Partitionnement et mise à l’échelle horizontale dans Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB utilise le partitionnement pour procéder à la mise à l’échelle des conteneurs au sein d’une base de données afin de répondre aux besoins de performances de votre application. Les éléments d’un conteneur sont divisés en sous-ensembles distincts appelés partitions logiques. Les partitions logiques sont formées en fonction de la valeur d’une clé de partition associée à chaque élément d’un conteneur. Tous les éléments d’une partition logique possèdent la même valeur de clé de partition.
Par exemple, un conteneur contient des éléments. Chaque élément a une valeur unique pour la propriété UserID. Si UserID sert de clé de partition pour les éléments présents dans un conteneur et qu’il existe 1 000 valeurs UserID uniques, 1 000 partitions logiques sont créées pour le conteneur.
Outre une clé de partition qui détermine la partition logique de l’élément, chaque élément présent dans un conteneur possède un ID d’élément (unique dans une partition logique). La combinaison de la clé de partition et de l’ID d’élément crée l’index de l’élément, qui identifie l’élément de façon unique. Le choix d’une clé de partition est une décision importante qui affecte les performances de votre application.
Cet article explique la relation entre les partitions logiques et physiques. Il présente également les bonnes pratiques pour le partitionnement et donne une vue détaillée du fonctionnement de la mise à l’échelle horizontale dans Azure Cosmos DB. Il n’est pas nécessaire de comprendre ces détails internes pour sélectionner votre clé de partition, mais nous les couvrons afin que vous puissiez avoir plus de clarté sur le fonctionnement d’Azure Cosmos DB.
Partitions logiques
Une partition logique est constituée d’un ensemble d’éléments dotés de la même clé de partition. Par exemple, dans un conteneur qui contient des données sur la nutrition, tous les éléments contiennent une propriété foodGroup. Vous pouvez utiliser foodGroup comme clé de partition pour le conteneur. Des groupes d’éléments ayant des valeurs spécifiques pour foodGroup, telles que Beef Products, Baked Products et Sausages and Luncheon Meats, forment des partitions logiques distinctes.
Une partition logique définit également la portée des transactions de base de données. Vous pouvez mettre à jour les éléments d’une partition logique via une transaction avec isolement de capture instantanée. Lorsque de nouveaux éléments sont ajoutés à un conteneur, de nouvelles partitions logiques sont créées de façon transparente par le système. Vous n’avez pas à vous soucier de la suppression d’une partition logique quand les données sous-jacentes sont supprimées.
Il n’existe pas de limite quant au nombre de partitions logiques dans votre conteneur. Chaque partition logique peut stocker jusqu’à 20 Go de données. Les bons choix de clé de partition procurent une large gamme de valeurs possibles. Par exemple, dans un conteneur dont tous les éléments contiennent une propriété foodGroup, les données de la partition logique Beef Products peuvent croître jusqu’à 20 Go. La sélection d’une clé de partition avec une large gamme de valeurs possibles garantit que le conteneur peut être mis à l’échelle.
Vous pouvez utiliser les alertes Azure Monitor pour surveiller si la taille d’une partition logique approche 20 Go.
Partitions physiques
Un conteneur est mis à l’échelle en distribuant les données et le débit sur des partitions physiques. En interne, une ou plusieurs partitions logiques sont mappées à une seule partition physique. En général, les petits conteneurs ont de nombreuses partitions logiques, mais ils n’ont besoin que d’une seule partition physique. Contrairement aux partitions logiques, les partitions physiques sont une implémentation interne du système et sont entièrement gérées par Azure Cosmos DB.
Le nombre de partitions physiques dans votre conteneur dépend des caractéristiques suivantes :
Le volume du débit provisionné (chaque partition physique peut fournir un débit allant jusqu’à 10 000 unités de requête par seconde). La limite de 10 000 RU/s pour les partitions physiques implique que les partitions logiques doivent également avoir une limite de 10 000 RU/s, car chaque partition logique est seulement mappée à une seule partition physique.
Le stockage de données total (chaque partition physique peut stocker jusqu’à 50 Go de données).
