Interroger des données dans Azure Data Lake à l’aide d’Azure Data Explorer
Azure Data Lake Storage est une solution Data Lake hautement évolutive et économique pour l’analytique Big Data. Elle combine la puissance d’un système de fichiers hautes performances à grande échelle et la rentabilité afin de réduire le temps nécessaire pour accéder aux insights. Data Lake Storage Gen2 étend les fonctionnalités de Stockage Blob Azure et est optimisé pour les charges de travail analytiques.
Azure Data Explorer s’intègre au Stockage Blob Azure et à Azure Data Lake Storage (Gen1 et Gen2) pour offrir un accès rapide, en cache et indexé aux données stockées dans un stockage externe. Vous pouvez analyser et interroger des données sans ingestion préalable dans Azure Data Explorer. Vous pouvez également interroger simultanément des données externes ingérées ou non ingérées. Pour plus d’informations, consultez Créer une table externe à l’aide de l’Assistant de l’interface utilisateur web d’Azure Data Explorer. Pour une brève vue d’ensemble, consultez Tables externes.
Conseil
Pour des requêtes plus performantes, l'ingestion des données dans Azure Data Explorer est requise. La possibilité d’interroger des données externes sans ingestion préalable doit être réservée aux données historiques ou aux données rarement interrogées. Pour obtenir de meilleurs résultats, optimisez les performances de vos requêtes de données externes.
Créer une table externe
Supposons que vous disposiez d’un grand nombre de fichiers CSV contenant des informations historiques sur des produits stockés dans un entrepôt, et que vous vouliez effectuer une analyse rapide afin de trouver les cinq produits les plus populaires de l’année dernière. Dans cet exemple, les fichiers CSV se présentent comme suit :
| Timestamp | ProductId | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD Floppy Disk |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
Les fichiers sont stockés dans le Stockage Blob Azure mycompanystorage sous un conteneur nommé archivedproducts, partitionnés par date :
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Pour exécuter une requête KQL directement sur ces fichiers CSV, utilisez la commande .create external table pour définir une table externe dans Azure Data Explorer. Pour plus d’informations sur les options de commande de création de table externe, consultez Commandes de table externe.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
La table externe est maintenant visible dans le volet de gauche de l’interface utilisateur web d’Azure Data Explorer :
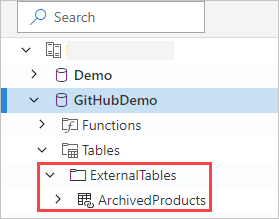
Autorisations de table externe
- L’utilisateur de base de données peut créer une table externe. Le créateur de la table en devient automatiquement l’administrateur.
- L'administrateur de cluster, base de données ou table peut modifier une table existante.
- Tout utilisateur ou lecteur de base de données peut interroger une table externe.
Interrogation d’une table externe
Une fois qu’une table externe est définie, la fonction external_table() peut être utilisée pour y faire référence. Le reste de la requête est du langage de requête Kusto standard.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Interrogation simultanée de données externes et ingérées
Vous pouvez utiliser la même requête pour interroger des tables externes et des tables de données ingérées. Vous pouvez joindre (join) ou unir (union) la table externe à d’autres données issues d’Azure Data Explorer, de serveurs SQL ou d’autres sources. Utilisez une let( ) statement pour attribuer un nom abrégé à une référence de table externe.
Dans l’exemple ci-dessous, Products est une table de données ingérées et ArchivedProducts est une table externe que nous avons définie précédemment :
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Interrogation de formats de données hiérarchiques
Azure Data Explorer permet d’interroger des formats hiérarchiques, comme JSON, Parquet, Avro et ORC. Pour mapper un schéma de données hiérarchiques à un schéma de table externe (s’il est différent), utilisez des commandes de mappages de tables externes. Par exemple, si vous voulez interroger les fichiers journaux JSON au format suivant :
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
La définition de la table externe ressemble à ceci :
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Définissez un mappage JSON qui mappe les champs de données aux champs de définition de la table externe :
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Quand vous interrogez la table externe, le mappage est appelé et les données pertinentes sont mappées aux colonnes de la table externe :
external_table('ApiCalls') | take 10
Pour plus d’informations sur la syntaxe de mappage, consultez Mappages de données.
Interroger la table TaxiRides dans le cluster d'aide
Utilisez le cluster de test appelé help pour tester différentes fonctionnalités Azure Data Explorer. Le cluster help contient une définition de table externe pour un jeu de données des taxis de New York contenant des milliards de courses.
Créer une table externe TaxiRides
Cette section présente la requête utilisée pour créer la table externe TaxiRides du cluster help. Cette table ayant déjà été créée, vous pouvez ignorer cette section et interroger directement les données de la table externe TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Pour accéder à la table TaxiRides créée, examinez le volet gauche de l’interface utilisateur web d’Azure Data Explorer :
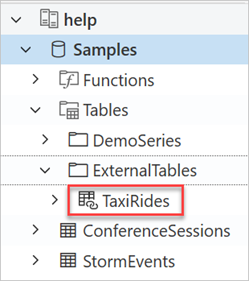
Interroger les données de la table externe TaxiRides
Connectez-vous à https://dataexplorer.azure.com/clusters/help/databases/Samples.
