Modéliser des applications SaaS multilocataires dans Azure Cosmos DB for PostgreSQL
S’APPLIQUE À : ![]() Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
ID de locataire comme clé de partition
L’ID de locataire est la colonne à la racine de la charge de travail, ou le haut de la hiérarchie dans votre modèle de données. Par exemple, dans ce schéma de commerce électronique SaaS, il s’agit de l’ID de boutique :
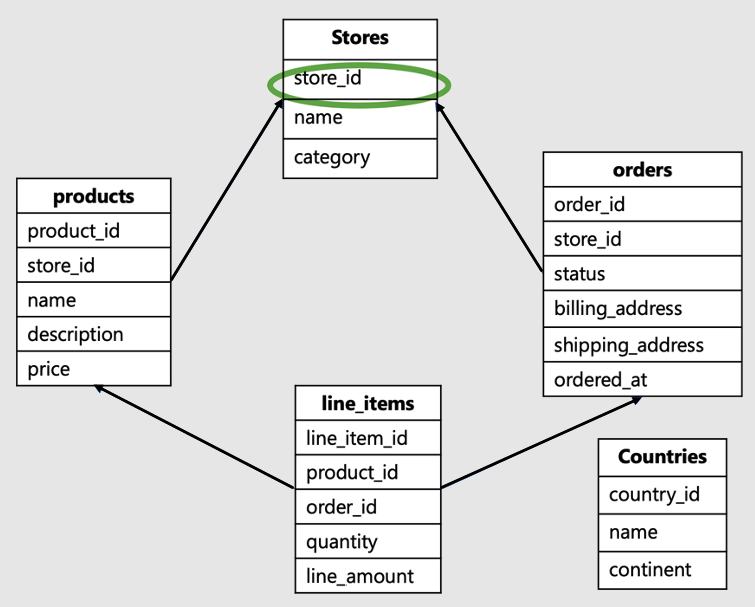
Ce modèle de données serait typiquement adapté à une entreprise telle que Shopify. Il héberge des sites pour plusieurs boutiques en ligne, où chaque boutique interagit avec ses propres données.
- Ce modèle de données comporte un ensemble de tables : boutiques, produits, commandes, articles de ligne et pays.
- La table des boutiques se trouve en haut de la hiérarchie. Les produits, les commandes et les articles de ligne sont tous associés aux boutiques, donc situés plus bas dans la hiérarchie.
- La table des pays n’est pas liée aux boutiques individuelles, mais à toutes les boutiques.
Dans cet exemple, store_id, qui se trouve en haut de la hiérarchie, est l’identificateur du locataire. C’est la clé de partition appropriée. Choisir store_id en tant que clé de partition active la colocalisation de données entre toutes les tables pour une seule boutique sur un seul Worker.
La colocalisation des tables par boutique présente des avantages :
- Fournit la couverture SQL comme les clés étrangères, les opérations JOIN. Les transactions pour un seul locataire sont localisées sur un seul nœud Worker où chaque locataire existe.
- Atteint des performances en milliseconde à un seul chiffre. Les requêtes d’un seul locataire sont routées vers un seul nœud au lieu d’être parallélisées, ce qui permet d’optimiser les tronçons réseau et de mettre à l’échelle le calcul/la mémoire.
- Elle évolue. À mesure que le nombre de locataires augmente, vous pouvez ajouter des nœuds et rééquilibrer les locataires en fonction des nouveaux nœuds, ou même isoler les locataires volumineux sur leurs propres nœuds. L’isolation du locataire vous permet de fournir des ressources dédiées.
Modèle de données optimal pour les applications multi-locataire
Dans cet exemple, nous devons distribuer les tables spécifiques à une boutique par ID de boutique et désigner countries comme table de référence.
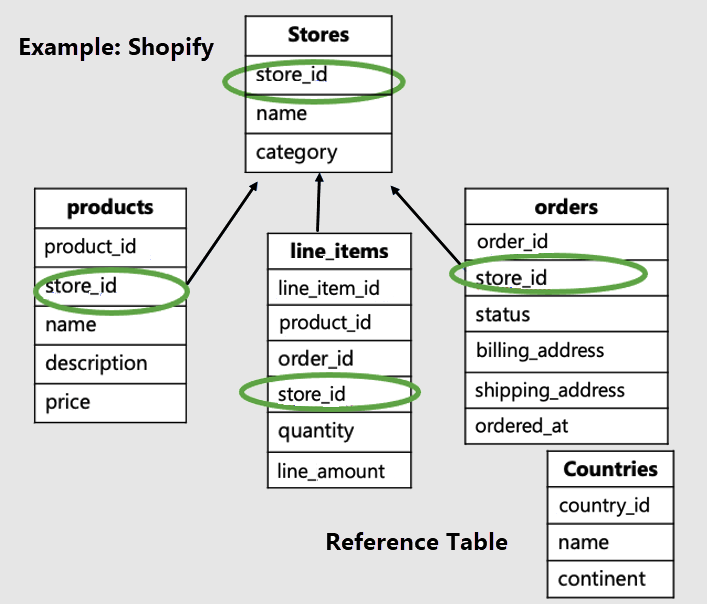
Notez que les tables spécifiques au locataire ont l’ID du locataire et sont distribuées. Dans notre exemple, les boutiques, les produits et les articles de ligne sont distribués. Les autres tables sont des tables de référence. Dans notre exemple, la table des pays est une table de référence.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Les tables volumineuses doivent toutes avoir l’ID du locataire.
- Si vous migrez une application multi-locataire existante vers Azure Cosmos DB for PostgreSQL, vous devrez peut-être dénormaliser un peu et ajouter la colonne ID de locataire à des tables volumineuses si elle est manquante, puis compléter les valeurs manquantes de la colonne.
- Pour les nouvelles applications sur Azure Cosmos DB for PostgreSQL, vérifiez que l’ID de locataire est présent sur toutes les tables spécifiques du locataire.
Veillez à inclure l’ID de locataire sur les contraintes de clé primaire, unique et étrangère sur les tables distribuées sous la forme d’une clé composite. Par exemple, si une table a une clé primaire id, transformez-la en clé composite (tenant_id,id).
Il n’est pas nécessaire de modifier les clés pour les tables de référence.
Considérations relatives aux requêtes pour optimiser les performances
Les requêtes distribuées filtrées sur l’ID de locataire s’exécutent plus efficacement dans les applications multi-locataire. Vérifiez que vos requêtes sont toujours étendues à un seul locataire.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
Il est nécessaire d’ajouter le filtre d’ID de locataire même si les conditions de filtre d’origine identifient sans ambiguïté les lignes souhaitées. Le filtre d’ID de locataire, tout en semblant redondant, indique à Azure Cosmos DB for PostgreSQL comment acheminer la requête vers un seul nœud Worker.
De même, lorsque vous joignez deux tables distribuées, vérifiez que les deux tables sont étendues à un seul locataire. La définition de l’étendue peut être effectuée en veillant à ce que les conditions de jointure incluent l’ID de locataire.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
Il existe des bibliothèques d’assistance pour plusieurs frameworks d’application populaires qui facilitent l’intégration d’un ID de locataire dans les requêtes. Voici des instructions :
Étapes suivantes
Nous avons terminé d’explorer la modélisation de données pour les applications scalables. L’étape suivante consiste à connecter et interroger la base de données avec le langage de programmation de votre choix.