Notes
Les partitions physiques sont une implémentation interne du système et sont entièrement gérées par Azure Cosmos DB. Lorsque vous développez vos solutions, ne vous concentrez pas sur les partitions physiques, car vous ne pouvez pas les contrôler. Au lieu de cela, concentrez-vous sur vos clés de partition. Si vous choisissez une clé de partition qui répartit uniformément la consommation du débit entre les partitions logiques, vous vous assurez que la consommation du débit sur les partitions physiques est équilibrée.
Il n’existe pas de limite quant au nombre total de partitions physiques dans votre conteneur. À mesure qu’augmente la taille des données ou du débit provisionné, Azure Cosmos DB crée automatiquement des partitions physiques en divisant celles qui existent déjà. Les divisions des partitions physiques n’impactent pas la disponibilité de votre application. Après la division des partitions physiques, toutes les données d’une seule partition logique sont toujours stockées sur la même partition physique. La division d’une partition physique crée simplement un mappage de partitions logiques sur des partitions physiques.
Le débit approvisionné pour un conteneur est uniformément réparti entre les partitions physiques. Une conception de clé de partition qui ne distribue pas les requêtes de manière égale peut entraîner l’envoi d’un trop grand nombre de requêtes vers un petit sous-ensemble de partitions qui deviennent alors « chaudes ». Les partitions « chaudes » peuvent entraîner une utilisation inefficace du débit approvisionné et, par conséquent, une limitation du débit et une augmentation des coûts.
Par exemple, considérez un conteneur avec le chemin /foodGroup spécifié comme clé de partition. Le conteneur peut avoir un nombre quelconque de partitions physiques, mais dans cet exemple, nous supposons qu’il en a trois. Une partition physique unique peut contenir plusieurs clés de partition. Par exemple, la plus grande partition physique peut contenir les trois partitions logiques les plus significatives : Beef Products, Vegetable and Vegetable Productset Soups, Sauces, and Gravies.
Si vous attribuez un débit de 18 000 unités de requête par seconde (RU/s), chacune des trois partitions physiques peut utiliser 1/3 du débit total provisionné. Au sein de la partition physique sélectionnée, les clés de partition logique Beef Products, Vegetable and Vegetable Products et Soups, Sauces, and Gravies peuvent, collectivement, utiliser les 6 000 RU/s provisionnées de la partition physique. Le débit provisionné étant réparti uniformément entre les partitions physiques de votre conteneur, il est important de choisir une clé de partition qui répartit uniformément la consommation du débit. Pour plus d’informations, consultez Choisir la clé de partition logique appropriée.
Gestion des partitions logiques
Azure Cosmos DB gère de manière transparente et automatique le positionnement des partitions logiques sur les partitions physiques afin de répondre efficacement aux besoins d’extensibilité et de performances du conteneur. À mesure que le débit et le stockage requis par une application augmentent, Azure Cosmos DB déplace les partitions logiques pour répartir automatiquement la charge sur un plus grand nombre de partitions physiques. En savoir plus sur les partitions physiques.
Azure Cosmos DB utilise un partitionnement basé sur un hachage pour répartir les partitions logiques sur des partitions physiques. Azure Cosmos DB hache la valeur de la clé de partition d’un élément. Le résultat du hachage détermine la partition logique. Azure Cosmos DB alloue ensuite l’espace des hachages de clé de partition uniformément entre les partitions physiques.
Les transactions (dans les procédures stockées ou dans les déclencheurs) ne sont autorisées que pour les éléments d’une même partition logique.
Jeux de réplicas
Chaque partition physique se compose d’un ensemble de réplicas, également appelé jeu de réplicas. Chaque réplica héberge une instance du moteur de base de données. Grâce au jeu de réplicas, les données stockées dans la partition physique sont durables, hautement disponibles et cohérentes. Chaque réplica qui constitue la partition physique hérite du quota de stockage de la partition. Tous les réplicas d’une partition physique prennent collectivement en charge le débit alloué à la partition physique. Azure Cosmos DB gère automatiquement les jeux de réplicas.
En général, les petits conteneurs nécessitent uniquement une seule partition physique, mais ils ont toujours au moins quatre réplicas.
