Informations de référence sur le schéma de configuration du générateur d’API de données
Le moteur du générateur d’API de données nécessite un fichier de configuration. Le fichier de configuration du Générateur d’API de données fournit une approche structurée et complète de la configuration de votre API, détaillant tout, des variables environnementales aux configurations spécifiques à l’entité. Ce document au format JSON commence par une propriété $schema. Cette configuration valide le document.
Les propriétés database-type et connection-string garantir une intégration transparente avec les systèmes de base de données, d’Azure SQL Database à l’API NoSQL Cosmos DB.
Le fichier de configuration peut inclure des options telles que :
- Informations de connexion et de service de base de données
- Options de configuration globales et d’exécution
- Ensemble d’entités exposées
- Méthode d’authentification
- Règles de sécurité requises pour accéder aux identités
- Règles de mappage de noms entre l’API et la base de données
- Relations entre les entités qui ne peuvent pas être déduites
- Fonctionnalités uniques pour des services de base de données spécifiques
Vue d’ensemble de la syntaxe
Voici une répartition rapide des « sections » principales dans un fichier de configuration.
{
"$schema": "...",
"data-source": { ... },
"data-source-files": [ ... ],
"runtime": {
"rest": { ... },
"graphql": { .. },
"host": { ... },
"cache": { ... },
"telemetry": { ... },
"pagination": { ... }
}
"entities": [ ... ]
}
Propriétés de niveau supérieur
Voici la description des propriétés de niveau supérieur dans un format de tableau :
| Propriété | Description |
|---|---|
| $schema | Spécifie le schéma JSON pour la validation, en veillant à ce que la configuration respecte le format requis. |
| de source de données | Contient les détails relatifs au type de base de données et à la chaîne de connexion , nécessaire pour établir la connexion de base de données. |
| des fichiers sources de données | Tableau facultatif spécifiant d’autres fichiers de configuration susceptibles de définir d’autres sources de données. |
| runtime | Configure les comportements et paramètres d’exécution, y compris les sous-propriétés pour REST, GraphQL, hôte, cacheet de télémétrie. |
| entités | Définit l’ensemble d’entités (tables de base de données, vues, etc.) exposées via l’API, y compris leurs mappages de , les autorisations et les relations . |
Exemples de configurations
Voici un exemple de fichier de configuration qui inclut uniquement les propriétés requises pour une seule entité simple. Cet exemple est destiné à illustrer un scénario minimal.
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')"
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Pour obtenir un exemple de scénario plus complexe, consultez l’exemple de configuration de bout en bout.
Environnements
Le fichier de configuration du générateur d’API de données peut prendre en charge les scénarios dans lesquels vous devez prendre en charge plusieurs environnements, comme le fichier appSettings.json dans ASP.NET Core. Le framework fournit trois valeurs d’environnement courantes ; Development, Staginget Production; mais vous pouvez choisir d’utiliser n’importe quelle valeur d’environnement que vous choisissez. L’environnement utilisé par le générateur d’API de données doit être configuré à l’aide de la variable d’environnement DAB_ENVIRONMENT.
Prenons un exemple dans lequel vous souhaitez une configuration de base et une configuration spécifique au développement. Cet exemple nécessite deux fichiers de configuration :
| Environnement | |
|---|---|
| dab-config.json | Base |
| dab-config.Development.json | Développement |
Pour utiliser la configuration spécifique au développement, vous devez définir la variable d’environnement DAB_ENVIRONMENT sur Development.
Les fichiers de configuration spécifiques à l’environnement remplacent les valeurs de propriété dans le fichier de configuration de base. Dans cet exemple, si la valeur connection-string est définie dans les deux fichiers, la valeur du fichier *.Development.json est utilisée.
Reportez-vous à cette matrice pour mieux comprendre la valeur utilisée en fonction de l’endroit où cette valeur est spécifiée (ou non spécifiée) dans un fichier.
| spécifié dans le de configuration de base | Non spécifié dans la configuration de base | |
|---|---|---|
| spécifié dans la configuration de l’environnement actuel | Environnement actuel | Environnement actuel |
| Non spécifié dans la configuration de l’environnement actuel | Base | Aucun |
Pour obtenir un exemple d’utilisation de plusieurs fichiers de configuration, consultez utiliser le générateur d’API de données avec des environnements.
Propriétés de configuration
Cette section inclut toutes les propriétés de configuration possibles disponibles pour un fichier de configuration.
Schéma
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
$root |
$schema |
corde | ✔️ Oui | Aucun |
Chaque fichier de configuration commence par une propriété $schema, en spécifiant le schéma JSON pour validation.
Format
{
"$schema": <string>
}
Exemples
Les fichiers de schéma sont disponibles pour les versions 0.3.7-alpha ultérieures à des URL spécifiques, ce qui vous permet d’utiliser la version correcte ou le schéma disponible le plus récent.
https://github.com/Azure/data-api-builder/releases/download/<VERSION>-<suffix>/dab.draft.schema.json
Remplacez VERSION-suffix par la version souhaitée.
https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json
La dernière version du schéma est toujours disponible à https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json.
Voici quelques exemples de valeurs de schéma valides.
| Version | URI | Description |
|---|---|---|
| 0.3.7-alpha | https://github.com/Azure/data-api-builder/releases/download/v0.3.7-alpha/dab.draft.schema.json |
Utilise le schéma de configuration à partir d’une version alpha de l’outil. |
| 0.10.23 | https://github.com/Azure/data-api-builder/releases/download/v0.10.23/dab.draft.schema.json |
Utilise le schéma de configuration pour une version stable de l’outil. |
| Dernier | https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json |
Utilise la dernière version du schéma de configuration. |
Note
Les versions du générateur d’API de données antérieures à 0.3.7-alpha peuvent avoir un URI de schéma différent.
Source de données
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
$root |
data-source |
corde | ✔️ Oui | Aucun |
La section data-source définit la base de données et l’accès à la base de données via la chaîne de connexion. Il définit également les options de base de données. La propriété data-source configure les informations d’identification nécessaires pour se connecter à la base de données de stockage. La section data-source décrit la connectivité de la base de données back-end, en spécifiant les database-type et les connection-string.
Format
{
"data-source": {
"database-type": <string>,
"connection-string": <string>,
// mssql-only
"options": {
"set-session-context": <true> (default) | <false>
},
// cosmosdb_nosql-only
"options": {
"database": <string>,
"container": <string>,
"schema": <string>
}
}
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
database-type |
✔️ Oui | chaîne d’énumération |
connection-string |
✔️ Oui | corde |
options |
❌ Non | objet |
Type de base de données
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
data-source |
database-type |
enum-string | ✔️ Oui | Aucun |
Chaîne d’énumération utilisée pour spécifier le type de base de données à utiliser comme source de données.
Format
{
"data-source": {
"database-type": <string>
}
}
Valeurs de type
La propriété type indique le type de base de données back-end.
| Type | Description | Version minimale |
|---|---|---|
mssql |
Azure SQL Database | Aucun |
mssql |
Azure SQL MI | Aucun |
mssql |
SQL Server | SQL 2016 |
sqldw |
Azure SQL Data Warehouse | Aucun |
postgresql |
PostgreSQL | v11 |
mysql |
MySQL | v8 |
cosmosdb_nosql |
Azure Cosmos DB pour NoSQL | Aucun |
cosmosdb_postgresql |
Azure Cosmos DB pour PostgreSQL | Aucun |
Chaîne de connexion
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
data-source |
connection-string |
corde | ✔️ Oui | Aucun |
Chaîne valeur contenant une chaîne de connexion valide pour se connecter au service de base de données cible. Chaîne de connexion ADO.NET pour se connecter à la base de données back-end. Pour plus d’informations, consultez ADO.NET chaînes de connexion.
Format
{
"data-source": {
"connection-string": <string>
}
}
Résilience des connexions
Le générateur d’API de données retente automatiquement les demandes de base de données après la détection d’erreurs temporaires. La logique de nouvelle tentative suit une stratégie d’interruption exponentielle où le nombre maximal de nouvelles tentatives est cinq. Durée d’interruption de nouvelle tentative après que les demandes suivantes sont calculées à l’aide de cette formule (en supposant que la tentative de nouvelle tentative actuelle est r) : $r^2$
À l’aide de cette formule, vous pouvez calculer le temps de chaque nouvelle tentative en secondes.
| Secondes | |
|---|---|
| Premier | 2 |
| Second | 4 |
| troisième | 8 |
| Quatrième | 16 |
| Cinquième | 32 |
Azure SQL et SQL Server
Le générateur d’API de données utilise la bibliothèque SqlClient pour se connecter à Azure SQL ou SQL Server à l’aide de la chaîne de connexion que vous fournissez dans le fichier de configuration. Une liste de toutes les options de chaîne de connexion prises en charge est disponible ici : propriété SqlConnection.ConnectionString.
Le générateur d’API de données peut également se connecter à la base de données cible à l’aide d’identités de service managées (MSI) lorsque le générateur d’API de données est hébergé dans Azure. La DefaultAzureCredential définie dans Azure.Identity bibliothèque est utilisée pour vous connecter à l’aide d’identités connues lorsque vous ne spécifiez pas de nom d’utilisateur ou de mot de passe dans votre chaîne de connexion. Pour plus d’informations, consultez DefaultAzureCredential exemples.
'identité managée affectée par l’utilisateur (UMI) : ajoutez le d’authentificationet propriétés d’ID utilisateur à votre chaîne de connexion tout en remplaçant l’ID client de votre identité managée affectée par l’utilisateur :. identité managée affectée par le système (SMI) : ajoutez la propriétéAuthentication et excluez les argumentsUserId et Mot de passe de votre chaîne de connexion :. L’absence du UserId et propriétés de chaîne de connexion mot de passe signalent à DAB de s’authentifier à l’aide d’une identité managée affectée par le système.
Pour plus d’informations sur la configuration d’une identité de service managé avec Azure SQL ou SQL Server, consultez identités managées dans Microsoft Entra pour Azure SQL.
Exemples
La valeur utilisée pour la chaîne de connexion dépend en grande partie du service de base de données utilisé dans votre scénario. Vous pouvez toujours choisir de stocker la chaîne de connexion dans une variable d’environnement et de l’accéder à l’aide de la fonction @env().
| Valeur | Description | |
|---|---|---|
| Utiliser la valeur de chaîne Azure SQL Database | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>; |
Chaîne de connexion à un compte Azure SQL Database. Pour plus d’informations, consultez chaînes de connexion Azure SQL Database. |
| Utiliser la valeur de chaîne Azure Database pour PostgreSQL | Server=<server-address>;Database=<name-of-database>;Port=5432;User Id=<username>;Password=<password>;Ssl Mode=Require; |
Chaîne de connexion à un compte Azure Database pour PostgreSQL. Pour plus d’informations, consultez chaînes de connexion Azure Database pour PostgreSQL. |
| Utiliser la valeur de chaîne Azure Cosmos DB pour NoSQL | AccountEndpoint=<endpoint>;AccountKey=<key>; |
Chaîne de connexion à un compte Azure Cosmos DB pour NoSQL. Pour plus d’informations, consultez chaînes de connexion NoSQL Azure Cosmos DB pour NoSQL. |
| Utiliser la valeur de chaîne Azure Database pour MySQL | Server=<server-address>;Database=<name-of-database>;User ID=<username>;Password=<password>;Sslmode=Required;SslCa=<path-to-certificate>; |
Chaîne de connexion à un compte Azure Database pour MySQL. Pour plus d’informations, consultez chaînes de connexion Azure Database pour MySQL. |
| variable d’environnement Access | @env('SQL_CONNECTION_STRING') |
Accédez à une variable d’environnement à partir de l’ordinateur local. Dans cet exemple, la variable d’environnement SQL_CONNECTION_STRING est référencée. |
Pourboire
En guise de meilleure pratique, évitez de stocker des informations sensibles dans votre fichier de configuration. Si possible, utilisez @env() pour référencer des variables d’environnement. Pour plus d’informations, consultez @env() fonction.
Ces exemples illustrent simplement comment chaque type de base de données peut être configuré. Votre scénario peut être unique, mais cet exemple est un bon point de départ. Remplacez les espaces réservés tels que myserver, myDataBase, myloginet myPassword par les valeurs réelles propres à votre environnement.
mssql"data-source": { "database-type": "mssql", "connection-string": "$env('my-connection-string')", "options": { "set-session-context": true } }-
format de chaîne de connexion classique:
"Server=tcp:myserver.database.windows.net,1433;Initial Catalog=myDataBase;Persist Security Info=False;User ID=mylogin;Password=myPassword;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"
-
format de chaîne de connexion classique:
postgresql"data-source": { "database-type": "postgresql", "connection-string": "$env('my-connection-string')" }-
format de chaîne de connexion classique:
"Host=myserver.postgres.database.azure.com;Database=myDataBase;Username=mylogin@myserver;Password=myPassword;"
-
format de chaîne de connexion classique:
mysql"data-source": { "database-type": "mysql", "connection-string": "$env('my-connection-string')" }-
format de chaîne de connexion classique:
"Server=myserver.mysql.database.azure.com;Database=myDataBase;Uid=mylogin@myserver;Pwd=myPassword;"
-
format de chaîne de connexion classique:
cosmosdb_nosql"data-source": { "database-type": "cosmosdb_nosql", "connection-string": "$env('my-connection-string')", "options": { "database": "Your_CosmosDB_Database_Name", "container": "Your_CosmosDB_Container_Name", "schema": "Path_to_Your_GraphQL_Schema_File" } }-
format de chaîne de connexion classique:
"AccountEndpoint=https://mycosmosdb.documents.azure.com:443/;AccountKey=myAccountKey;"
-
format de chaîne de connexion classique:
cosmosdb_postgresql"data-source": { "database-type": "cosmosdb_postgresql", "connection-string": "$env('my-connection-string')" }-
format de chaîne de connexion classique:
"Host=mycosmosdb.postgres.database.azure.com;Database=myDataBase;Username=mylogin@mycosmosdb;Password=myPassword;Port=5432;SSL Mode=Require;"
-
format de chaîne de connexion classique:
Note
Les « options » spécifiées telles que database, containeret schema sont spécifiques à l’API NoSQL d’Azure Cosmos DB plutôt qu’à l’API PostgreSQL. Pour Azure Cosmos DB à l’aide de l’API PostgreSQL, les « options » n’incluent pas database, containerou schema comme dans l’installation de NoSQL.
