Réseaux sociaux avec Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Vivre dans une société massivement interconnectée signifie qu’à un moment donné, vous vous joignez à un réseau social. Vous utilisez les réseaux sociaux pour rester en contact avec vos amis, vos collègues, votre famille, ou parfois pour partager votre passion avec des personnes ayant des intérêts communs.
En tant qu’ingénieurs ou développeurs, vous vous demandez peut-être comment ces réseaux stockent et interconnectent vos données. Ou peut-être vous a-t-on déjà chargé de créer ou de concevoir un nouveau réseau social pour un marché spécifique. C’est à ce moment qu’une question importante se pose : comment sont stockées toutes ces données ?
Supposez que vous créez un nouveau réseau social, où vos utilisateurs peuvent publier des articles accompagnés de contenus multimédias comme des images, des vidéos ou même de la musique. Les utilisateurs peuvent commenter les publications et attribuer des points pour créer des classements. Les utilisateurs peuvent afficher un flux de messages avec lequel ils interagissent sur la page d’accueil du site web principal. Cette méthode ne semble pas complexe de prime abord, mais par souci de simplicité nous allons nous arrêter là. (Vous pouvez étudier les flux utilisateur personnalisés influencés par les relations, mais ça n’est pas l’objectif de cet article.)
Alors, comment et où stockez-vous ces données ?
Vous disposez sans doute d’une expérience d’utilisation des bases de données SQL ou avez des connaissances de base sur la modélisation relationnelle des données. Vous commencerez peut-être à concevoir quelque chose comme ceci :
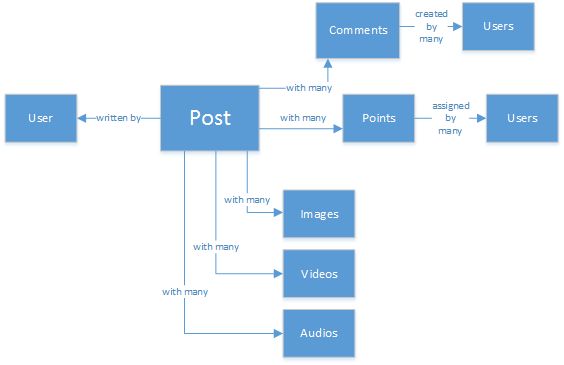
Une structure de données tout à fait normalisée et agréable... qui n’est pas extensible.
Ne vous méprenez pas, j’ai travaillé avec des bases de données SQL toute ma vie. Elles sont très utiles, mais comme chaque modèle, pratique et plateforme logicielle, elles ne sont pas parfaites pour chaque scénario.
Pourquoi SQL n’est-il pas le meilleur choix dans ce scénario ? Examinons la structure d’une publication. Si je souhaitais l’afficher dans un site web ou une application, je devrais effectuer une requête avec... huit jointures de tables (!) rien que pour afficher une seule publication. À présent, imaginez un flux de publications qui se chargent et s’affichent de façon dynamique, et vous verrez peut-être où je veux en venir.
Vous pourriez utiliser une énorme instance SQL suffisamment puissante pour résoudre des milliers de requêtes avec de nombreuses jointures pour délivrer votre contenu. Mais pourquoi procéder ainsi alors qu’il existe une solution plus simple ?
L’utilisation de NoSQL
Cet article vous montre comment modéliser les données de votre plateforme sociale avec la base de données NoSQL d’Azure Azure Cosmos DB à moindre coût. Il explique également comment utiliser d’autres fonctionnalités d’Azure Cosmos DB telles que l’API pour Gremlin. Avec une approche NoSQL, le stockage des données au format JSON et l’application de la dénormalisation, la publication, auparavant si compliquée, peut être transformée en un seul document :
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Et elle peut être obtenue avec une seule requête, sans jointure. Cette requête est beaucoup plus simple et directe. Elle nécessite moins de ressources pour un meilleur résultat, ce qui est parfait du point de vue du budget.