L’illustration suivante montre comment les partitions logiques sont mappées sur des partitions physiques distribuées à l’échelle mondiale. Le jeu de partitions de l’image fait référence à un groupe de partitions physiques qui gèrent les mêmes clés de partition logique dans plusieurs régions :
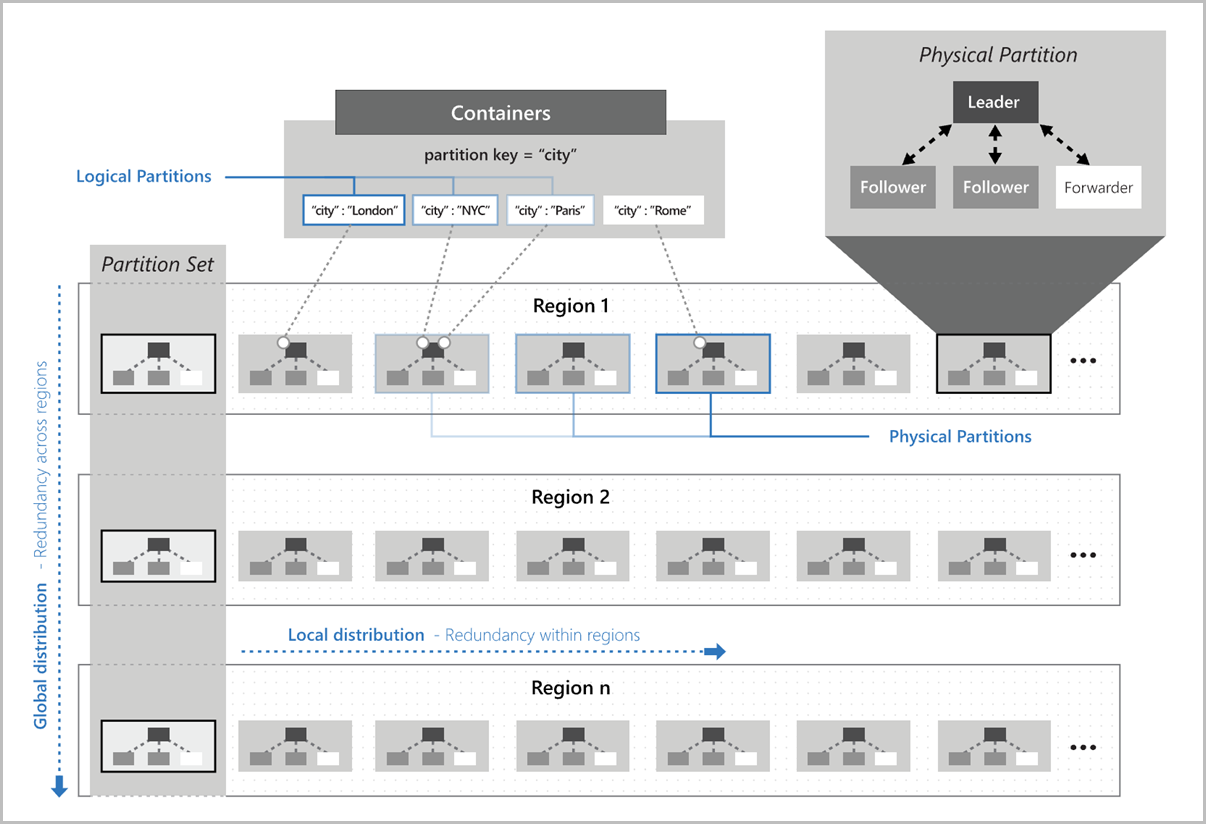
Choisir une clé de partition
Une clé de partition a deux composants : le chemin de clé de partition et la valeur de clé de partition. Par exemple, envisagez un élément { "userId" : "Andrew", "worksFor": "Microsoft" } si vous choisissez « userId » comme clé de partition. Voici les deux composants d’une clé de partition :
Chemin de clé de partition (par exemple : « /userId »). Le chemin de clé de partition accepte les caractères alphanumériques et les traits de soulignement (_). Vous pouvez également utiliser des objets imbriqués à l’aide de la notation de chemin standard (/).
La valeur de clé de partition (par exemple : « Andrew »). La valeur de clé de partition peut être de type chaîne ou numérique.
Pour en savoir plus sur les limites du débit, du stockage et de la longueur de la clé de partition, consultez l’article Quotas de service Azure Cosmos DB.
La sélection de votre clé de partition est un choix de conception simple, mais important dans Azure Cosmos DB. Une fois que vous avez sélectionné votre clé de partition, il n’est pas possible de la modifier sur place. Si vous avez besoin de modifier votre clé de partition, vous devez déplacer vos données vers un nouveau conteneur à l’aide de la nouvelle clé de partition de votre choix. (Les travaux de copie de conteneur facilitent ce processus.)