Options
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
data-source |
options |
objet | ❌ Non | Aucun |
Section facultative des paramètres de valeur de clé supplémentaire pour des connexions de base de données spécifiques.
Indique si la section options est requise ou non dépend en grande partie du service de base de données utilisé.
Format
{
"data-source": {
"options": {
"<key-name>": <string>
}
}
}
options : { set-session-context : boolean }
Pour Azure SQL et SQL Server, le générateur d’API de données peut tirer parti de SESSION_CONTEXT pour envoyer des métadonnées spécifiées par l’utilisateur à la base de données sous-jacente. Ces métadonnées sont disponibles pour le générateur d’API de données en vertu des revendications présentes dans le jeton d’accès. Les données SESSION_CONTEXT sont disponibles pour la base de données pendant la connexion de base de données jusqu’à ce que cette connexion soit fermée. Pour plus d’informations, consultez contexte de session.
Exemple de procédure stockée SQL :
CREATE PROC GetUser @userId INT AS
BEGIN
-- Check if the current user has access to the requested userId
IF SESSION_CONTEXT(N'user_role') = 'admin'
OR SESSION_CONTEXT(N'user_id') = @userId
BEGIN
SELECT Id, Name, Age, IsAdmin
FROM Users
WHERE Id = @userId;
END
ELSE
BEGIN
RAISERROR('Unauthorized access', 16, 1);
END
END;
Exemple de configuration JSON :
{
"$schema": "https://github.com/Azure/data-api-builder/releases/latest/download/dab.draft.schema.json",
"data-source": {
"database-type": "mssql",
"connection-string": "@env('SQL_CONNECTION_STRING')",
"options": {
"set-session-context": true
}
},
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "authenticated",
"actions": ["execute"]
}
]
}
}
}
Explication:
procédure stockée (
GetUser):- La procédure vérifie la
SESSION_CONTEXTpour vérifier si l’appelant a le rôleadminou correspond auuserIdfourni. - L’accès non autorisé entraîne une erreur.
- La procédure vérifie la
de configuration JSON :
-
set-session-contextest activé pour transmettre des métadonnées utilisateur à partir du jeton d’accès à la base de données. - La propriété
parametersmappe le paramètreuserIdrequis par la procédure stockée. - Le bloc
permissionsgarantit que seuls les utilisateurs authentifiés peuvent exécuter la procédure stockée.
-
Fichiers sources de données
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
$root |
data-source-files |
tableau de chaînes | ❌ Non | Aucun |
Le générateur d’API de données prend en charge plusieurs fichiers de configuration pour différentes sources de données, avec un fichier désigné comme fichier de niveau supérieur gérant les paramètres de runtime. Toutes les configurations partagent le même schéma, ce qui permet runtime paramètres dans un fichier sans erreurs. Les configurations enfants fusionnent automatiquement, mais les références circulaires doivent être évitées. Les entités peuvent être divisées en fichiers distincts pour une meilleure gestion, mais les relations entre les entités doivent se trouver dans le même fichier.
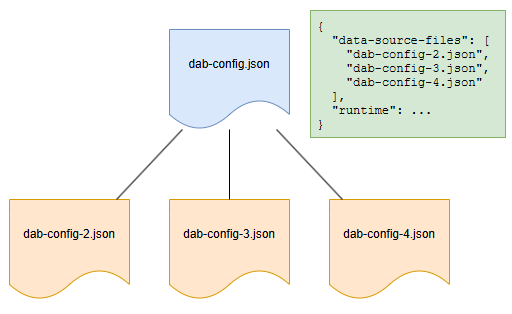
Format
{
"data-source-files": [ <string> ]
}
Considérations relatives au fichier de configuration
- Chaque fichier de configuration doit inclure la propriété
data-source. - Chaque fichier de configuration doit inclure la propriété
entities. - Le paramètre
runtimeest utilisé uniquement à partir du fichier de configuration de niveau supérieur, même s’il est inclus dans d’autres fichiers. - Les fichiers de configuration enfants peuvent également inclure leurs propres fichiers enfants.
- Les fichiers de configuration peuvent être organisés en sous-dossiers comme vous le souhaitez.
- Les noms d’entités doivent être uniques dans tous les fichiers de configuration.
- Les relations entre les entités dans différents fichiers de configuration ne sont pas prises en charge.
Exemples
{
"data-source-files": [
"dab-config-2.json"
]
}
{
"data-source-files": [
"dab-config-2.json",
"dab-config-3.json"
]
}
La syntaxe du sous-dossier est également prise en charge :
{
"data-source-files": [
"dab-config-2.json",
"my-folder/dab-config-3.json",
"my-folder/my-other-folder/dab-config-4.json"
]
}
Duree
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
$root |
runtime |
objet | ✔️ Oui | Aucun |
La section runtime présente les options qui influencent le comportement et les paramètres du runtime pour toutes les entités exposées.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
},
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"allow-introspection": <true> (default) | <false>
},
"host": {
"mode": "production" (default) | "development",
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
},
"cache": {
"enabled": <true> | <false> (default),
"ttl-seconds": <integer; default: 5>
},
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": <string>,
"enabled": <true> | <false> (default)
}
}
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
rest |
❌ Non | objet |
graphql |
❌ Non | objet |
host |
❌ Non | objet |
cache |
❌ Non | objet |
Exemples
Voici un exemple de section runtime avec plusieurs paramètres par défaut courants spécifiés.
{
"runtime": {
"rest": {
"enabled": true,
"path": "/api",
"request-body-strict": true
},
"graphql": {
"enabled": true,
"path": "/graphql",
"allow-introspection": true
},
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": [
"*"
]
},
"authentication": {
"provider": "StaticWebApps",
"jwt": {
"audience": "<client-id>",
"issuer": "<identity-provider-issuer-uri>"
}
}
},
"cache": {
"enabled": true,
"ttl-seconds": 5
},
"pagination": {
"max-page-size": -1 | <integer; default: 100000>,
"default-page-size": -1 | <integer; default: 100>,
"max-response-size-mb": <integer; default: 158>
},
"telemetry": {
"application-insights": {
"connection-string": "<connection-string>",
"enabled": true
}
}
}
}
GraphQL (runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime |
graphql |
objet | ❌ Non | Aucun |
Cet objet définit si GraphQL est activé et si le nom[s] utilisé pour exposer l’entité en tant que type GraphQL. Cet objet est facultatif et utilisé uniquement si le nom ou les paramètres par défaut ne sont pas suffisants. Cette section décrit les paramètres globaux du point de terminaison GraphQL.
Format
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql),
"enabled": <true> (default) | <false>,
"depth-limit": <integer; default: none>,
"allow-introspection": <true> (default) | <false>,
"multiple-mutations": <object>
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
❌ Non | booléen | Vrai |
path |
❌ Non | corde | /graphql (par défaut) |
allow-introspection |
❌ Non | booléen | Vrai |
multiple-mutations |
❌ Non | objet | { create : { enabled : false } } |
Activé (runtime GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.graphql |
enabled |
booléen | ❌ Non | Aucun |
Définit s’il faut activer ou désactiver globalement les points de terminaison GraphQL. Si elle est désactivée globalement, aucune entité n’est accessible via les requêtes GraphQL, quel que soit les paramètres d’entité individuels.
Format
{
"runtime": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
Exemples
Dans cet exemple, le point de terminaison GraphQL est désactivé pour toutes les entités.
{
"runtime": {
"graphql": {
"enabled": false
}
}
}
Limite de profondeur (runtime GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.graphql |
depth-limit |
entier | ❌ Non | Aucun |
Profondeur maximale autorisée de requête d’une requête.
La capacité de GraphQL à gérer des requêtes imbriquées basées sur des définitions de relation est une fonctionnalité incroyable, permettant aux utilisateurs d’extraire des données complexes et associées dans une seule requête. Toutefois, à mesure que les utilisateurs continuent d’ajouter des requêtes imbriquées, la complexité de la requête augmente, ce qui peut éventuellement compromettre les performances et la fiabilité de la base de données et du point de terminaison de l’API. Pour gérer cette situation, la propriété runtime/graphql/depth-limit définit la profondeur maximale autorisée d’une requête GraphQL (et mutation). Cette propriété permet aux développeurs de trouver un équilibre, ce qui permet aux utilisateurs de profiter des avantages des requêtes imbriquées tout en plaçant des limites pour empêcher les scénarios susceptibles de compromettre les performances et la qualité du système.
Exemples
{
"runtime": {
"graphql": {
"depth-limit": 2
}
}
}
Chemin d’accès (runtime GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.graphql |
path |
corde | ❌ Non | « /graphql » |
Définit le chemin d’URL où le point de terminaison GraphQL est mis à disposition. Par exemple, si ce paramètre est défini sur /graphql, le point de terminaison GraphQL est exposé en tant que /graphql. Par défaut, le chemin d’accès est /graphql.
Important
Les sous-chemins ne sont pas autorisés pour cette propriété. Une valeur de chemin personnalisée pour le point de terminaison GraphQL n’est actuellement pas disponible.
Format
{
"runtime": {
"graphql": {
"path": <string> (default: /graphql)
}
}
}
Exemples
Dans cet exemple, l’URI GraphQL racine est /query.
{
"runtime": {
"graphql": {
"path": "/query"
}
}
}
Autoriser l’introspection (runtime GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.graphql |
allow-introspection |
booléen | ❌ Non | Vrai |
Cet indicateur booléen contrôle la possibilité d’effectuer des requêtes d’introspection de schéma sur le point de terminaison GraphQL. L’activation de l’introspection permet aux clients d’interroger le schéma pour obtenir des informations sur les types de données disponibles, les types de requêtes qu’ils peuvent effectuer et les mutations disponibles.
Cette fonctionnalité est utile pendant le développement pour comprendre la structure de l’API GraphQL et pour les outils qui génèrent automatiquement des requêtes. Toutefois, pour les environnements de production, il peut être désactivé pour masquer les détails du schéma de l’API et améliorer la sécurité. Par défaut, l’introspection est activée, ce qui permet une exploration immédiate et complète du schéma GraphQL.
Format
{
"runtime": {
"graphql": {
"allow-introspection": <true> (default) | <false>
}
}
}
Exemples
Dans cet exemple, l’introspection est désactivée.
{
"runtime": {
"graphql": {
"allow-introspection": false
}
}
}
Mutations multiples (runtime GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.graphql |
multiple-mutations |
objet | ❌ Non | Aucun |
Configure toutes les opérations de mutation multiples pour le runtime GraphQL.
Note
Par défaut, plusieurs mutations ne sont pas activées et doivent être configurées explicitement pour être activées.
Format
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
create |
❌ Non | objet |
Mutations multiples - créer (runtime GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.graphql.multiple-mutations |
create |
booléen | ❌ Non | Faux |
Configure plusieurs opérations de création pour le runtime GraphQL.
Format
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": <true> (default) | <false>
}
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
✔️ Oui | booléen | Vrai |
Exemples
L’exemple suivant montre comment activer et utiliser plusieurs mutations dans le runtime GraphQL. Dans ce cas, l’opération de create est configurée pour permettre la création de plusieurs enregistrements dans une seule requête en définissant la propriété runtime.graphql.multiple-mutations.create.enabled sur true.
Exemple de configuration
Cette configuration permet plusieurs mutations create :
{
"runtime": {
"graphql": {
"multiple-mutations": {
"create": {
"enabled": true
}
}
}
},
"entities": {
"User": {
"source": "dbo.Users",
"permissions": [
{
"role": "anonymous",
"actions": ["create"]
}
]
}
}
}
Exemple de mutation GraphQL
À l’aide de la configuration ci-dessus, la mutation suivante crée plusieurs enregistrements User dans une seule opération :
mutation {
createUsers(input: [
{ name: "Alice", age: 30, isAdmin: true },
{ name: "Bob", age: 25, isAdmin: false },
{ name: "Charlie", age: 35, isAdmin: true }
]) {
id
name
age
isAdmin
}
}
REST (runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime |
rest |
objet | ❌ Non | Aucun |
Cette section décrit les paramètres globaux des points de terminaison REST. Ces paramètres servent de valeurs par défaut pour toutes les entités, mais peuvent être substitués par entité dans leurs configurations respectives.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api),
"enabled": <true> (default) | <false>,
"request-body-strict": <true> (default) | <false>
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
❌ Non | booléen | Vrai |
path |
❌ Non | corde | /API |
request-body-strict |
❌ Non | booléen | Vrai |
Activé (runtime REST)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.rest |
enabled |
booléen | ❌ Non | Aucun |
Indicateur booléen qui détermine la disponibilité globale des points de terminaison REST. Si elle est désactivée, les entités ne sont pas accessibles via REST, quels que soient les paramètres d’entité individuels.