Azure Cosmos DB garantit que toutes les propriétés sont indexées avec son indexation automatique. L’indexation automatique peut même être personnalisée. L’approche sans schéma nous permet de stocker des documents avec des structures différentes et dynamiques. Plus tard, vous souhaiterez peut-être associer une liste de catégories ou de hashtags aux publications ? Azure Cosmos DB gérera les nouveaux documents avec les attributs supplémentaires sans aucun travail supplémentaire de notre part.
Les commentaires sur une publication peuvent être traités comme d’autres publications avec une propriété parente. (Cette pratique simplifie le mappage d’objets.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Et toutes les interactions sociales peuvent être stockées sur un objet distinct en tant que compteurs :
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
La création de flux consiste simplement à créer des documents qui peuvent contenir une liste des ID des publications avec un ordre de pertinence donné :
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Vous pourriez avoir un flux « récent » avec les publications classées par date de création. Ou vous pourriez avoir un flux « populaire » regroupant les publications ayant le plus de mentions J’aime durant les dernières 24 heures. Vous pourriez même implémenter un flux personnalisé pour chaque utilisateur basé sur une logique comme les abonnés et les centres d’intérêt. Il s’agirait toujours d’une liste de publications. La question est de savoir comment créer ces listes, mais les performances de lecture ne sont pas affectées. Une fois que vous avez obtenu une de ces listes, vous émettez une requête unique à Azure Cosmos DB avec le mot clé IN pour obtenir plusieurs pages de publications simultanément.
Les flux de commentaires peuvent être créés à l’aide des processus d’arrière-plan d’Azure App Services : Webjobs. Une fois qu’une publication est créée, le traitement en arrière-plan peut être déclenché avec des files d’attente de Stockage Azure et des tâches webjobs déclenchées avec le SDK Azure WebJobs, implémentant la propagation des publications dans des flux basés sur votre propre logique personnalisée.
Les points et les J’aime attribués à une publication peuvent être traités de manière différée à l’aide de cette même technique pour créer un environnement cohérent.
Cela est plus compliqué pour les abonnés. Azure Cosmos DB a une taille de document limite. Ainsi, la lecture ou l’écriture de documents volumineux peut avoir une incidence sur la scalabilité de votre application. Vous pouvez envisager de stocker les abonnés dans un document avec cette structure :
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Cette structure peut fonctionner pour un utilisateur avec quelques milliers abonnés. Toutefois, si des célébrités rejoignent les rangs, cette approche aboutira à un document de grande taille, qui pourrait au final atteindre la limite de taille des documents.
Pour résoudre ce problème, vous pouvez adopter une approche mixte. Dans le cadre du document Statistiques de l’utilisateur, vous pouvez stocker le nombre d’abonnés :
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Vous pouvez stocker le graphe réel d’abonnés à l’aide de l’API Gremlin d’Azure Cosmos DB afin de créer des sommets pour chaque utilisateur et des arêtes qui gèrent les relations de type « A-suit-B ». Avec l’API pour Gremlin, vous pouvez obtenir les abonnés d’un utilisateur donné et créer des requêtes plus complexes pour suggérer des personnes en commun. Si vous ajoutez au graphe les catégories de contenus que les personnes aiment ou apprécient, vous pouvez commencer à créer des expériences qui incluent la détection de contenu intelligente, la suggestion de contenu aimé par les personnes que vous suivez ou la recherche de personnes avec lesquelles vous pourriez avoir beaucoup en commun.
Le document sur les statistiques utilisateur peut toujours servir à créer des cartes dans l’interface utilisateur ou des préversions de profil rapides.
Duplication des données et modèle « Échelle »
Comme vous l’avez peut-être remarqué dans le document JSON référence une publication, il existe de nombreuses occurrences d’un utilisateur. Ces doublons signifient que les informations qui décrivent un utilisateur peuvent être présentes à plusieurs endroits, en raison de la dénormalisation.
Pour obtenir des requêtes plus rapides, vous acceptez la duplication des données. Le problème de cet effet secondaire est que si les données d’un utilisateur changent, vous devez rechercher toutes les activités auxquelles il a participé et les mettre toutes à jour. Ceci ne semble pas pratique.