Interroger la table externe TaxiRides sans partitionnement
Exécutez cette requête sur la table externe TaxiRides pour afficher les courses pour chaque jour de la semaine, dans l’ensemble du jeu de données.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Cette requête affiche le jour le plus chargé de la semaine. Les données n’étant pas partitionnées, plusieurs minutes peuvent être nécessaires pour que la requête retourne des résultats.
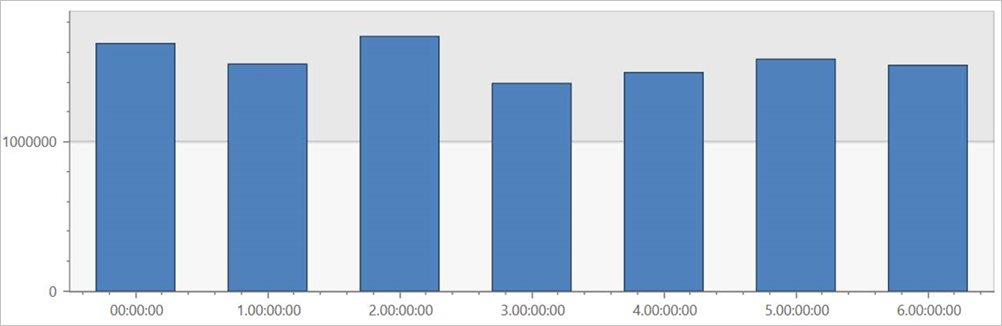
Interroger la table externe TaxiRides avec partitionnement
Exécutez cette requête sur la table externe TaxiRides pour afficher les types de taxis (jaunes ou verts) utilisés en janvier 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Cette requête utilise le partitionnement, ce qui optimise le temps de requête et le niveau de performance. La requête filtre une colonne partitionnée (pickup_datetime) et renvoie les résultats en quelques secondes.
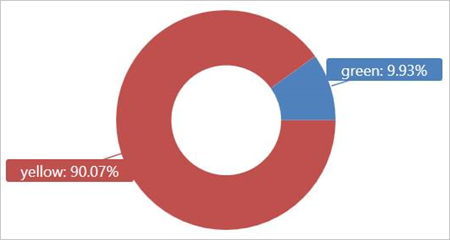
Vous pouvez écrire d’autres requêtes à exécuter sur la table externe TaxiRides et en savoir plus sur les données.
Optimiser les performances de vos requêtes
Optimisez les performances de vos requêtes dans le lac en observant les bonnes pratiques suivantes pour interroger des données externes.
Format de données
- Utilisez un format columnar pour les requêtes analytiques, pour les raisons suivantes :
- Seules les colonnes appropriées à une requête peuvent être lues.
- Les techniques d’encodage de colonne peuvent réduire considérablement la taille des données.
- Azure Data Explorer prend en charge les formats en colonnes Parquet et ORC. Le format Parquet est suggéré en raison de son implémentation optimisée.
Région Azure
Vérifiez que les données externes se trouvent dans la même région Azure que votre cluster Azure Data Explorer. Cette configuration réduit le coût et le temps d’extraction des données.
Taille du fichier
La taille de fichier optimale est de plusieurs centaines de Mo (jusqu’à 1 Go) par fichier. Évitez d’avoir un grand nombre de petits fichiers qui nécessitent une surcharge inutile, par exemple un processus d’énumération de fichiers plus lent et une utilisation limitée du format en colonnes. Le nombre de fichiers doit être supérieur au nombre de cœurs de processeur dans votre cluster Azure Data Explorer.
Compression
Utilisez la compression pour réduire la quantité de données extraites du stockage distant. Pour le format Parquet, utilisez le mécanisme de compression Parquet interne qui compresse les groupes de colonnes séparément, ce qui vous permet de les lire séparément. Pour valider l’utilisation du mécanisme de compression, vérifiez que les fichiers sont nommés comme suit : <nom_fichier>.gz.parquet ou <nom_fichier>.snappy.parquet, et non pas <nom_fichier>.parquet.gz.
Partitionnement
Organisez vos données en utilisant des partitions de « dossiers » qui permettent à la requête d’ignorer les chemins non pertinents. Lors de la planification d’un partitionnement, tenez compte de la taille des fichiers et des filtres courants utilisés dans vos requêtes, comme l’horodatage ou l’ID de locataire.
Taille de la machine virtuelle
Sélectionnez les références SKU de machine virtuelle avec plus de cœurs et un débit réseau plus élevé (la mémoire est moins importante). Pour plus d’informations, consultez Sélectionner la bonne référence SKU de machine virtuelle pour votre cluster Azure Data Explorer.