Format
{
"runtime": {
"rest": {
"enabled": <true> (default) | <false>,
}
}
}
Exemples
Dans cet exemple, le point de terminaison de l’API REST est désactivé pour toutes les entités.
{
"runtime": {
"rest": {
"enabled": false
}
}
}
Chemin d’accès (runtime REST)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.rest |
path |
corde | ❌ Non | « /api » |
Définit le chemin d’URL pour accéder à tous les points de terminaison REST exposés. Par exemple, la définition de path sur /api rend le point de terminaison REST accessible à /api/<entity>. Les sous-chemins ne sont pas autorisés. Ce champ est facultatif, avec /api comme valeur par défaut.
Note
Lors du déploiement du générateur d’API de données à l’aide d’Static Web Apps (préversion), le service Azure injecte automatiquement le sous-chemin supplémentaire /data-api à l’URL. Ce comportement garantit la compatibilité avec les fonctionnalités d’application web statique existantes. Le point de terminaison résultant serait /data-api/api/<entity>. Cela s’applique uniquement aux applications web statiques.
Format
{
"runtime": {
"rest": {
"path": <string> (default: /api)
}
}
}
Important
Les sous-chemins fournis par l’utilisateur ne sont pas autorisés pour cette propriété.
Exemples
Dans cet exemple, l’URI de l’API REST racine est /data.
{
"runtime": {
"rest": {
"path": "/data"
}
}
}
Pourboire
Si vous définissez une entité Author, le point de terminaison de cette entité serait /data/Author.
Corps de requête strict (runtime REST)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.rest |
request-body-strict |
booléen | ❌ Non | Vrai |
Ce paramètre contrôle la façon dont le corps de la requête pour les opérations de mutation REST (par exemple, POST, PUT, PATCH) est validé.
-
true(valeur par défaut): des champs supplémentaires dans le corps de la requête qui ne sont pas mappés aux colonnes de table provoquent une exceptionBadRequest. -
false: les champs supplémentaires sont ignorés et seules les colonnes valides sont traitées.
Ce paramètre ne s’applique pas s’applique aux requêtes GET, car leur corps de requête est toujours ignoré.
Comportement avec des configurations de colonne spécifiques
- Les colonnes avec une valeur par défaut () sont ignorées pendant
INSERTuniquement lorsque leur valeur dans la charge utile estnull. Les colonnes avec une valeur par défaut () ne sont pas ignorées pendantUPDATEquelle que soit la valeur de la charge utile. - Les colonnes calculées sont toujours ignorées.
- Les colonnes générées automatiquement sont toujours ignorées.
Format
{
"runtime": {
"rest": {
"request-body-strict": <true> (default) | <false>
}
}
}
Exemples
CREATE TABLE Users (
Id INT PRIMARY KEY IDENTITY,
Name NVARCHAR(50) NOT NULL,
Age INT DEFAULT 18,
IsAdmin BIT DEFAULT 0,
IsMinor AS IIF(Age <= 18, 1, 0)
);
Exemple de configuration
{
"runtime": {
"rest": {
"request-body-strict": false
}
}
}
Comportement INSERT avec request-body-strict: false
demande de charge utile:
{
"Id": 999,
"Name": "Alice",
"Age": null,
"IsAdmin": null,
"IsMinor": false,
"ExtraField": "ignored"
}
instruction Insert résultante:
INSERT INTO Users (Name) VALUES ('Alice');
-- Default values for Age (18) and IsAdmin (0) are applied by the database.
-- IsMinor is ignored because it’s a computed column.
-- ExtraField is ignored.
-- The database generates the Id value.
de charge utile de réponse :
{
"Id": 1, // Auto-generated by the database
"Name": "Alice",
"Age": 18, // Default applied
"IsAdmin": false, // Default applied
"IsMinor": true // Computed
}
Comportement UPDATE avec request-body-strict: false
demande de charge utile:
{
"Id": 1,
"Name": "Alice Updated",
"Age": null, // explicitely set to 'null'
"IsMinor": true, // ignored because computed
"ExtraField": "ignored"
}
instruction de mise à jour résultante:
UPDATE Users
SET Name = 'Alice Updated', Age = NULL
WHERE Id = 1;
-- IsMinor and ExtraField are ignored.
de charge utile de réponse :
{
"Id": 1,
"Name": "Alice Updated",
"Age": null,
"IsAdmin": false,
"IsMinor": false // Recomputed by the database (false when age is `null`)
}
Hôte (runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime |
host |
objet | ❌ Non | Aucun |
La section host dans la configuration du runtime fournit des paramètres essentiels pour l’environnement opérationnel du générateur d’API de données. Ces paramètres incluent les modes opérationnels, la configuration CORS et les détails de l’authentification.
Format
{
"runtime": {
"host": {
"mode": "production" (default) | "development",
"max-response-size-mb": <integer; default: 158>,
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
},
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
mode |
❌ Non | chaîne d’énumération | production |
cors |
❌ Non | objet | Aucun |
authentication |
❌ Non | objet | Aucun |
Exemples
Voici un exemple d’exécution configuré pour l’hébergement de développement.
{
"runtime": {
"host": {
"mode": "development",
"cors": {
"allow-credentials": false,
"origins": ["*"]
},
"authentication": {
"provider": "Simulator"
}
}
}
}
Mode (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host |
mode |
corde | ❌ Non | « production » |
Définit si le moteur du générateur d’API de données doit s’exécuter en mode development ou production. La valeur par défaut est production.
En règle générale, les erreurs de base de données sous-jacentes sont exposées en détail en définissant le niveau de détail par défaut pour les journaux à Debug lors de l’exécution dans le développement. En production, le niveau de détail des journaux est défini sur Error.
Pourboire
Le niveau de journal par défaut peut être substitué à l’aide de dab start --LogLevel <level-of-detail>. Pour plus d’informations, consultez informations de référence sur l’interface de ligne de commande (CLI).
Format
{
"runtime": {
"host": {
"mode": "production" (default) | "development"
}
}
}
Valeurs
Voici la liste des valeurs autorisées pour cette propriété :
| Description | |
|---|---|
production |
Utiliser lors de l’hébergement en production sur Azure |
development |
Utilisation dans le développement sur l’ordinateur local |
Comportements
- Uniquement en mode
developmentest Swagger disponible. - Seulement en mode
developmentest Banana Cake Pop disponible.
Taille de réponse maximale (Runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host |
max-response-size-mb |
entier | ❌ Non | 158 |
Définit la taille maximale (en mégaoctets) pour un résultat donné. Ce paramètre permet aux utilisateurs de configurer la quantité de données que la mémoire de leur plateforme hôte peut gérer lors de la diffusion en continu de données à partir des sources de données sous-jacentes.
Lorsque les utilisateurs demandent des jeux de résultats volumineux, ils peuvent forcer la base de données et le générateur d’API de données. Pour résoudre ce problème, max-response-size-mb permet aux développeurs de limiter la taille de réponse maximale, mesurée en mégaoctets, en tant que flux de données de la source de données. Cette limite est basée sur la taille globale des données, et non sur le nombre de lignes. Étant donné que les colonnes peuvent varier en taille, certaines colonnes (telles que du texte, binaire, XML ou JSON) peuvent contenir jusqu’à 2 Go chacune, ce qui rend potentiellement très volumineuses les lignes individuelles. Ce paramètre permet aux développeurs de protéger leurs points de terminaison en limitant les tailles de réponse et en empêchant les surcharges système tout en conservant la flexibilité pour différents types de données.
Valeurs autorisées
| Valeur | Résultat |
|---|---|
null |
La valeur par défaut est de 158 mégaoctets si un ensemble ou défini explicitement sur null. |
integer |
Tout entier 32 bits positif est pris en charge. |
< 0 |
Non pris en charge. Des erreurs de validation se produisent si la valeur est inférieure à 1 Mo. |
Format
{
"runtime": {
"host": {
"max-response-size-mb": <integer; default: 158>
}
}
}
CORS (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host |
cors |
objet | ❌ Non | Aucun |
Paramètres de partage de ressources cross-origin (CORS) pour l’hôte du moteur du générateur d’API de données.
Format
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"],
"allow-credentials": <true> | <false> (default)
}
}
}
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
allow-credentials |
❌ Non | booléen |
origins |
❌ Non | tableau de chaînes |
Autoriser les informations d’identification (runtime de l’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host.cors |
allow-credentials |
booléen | ❌ Non | Faux |
Si la valeur est true, définit l’en-tête CORS Access-Control-Allow-Credentials.
Note
Pour plus d’informations sur l’en-tête CORS Access-Control-Allow-Credentials, consultez référence MDN Web Docs CORS.
Format
{
"runtime": {
"host": {
"cors": {
"allow-credentials": <true> (default) | <false>
}
}
}
}
Origines (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host.cors |
origins |
tableau de chaînes | ❌ Non | Aucun |
Définit un tableau avec une liste d’origines autorisées pour CORS. Ce paramètre permet de * caractères génériques pour toutes les origines.
Format
{
"runtime": {
"host": {
"cors": {
"origins": ["<array-of-strings>"]
}
}
}
}
Exemples
Voici un exemple d’hôte qui autorise CORS sans informations d’identification de toutes les origines.
{
"runtime": {
"host": {
"cors": {
"allow-credentials": false,
"origins": ["*"]
}
}
}
}
Authentification (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host |
authentication |
objet | ❌ Non | Aucun |
Configure l’authentification pour l’hôte du générateur d’API de données.
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<string>",
"issuer": "<string>"
}
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
provider |
❌ Non | chaîne d’énumération | StaticWebApps |
jwt |
❌ Non | objet | Aucun |
Les responsabilités de l’authentification et des clients
Le générateur d’API de données est conçu pour fonctionner dans un pipeline de sécurité plus large et il existe des étapes importantes à configurer avant de traiter les demandes. Il est important de comprendre que le générateur d’API de données n’authentifie pas l’appelant direct (par exemple, votre application web), mais plutôt l’utilisateur final, en fonction d’un jeton JWT valide fourni par un fournisseur d’identité approuvé (par exemple, Entra ID). Lorsqu’une requête atteint le générateur d’API de données, elle suppose que le jeton JWT est valide et le vérifie par rapport aux conditions préalables que vous avez configurées, telles que des revendications spécifiques. Les règles d’autorisation sont ensuite appliquées pour déterminer ce que l’utilisateur peut accéder ou modifier.
Une fois l’autorisation passée, le générateur d’API de données exécute la requête à l’aide du compte spécifié dans la chaîne de connexion. Étant donné que ce compte nécessite souvent des autorisations élevées pour gérer diverses demandes d’utilisateur, il est essentiel de réduire ses droits d’accès afin de réduire les risques. Nous vous recommandons de sécuriser votre architecture en configurant une liaison privée entre votre application web frontale et le point de terminaison de l’API, et en renforcéssant le générateur d’API de données hébergeant la machine. Ces mesures permettent de garantir la sécurité de votre environnement, de protéger vos données et de réduire les vulnérabilités susceptibles d’être exploitées pour accéder, modifier ou exfiltrer des informations sensibles.
Fournisseur (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host.authentication |
provider |
corde | ❌ Non | « StaticWebApps » |
Le paramètre authentication.provider dans la configuration host définit la méthode d’authentification utilisée par le générateur d’API de données. Elle détermine comment l’API valide l’identité des utilisateurs ou des services qui tentent d’accéder à ses ressources. Ce paramètre permet une flexibilité dans le déploiement et l’intégration en prenant en charge différents mécanismes d’authentification adaptés à différents environnements et exigences de sécurité.
| Fournisseur | Description |
|---|---|
StaticWebApps |
Indique au générateur d’API de données de rechercher un ensemble d’en-têtes HTTP uniquement présents lors de l’exécution dans un environnement Static Web Apps. |
AppService |
Lorsque le runtime est hébergé dans Azure AppService avec l’authentification AppService activée et configurée (EasyAuth). |
AzureAd |
Microsoft Entra Identity doit être configuré afin qu’il puisse authentifier une demande envoyée au générateur d’API de données (l'« application serveur »). Pour plus d’informations, consultez l’authentification Microsoft Entra ID. |
Simulator |
Fournisseur d’authentification configurable qui demande au moteur du générateur d’API de données de traiter toutes les demandes comme authentifiées. Pour plus d’informations, consultez d’authentification locale. |
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...
}
}
}
}
Valeurs
Voici la liste des valeurs autorisées pour cette propriété :
| Description | |
|---|---|
StaticWebApps |
Azure Static Web Apps |
AppService |
Azure App Service |
AzureAD |
Microsoft Entra ID |
Simulator |
Simulateur |
Jetons web JSON (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host.authentication |
jwt |
objet | ❌ Non | Aucun |
Si le fournisseur d’authentification est défini sur AzureAD (ID Microsoft Entra), cette section est requise pour spécifier l’audience et les émetteurs pour le jeton JSOn Web Tokens (JWT). Ces données sont utilisées pour valider les jetons sur votre locataire Microsoft Entra.