Vous allez le résoudre en identifiant les attributs clés d’un utilisateur que vous affichez dans votre application pour chaque activité. Si vous montrez une publication dans votre application et que vous affichez seulement le nom et la photo du créateur, pourquoi stocker toutes les données de l’utilisateur dans l’attribut « createdBy » ? Si, pour chaque commentaire, vous affichez seulement la photo de l’utilisateur, vous n’avez pas vraiment besoin des autres informations le concernant. C’est là que ce que j’appelle le « modèle Échelle » entre en jeu.
Prenons comme exemple les informations utilisateur :
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
En examinant ces informations, vous pouvez rapidement détecter les informations critiques et celles qui ne le sont pas, créant ainsi une « échelle » :

L’étape la plus petite est appelée UserChunk, l’information minimale qui identifie un utilisateur et qui est utilisée pour la duplication des données. En limitant la taille des données dupliquées aux seules informations que vous allez « montrer », vous réduisez la possibilité de procéder à des mises à jour massives.
L’étape intermédiaire est appelée Utilisateur. Ce sont les données complètes qui seront employées pour les requêtes qui dépendent le plus des performances sur Azure Cosmos DB, les données les plus consultées et les plus essentielles. Elles incluent les informations représentées par un UserChunk.
L’étape la plus importante est appelée Utilisateur étendu. Elle inclut les informations utilisateur essentielles et d’autres données qui n’ont pas besoin d’être lues rapidement ou ont une utilisation éventuelle, comme le processus de connexion. Ces données peuvent être stockées en dehors d’Azure Cosmos DB, dans Azure SQL Database ou des tables Stockage Azure.
Pourquoi fractionner les données de l’utilisateur et même stocker ces informations dans des endroits différents ? Parce que du point de vue du niveau de performance, plus les documents sont volumineux, plus les requêtes sont coûteuses. Maintenez les documents à une taille minimale, avec les informations correctes pour exécuter toutes vos requêtes dépendantes des performances pour votre réseau social. Stockez les informations supplémentaires pour des scénarios éventuels comme les modifications de profil complètes, les connexions et l’exploration des données pour l’analyse de l’utilisation et les initiatives de Big Data. Peu importe que la collecte de données pour l’analyse soit plus lente, car elle est exécutée sur Azure SQL Database. Ce qui vous importe, c’est que vos utilisateurs bénéficient d’une expérience rapide et allégée. Un utilisateur, stocké sur Azure Cosmos DB, ressemblerait à ce code :
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Et une publication ressemblerait à ce qui suit :
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
En cas de modification où l’un des attributs du bloc est affecté, il est facile de trouver les documents affectés. Il suffit d’utiliser des requêtes qui pointent vers les attributs indexés, par exemple SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", puis de mettre les blocs à jour.
La zone de recherche
Les utilisateurs vont heureusement générer beaucoup de contenu. Et vous devriez être en mesure de fournir la possibilité de rechercher et de trouver du contenu qui n’est peut-être pas directement dans leur flux de contenu, car vous ne suivez pas les créateurs ou vous essayez peut-être simplement de trouver une publication créée il y a six mois.
Comme vous utilisez Azure Cosmos DB, vous pouvez facilement implémenter un moteur de recherche avec Recherche Azure AI en quelques minutes et sans taper une seule ligne de code (autre que le processus de recherche et l’interface utilisateur).
Pourquoi ce processus est-il si simple ?
Le service Recherche Azure AI implémente des indexeurs. Ce sont des processus d’arrière-plan intégrés dans vos référentiels de données et qui ajoutent, mettent à jour ou suppriment automatiquement vos objets dans les index. Ils prennent en charge les indexeurs Azure SQL Database, les indexeurs d’objets blob Azure et les indexeurs Azure Cosmos DB. Le passage des informations d’Azure Cosmos DB à la Recherche Azure AI est simple. Ces deux technologies stockent les informations au format JSON. Il vous suffit donc de créer votre index et de mapper les attributs de vos documents à indexer. Et voilà ! En fonction de la taille des données, tout votre contenu est disponible pour la recherche en quelques minutes, grâce à la meilleure solution Search-as-a-Service de l’infrastructure cloud.