Pour tous les conteneurs, votre clé de partition doit :
Être une propriété qui a une valeur qui ne change pas. Si une propriété est votre clé de partition, vous ne pouvez pas mettre à jour la valeur de cette propriété.
Ne doit contenir que des valeurs
String, ou les nombres doivent idéalement être convertis enString, s’il y a une probabilité qu’ils soient en dehors des limites des nombres en double précision selon IEEE 754 binary64. La spécification Json appelle les raisons pour lesquelles l’utilisation de nombres en dehors de cette limite est une mauvaise pratique en raison de problèmes d’interopérabilité probables. Ces préoccupations sont particulièrement pertinentes pour la colonne de clé de partition, car elle est immuable et nécessite une migration de données s’il faut la modifier ultérieurement.Avoir une cardinalité élevée. En d’autres termes, la propriété doit avoir une large gamme de valeurs possibles.
Répartir la consommation d’unités de requête (RU) et le stockage des données uniformément sur toutes les partitions logiques. Cette diffusion garantit une consommation de RU et une répartition du stockage uniformes sur vos partitions physiques.
Avoir des valeurs qui ne sont généralement pas supérieures à 2048 octets, ou à 101 octets si les clés de partition volumineuses ne sont pas activées. Pour plus d’informations, consultez grandes clés de partition
Si vous avez besoin de transactions ACID à plusieurs éléments dans Azure Cosmos DB, vous devez utiliser des procédures stockées ou des déclencheurs. Toutes les procédures stockées et tous les déclencheurs basés sur JavaScript sont limités à une seule partition logique.
Notes
Si vous n’avez qu’une seule partition physique, la valeur de la clé de partition peut ne pas être pertinente, car toutes les requêtes ciblent la même partition physique.
Types de clés de partition
| Stratégie de partitionnement | Utilisation | Avantages | Inconvénients |
|---|---|---|---|
| Clé de partition régulière (par exemple, CustomerId, OrderId) | – À utiliser lorsque la clé de partition a une cardinalité élevée et s’aligne sur les modèles de requête (par exemple, un filtrage par CustomerId). – Convient aux charges de travail dans lesquelles les requêtes ciblent principalement les données d’un seul client (par exemple, la récupération de toutes les commandes d’un client). |
– Simple à gérer. – Requêtes efficaces lorsque le modèle d’accès correspond à la clé de partition (par exemple, l’interrogation de toutes les commandes par CustomerId). – Empêche les requêtes sur plusieurs partitions si les modèles d’accès sont cohérents. |
– Risque de partitions à chaud si certaines valeurs (par exemple, quelques clients à trafic élevé) génèrent beaucoup plus de données que les autres. – Peut atteindre la limite de 20 Go par partition logique si le volume de données d’une clé spécifique augmente rapidement. |
| Clé de partition synthétique (par exemple, CustomerId + OrderDate) | – À utiliser lorsqu’aucun champ unique n’a une cardinalité élevée et correspond aux modèles de requête. – Adapté aux charges de travail lourdes en écriture où les données doivent être uniformément distribuées sur toutes les partitions physiques (par exemple, plusieurs commandes passées à la même date). |
– Permet de distribuer des données uniformément sur toutes les partitions, ce qui réduit les partitions à chaud (par exemple, une distribution de commandes par CustomerId et OrderDate). – Répartit les écritures entre plusieurs partitions, ce qui améliore ainsi le débit. |
– Les requêtes filtrant uniquement sur un champ (par exemple, CustomerId uniquement) peuvent entraîner des requêtes sur plusieurs partitions. – Les requêtes entre partitions peuvent entraîner une consommation de RU plus élevée (2 à 3 RU/frais supplémentaire pour chaque partition physique existante) et une latence accrue. |
| Clé de partition hiérarchique (HPK) (par exemple, CustomerId/OrderId, StoreId/ProductId) | – À utiliser lorsque vous avez besoin d’un partitionnement à plusieurs niveaux pour prendre en charge des jeux de données à grande échelle. – Idéal quand des requêtes filtrent sur les premier et deuxième niveaux de la hiérarchie. |