Obligatoire si le fournisseur d’authentification est AzureAD pour l’ID Microsoft Entra. Cette section doit spécifier les audience et les issuer pour valider le jeton JWT reçu par rapport au locataire AzureAD prévu pour l’authentification.
| Réglage | Description |
|---|---|
| audience | Identifie le destinataire prévu du jeton ; en règle générale, l’identificateur de l’application inscrit dans Microsoft Entra Identity (ou votre fournisseur d’identité) garantit que le jeton a été émis pour votre application. |
| émetteur | Spécifie l’URL de l’autorité émettrice, qui est le service de jeton qui a émis le JWT. Cette URL doit correspondre à l’URL de l’émetteur du fournisseur d’identité à partir de laquelle le JWT a été obtenu, en validant l’origine du jeton. |
Format
{
"runtime": {
"host": {
"authentication": {
"provider": "StaticWebApps" (default) | ...,
"jwt": {
"audience": "<client-id>",
"issuer": "<issuer-url>"
}
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
audience |
❌ Non | corde | Aucun |
issuer |
❌ Non | corde | Aucun |
Exemples
Le générateur d’API de données (DAB) offre une prise en charge flexible de l’authentification, en s’intégrant à Microsoft Entra Identity et aux serveurs JWT (Json Web Token) personnalisés. Dans cette image, serveur JWT représente le service d’authentification qui émet des jetons JWT aux clients lors de la connexion réussie. Le client transmet ensuite le jeton à DAB, ce qui peut interroger ses revendications et ses propriétés.
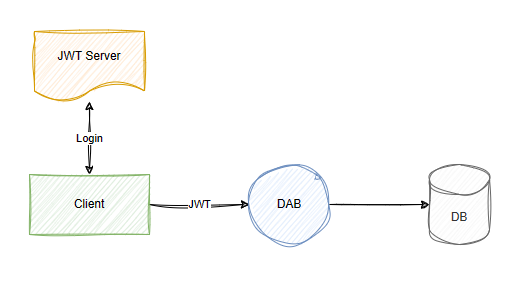
Voici des exemples de la propriété host en fonction de différents choix architecturaux que vous pouvez effectuer dans votre solution.
Azure Static Web Apps
{
"host": {
"mode": "development",
"cors": {
"origins": ["https://dev.example.com"],
"credentials": true
},
"authentication": {
"provider": "StaticWebApps"
}
}
}
Avec StaticWebApps, le générateur d’API de données s’attend à ce qu’Azure Static Web Apps authentifie la requête et que l’en-tête HTTP X-MS-CLIENT-PRINCIPAL soit présent.
Azure App Service
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": false
},
"authentication": {
"provider": "AppService",
"jwt": {
"audience": "9e7d452b-7e23-4300-8053-55fbf243b673",
"issuer": "https://example-appservice-auth.com"
}
}
}
}
L’authentification est déléguée à un fournisseur d’identité pris en charge où le jeton d’accès peut être émis. Un jeton d’accès acquis doit être inclus avec les requêtes entrantes adressées au générateur d’API de données. Le générateur d’API de données valide ensuite tous les jetons d’accès présentés, ce qui garantit que le générateur d’API de données était l’audience prévue du jeton.
Microsoft Entra ID
{
"host": {
"mode": "production",
"cors": {
"origins": [ "https://api.example.com" ],
"credentials": true
},
"authentication": {
"provider": "AzureAD",
"jwt": {
"audience": "c123d456-a789-0abc-a12b-3c4d56e78f90",
"issuer": "https://login.microsoftonline.com/98765f43-21ba-400c-a5de-1f2a3d4e5f6a/v2.0"
}
}
}
}
Simulateur (développement uniquement)
{
"host": {
"mode": "development",
"authentication": {
"provider": "Simulator"
}
}
}
Audience (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host.authentication.jwt |
audience |
corde | ❌ Non | Aucun |
Audience du jeton JWT.
Format
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"audience": "<client-id>"
}
}
}
}
}
Émetteur (runtime d’hôte)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.host.authentication.jwt |
issuer |
corde | ❌ Non | Aucun |
Émetteur pour le jeton JWT.
Format
{
"runtime": {
"host": {
"authentication": {
"jwt": {
"issuer": "<issuer-url>"
}
}
}
}
}
Pagination (runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime |
pagination |
objet | ❌ Non | Aucun |
Configure les limites de pagination pour les points de terminaison REST et GraphQL.
Format
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>,
"default-page-size": <integer; default: 100>
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
max-page-size |
❌ Non | entier | 100,000 |
default-page-size |
❌ Non | entier | 100 |
Exemple de configuration
{
"runtime": {
"pagination": {
"max-page-size": 1000,
"default-page-size": 2
}
},
"entities": {
"Users": {
"source": "dbo.Users",
"permissions": [
{
"actions": ["read"],
"role": "anonymous"
}
]
}
}
}
Exemple de pagination REST
Dans cet exemple, l’émission de la requête REST GET https://localhost:5001/api/users retournerait deux enregistrements dans le tableau value, car le default-page-size est défini sur 2. Si d’autres résultats existent, le générateur d’API de données inclut une nextLink dans la réponse. Le nextLink contient un paramètre $after pour récupérer la page suivante des données.
Demander:
GET https://localhost:5001/api/users
Réponse:
{
"value": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"nextLink": "https://localhost:5001/api/users?$after=W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
À l’aide de la nextLink, le client peut extraire le jeu de résultats suivant.
Exemple de pagination GraphQL
Pour GraphQL, utilisez les champs hasNextPage et endCursor pour la pagination. Ces champs indiquent si d’autres résultats sont disponibles et fournissent un curseur pour extraire la page suivante.
Requête:
query {
users {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Réponse:
{
"data": {
"users": {
"items": [
{
"Id": 1,
"Name": "Alice",
"Age": 30,
"IsAdmin": true,
"IsMinor": false
},
{
"Id": 2,
"Name": "Bob",
"Age": 17,
"IsAdmin": false,
"IsMinor": true
}
],
"hasNextPage": true,
"endCursor": "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI=="
}
}
}
Pour extraire la page suivante, incluez la valeur endCursor dans la requête suivante :
Requête avec curseur :
query {
users(after: "W3siRW50aXR5TmFtZSI6InVzZXJzIiwiRmllbGROYW1lI==") {
items {
Id
Name
Age
IsAdmin
IsMinor
}
hasNextPage
endCursor
}
}
Ajustement de la taille de page
REST et GraphQL permettent d’ajuster le nombre de résultats par requête à l’aide de $limit (REST) ou de first (GraphQL).
valeur $limit/first |
Comportement |
|---|---|
-1 |
La valeur par défaut est max-page-size. |
< max-page-size |
Limite les résultats à la valeur spécifiée. |
0 ou < -1 |
Non pris en charge. |
> max-page-size |
Limité à max-page-size. |
Exemple de requête REST :
GET https://localhost:5001/api/users?$limit=5
Exemple de requête GraphQL :
query {
users(first: 5) {
items {
Id
Name
Age
IsAdmin
IsMinor
}
}
}
Taille de page maximale (runtime pagination)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.pagination |
max-page-size |
Int | ❌ Non | 100,000 |
Définit le nombre maximal d’enregistrements de niveau supérieur retournés par REST ou GraphQL. Si un utilisateur demande plus de max-page-size, les résultats sont limités à max-page-size.
Valeurs autorisées
| Valeur | Résultat |
|---|---|
-1 |
Correspond par défaut à la valeur maximale prise en charge. |
integer |
Tout entier 32 bits positif est pris en charge. |
< -1 |
Non pris en charge. |
0 |
Non pris en charge. |
Format
{
"runtime": {
"pagination": {
"max-page-size": <integer; default: 100000>
}
}
}
Taille de page par défaut (runtime pagination)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.pagination |
default-page-size |
Int | ❌ Non | 100 |
Définit le nombre par défaut d’enregistrements de niveau supérieur retourné lorsque la pagination est activée, mais aucune taille de page explicite n’est fournie.
Valeurs autorisées
| Valeur | Résultat |
|---|---|
-1 |
La valeur par défaut est le paramètre de max-page-size actuel. |
integer |
Entier positif inférieur à l'max-page-sizeactuel . |
< -1 |
Non pris en charge. |
0 |
Non pris en charge. |
Cache (runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime |
cache |
objet | ❌ Non | Aucun |
Active et configure la mise en cache pour l’intégralité du runtime.
Format
{
"runtime": {
"cache": <object>
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
❌ Non | booléen | Aucun |
ttl-seconds |
❌ Non | entier | 5 |
Exemples
Dans cet exemple, le cache est activé et les éléments expirent après 30 secondes.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
Activé (runtime du cache)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.cache |
enabled |
booléen | ❌ Non | Faux |
Active la mise en cache globale pour toutes les entités. La valeur par défaut est false.
Format
{
"runtime": {
"cache": {
"enabled": <boolean>
}
}
}
Exemples
Dans cet exemple, le cache est désactivé.
{
"runtime": {
"cache": {
"enabled": false
}
}
}
Durée de vie en secondes (runtime du cache)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.cache |
ttl-seconds |
entier | ❌ Non | 5 |
Configure la valeur de durée de vie (TTL) en secondes pour les éléments mis en cache. Une fois ce temps écoulé, les éléments sont automatiquement supprimés du cache. La valeur par défaut est 5 secondes.
Format
{
"runtime": {
"cache": {
"ttl-seconds": <integer>
}
}
}
Exemples
Dans cet exemple, le cache est activé globalement et tous les éléments expirent après 15 secondes.
{
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
Télémétrie (runtime)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime |
telemetry |
objet | ❌ Non | Aucun |
Cette propriété configure Application Insights pour centraliser les journaux d’API. Découvrez plus.
Format
{
"runtime": {
"telemetry": {
"application-insights": {
"enabled": <true; default: true> | <false>,
"connection-string": <string>
}
}
}
}
Application Insights (runtime de télémétrie)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.telemetry |
application-insights |
objet | ✔️ Oui | Aucun |
Activé (télémétrie Application Insights)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.telemetry.application-insights |
enabled |
booléen | ❌ Non | Vrai |
Chaîne de connexion (télémétrie Application Insights)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
runtime.telemetry.application-insights |
connection-string |
corde | ✔️ Oui | Aucun |
Entités
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
$root |
entities |
objet | ✔️ Oui | Aucun |
La section entities sert de cœur du fichier de configuration, en établissant un pont entre les objets de base de données et leurs points de terminaison d’API correspondants. Cette section mappe les objets de base de données aux points de terminaison exposés. Cette section inclut également le mappage des propriétés et la définition d’autorisation. Chaque entité exposée est définie dans un objet dédié. Le nom de propriété de l’objet est utilisé comme nom de l’entité à exposer.
Cette section définit la façon dont chaque entité de la base de données est représentée dans l’API, y compris les mappages de propriétés et les autorisations. Chaque entité est encapsulée dans sa propre sous-section, avec le nom de l’entité agissant comme clé pour référence tout au long de la configuration.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true; default: true> | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
},
"graphql": {
"enabled": <true; default: true> | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": <"query" | "mutation"; default: "query">
},
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": {
"<parameter-name>": <string | number | boolean>
}
},
"mappings": {
"<database-field-name>": <string>
},
"relationships": {
"<relationship-name>": {
"cardinality": <"one" | "many">,
"target.entity": <string>,
"source.fields": <array of strings>,
"target.fields": <array of strings>,
"linking.object": <string>,
"linking.source.fields": <array of strings>,
"linking.target.fields": <array of strings>
}
},
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role-name">,
"actions": <array of strings>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
}
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
source |
✔️ Oui | objet |
permissions |
✔️ Oui | tableau |
rest |
❌ Non | objet |
graphql |
❌ Non | objet |
mappings |
❌ Non | objet |
relationships |
❌ Non | objet |
cache |
❌ Non | objet |
Exemples
Par exemple, cet objet JSON indique au générateur d’API de données d’exposer une entité GraphQL nommée User et un point de terminaison REST accessible via le chemin d’accès /User. La table de base de données dbo.User sauvegarde l’entité et la configuration permet à toute personne d’accéder anonymement au point de terminaison.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Cet exemple déclare l’entité User. Ce nom User est utilisé n’importe où dans le fichier de configuration où les entités sont référencées. Sinon, le nom de l’entité n’est pas pertinent pour les points de terminaison.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table",
"key-fields": ["Id"],
"parameters": {} // only when source.type = stored-procedure
},
"rest": {
"enabled": true,
"path": "/users",
"methods": [] // only when source.type = stored-procedure
},
"graphql": {
"enabled": true,
"type": {
"singular": "User",
"plural": "Users"
},
"operation": "query"
},
"mappings": {
"id": "Id",
"name": "Name",
"age": "Age",
"isAdmin": "IsAdmin"
},
"permissions": [
{
"role": "authenticated",
"actions": ["read"], // "execute" only when source.type = stored-procedure
"fields": {
"include": ["id", "name", "age", "isAdmin"],
"exclude": []
},
"policy": {
"database": "@claims.userId eq @item.id"
}
},
{
"role": "admin",
"actions": ["create", "read", "update", "delete"],
"fields": {
"include": ["*"],
"exclude": []
},
"policy": {
"database": "@claims.userRole eq 'UserAdmin'"
}
}
]
}
}
}
Source
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity} |
source |
objet | ✔️ Oui | Aucun |
La configuration {entity}.source connecte l’entité exposée à l’API et son objet de base de données sous-jacent. Cette propriété spécifie la table de base de données, la vue ou la procédure stockée que l’entité représente, établissant un lien direct pour la récupération et la manipulation des données.
