Guide pratique pour ingérer des données historiques dans Azure Data Explorer
Un scénario courant lors de l’intégration à Azure Data Explorer consiste à ingérer des données historiques, parfois appelées réapprovisionnement. Le processus implique l’ingestion de données d’un système de stockage existant dans une table, qui est une collection d’étendues.
Nous vous recommandons d’ingérer des données historiques à l’aide de la propriété d’ingestion creationTime pour définir l’heure de création des étendues au moment où les données ont été créées. L’utilisation du temps de création comme critère de partitionnement d’ingestion peut vieillir vos données conformément à vos stratégies de cache et de rétention , et rendre les filtres de temps plus efficaces.
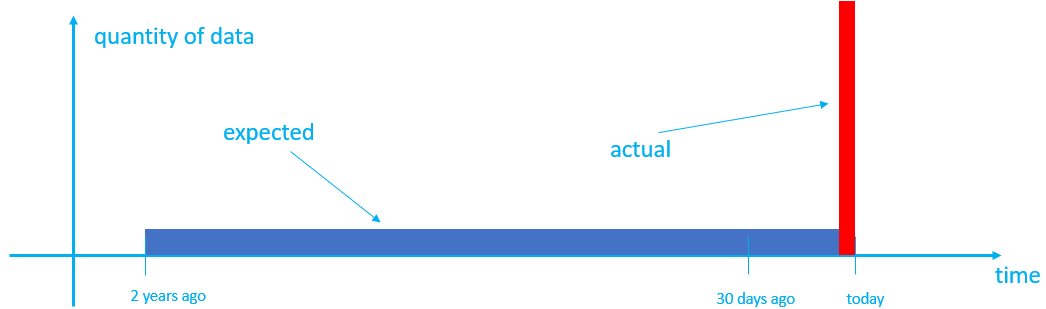
Par défaut, l’heure de création des étendues est définie sur l’heure à laquelle les données sont ingérées, ce qui peut ne pas produire le comportement attendu. Par exemple, supposons que vous disposez d’une table qui a une période de cache de 30 jours et une période de rétention de deux ans. Dans le flux normal, les données ingérées à mesure qu’elles sont produites sont mises en cache pendant 30 jours, puis déplacées vers le stockage à froid. Après deux ans, en fonction de son temps de création, les données plus anciennes sont supprimées un jour à la fois. Toutefois, si vous ingérez deux années de données historiques où, par défaut, les données sont marquées avec le temps de création, car elles sont ingérées. Cela peut ne pas produire le résultat souhaité, car :
- Toutes les données se trouvent dans le cache et restent là pendant 30 jours, en utilisant plus de cache que prévu.
- Les données plus anciennes ne sont pas supprimées un jour à la fois ; par conséquent, les données sont conservées dans le cluster pendant plus longtemps que nécessaire et, après deux ans, sont toutes supprimées à la fois.
- Les données, précédemment regroupées par date dans le système source, peuvent désormais être regroupées dans la même mesure, ce qui entraîne des requêtes inefficaces.
Dans cet article, vous allez apprendre à partitionner des données historiques :
Utilisation de la propriété d’ingestion
creationTimependant l’ingestion (recommandé)Dans la mesure du possible, ingérer des données historiques à l’aide de la
creationTimepropriété d’ingestion, ce qui vous permet de définir l’heure de création des étendues en l’extrayant du chemin d’accès du fichier ou de l’objet blob. Si votre structure de dossiers n’utilise pas de modèle de date de création, nous vous recommandons de restructurer votre chemin d’accès de fichier ou d’objet blob pour refléter l’heure de création. À l’aide de cette méthode, les données sont ingérées dans la table avec l’heure de création correcte, et les périodes de cache et de rétention sont appliquées correctement.Remarque
Par défaut, les étendues sont partitionnée par heure de création (ingestion) et, dans la plupart des cas, il n’est pas nécessaire de définir une stratégie de partitionnement de données.
Utilisation d’une stratégie de partitionnement après l’ingestion
Si vous ne pouvez pas utiliser la
creationTimepropriété d’ingestion, par exemple si vous ingestionnez des données à l’aide du connecteur Azure Cosmos DB où vous ne pouvez pas contrôler le temps de création ou si vous ne pouvez pas restructurer votre structure de dossiers, vous pouvez repartitionner la table après l’ingestion pour obtenir le même effet à l’aide de la stratégie de partitionnement. Toutefois, cette méthode peut nécessiter une certaine évaluation et une erreur pour optimiser les propriétés de stratégie et est moins efficace que l’utilisation de lacreationTimepropriété d’ingestion. Nous vous recommandons uniquement cette méthode lors de l’utilisation de lacreationTimepropriété d’ingestion.
