce fichier contient le fichier de propriétés du récepteur Kusto dans lequel vous mettez à jour des détails de configuration spécifiques :
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Remplacez les valeurs des attributs suivants par celles de votre configuration : aad.auth.authority, aad.auth.appid, aad.auth.appkey, kusto.tables.topics.mapping (nom de la base de données), kusto.ingestion.url et kusto.query.url.
Connector - Dockerfile
Ce fichier contient les commandes permettant de générer l’image Docker pour l’instance du connecteur. Il comprend le téléchargement du connecteur à partir du répertoire de publication des dépôts git.
Répertoire Storm-events-producer
Ce répertoire contient un programme Go qui lit un fichier local « StormEvents. csv » et publie les données dans une rubrique Kafka.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Démarrer les conteneurs
Sur un terminal, démarrez les conteneurs :
docker-compose upL’application producer commence à envoyer des événements à la rubrique
storm-events. Vous devriez voir des journaux similaires aux journaux suivants :.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Pour consulter les journaux, exécutez la commande suivante dans un terminal distinct :
docker-compose logs -f | grep kusto-connect
Démarrer le connecteur
Utilisez un appel REST Kafka Connect pour démarrer le connecteur.
Dans un autre terminal, lancez la tâche du récepteur avec la commande suivante :
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsPour vérifier l’état, exécutez la commande suivante dans un autre terminal :
curl http://localhost:8083/connectors/storm/status
Le connecteur commence à mettre en file d’attente les processus d’ingestion.
Remarque
Si vous rencontrez des problèmes de connecteur de journaux, signalez-les.
Identité managée
Par défaut, le connecteur Kafka utilise la méthode d’application pour l’authentification pendant l’ingestion. Pour vous authentifier à l’aide de l’identité managée :
Attribuez à votre cluster une identité managée et accordez des autorisations de lecture à votre compte de stockage. Pour plus d’informations, consultez Ingestion de données à l’aide de l’authentification d’identité managée.
Dans votre fichier adx-sink-config.json , définissez
aad.auth.strategymanaged_identityet vérifiez qu’ilaad.auth.appidest défini sur l’ID du client d’identité managée (application).Utilisez un jeton de service de métadonnées d’instance privée au lieu du principal du service Microsoft Entra.
Remarque
Lors de l’utilisation d’une identité managée et appId tenant sont déduites du contexte du site d’appel et password ne sont pas nécessaires.
Interroger et examiner les données
Confirmer l’ingestion de données
Une fois les données arrivées dans la table
Storms, confirmez le transfert de données en vérifiant le nombre de lignes :Storms | countConfirmez qu’il n’y a pas de défaillance dans le processus d’ingestion :
.show ingestion failuresUne fois que vous voyez les données, essayez quelques requêtes.
Interroger les données