Pour plus d’informations sur Recherche Azure AI, vous pouvez consulter le document Hitchhiker’s Guide to Search.
Les connaissances sous-jacentes
Après avoir stocké ce contenu dont la taille augmente chaque jour, vous vous demanderez peut-être : Que puis-je faire avec toutes ces flux d’informations venant de mes utilisateurs ?
La réponse est simple : Faites-les travailler et apprenez-en quelque chose.
Que pouvez-vous découvrir ? Voici quelques exemples simples : l’analyse des sentiments, les recommandations de contenu basées sur les préférences d’un utilisateur ou même un modérateur de contenu automatique, qui vérifie que tout le contenu publié par votre réseau social est adapté à un environnement familial.
Maintenant que j’ai votre attention, vous pensez sans doute qu’il vous faut un doctorat en sciences mathématiques pour extraire ces modèles et ces informations de fichiers et de bases de données simples, mais vous avez tort.
Azure Machine Learning , est un service cloud entièrement géré qui vous permet de créer des flux de travail à l’aide d’algorithmes dans une interface simple de type glisser-déposer, de coder vos propres algorithmes en R, ou d’utiliser certaines des API déjà créées et prêtes à l’emploi, telles que : Analyse de texte, Modérateur de contenu ou Recommandations.
Pour réaliser l’un de ces scénarios d’apprentissage automatique, vous pouvez utiliser Azure Data Lake afin d’ingérer les informations de différentes sources. Vous pouvez également utiliser U-SQL pour traiter les informations et générer une sortie qui peut être traitée par Azure Machine Learning.
Une autre possibilité consiste à utiliser Azure AI services pour analyser le contenu de vos utilisateurs. Non seulement vous allez mieux le comprendre (en analysant ce qu’ils écrivent avec l’API Analyse de texte), mais vous allez également pouvoir détecter du contenu indésirable ou réservé aux adultes, et agir en conséquence avec l’API Vision par ordinateur. Azure AI services comprend un grand nombre de solutions prêtes à l’emploi ne nécessitant aucune connaissance en Machine Learning.
Une expérience sociale à l’échelle de la planète
Il existe un dernier sujet tout aussi important à traiter : la scalabilité. Quand vous concevez une architecture, chaque composant doit pouvoir être mis à l’échelle de façon autonome. Vous devrez un jour ou l’autre traiter davantage de données, ou vous souhaiterez avoir une couverture géographique plus étendue. Heureusement, Azure Cosmos DB offre une solution clé en main pour gérer ces deux tâches.
Azure Cosmos DB prend en charge nativement le partitionnement dynamique. Il crée automatiquement des partitions basées sur une clé de partition donnée, qui est définie comme attribut dans vos documents. La définition de la clé de partition appropriée doit être effectuée au moment de la conception. Pour plus d'informations, consultez Partitionnement dans Azure Cosmos DB.
Dans le cas d’une expérience sociale, vous devez aligner votre stratégie de partitionnement sur la manière dont vous interrogez et écrivez. (Par exemple, des lectures au sein de la même partition sont souhaitables, et vous devez éviter les « zones réactives » en répartissant les écritures sur plusieurs partitions.) Les options disponibles sont les suivantes : partitions basées sur une clé temporaire (jour/mois/semaine), par catégorie de contenu, par région géographique ou par utilisateur. Tout cela dépend de la façon dont vous interrogerez les données et les présenterez dans votre expérience sociale.
Azure Cosmos DB exécute vos requêtes (notamment les agrégats) de façon transparente sur toutes vos partitions ; vous n’avez donc pas besoin d’ajouter de logique à mesure que vos données augmentent.