Prérequis
- Un compte Microsoft ou une identité utilisateur Microsoft Entra. Un abonnement Azure n’est pas requis.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Un compte de stockage.
- Pour la méthode recommandée d’utilisation de la
creationTimepropriété d’ingestion pendant l’ingestion, installez LightIngest.
Ingérer des données d’historique
Nous vous recommandons vivement de partitionner les données historiques à l’aide de la creationTime propriété d’ingestion pendant l’ingestion. Toutefois, si vous ne pouvez pas utiliser cette méthode, vous pouvez repartitionner la table après l’ingestion à l’aide d’une stratégie de partitionnement.
LightIngest peut être utile pour charger des données historiques à partir d’un système de stockage existant vers Azure Data Explorer. Bien que vous puissiez générer votre propre commande à l’aide de la liste des arguments de ligne de commande, cet article vous montre comment générer automatiquement cette commande via un Assistant d’ingestion. Outre la création de la commande, vous pouvez utiliser ce processus pour créer une nouvelle table et un mappage de schéma. Cet outil déduit le mappage de schéma à partir de votre jeu de données.
Destination
Dans l’interface utilisateur web d’Azure Data Explorer, dans le menu de gauche, sélectionnez Requête.
Cliquez avec le bouton droit sur la base de données dans laquelle vous souhaitez ingérer les données, puis sélectionnez LightIngest.

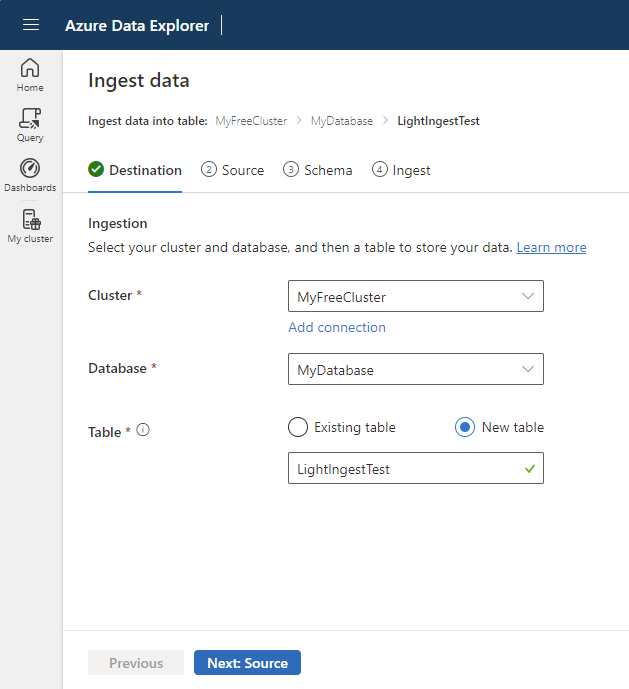
La fenêtre De données d’ingestion s’ouvre avec l’onglet Destination sélectionné. Les champs Cluster et Base de données sont remplis automatiquement.
Sélectionner la table cible. Si vous souhaitez ingérer des données dans une nouvelle table, sélectionnez Nouvelle table, puis entrez un nom de table.
Remarque
Les noms de tables peuvent comporter jusqu’à 1024 caractères, y compris des espaces, des caractères alphanumériques, des traits d’union et des traits de soulignement. Les caractères spéciaux ne sont pas pris en charge.
Sélectionnez Suivant : Source.

Source
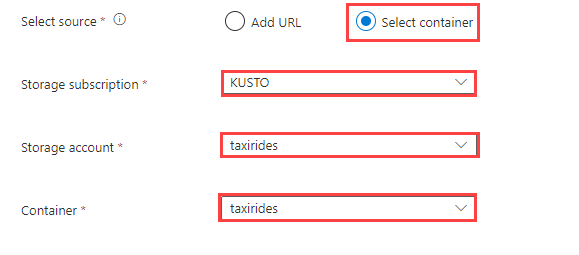
Sous Sélectionner une source, sélectionnez Ajouter une URL ou Sélectionner un conteneur.
Lors de l’ajout d’une URL, sous Lien vers la source, spécifiez la clé de compte ou l’URL SAP d’un conteneur. Vous pouvez créer l’URL SAP manuellement ou automatiquement.
Lorsque vous sélectionnez un conteneur dans votre compte de stockage, sélectionnez votre abonnement de stockage, votre compte de stockage et conteneur dans les menus déroulants.
Remarque
L’ingestion prend en charge une taille de fichier maximale de 6 Go. Nous vous recommandons d’ingérer des fichiers entre 100 Mo et 1 Go.
