Modéliser des applications transactionnelles à haut débit dans Azure Cosmos DB for PostgreSQL
S’APPLIQUE À : ![]() Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Filtre commun en tant que clé de partition
Pour sélectionner la clé de partition pour une application transactionnelle à haut débit, suivez ces instructions :
- Choisissez une colonne utilisée pour les recherches de points et présente dans la plupart des opérations de création, de lecture, de mise à jour et de suppression.
- Choisissez une colonne qui est une dimension naturelle dans les données ou un élément central de l’application. Par exemple :
- Dans une charge de travail IoT,
device_idest une bonne colonne de distribution.
- Dans une charge de travail IoT,
Le choix d’une bonne clé de partition permet d’optimiser les tronçons réseau, tout en tirant parti de la mémoire et du calcul pour atteindre une latence de l’ordre de la milliseconde.
Modèle de données optimal pour les applications à haut débit
Voici un exemple de modèle de données pour une application IoT qui capture les données de télémétrie (données de série chronologique) à partir d’appareils. Il existe deux tables pour capturer les données de télémétrie : devices et events. Il peut y avoir d’autres tables, mais elles ne sont pas couvertes dans cet exemple.
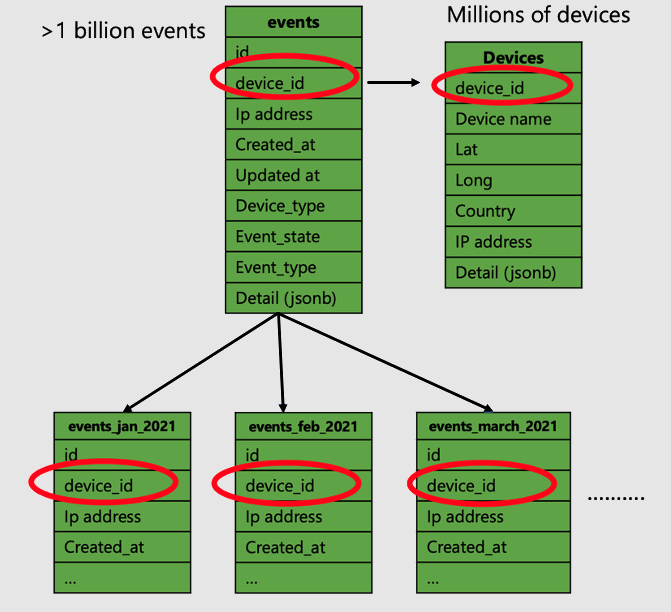
Lors de la création d’une application à haut débit, gardez à l’esprit une certaine optimisation.
- Distribuez des tables volumineuses sur une colonne commune qui est un élément central de l’application et la colonne que votre application interroge principalement. Dans l’exemple ci-dessus d’une application IoT,
device_idest cette colonne qui colocalise les événements et les tables d’appareils. - Le reste des petites tables peut être des tables de référence.
- Comme les applications IoT ont une dimension de temps, partitionnez vos tables distribuées en fonction de l’heure. Vous pouvez utiliser des fonctionnalités natives de série chronologique Azure Cosmos DB pour PostgreSQL pour créer et gérer des partitions.
- Le partitionnement permet de filtrer efficacement les données pour les requêtes avec des filtres de temps.
- L’expiration des anciennes données est également rapide, à l’aide de la commande DROP vs DELETE.
- Le tableau des événements de notre exemple est partitionné par mois.
- Utilisez le type de données JSONB pour stocker des données semi-structurées. Les données de télémétrie des appareils ne sont généralement pas structurées, chaque appareil a ses propres métriques.
- Dans notre exemple, la table d’événements a une colonne
detail, qui est JSONB.
- Dans notre exemple, la table d’événements a une colonne
- Si votre application IoT nécessite des fonctionnalités géospatiales, vous pouvez utiliser l’extension PostGIS, que Azure Cosmos DB for PostgreSQL prend en charge en mode natif.
Étapes suivantes
Nous avons terminé d’explorer la modélisation de données pour les applications scalables. L’étape suivante consiste à connecter et interroger la base de données avec le langage de programmation de votre choix.