Pour les scénarios simples où l’entité est mappée directement à une seule table de base de données, la propriété source n’a besoin que du nom de cet objet de base de données. Cette simplicité facilite la configuration rapide pour les cas d’usage courants : "source": "dbo.User".
Format
{
"entities": {
"<entity-name>": {
"source": {
"object": <string>,
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>,
"parameters": { // only when source.type = stored-procedure
"<name>": <string | number | boolean>
}
}
}
}
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
object |
✔️ Oui | corde |
type |
✔️ Oui | chaîne d’énumération |
parameters |
❌ Non | objet |
key-fields |
❌ Non | tableau de chaînes |
Exemples
1. Mappage de table simple :
Cet exemple montre comment associer une entité User à une table source dbo.Users.
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Exemple de procédure stockée :
Cet exemple montre comment associer une entité User à une procédure source dbo.GetUsers.
SQL
CREATE PROCEDURE GetUsers
@IsAdmin BIT
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
configuration
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age",
"IsAdmin": "isAdmin"
}
}
}
}
La propriété mappings est facultative pour les procédures stockées.
Objet
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.source |
object |
corde | ✔️ Oui | Aucun |
Nom de l’objet de base de données à utiliser. Si l’objet appartient au schéma dbo, la spécification du schéma est facultative. En outre, les crochets autour des noms d’objets (par exemple, [dbo].[Users] et dbo.Users) peuvent être utilisés ou omis.
Exemples
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
notation alternative sans schéma et crochets :
Si la table se trouve dans le schéma dbo, vous pouvez omettre le schéma ou les crochets :
{
"entities": {
"User": {
"source": {
"object": "Users",
"type": "table"
}
}
}
}
Type (entités)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.source |
type |
corde | ✔️ Oui | Aucun |
La propriété type identifie le type d’objet de base de données derrière l’entité, y compris view, tableet stored-procedure. Cette propriété est requise et n’a aucune valeur par défaut.
Format
{
"entities": {
"<entity-name>": {
"type": <"view" | "stored-procedure" | "table">
}
}
}
Valeurs
| Valeur | Description |
|---|---|
table |
Représente une table. |
stored-procedure |
Représente une procédure stockée. |
view |
Représente une vue. |
Exemples
1. Exemple de tableau :
SQL
CREATE TABLE dbo.Users (
Id INT PRIMARY KEY,
Name NVARCHAR(100),
Age INT,
IsAdmin BIT
);
configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
}
}
}
}
2. Exemple de vue :
SQL
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
configuration
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
},
"mappings": {
"Id": "id",
"Name": "name",
"Age": "age"
}
}
}
}
Remarque : spécification de key-fields est importante pour les vues, car elles n’ont pas de clés primaires inhérentes.
3. Exemple de procédure stockée :
SQL
CREATE PROCEDURE dbo.GetUsers (@IsAdmin BIT)
AS
SELECT Id, Name, Age, IsAdmin
FROM dbo.Users
WHERE IsAdmin = @IsAdmin;
configuration
{
"entities": {
"User": {
"source": {
"type": "stored-procedure",
"object": "GetUsers",
"parameters": {
"IsAdmin": "boolean"
}
}
}
}
}
Champs clés
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.source |
key-fields |
tableau de chaînes | ❌ Non | Aucun |
La propriété {entity}.key-fields est particulièrement nécessaire pour les entités sauvegardées par les vues. Le Générateur d’API de données sait donc identifier et retourner un seul élément. Si type est défini sur view sans spécifier key-fields, le moteur refuse de démarrer. Cette propriété est autorisée avec des tables et des procédures stockées, mais elle n’est pas utilisée dans ces cas.
Important
Cette propriété est requise si le type d’objet est un view.
Format
{
"entities": {
"<entity-name>": {
"source": {
"type": <"view" | "stored-procedure" | "table">,
"key-fields": <array of strings>
}
}
}
}
Exemple : Afficher avec des champs clés
Cet exemple utilise la vue dbo.AdminUsers avec Id indiqué comme champ clé.
SQL
CREATE VIEW dbo.AdminUsers AS
SELECT Id, Name, Age
FROM dbo.Users
WHERE IsAdmin = 1;
configuration
{
"entities": {
"AdminUsers": {
"source": {
"object": "dbo.AdminUsers",
"type": "view",
"key-fields": ["Id"]
}
}
}
}
Paramètres
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.source |
parameters |
objet | ❌ Non | Aucun |
La propriété parameters dans entities.{entity}.source est utilisée pour les entités sauvegardées par des procédures stockées. Il garantit le mappage approprié des noms de paramètres et des types de données requis par la procédure stockée.
Important
La propriété parameters est obligatoire si la type de l’objet est stored-procedure et que le paramètre est requis.
Format
{
"entities": {
"<entity-name>": {
"source": {
"type": "stored-procedure",
"parameters": {
"<parameter-name-1>": <string | number | boolean>,
"<parameter-name-2>": <string | number | boolean>
}
}
}
}
}
Exemple 1 : Procédure stockée sans paramètres
SQL
CREATE PROCEDURE dbo.GetUsers AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users;
configuration
{
"entities": {
"Users": {
"source": {
"object": "dbo.GetUsers",
"type": "stored-procedure"
}
}
}
}
Exemple 2 : Procédure stockée avec des paramètres
SQL
CREATE PROCEDURE dbo.GetUser (@userId INT) AS
SELECT Id, Name, Age, IsAdmin FROM dbo.Users
WHERE Id = @userId;
configuration
{
"entities": {
"User": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
}
}
}
}
Autorisations
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity} |
permissions |
objet | ✔️ Oui | Aucun |
Cette section définit qui peut accéder à l’entité associée et quelles actions sont autorisées. Les autorisations sont définies en termes de rôles et d’opérations CRUD : create, read, updateet delete. La section permissions spécifie quels rôles peuvent accéder à l’entité associée et à l’aide des actions.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"actions": ["create", "read", "update", "delete", "execute", "*"]
}
]
}
}
}
| Action | Description |
|---|---|
create |
Permet de créer un enregistrement dans l’entité. |
read |
Permet de lire ou de récupérer des enregistrements à partir de l’entité. |
update |
Autorise la mise à jour des enregistrements existants dans l’entité. |
delete |
Autorise la suppression d’enregistrements de l’entité. |
execute |
Autorise l’exécution d’une procédure stockée ou d’une opération. |
* |
Accorde toutes les opérations CRUD applicables. |
Exemples
Exemple 1 : Rôle anonyme sur l’entité utilisateur
Dans cet exemple, le rôle anonymous est défini avec l’accès à toutes les actions possibles sur l’entité User.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
]
}
}
}
Exemple 2 : Actions mixtes pour les de rôle anonyme
Cet exemple montre comment combiner des actions de tableau de chaînes et d’objets pour l’entité User.
{
"entities": {
"User": {
"permissions": [
{
"role": "anonymous",
"actions": [
{ "action": "read" },
"create"
]
}
]
}
}
}
rôle anonyme: permet aux utilisateurs anonymes de lire tous les champs à l’exception d’un champ sensible hypothétique (par exemple, secret-field). L’utilisation de "include": ["*"] avec "exclude": ["secret-field"] masque secret-field tout en autorisant l’accès à tous les autres champs.
rôle authentifié: permet aux utilisateurs authentifiés de lire et de mettre à jour des champs spécifiques. Par exemple, y compris explicitement id, nameet age, mais l’exclusion de isAdmin peut démontrer comment les exclusions remplacent les inclusions.
rôle d’administrateur: les administrateurs peuvent effectuer toutes les opérations (*) sur tous les champs sans exclusion. La spécification de "include": ["*"] avec un tableau de "exclude": [] vide accorde l’accès à tous les champs.
Cette configuration :
"fields": {
"include": [],
"exclude": []
}
est effectivement identique à :
"fields": {
"include": ["*"],
"exclude": []
}
Tenez également compte de cette configuration :
"fields": {
"include": [],
"exclude": ["*"]
}
Cela spécifie qu’aucun champ n’est explicitement inclus et que tous les champs sont exclus, ce qui limite généralement entièrement l’accès.
Utilisation pratique: une telle configuration peut sembler contre-intuitive, car elle limite l’accès à tous les champs. Toutefois, il peut être utilisé dans les scénarios où un rôle effectue certaines actions (comme la création d’une entité) sans accéder à ses données.
Le même comportement, mais avec une syntaxe différente, serait :
"fields": {
"include": ["Id", "Name"],
"exclude": ["*"]
}
Cette configuration tente d’inclure uniquement des champs Id et Name, mais exclut tous les champs en raison du caractère générique dans exclude.
Une autre façon d’exprimer la même logique serait :
"fields": {
"include": ["Id", "Name"],
"exclude": ["Id", "Name"]
}
Étant donné que exclude est prioritaire sur include, en spécifiant exclude: ["*"] signifie que tous les champs sont exclus, même ceux de include. Ainsi, à première vue, cette configuration peut sembler empêcher tout champ d’être accessible.
Leinverse : si l’intention est d’accorder l’accès uniquement aux champs Id et Name, il est plus clair et plus fiable de spécifier uniquement ces champs dans la section include sans utiliser de caractère générique d’exclusion :
"fields": {
"include": ["Id", "Name"],
"exclude": []
}
Propriétés
| Obligatoire | Type | |
|---|---|---|
role |
✔️ Oui | corde |
actions (tableau de chaînes)ou actions (tableau d’objets) |
✔️ Oui | tableau d’objets ou de chaînes |
Rôle
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.permissions |
role |
corde | ✔️ Oui | Aucun |
Chaîne contenant le nom du rôle auquel l’autorisation définie s’applique. Les rôles définissent le contexte d’autorisations dans lequel une requête doit être exécutée. Pour chaque entité définie dans la configuration du runtime, vous pouvez définir un ensemble de rôles et d’autorisations associées qui déterminent la façon dont l’entité est accessible via des points de terminaison REST et GraphQL. Les rôles ne sont pas additifs.
Data API Builder évalue les requêtes dans le contexte d’un seul rôle :
| Rôle | Description |
|---|---|
anonymous |
Aucun jeton d’accès n’est présenté |
authenticated |
Un jeton d’accès valide est présenté |
<custom-role> |
Un jeton d’accès valide est présenté et l’en-tête HTTP X-MS-API-ROLE spécifie un rôle présent dans le jeton |
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <"anonymous" | "authenticated" | "custom-role">,
"actions": ["create", "read", "update", "delete", "execute", "*"],
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
}
}
]
}
}
}
Exemples
Cet exemple définit un rôle nommé reader avec uniquement des autorisations read sur l’entité User.
{
"entities": {
"User": {
"permissions": [
{
"role": "reader",
"actions": ["read"]
}
]
}
}
}
Vous pouvez utiliser <custom-role> lorsqu’un jeton d’accès valide est présenté et l’en-tête HTTP X-MS-API-ROLE est inclus, en spécifiant un rôle d’utilisateur qui est également contenu dans la revendication des rôles du jeton d’accès. Voici des exemples de requêtes GET adressées à l’entité User, y compris le jeton du porteur d’autorisation et l’en-tête X-MS-API-ROLE, sur la base de point de terminaison REST /api à localhost à l’aide de différentes langues.
GET https://localhost:5001/api/User
Authorization: Bearer <your_access_token>
X-MS-API-ROLE: custom-role
Actions (tableau de chaînes)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.permissions |
actions |
oneOf [chaîne, tableau] | ✔️ Oui | Aucun |
Tableau de valeurs de chaîne détaillant les opérations autorisées pour le rôle associé. Pour les objets de base de données table et view, les rôles peuvent utiliser n’importe quelle combinaison de create, de read, de updateou d’actions de delete. Pour les procédures stockées, les rôles ne peuvent avoir que l’action execute.
| Action | Opération SQL |
|---|---|
* |
Caractère générique, y compris l’exécution |
create |
Insérer une ou plusieurs lignes |
read |
Sélectionner une ou plusieurs lignes |
update |
Modifier une ou plusieurs lignes |
delete |
Supprimer une ou plusieurs lignes |
execute |
Exécute une procédure stockée |
Note
Pour les procédures stockées, l’action générique (*) s’étend uniquement à l’action execute. Pour les tables et les vues, il s’étend à create, read, updateet delete.
Exemples
Cet exemple donne create et read autorisations à un rôle nommé contributor et delete autorisations à un rôle nommé auditor sur l’entité User.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": ["delete"]
},
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Autre exemple :
{
"entities": {
"User": {
"permissions": [
{
"role": "contributor",
"actions": ["read", "create"]
}
]
}
}
}
Actions (object-array)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.permissions |
actions |
tableau de chaînes | ✔️ Oui | Aucun |
Tableau d’objets d’action détaillant les opérations autorisées pour le rôle associé. Pour les objets table et view, les rôles peuvent utiliser n’importe quelle combinaison de create, read, updateou delete. Pour les procédures stockées, seules les execute sont autorisées.