Sélectionnez Paramètres avancés pour définir des paramètres supplémentaires pour le processus d’ingestion à l’aide de LightIngest.
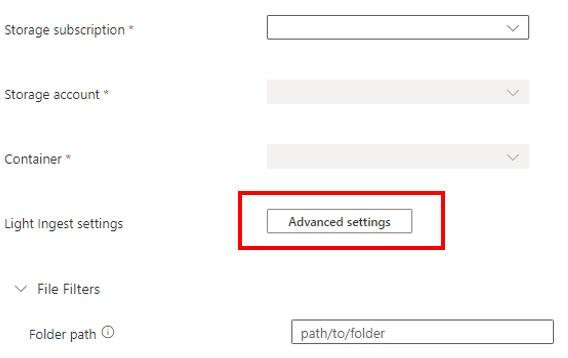
Dans le volet Configuration avancée , définissez les paramètres LightIngest en fonction du tableau suivant.
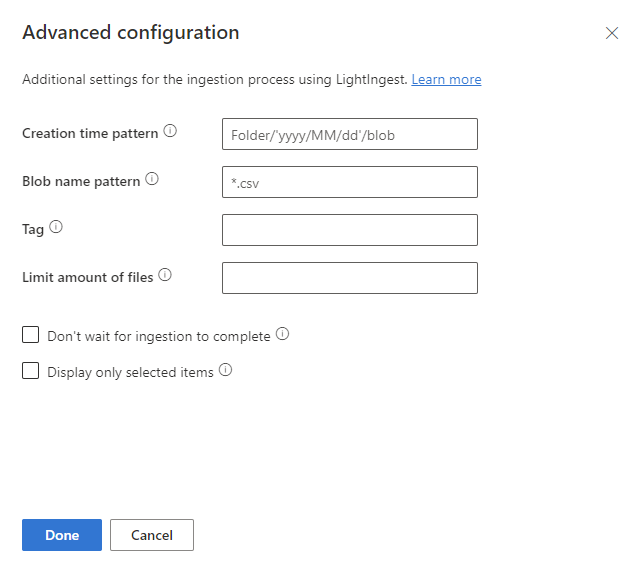
Propriété Description Modèle de temps de création Spécifiez le remplacement de la propriété d’heure d’ingestion de l’étendue créée par un modèle, par exemple pour appliquer une date basée sur la structure de dossiers du conteneur. Consultez aussi Modèle d’heure de création. Modèle de nom d’objet blob Spécifiez le modèle utilisé pour identifier les fichiers à ingérer. Ingérez tous les fichiers qui correspondent au modèle de nom d’objet blob dans le conteneur donné. Prend en charge les caractères génériques. Nous vous recommandons d’inclure entre guillemets doubles. Graphique avec indicateur Une étiquette affectée aux données ingérées. L’étiquette peut être n’importe quelle chaîne. Limiter la quantité de fichiers Spécifiez le nombre de fichiers qui peuvent être ingérés. Ingère les premiers nfichiers qui correspondent au modèle de nom d’objet blob, jusqu’au nombre spécifié.N’attendez pas la fin de l’ingestion Si cette option est définie, met en file d’attente les objets blob pour ingestion sans superviser le processus d’ingestion. Si elle n’est pas définie, LightIngest continue à interroger l’état de l’ingestion jusqu’à ce que celle-ci soit terminée. Afficher uniquement les éléments sélectionnés Liste les fichiers dans le conteneur, mais ne les ingère pas. Sélectionnez Terminé pour revenir à l’onglet Source .
Si vous le souhaitez, sélectionnez Filtres de fichiers pour filtrer les données pour ingérer uniquement des fichiers dans un chemin d’accès de dossier spécifique ou avec une extension de fichier particulière.
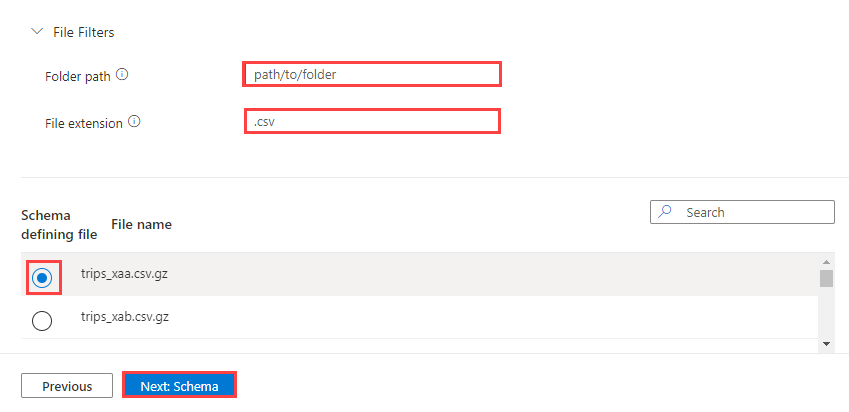
Par défaut, l’un des fichiers du conteneur est sélectionné de manière aléatoire et utilisé pour générer le schéma de la table.