Avec le temps, le trafic et la consommation des ressources augmenteront (mesurés en unité de requête ou RU). Vous lirez et vous écrirez plus fréquemment à mesure que votre base d’utilisateurs se développera. Ces utilisateurs commenceront à créer et à lire plus de contenu. La possibilité de mise à l’échelle du débit est donc indispensable. Augmenter vos unités de requête est très facile. Vous pouvez le faire en quelques clics sur le portail Azure ou en émettant des commandes par le biais de l’API.
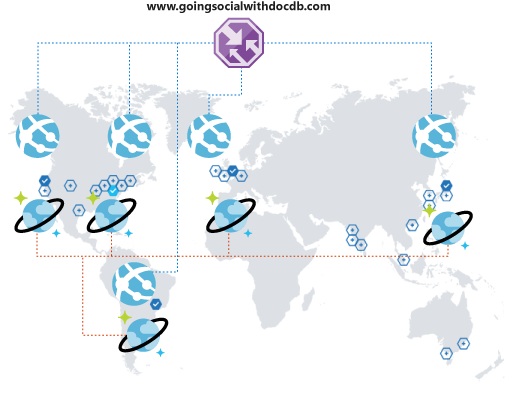
Que se passe-t-il si tout va de mieux en mieux ? Supposez que des utilisateurs d’une autre région / d’un autre pays ou continent découvrent votre plateforme et commencent à l’utiliser. Quelle bonne surprise !
Mais vous constatez rapidement que leur expérience avec votre plateforme n’est pas optimale. Ils sont si éloignés de votre région opérationnelle que la latence est catastrophique. Évidemment, vous ne souhaitez pas perdre ces nouveaux utilisateurs. Heureusement, il existe un moyen facile de développer votre visibilité globale .
Azure Cosmos DB vous permet de répliquer vos données globalement et de manière transparente en quelques clics, mais aussi de choisir automatiquement parmi les régions disponibles à partir de votre code client. Cela signifie également que vous pouvez avoir plusieurs régions de basculement.
Lorsque vous répliquez vos données globalement, vous devez vous assurer que vos clients peuvent en tirer parti. Si vous utilisez un front-end web ou que vous accédez aux API à partir de clients mobiles, vous pouvez déployer Azure Traffic Manager et cloner votre Azure App Service dans toutes les régions de votre choix en utilisant une configuration des performances pour prendre en charge votre couverture étendue globale. Quand vos clients accèdent à votre front-end ou à vos API, ils sont redirigés vers l’instance App Service la plus proche qui, à son tour, se connecte au réplica Azure Cosmos DB local.
Conclusion
Cet article tente de vous éclairer sur les alternatives de création de réseaux sociaux entièrement sur Azure avec des services à faible coût. Il offre de bons résultats, avec l’utilisation d’une solution de stockage à plusieurs niveaux et une distribution des données appelée « Échelle ».
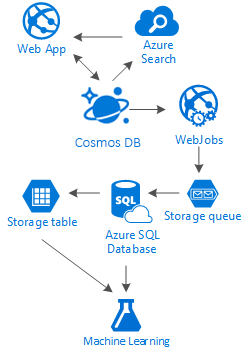
La vérité est qu’il n’existe aucune solution parfaite pour ce genre de scénarios. C’est la synergie créée par la combinaison d’excellents services qui nous permet de concevoir des expériences exceptionnelles : la rapidité et la liberté d’Azure Cosmos DB pour une application sociale intéressante, l’intelligence d’une solution de recherche de premier ordre comme Recherche Azure AI, la flexibilité d’Azure App Services pour héberger non pas des applications indépendantes du langage, mais des processus d’arrière-plan puissants, ainsi que les outils de stockage Azure et Azure SQL Database extensibles pour le stockage de grandes quantités de données et la puissance d’analyse d’Azure Machine Learning pour créer les connaissances et l’intelligence décisionnelle capables de fournir un commentaire à vos processus et de nous aider à délivrer le bon contenu aux bons utilisateurs.
Étapes suivantes
Pour en savoir plus sur les cas d’usage d’Azure Cosmos DB, consultez Cas d’utilisation courants et scénarios pour Azure Cosmos DB.