Note
Pour les procédures stockées, l’action générique (*) s’étend uniquement à execute. Pour les tables/vues, il s’étend à create, read, updateet delete.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <array of strings>,
"policy": <object>
}
]
}
]
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
action |
✔️ Oui | corde | Aucun |
fields |
❌ Non | tableau de chaînes | Aucun |
policy |
❌ Non | objet | Aucun |
Exemple
Cet exemple accorde uniquement read autorisation au rôle auditor sur l’entité User, avec des restrictions de champ et de stratégie.
{
"entities": {
"User": {
"permissions": [
{
"role": "auditor",
"actions": [
{
"action": "read",
"fields": {
"include": ["*"],
"exclude": ["last_login"]
},
"policy": {
"database": "@item.IsAdmin eq false"
}
}
]
}
]
}
}
}
Action
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.permissions.actions[] |
action |
corde | ✔️ Oui | Aucun |
Spécifie l’opération spécifique autorisée sur l’objet de base de données.
Valeurs
| Tables | Affichage | Procédures stockées | Description | |
|---|---|---|---|---|
create |
✔️ Oui | ✔️ Oui | ❌ Non | Créer des éléments |
read |
✔️ Oui | ✔️ Oui | ❌ Non | Lire les éléments existants |
update |
✔️ Oui | ✔️ Oui | ❌ Non | Mettre à jour ou remplacer des éléments |
delete |
✔️ Oui | ✔️ Oui | ❌ Non | Supprimer des éléments |
execute |
❌ Non | ❌ Non | ✔️ Oui | Exécuter des opérations programmatiques |
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": "<role>",
"actions": [
{
"action": "<string>",
"fields": {
"include": [/* fields */],
"exclude": [/* fields */]
},
"policy": {
"database": "<predicate>"
}
}
]
}
]
}
}
}
Exemple
Voici un exemple où anonymous utilisateurs sont autorisés à execute une procédure stockée et read à partir de la table User.
{
"entities": {
"User": {
"source": {
"object": "dbo.Users",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read"
}
]
}
]
},
"GetUser": {
"source": {
"object": "dbo.GetUser",
"type": "stored-procedure",
"parameters": {
"userId": "number"
}
},
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "execute"
}
]
}
]
}
}
}
Champs
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.permissions.actions[] |
fields |
objet | ❌ Non | Aucun |
Spécifications granulaires sur lesquelles des champs spécifiques sont autorisés à accéder à l’objet de base de données. La configuration de rôle est un type d’objet avec deux propriétés internes, include et exclude. Ces valeurs prennent en charge la définition granulaire des colonnes de base de données (champs) autorisées dans la section fields.
Format
{
"entities": {
<string>: {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": <object>
}
]
}
]
}
}
}
Exemples
Dans cet exemple, le rôle anonymous est autorisé à lire à partir de tous les champs, sauf id, mais peut utiliser tous les champs lors de la création d’un élément.
{
"entities": {
"Author": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"fields": {
"include": [ "*" ],
"exclude": [ "id" ]
}
},
{ "action": "create" }
]
}
]
}
}
}
Incluez et excluez le travail ensemble. Le caractère générique * dans la section include indique tous les champs. Les champs notés dans la section exclude ont la priorité sur les champs notés dans la section include. La définition se traduit par inclure tous les champs à l’exception du champ « last_updated ».
"Book": {
"source": "books",
"permissions": [
{
"role": "anonymous",
"actions": [ "read" ],
// Include All Except Specific Fields
"fields": {
"include": [ "*" ],
"exclude": [ "secret-field" ]
}
},
{
"role": "authenticated",
"actions": [ "read", "update" ],
// Explicit Include and Exclude
"fields": {
"include": [ "id", "title", "secret-field" ],
"exclude": [ "secret-field" ]
}
},
{
"role": "author",
"actions": [ "*" ],
// Include All With No Exclusions (default)
"fields": {
"include": ["*"],
"exclude": []
}
}
]
}
Politique
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.permissions.actions[] |
policy |
objet | ❌ Non | Aucun |
La section policy, définie par action, définit des règles de sécurité au niveau de l’élément (stratégies de base de données) qui limitent les résultats retournés par une requête. La sous-section database indique l’expression de stratégie de base de données évaluée pendant l’exécution de la requête.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": <object>,
"policy": {
"database": <string>
}
}
]
}
]
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
database |
✔️ Oui | corde | Aucun |
Description
La stratégie database : expression de type OData traduite en prédicat de requête évaluée par la base de données, y compris les opérateurs tels que eq, ltet gt. Pour que les résultats soient retournés pour une demande, le prédicat de requête de la requête résolu à partir d’une stratégie de base de données doit être évalué à true lors de l’exécution sur la base de données.
| Exemple de stratégie d’élément | Prédicat |
|---|---|
@item.OwnerId eq 2000 |
WHERE Table.OwnerId = 2000 |
@item.OwnerId gt 2000 |
WHERE Table.OwnerId > 2000 |
@item.OwnerId lt 2000 |
WHERE Table.OwnerId < 2000 |
Une
predicateest une expression qui prend la valeur TRUE ou FALSE. Les prédicats sont utilisés dans la condition de recherche de clauses WHERE et clauses HAVING, les conditions de jointure des clauses FROM et d’autres constructions où une valeur booléenne est requise. (Microsoft Learn Docs)
Stratégie de base de données
Deux types de directives peuvent être utilisés pour gérer la stratégie de base de données lors de la création d’une expression de stratégie de base de données :
| Directive | Description |
|---|---|
@claims |
Accéder à une revendication dans le jeton d’accès validé fourni dans la demande |
@item |
Représente un champ de l’entité pour laquelle la stratégie de base de données est définie |
Note
Lorsque Azure Static Web Apps l’authentification (EasyAuth) est configurée, un nombre limité de types de revendications sont disponibles pour une utilisation dans les stratégies de base de données : identityProvider, userId, userDetailset userRoles. Pour plus d’informations, consultez la documentation des données du principal client d’Azure Static Web App.
Voici quelques exemples de stratégies de base de données :
@claims.userId eq @item.OwnerId@claims.userId gt @item.OwnerId@claims.userId lt @item.OwnerId
Le générateur d’API de données compare la valeur de la revendication UserId à la valeur du champ de base de données OwnerId. La charge utile de résultat inclut uniquement les enregistrements qui remplissent les deux les métadonnées de la requête et l’expression de stratégie de base de données.
Limitations
Les stratégies de base de données sont prises en charge pour les tables et les vues. Les procédures stockées ne peuvent pas être configurées avec des stratégies.
Les stratégies de base de données n’empêchent pas les requêtes d’être exécutées dans la base de données. Ce comportement est dû au fait qu’ils sont résolus en tant que prédicats dans les requêtes générées passées au moteur de base de données.
Les stratégies de base de données ne sont prises en charge que pour la actionscréer, lire, mettre à jouret supprimer . Étant donné qu’il n’existe aucun prédicat dans un appel de procédure stockée, ils ne peuvent pas être ajoutés.
Opérateurs de type OData pris en charge
| Opérateur | Description | Exemple de syntaxe |
|---|---|---|
and |
AND logique | "@item.status eq 'active' and @item.age gt 18" |
or |
OR logique | "@item.region eq 'US' or @item.region eq 'EU'" |
eq |
Égale | "@item.type eq 'employee'" |
gt |
Plus grand que | "@item.salary gt 50000" |
lt |
Moins de | "@item.experience lt 5" |
Pour plus d’informations, consultez opérateurs binaires.
| Opérateur | Description | Exemple de syntaxe |
|---|---|---|
- |
Negate (numérique) | "@item.balance lt -100" |
not |
Négation logique (NOT) | "not @item.status eq 'inactive'" |
Pour plus d’informations, consultez opérateurs unaires.
Restrictions de nom de champ d’entité
-
Règles: doit commencer par une lettre ou un trait de soulignement (
_), suivi de 127 lettres, traits de soulignement (_) ou chiffres (0-9). - Impact: les champs qui ne respectent pas ces règles ne peuvent pas être utilisés directement dans les stratégies de base de données.
-
Solution: utilisez la section
mappingspour créer des alias pour les champs qui ne répondent pas à ces conventions d’affectation de noms ; les mappages garantissent que tous les champs peuvent être inclus dans les expressions de stratégie.
Utilisation de mappings pour les champs non conformes
Si vos noms de champs d’entité ne répondent pas aux règles de syntaxe OData ou que vous souhaitez simplement les alias pour d’autres raisons, vous pouvez définir des alias dans la section mappings de votre configuration.
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": <string>,
"<field-2-name>": <string>,
"<field-3-name>": <string>
}
}
}
}
Dans cet exemple, field-1-name est le nom du champ de base de données d’origine qui ne répond pas aux conventions d’affectation de noms OData. La création d’une carte à field-1-name et field-1-alias permet à ce champ d’être référencé dans les expressions de stratégie de base de données sans problème. Cette approche permet non seulement de respecter les conventions d’affectation de noms OData, mais également d’améliorer la clarté et l’accessibilité de votre modèle de données dans les points de terminaison GraphQL et RESTful.
Exemples
Considérez une entité nommée Employee dans une configuration d’API de données qui utilise à la fois les directives de revendications et d’élément. Il garantit que l’accès aux données est géré en toute sécurité en fonction des rôles d’utilisateur et de la propriété d’entité :
{
"entities": {
"Employee": {
"source": {
"object": "HRUNITS",
"type": "table",
"key-fields": ["employee NUM"],
"parameters": {}
},
"mappings": {
"employee NUM": "EmployeeId",
"employee Name": "EmployeeName",
"department COID": "DepartmentId"
},
"policy": {
"database": "@claims.role eq 'HR' or @claims.userId eq @item.EmployeeId"
}
}
}
}
définition d’entité: l’entité Employee est configurée pour les interfaces REST et GraphQL, ce qui indique que ses données peuvent être interrogées ou manipulées via ces points de terminaison.
de configuration source : identifie le HRUNITS dans la base de données, avec employee NUM comme champ clé.
Mappages: les alias sont utilisés pour mapper employee NUM, employee Nameet department COID pour EmployeeId, EmployeeNameet DepartmentId, respectivement, simplifier les noms de champs et potentiellement obfusquer les détails du schéma de base de données sensible.
application de stratégie: la section policy applique une stratégie de base de données à l’aide d’une expression de type OData. Cette stratégie limite l’accès aux données aux utilisateurs disposant du rôle RH (@claims.role eq 'HR') ou aux utilisateurs dont la revendication UserId correspond à EmployeeId - l’alias de champ - dans la base de données (@claims.userId eq @item.EmployeeId). Elle garantit que les employés ne peuvent accéder qu’à leurs propres enregistrements, sauf s’ils appartiennent au service rh. Les stratégies peuvent appliquer la sécurité au niveau des lignes en fonction de conditions dynamiques.
Base de données
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.permissions.actions.policy |
database |
objet | ✔️ Oui | Aucun |
La section policy, définie par action, définit des règles de sécurité au niveau de l’élément (stratégies de base de données) qui limitent les résultats retournés par une requête. La sous-section database indique l’expression de stratégie de base de données évaluée pendant l’exécution de la requête.
Format
{
"entities": {
"<entity-name>": {
"permissions": [
{
"role": <string>,
"actions": [
{
"action": <string>,
"fields": {
"include": <array of strings>,
"exclude": <array of strings>
},
"policy": {
"database": <string>
}
}
]
}
]
}
}
}
Cette propriété indique l’expression de stratégie de base de données évaluée pendant l’exécution de la demande. La chaîne de stratégie est une expression OData traduite en une requête prédicée évaluée par la base de données. Par exemple, l’expression de stratégie @item.OwnerId eq 2000 est traduite en prédicat de requête WHERE <schema>.<object-name>.OwnerId = 2000.
Note
Un prédicat est une expression qui évalue à TRUE, FALSEou UNKNOWN. Les prédicats sont utilisés dans :
- Condition de recherche des clauses
WHERE - Condition de recherche des clauses
FROM - Conditions de jointure des clauses
FROM - Autres constructions où une valeur booléenne est requise.
Pour plus d’informations, consultez prédicats.
Pour que les résultats soient retournés pour une demande, le prédicat de requête de la requête résolu à partir d’une stratégie de base de données doit être évalué à true lors de l’exécution sur la base de données.
Deux types de directives peuvent être utilisés pour gérer la stratégie de base de données lors de la création d’une expression de stratégie de base de données :
| Description | |
|---|---|
@claims |
Accède à une revendication dans le jeton d’accès validé fourni dans la demande |
@item |
Représente un champ de l’entité pour laquelle la stratégie de base de données est définie |
Note
Un nombre limité de types de revendications sont disponibles pour une utilisation dans les stratégies de base de données lorsque l’authentification Azure Static Web Apps (EasyAuth) est configurée. Ces types de revendications sont les suivants : identityProvider, userId, userDetailset userRoles. Pour plus d’informations, consultez données du principal du client Azure Static Web Apps.
Exemples
Par exemple, une expression de stratégie de base peut évaluer si un champ spécifique est vrai dans la table. Cet exemple évalue si le champ soft_delete est false.