Pour voir tous les enregistrements, exécutez la requête suivante :
Storms | take 10Utilisez
whereetprojectpour filtrer des données spécifiques :Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdUtilisez l’opérateur
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart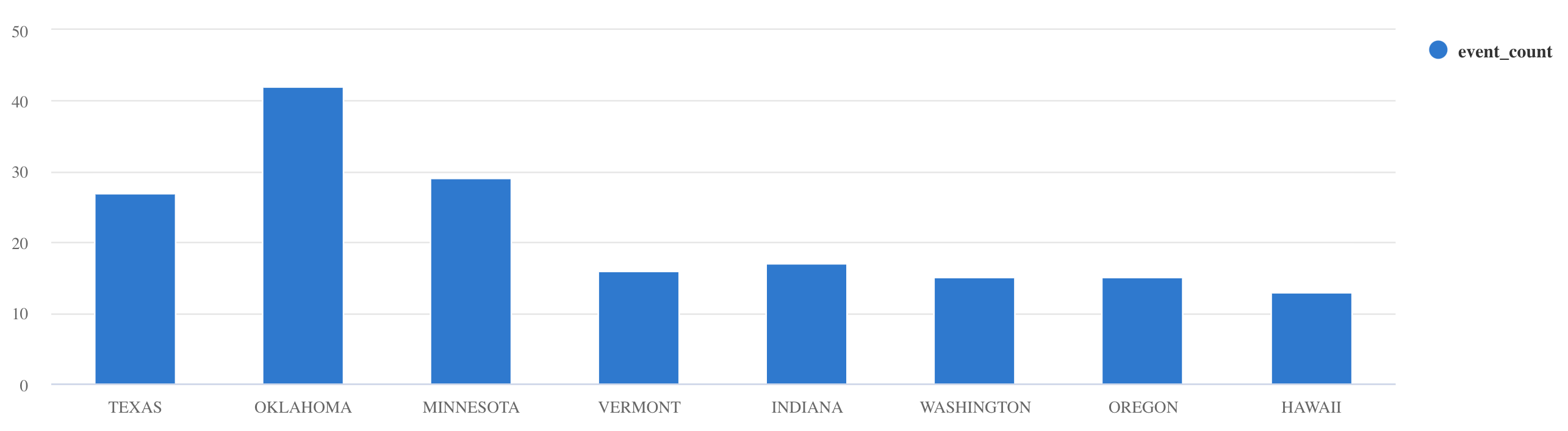
Pour plus de conseils et d’exemples de requête, consultez Écrire des requêtes dans KQL et la Documentation sur le langage de requête Kusto.
Réinitialiser
Pour réinitialiser, procédez comme suit :
- Arrêter les conteneurs (
docker-compose down -v) - Supprimer (
drop table Storms) - Recréer la table
Storms - Recréer le mappage de table
- Redémarrer les conteneurs (
docker-compose up)
Nettoyer les ressources
Pour supprimer les ressources Azure Data Explorer, utilisez az kusto cluster delete (extension kusto) ou az kusto database delete (extension kusto) :
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
Vous pouvez également supprimer votre cluster et votre base de données via le Portail Azure. Pour plus d’informations, consultez Supprimer un cluster Azure Data Explorer et supprimer une base de données dans Azure Data Explorer.
Réglage du connecteur Kafka Sink
Réglez le connecteur Kafka Sink pour qu’il fonctionne avec la stratégie de traitement par lot d’ingestion :
- Réglez la taille limite
flush.size.bytesde Kafka Sink en commençant à 1 Mo, puis en augmentant par incréments de 10 Mo ou 100 Mo. - Lors de l’utilisation de Kafka Sink, les données sont agrégées deux fois. Les données sont agrégées en fonction des paramètres de vidage côté connecteur et selon la stratégie de traitement par lot du côté du service. Si le temps de traitement par lot est trop faible et qu’aucune donnée ne peut être ingérée par le connecteur et le service, le temps de traitement par lot doit être augmenté. Définissez la taille de lot sur 1 Go et augmentez ou diminuez la taille par incréments de 100 Mo en fonction des besoins. Par exemple, si la taille de vidage est de 1 Mo et que la taille de stratégie de traitement par lot est de 100 Mo, le connecteur récepteur Kafka agrège les données dans un lot de 100 Mo. Ce lot est ensuite ingéré par le service. Si la durée de la stratégie de traitement par lot est de 20 secondes et que le connecteur Kafka Sink vide 50 Mo dans une période de 20 secondes, le service ingère un lot de 50 Mo.
- Vous pouvez effectuer une mise à l’échelle en ajoutant des instances et des partitions Kafka. Augmentez
tasks.maxen le définissant sur le nombre de partitions. Créez une partition si vous avez suffisamment de données pour produire un objet blob de la taille définie par le paramètreflush.size.bytes. Si l’objet blob est plus petit, le lot est traité lorsqu’il atteint la limite de temps, de telle sorte que la partition ne reçoit pas suffisamment de débit. Un grand nombre de partitions signifie une charge de traitement plus importante.
Contenu connexe
- Explorez en détail l’architecture de big data.
- Apprenez à Ingérer des exemples de données au format JSON dans Azure Data Explorer.
- En savoir plus avec les laboratoires Kafka :