– Permet d’éviter la limite de 20 Go en créant plusieurs niveaux de partitionnement. – Interrogation efficace sur les deux niveaux hiérarchiques (par exemple, filtrage en premier par CustomerID, puis par OrderID). – Permet de minimiser les requêtes dans plusieurs partitions pour les requêtes ciblant le niveau supérieur (par exemple, récupération de toutes les données à partir d’un CustomerID spécifique). |
– Nécessite une planification minutieuse pour veiller à ce que la clé de premier niveau ait une cardinalité élevée et soit incluse dans la plupart des requêtes. – Plus complexe à gérer par rapport à une clé de partition régulière. – Si des requêtes ne s’alignent pas sur la hiérarchie (par exemple, filtrage uniquement par OrderID quand CustomerID est le premier niveau), il est possible que les performances des requêtes en souffrent. |
Clés de partition pour les conteneurs à lecture intensive
Pour la plupart des conteneurs, les critères ci-dessus sont tout ce que vous devez prendre en compte lors de la sélection d’une clé de partition. Toutefois, pour les conteneurs à lecture intensive, vous souhaiterez peut-être choisir une clé de partition qui apparaît fréquemment comme filtre dans vos requêtes. Les requêtes peuvent être efficacement acheminées uniquement vers les partitions physiques concernées en incluant la clé de partition dans le prédicat de filtre.
Si la plupart des demandes de votre charge de travail sont des requêtes et que la plupart de vos requêtes ont un filtre d’égalité sur la même propriété, cette propriété peut être un bon choix de clé de partition. Par exemple, si vous exécutez fréquemment une requête qui filtre sur UserID, la sélection de UserID comme clé de partition réduit le nombre de requêtes dans plusieurs partitions.
Toutefois, si votre conteneur est petit, vous n’avez probablement pas assez de partitions physiques pour avoir à vous soucier des performances des requêtes dans plusieurs partitions. La plupart des petits conteneurs dans Azure Cosmos DB nécessitent uniquement une ou deux partitions physiques.
Si votre conteneur peut atteindre plus de quelques partitions physiques, vous devez vous assurer de choisir une clé de partition qui minimise les requêtes dans plusieurs partitions. Votre conteneur nécessite plus de quelques partitions physiques lorsque l’une des conditions suivantes est remplie :
Votre conteneur a plus de 30 000 RU configurées
Votre conteneur stocke plus de 100 Go de données
Utiliser l’ID d’élément comme clé de partition
Remarque
Cette section s’applique principalement à l’API pour NoSQL. D’autres API, telles que l’API pour Gremlin, ne prennent pas en charge l’identificateur unique comme clé de partition.
Si votre conteneur a une propriété qui contient une large plage de valeurs possibles, c’est probablement un bon choix pour la clé de partition. L’ID d’élément est un exemple possible d’une telle propriété. Pour les petits conteneurs à lecture intensive ou les conteneurs à écriture intensive de toute taille, l’ID d’élément/id est naturellement un bon choix pour la clé de partition.
La propriété système ID d’élément existe dans chaque élément de votre conteneur. Vous pouvez avoir d’autres propriétés qui représentent un ID logique de votre élément. Dans de nombreux cas, ces ID sont d’excellents choix de clé de partition pour les mêmes raisons que pour l’ID d’élément.
L’ID d’élément est un excellent choix de clé de partition pour les raisons suivantes :
- Il existe un large éventail de valeurs possibles (un ID d’élément unique par élément).
- Comme il y a un ID d’élément unique par élément, l’ID d’élément permet de bien équilibrer la consommation des RU et le stockage des données.
- Vous pouvez facilement effectuer des lectures de point efficaces, car vous connaissez toujours la clé de partition d’un élément si vous connaissez son ID d’élément.
Voici quelques points à prendre en compte lors de la sélection de l’ID d’élément comme clé de partition :
- Si l’ID d’élément est la clé de partition, il devient un identificateur unique dans tout le conteneur. Vous ne pouvez pas créer d’éléments qui ont des ID d’élément en double.
- Si vous disposez d’un conteneur à lecture intensive qui comporte un grand nombre de partitions physiques, les requêtes sont plus efficaces si elles sont dotées d’un filtre d’égalité avec l’ID d’élément.
- Vous ne pouvez pas exécuter de procédures stockées ni de déclencheurs ciblant plusieurs partitions logiques.