{
"entities": {
"Manuscripts": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"policy": {
"database": "@item.soft_delete eq false"
}
}
]
}
]
}
}
}
Les prédicats peuvent également évaluer les types de directive claims et item. Cet exemple extrait le champ UserId à partir du jeton d’accès et le compare au champ owner_id de la table de base de données cible.
{
"entities": {
"Manuscript": {
"permissions": [
{
"role": "anonymous",
"actions": [
{
"action": "read",
"policy": {
"database": "@claims.userId eq @item.owner_id"
}
}
]
}
]
}
}
}
Limitations
- Les stratégies de base de données sont prises en charge pour les tables et les vues. Les procédures stockées ne peuvent pas être configurées avec des stratégies.
- Les stratégies de base de données ne peuvent pas être utilisées pour empêcher l’exécution d’une demande dans une base de données. Cette limitation est due au fait que les stratégies de base de données sont résolues en tant que prédicats de requête dans les requêtes de base de données générées. Le moteur de base de données évalue finalement ces requêtes.
- Les stratégies de base de données ne sont prises en charge que pour les
actionscreate, lesread, lesupdateet lesdelete. - La syntaxe d’expression OData de stratégie de base de données prend uniquement en charge ces scénarios.
- Opérateurs binaires, y compris, mais pas limités à ;
and,or,eq,gtetlt. Pour plus d’informations, voirBinaryOperatorKind. - Opérateurs unaires tels que les opérateurs
-(négation) etnot. Pour plus d’informations, voirUnaryOperatorKind.
- Opérateurs binaires, y compris, mais pas limités à ;
- Les stratégies de base de données ont également des restrictions relatives aux noms de champs.
- Noms de champs d’entité commençant par une lettre ou un trait de soulignement, suivis d’au plus 127 lettres, traits de soulignement ou chiffres.
- Cette exigence est conformément à la spécification OData. Pour plus d’informations, consultez langage de définition de schéma commun OData.
Pourboire
Les champs qui ne sont pas conformes aux restrictions mentionnées ne peuvent pas être référencés dans les stratégies de base de données. Pour contourner ce problème, configurez l’entité avec une section mappages pour affecter des alias conformes aux champs.
GraphQL (entités)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity} |
graphql |
objet | ❌ Non | Aucun |
Cet objet définit si GraphQL est activé et si le nom[s] utilisé pour exposer l’entité en tant que type GraphQL. Cet objet est facultatif et utilisé uniquement si le nom ou les paramètres par défaut ne sont pas suffisants.
Ce segment fournit l’intégration d’une entité dans le schéma GraphQL. Il permet aux développeurs de spécifier ou de modifier des valeurs par défaut pour l’entité dans GraphQL. Cette configuration garantit que le schéma reflète avec précision la structure et les conventions d’affectation de noms prévues.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>,
"type": {
"singular": <string>,
"plural": <string>
},
"operation": "query" (default) | "mutation"
}
}
}
}
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <boolean>,
"type": <string-or-object>,
"operation": "query" (default) | "mutation"
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
❌ Non | booléen | Aucun |
type |
❌ Non | chaîne ou objet | Aucun |
operation |
❌ Non | chaîne d’énumération | Aucun |
Exemples
Ces deux exemples sont fonctionnellement équivalents.
{
"entities": {
"Author": {
"graphql": true
}
}
}
{
"entities": {
"Author": {
"graphql": {
"enabled": true
}
}
}
}
Dans cet exemple, l’entité définie est Book, ce qui indique que nous traitons un ensemble de données relatives aux livres de la base de données. La configuration de l’entité Book dans le segment GraphQL offre une structure claire sur la façon dont elle doit être représentée et interagir avec un schéma GraphQL.
propriété Enabled: l’entité Book est rendue disponible via GraphQL ("enabled": true), ce qui signifie que les développeurs et les utilisateurs peuvent interroger ou muter des données de livre via des opérations GraphQL.
propriété Type: l’entité est représentée avec le nom singulier "Book" et le nom pluriel "Books" dans le schéma GraphQL. Cette distinction garantit que lors de l’interrogation d’un seul livre ou de plusieurs livres, le schéma offre des types nommés intuitivement (Book pour une entrée unique, Books pour une liste), améliorant la facilité d’utilisation de l’API.
propriété Operation: l’opération est définie sur "query", indiquant que l’interaction principale avec l’entité Book via GraphQL est destinée à interroger (récupérer) des données plutôt que de le muter (création, mise à jour ou suppression). Cette configuration s’aligne sur les modèles d’utilisation classiques où les données de livre sont plus fréquemment lues que modifiées.
{
"entities": {
"Book": {
...
"graphql": {
"enabled": true,
"type": {
"singular": "Book",
"plural": "Books"
},
"operation": "query"
},
...
}
}
}
Type (entité GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.graphql |
type |
oneOf [string, object] | ❌ Non | {entity-name} |
Cette propriété détermine la convention d’affectation de noms pour une entité dans le schéma GraphQL. Il prend en charge les valeurs de chaîne scalaire et les types d’objets. La valeur de l’objet spécifie les formes singulières et plurielles. Cette propriété fournit un contrôle granulaire sur la lisibilité et l’expérience utilisateur du schéma.
Format
{
"entities": {
<entity-name>: {
"graphql": {
"type": <string>
}
}
}
}
{
"entities": {
<entity-name>: {
"graphql": {
"type": {
"singular": <string>,
"plural": <string>
}
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
singular |
❌ Non | corde | Aucun |
plural |
❌ Non | corde | N/A (valeur par défaut : singular) |
Exemples
Pour un contrôle encore plus important sur le type GraphQL, vous pouvez configurer la façon dont le nom singulier et pluriel est représenté indépendamment.
Si plural est manquant ou omis (comme la valeur scalaire) Le générateur d’API de données tente de pluraliser automatiquement le nom, en suivant les règles anglaises pour la pluralisation (par exemple : https://engdic.org/singular-and-plural-noun-rules-definitions-examples)
{
"entities" {
"<entity-name>": {
...
"graphql": {
...
"type": {
"singular": "User",
"plural": "Users"
}
}
}
}
}
Un nom d’entité personnalisé peut être spécifié à l’aide du paramètre type avec une valeur de chaîne. Dans cet exemple, le moteur différencie automatiquement les variantes singuliers et pluriels de ce nom à l’aide de règles anglaises communes pour la pluralisation.
{
"entities": {
"Author": {
"graphql": {
"type": "bookauthor"
}
}
}
}
Si vous choisissez de spécifier explicitement les noms, utilisez les propriétés type.singular et type.plural. Cet exemple définit explicitement les deux noms.
{
"entities": {
"Author": {
"graphql": {
"type": {
"singular": "bookauthor",
"plural": "bookauthors"
}
}
}
}
}
Ces deux exemples sont fonctionnellement équivalents. Ils retournent tous les deux la même sortie JSON pour une requête GraphQL qui utilise le nom d’entité bookauthors.
{
bookauthors {
items {
first_name
last_name
}
}
}
{
"data": {
"bookauthors": {
"items": [
{
"first_name": "Henry",
"last_name": "Ross"
},
{
"first_name": "Jacob",
"last_name": "Hancock"
},
...
]
}
}
}
Opération (entité GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.graphql |
operation |
chaîne d’énumération | ❌ Non | Aucun |
Pour les entités mappées aux procédures stockées, la propriété operation désigne le type d’opération GraphQL (requête ou mutation) où la procédure stockée est accessible. Ce paramètre permet l’organisation logique du schéma et l’adhésion aux meilleures pratiques GraphQL, sans impact sur les fonctionnalités.
Note
Une entité est spécifiée pour être une procédure stockée en définissant la valeur de propriété {entity}.type sur stored-procedure. Dans le cas d’une procédure stockée, un nouveau type GraphQL executeXXX est créé automatiquement. Toutefois, la propriété operation permet au développeur de coerser l’emplacement de ce type dans les parties mutation ou query du schéma. Cette propriété permet l’hygene de schéma et n’a aucun impact fonctionnel, quelle que soit la valeur de operation.
S’il est manquant, la valeur par défaut operation est mutation.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"operation": "query" (default) | "mutation"
}
}
}
}
Valeurs
Voici la liste des valeurs autorisées pour cette propriété :
| Description | |
|---|---|
query |
La procédure stockée sous-jacente est exposée en tant que requête |
mutation |
La procédure stockée sous-jacente est exposée en tant que mutation |
Exemples
Lorsque operation est mutation, le schéma GraphQL ressemble à :
type Mutation {
executeGetCowrittenBooksByAuthor(
searchType: String = "S"
): [GetCowrittenBooksByAuthor!]!
}
Lorsque operation est query, le schéma GraphQL ressemble à :
Le schéma GraphQL ressemblerait à ceci :
type Query {
executeGetCowrittenBooksByAuthor(
searchType: String = "S"
): [GetCowrittenBooksByAuthor!]!
}
Note
La propriété operation concerne uniquement le placement de l’opération dans le schéma GraphQL, elle ne modifie pas le comportement de l’opération.
Activé (entité GraphQL)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.graphql |
enabled |
booléen | ❌ Non | Vrai |
Active ou désactive le point de terminaison GraphQL. Contrôle si une entité est disponible via des points de terminaison GraphQL. Le basculement de la propriété enabled permet aux développeurs d’exposer sélectivement des entités à partir du schéma GraphQL.
Format
{
"entities": {
"<entity-name>": {
"graphql": {
"enabled": <true> (default) | <false>
}
}
}
}
REST (entités)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity} |
rest |
objet | ❌ Non | Aucun |
La section rest du fichier de configuration est dédiée à l’optimisation des points de terminaison RESTful pour chaque entité de base de données. Cette fonctionnalité de personnalisation garantit que l’API REST exposée correspond à des exigences spécifiques, ce qui améliore à la fois ses fonctionnalités d’utilitaire et d’intégration. Il traite des incompatibilités potentielles entre les paramètres déduits par défaut et les comportements de point de terminaison souhaités.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>,
"path": <string; default: "<entity-name>">,
"methods": <array of strings; default: ["GET", "POST"]>
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
✔️ Oui | booléen | Vrai |
path |
❌ Non | corde | /<entity-name> |
methods |
❌ Non | tableau de chaînes | AVOIR |
Exemples
Ces deux exemples sont fonctionnellement équivalents.
{
"entities": {
"Author": {
"source": {
"object": "dbo.authors",
"type": "table"
},
"permissions": [
{
"role": "anonymous",
"actions": ["*"]
}
],
"rest": true
}
}
}
{
"entities": {
"Author": {
...
"rest": {
"enabled": true
}
}
}
}
Voici un autre exemple de configuration REST pour une entité.
{
"entities" {
"User": {
"rest": {
"enabled": true,
"path": "/User"
},
...
}
}
}
Activé (entité REST)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.rest |
enabled |
booléen | ❌ Non | Vrai |
Cette propriété agit comme un bouton bascule pour la visibilité des entités au sein de l’API REST. En définissant la propriété enabled sur true ou false, les développeurs peuvent contrôler l’accès à des entités spécifiques, ce qui permet une surface d’API personnalisée qui s’aligne sur les exigences de sécurité et de fonctionnalité des applications.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"enabled": <true> (default) | <false>
}
}
}
}
Chemin d’accès (entité REST)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.rest |
path |
corde | ❌ Non | Aucun |
La propriété path spécifie le segment d’URI utilisé pour accéder à une entité via l’API REST. Cette personnalisation permet d’obtenir des chemins de point de terminaison plus descriptifs ou simplifiés au-delà du nom d’entité par défaut, ce qui améliore la navigabilité des API et l’intégration côté client. Par défaut, le chemin d’accès est /<entity-name>.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"path": <string; default: "<entity-name>">
}
}
}
}
Exemples
Cet exemple montre comment exposer l’entité Author à l’aide du point de terminaison /auth.
{
"entities": {
"Author": {
"rest": {
"path": "/auth"
}
}
}
}
Méthodes (entité REST)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.rest |
methods |
tableau de chaînes | ❌ Non | Aucun |
Applicable spécifiquement aux procédures stockées, la propriété methods définit les verbes HTTP (par exemple, GET, POST) auxquels la procédure peut répondre. Les méthodes permettent un contrôle précis sur la façon dont les procédures stockées sont exposées via l’API REST, garantissant ainsi la compatibilité avec les normes RESTful et les attentes des clients. Cette section souligne l’engagement de la plateforme en matière de flexibilité et de contrôle des développeurs, ce qui permet une conception d’API précise et intuitive adaptée aux besoins spécifiques de chaque application.
En cas d’omission ou d’absence, la valeur par défaut methods est POST.
Format
{
"entities": {
"<entity-name>": {
"rest": {
"methods": ["GET" (default), "POST"]
}
}
}
}
Valeurs
Voici la liste des valeurs autorisées pour cette propriété :
| Description | |
|---|---|
get |
Expose les requêtes HTTP GET |
post |
Expose les requêtes HTTP POST |
Exemples
Cet exemple indique au moteur que la procédure stockée stp_get_bestselling_authors prend uniquement en charge les actions HTTP GET.
{
"entities": {
"BestSellingAuthor": {
"source": {
"object": "dbo.stp_get_bestselling_authors",
"type": "stored-procedure",
"parameters": {
"depth": "number"
}
},
"rest": {
"path": "/best-selling-authors",
"methods": [ "get" ]
}
}
}
}
Mappages (entités)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity} |
mappings |
objet | ❌ Non | Aucun |
la section mappings permet de configurer des alias ou des noms exposés pour les champs d’objet de base de données. Les noms exposés configurés s’appliquent aux points de terminaison GraphQL et REST.