Si vous le souhaitez, sous Schéma définissant le fichier, vous pouvez spécifier le fichier à utiliser.
Sélectionnez Suivant : Schéma pour afficher et modifier la configuration des colonnes de votre table.
schéma
L’onglet schéma fournit un aperçu des données.
Pour générer la commande LightIngest, sélectionnez Suivant : Démarrer l’ingestion.
Si vous le souhaitez :
- Modifiez le format de données déduit automatiquement en sélectionnant le format souhaité dans le menu déroulant.
- Modifiez le nom de mappage déduit automatiquement. Vous pouvez utiliser des caractères alphanumériques et des traits de soulignement. Les espaces, les caractères spéciaux et les traits d’Union ne sont pas pris en charge.
- Lorsque vous utilisez une table existante, vous pouvez sélectionner l’option Conserver le schéma de la table actuelle si le schéma de la table correspond au format sélectionné.
- Sélectionnez Visionneuse de commandes pour afficher et copier les commandes automatiques générées à partir de vos entrées.
- Modifier les colonnes. Sous Aperçu des données partielles, sélectionnez les menus déroulants de colonne pour modifier différents aspects de la table.
Les modifications que vous pouvez apporter dans une table dépendent des paramètres suivants :
- Si le type de la table est nouveau ou existant
- Si le type du mappage est nouveau ou existant
| Type de la table | Type de mappage | Ajustements disponibles |
|---|---|---|
| Nouvelle table | Nouveau mappage | Modifier le type de données, Renommer la colonne, Nouvelle colonne, Supprimer la colonne, Mettre à jour la colonne, Trier par ordre croissant, Trier par ordre décroissant |
| Table existante | Nouveau mappage | Nouvelle colonne (sur laquelle vous pouvez ensuite modifier le type de données, renommer et mettre à jour), Mettre à jour la colonne, Tri croissant, Tri décroissant |
| Mappage existant | Tri croissant, Tri décroissant |
Notes
Lorsque vous ajoutez une nouvelle colonne ou mettez à jour une colonne, vous pouvez modifier les transformations de mappage. Pour plus d’informations, consultez Transformations de mappage.
Ingérer
Une fois la table, le mappage et la commande LightIngest marqués avec des coches vertes, sélectionnez l’icône de copie en haut à droite de la zone de commande Générée pour copier la commande LightIngest générée.
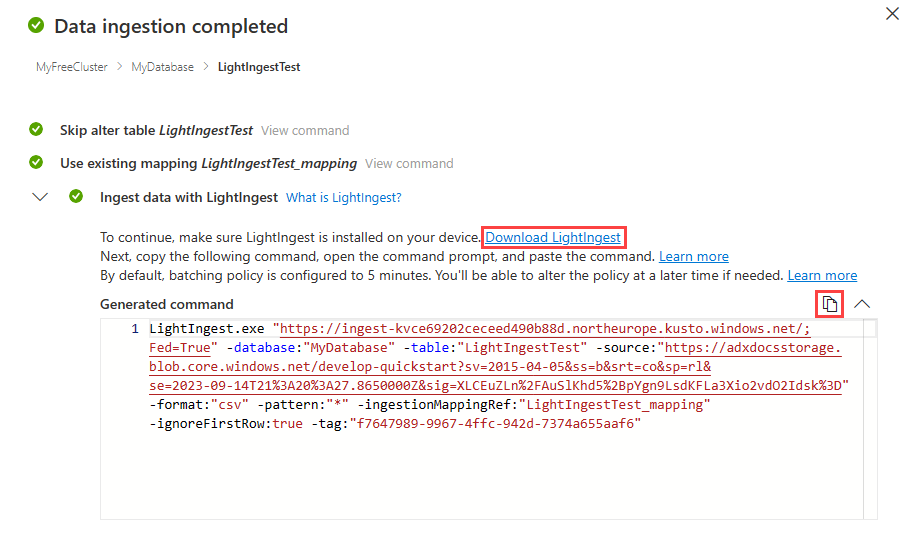
Remarque
Si nécessaire, vous pouvez télécharger l’outil LightIngest en sélectionnant Télécharger LightIngest.
Pour terminer le processus d’ingestion, vous devez exécuter LightIngest à l’aide de la commande copiée.