Important
Pour les entités avec GraphQL activée, le nom exposé configuré doit respecter les exigences de nommage GraphQL. Pour plus d’informations, consultez spécification des noms GraphQL.
Format
{
"entities": {
"<entity-name>": {
"mappings": {
"<field-1-name>": "<field-1-alias>",
"<field-2-name>": "<field-2-alias>",
"<field-3-name>": "<field-3-alias>"
}
}
}
}
Exemples
Dans cet exemple, le champ sku_title de l’objet de base de données dbo.magazines est exposé à l’aide du nom title. De même, le champ sku_status est exposé en tant que status dans les points de terminaison REST et GraphQL.
{
"entities": {
"Magazine": {
...
"mappings": {
"sku_title": "title",
"sku_status": "status"
}
}
}
}
Voici un autre exemple de mappages.
{
"entities": {
"Book": {
...
"mappings": {
"id": "BookID",
"title": "BookTitle",
"author": "AuthorName"
}
}
}
}
Mappages: l’objet mappings lie les champs de base de données (BookID, BookTitle, AuthorName) à des noms plus intuitifs ou standardisés (id, title, author) utilisés en externe. Cet alias sert à plusieurs fins :
de clarté et de cohérence : il permet d’utiliser un nom clair et cohérent dans l’API, quel que soit le schéma de base de données sous-jacent. Par exemple,
BookIDdans la base de données est représentée en tant queiddans l’API, ce qui rend plus intuitive pour les développeurs qui interagissent avec le point de terminaison.conformité GraphQL: en fournissant un mécanisme permettant d’alias des noms de champs, il garantit que les noms exposés via l’interface GraphQL sont conformes aux exigences d’affectation de noms GraphQL. L’attention aux noms est importante, car GraphQL a des règles strictes sur les noms (par exemple, aucun espace, ne doit commencer par une lettre ou un trait de soulignement, etc.). Par exemple, si un nom de champ de base de données ne répond pas à ces critères, il peut être alias vers un nom conforme via des mappages.
Flexibilité: cet alias ajoute une couche d’abstraction entre le schéma de base de données et l’API, ce qui permet de modifier l’un d’eux sans nécessiter de modifications dans l’autre. Par exemple, une modification de nom de champ dans la base de données ne nécessite pas de mise à jour de la documentation de l’API ou du code côté client si le mappage reste cohérent.
'obfuscation de nom de champ: le mappage permet l’obfuscation des noms de champs, ce qui peut empêcher les utilisateurs non autorisés de déduire des informations sensibles sur le schéma de base de données ou la nature des données stockées.
Protection des informations propriétaires: en renommant des champs, vous pouvez également protéger les noms propriétaires ou la logique métier qui peut être suggéré par le biais des noms de champs d’origine de la base de données.
Relations (entités)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity} |
relationships |
objet | ❌ Non | Aucun |
Cette section mappe un ensemble de définitions de relation qui mappent la façon dont les entités sont liées à d’autres entités exposées. Ces définitions de relation peuvent également inclure des détails sur les objets de base de données sous-jacents utilisés pour prendre en charge et appliquer les relations. Les objets définis dans cette section sont exposés en tant que champs GraphQL dans l’entité associée. Pour plus d’informations, consultez répartition des relations du générateur d’API de données.
Note
Les relations sont uniquement pertinentes pour les requêtes GraphQL. Les points de terminaison REST accèdent à une seule entité à la fois et ne peuvent pas retourner les types imbriqués.
La section relationships décrit comment les entités interagissent dans le générateur d’API de données, détaillent les associations et la prise en charge potentielle des bases de données pour ces relations. La propriété relationship-name pour chaque relation est requise et doit être unique dans toutes les relations d’une entité donnée. Les noms personnalisés garantissent des connexions claires, identifiables et conservent l’intégrité du schéma GraphQL généré à partir de ces configurations.
| Relation | Cardinalité | Exemple |
|---|---|---|
| un-à-plusieurs | many |
Une entité de catégorie peut être liée à de nombreuses entités todo |
| plusieurs à un | one |
De nombreuses entités todo peuvent se rapporter à une entité de catégorie |
| plusieurs-à-plusieurs | many |
Une entité todo peut être liée à de nombreuses entités utilisateur, et une entité utilisateur peut se rapporter à de nombreuses entités todo |
Format
{
"entities": {
"<entity-name>": {
"relationships": {
"<relationship-name>": {
"cardinality": "one" | "many",
"target.entity": "<string>",
"source.fields": ["<string>"],
"target.fields": ["<string>"],
"linking.object": "<string>",
"linking.source.fields": ["<string>"],
"linking.target.fields": ["<string>"]
}
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
cardinality |
✔️ Oui | chaîne d’énumération | Aucun |
target.entity |
✔️ Oui | corde | Aucun |
source.fields |
❌ Non | tableau de chaînes | Aucun |
target.fields |
❌ Non | tableau de chaînes | Aucun |
linking.<object-or-entity> |
❌ Non | corde | Aucun |
linking.source.fields |
❌ Non | tableau de chaînes | Aucun |
linking.target.fields |
❌ Non | tableau de chaînes | Aucun |
Exemples
Lorsque vous envisagez des relations, il est préférable de comparer les différences entre un-à-plusieurs, plusieurs-à-un et des relations plusieurs-à-plusieurs.
Un-à-plusieurs
Tout d’abord, prenons un exemple de relation avec l’entité Category exposée avec une relation un-à-plusieurs avec l’entité Book exposée. Ici, la cardinalité est définie sur many. Chaque Category peut avoir plusieurs entités Book associées, tandis que chaque entité Book n’est associée qu’à une seule entité Category.
{
"entities": {
"Book": {
...
},
"Category": {
"relationships": {
"category_books": {
"cardinality": "many",
"target.entity": "Book",
"source.fields": [ "id" ],
"target.fields": [ "category_id" ]
}
}
}
}
}
Dans cet exemple, la liste source.fields spécifie le champ id de l’entité source (Category). Ce champ est utilisé pour se connecter à l’élément associé dans l’entité target. À l’inverse, la liste target.fields spécifie le champ category_id de l’entité cible (Book). Ce champ est utilisé pour se connecter à l’élément associé dans l’entité source.
Avec cette relation définie, le schéma GraphQL exposé résultant doit ressembler à cet exemple.
type Category
{
id: Int!
...
books: [BookConnection]!
}
Plusieurs-à-un
Ensuite, envisagez plusieurs-à-un qui définit la cardinalité sur one. L’entité Book exposée peut avoir une entité Category associée unique. L’entité Category peut avoir plusieurs entités Book associées.
{
"entities": {
"Book": {
"relationships": {
"books_category": {
"cardinality": "one",
"target.entity": "Category",
"source.fields": [ "category_id" ],
"target.fields": [ "id" ]
}
},
"Category": {
...
}
}
}
}
Ici, la liste source.fields spécifie que le champ category_id de l’entité source (Book) fait référence au champ id de l’entité cible associée (Category). Inversement, la liste target.fields spécifie la relation inverse. Avec cette relation, le schéma GraphQL obtenu inclut désormais un mappage de livres à catégories.
type Book
{
id: Int!
...
category: Category
}
Plusieurs-à-plusieurs
Enfin, une relation plusieurs-à-plusieurs est définie avec une cardinalité de many et plus de métadonnées pour définir les objets de base de données utilisés pour créer la relation dans la base de données de stockage. Ici, l’entité Book peut avoir plusieurs entités Author et à l’inverse, l’entité Author peut avoir plusieurs entités Book.
{
"entities": {
"Book": {
"relationships": {
...,
"books_authors": {
"cardinality": "many",
"target.entity": "Author",
"source.fields": [ "id" ],
"target.fields": [ "id" ],
"linking.object": "dbo.books_authors",
"linking.source.fields": [ "book_id" ],
"linking.target.fields": [ "author_id" ]
}
},
"Category": {
...
},
"Author": {
...
}
}
}
}
Dans cet exemple, les source.fields et les target.fields indiquent que la table de relations utilise l’identificateur principal (id) des entités source (Book) et cible (Author). Le champ linking.object spécifie que la relation est définie dans l’objet de base de données dbo.books_authors. De plus, linking.source.fields spécifie que le champ book_id de l’objet de liaison fait référence au champ id de l’entité Book et linking.target.fields spécifie que le champ author_id de l’objet de liaison fait référence au champ id de l’entité Author.
Cet exemple peut être décrit à l’aide d’un schéma GraphQL similaire à cet exemple.
type Book
{
id: Int!
...
authors: [AuthorConnection]!
}
type Author
{
id: Int!
...
books: [BookConnection]!
}
Cardinalité
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
cardinality |
corde | ✔️ Oui | Aucun |
Spécifie si l’entité source actuelle est liée à une seule instance de l’entité cible ou à plusieurs.
Valeurs
Voici la liste des valeurs autorisées pour cette propriété :
| Description | |
|---|---|
one |
La source n’est liée qu’à un seul enregistrement de la cible |
many |
La source peut se rapporter à des enregistrements de zéro à plusieurs à partir de la cible |
Entité cible
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
target.entity |
corde | ✔️ Oui | Aucun |
Nom de l’entité définie ailleurs dans la configuration qui est la cible de la relation.
Champs sources
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
source.fields |
tableau | ❌ Non | Aucun |
Paramètre facultatif permettant de définir le champ utilisé pour le mappage dans l’entité source utilisée pour se connecter à l’élément associé dans l’entité cible.
Pourboire
Ce champ n’est pas obligatoire s’il existe une clé étrangère contrainte sur la base de données entre les deux objets de base de données qui peuvent être utilisés pour déduire automatiquement la relation.
Champs cibles
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
target.fields |
tableau | ❌ Non | Aucun |
Paramètre facultatif permettant de définir le champ utilisé pour le mappage dans l’entité cible cible utilisée pour se connecter à l’élément associé dans l’entité source.
Pourboire
Ce champ n’est pas obligatoire s’il existe une clé étrangère contrainte sur la base de données entre les deux objets de base de données qui peuvent être utilisés pour déduire automatiquement la relation.
Liaison d’un objet ou d’une entité
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.object |
corde | ❌ Non | Aucun |
Pour les relations plusieurs-à-plusieurs, le nom de l’objet ou de l’entité de base de données qui contient les données nécessaires pour définir une relation entre deux autres entités.
Liaison de champs sources
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.source.fields |
tableau | ❌ Non | Aucun |
Nom de l’objet de base de données ou du champ d’entité lié à l’entité source.
Liaison de champs cibles
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.relationships |
linking.target.fields |
tableau | ❌ Non | Aucun |
Nom de l’objet de base de données ou du champ d’entité lié à l’entité cible.
Cache (entités)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
booléen | ❌ Non | Faux |
Active et configure la mise en cache de l’entité.
Format
You're right; the formatting doesn't match your style. Here’s the corrected version following your preferred documentation format:
```json
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <true> (default) | <false>,
"ttl-seconds": <integer; default: 5>
}
}
}
}
Propriétés
| Propriété | Obligatoire | Type | Faire défaut |
|---|---|---|---|
enabled |
❌ Non | booléen | Faux |
ttl-seconds |
❌ Non | entier | 5 |
Exemples
Dans cet exemple, le cache est activé et les éléments expirent après 30 secondes.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 30
}
}
}
}
Activé (entité cache)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.{entity}.cache |
enabled |
booléen | ❌ Non | Faux |
Active la mise en cache de l’entité.
Prise en charge des objets de base de données
| Type d’objet | Prise en charge du cache |
|---|---|
| Table | ✅ Oui |
| Vue | ✅ Oui |
| Procédure stockée | ✖️ Non |
| Conteneur | ✖️ Non |
Prise en charge de l’en-tête HTTP
| En-tête de requête | Prise en charge du cache |
|---|---|
no-cache |
✖️ Non |
no-store |
✖️ Non |
max-age |
✖️ Non |
public |
✖️ Non |
private |
✖️ Non |
etag |
✖️ Non |
Format
{
"entities": {
"<entity-name>": {
"cache": {
"enabled": <boolean> (default: false)
}
}
}
}
Exemples
Dans cet exemple, le cache est désactivé.
{
"entities": {
"Author": {
"cache": {
"enabled": false
}
}
}
}
Durée de vie en secondes (entité cache)
| Parent | Propriété | Type | Obligatoire | Faire défaut |
|---|---|---|---|---|
entities.cache |
ttl-seconds |
entier | ❌ Non | 5 |
Configure la valeur de durée de vie (TTL) en secondes pour les éléments mis en cache. Une fois ce temps écoulé, les éléments sont automatiquement supprimés du cache. La valeur par défaut est 5 secondes.
Format
{
"entities": {
"<entity-name>": {
"cache": {
"ttl-seconds": <integer; inherited>
}
}
}
}
Exemples
Dans cet exemple, le cache est activé et les éléments expirent après 15 secondes. En cas d’omission, ce paramètre hérite du paramètre global ou de la valeur par défaut.
{
"entities": {
"Author": {
"cache": {
"enabled": true,
"ttl-seconds": 15
}
}
}
}