Modélisation des données dans Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL
Bien que les bases de données sans schéma, comme Azure Cosmos DB, rendent très faciles le stockage et l’interrogation des données non structurées et semi-structurées, vous devez prendre le temps de réfléchir à votre modèle de données pour tirer le meilleur parti du service en termes de niveau de performance, de scalabilité et de coût.
Comment les données seront-elles stockées ? Comment votre application va-t-elle récupérer et interroger des données ? Votre application exige-t-elle de nombreuses lectures (read heavy) ou de nombreuses écritures (write heavy) ?
Après avoir lu cet article, vous serez en mesure de répondre aux questions suivantes :
- Qu'est-ce que la modélisation de données et pourquoi dois-je m'en soucier ?
- En quoi la modélisation des données dans Azure Cosmos DB et dans une base de données relationnelle diffère-t-elle ?
- Comment exprimer les relations entre les données dans une base de données non relationnelle ?
- Quand dois-je incorporer les données et quand dois-je créer un lien vers les données ?
Nombres dans JSON
Azure Cosmos DB enregistre des documents dans JSON. Cela signifie qu’il est nécessaire de déterminer soigneusement s’il est nécessaire de convertir les nombres en chaînes avant de les stocker dans json ou non. Tous les nombres doivent idéalement être convertis en String, s’il existe des probabilités qu’ils soient en dehors des limites des nombres de double précision selon IEEE 754 binary64. La spécification Json appelle les raisons pour lesquelles l’utilisation de nombres en dehors de cette limite est une mauvaise pratique dans JSON en raison de problèmes d’interopérabilité probables. Ces préoccupations sont particulièrement pertinentes pour la colonne de clé de partition, car elle est immuable et nécessite une migration de données s’il faut la modifier ultérieurement.
Incorporer des données
Quand vous entamez la modélisation des données dans Azure Cosmos DB, essayez de traiter vos entités en tant qu’éléments autonomes représentés sous la forme de documents JSON.
À des fins de comparaison, nous allons tout d’abord voir comment nous pouvons modéliser les données dans une base de données relationnelle. L'exemple suivant montre comment une personne peut être stockée dans une base de données relationnelle.
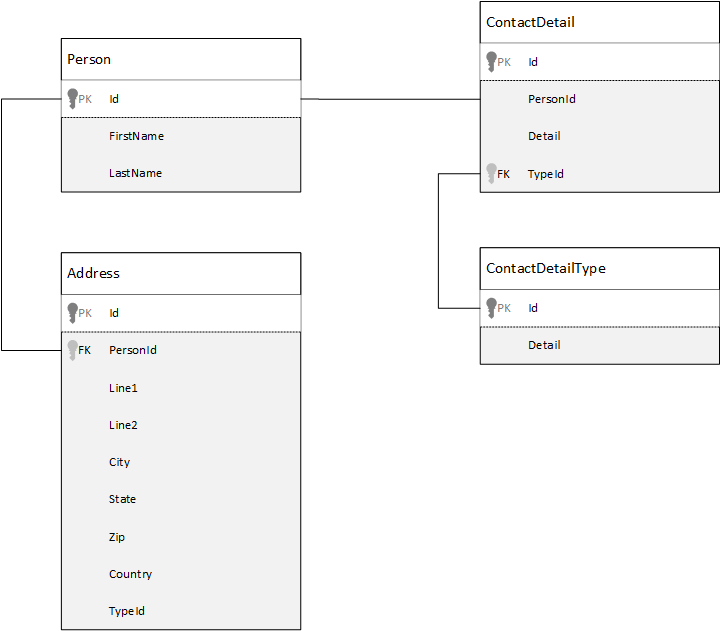
Quand vous utilisez des bases de données relationnelles, la stratégie consiste à normaliser toutes vos données. En général, la normalisation de vos données consiste à prendre une entité, une personne par exemple, et à la décomposer en composants discrets. Dans l’exemple, une personne peut avoir plusieurs enregistrements de coordonnées ainsi que plusieurs enregistrements d’adresse. Nous pouvons également décomposer les coordonnées en extrayant des champs communs tels qu’un type. Il en va de même pour l’adresse, chaque enregistrement pouvant être de type personnel ou professionnel.
Le principe directeur lors de la normalisation des données consiste à éviter de stocker des données redondantes dans chaque enregistrement et à faire plutôt référence aux données. Dans cet exemple, pour lire une personne, avec ses coordonnées et ses adresses, vous devez utiliser des jointures pour recomposer (dénormaliser) efficacement vos données au moment de l’exécution.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Les opérations d’écriture sur de nombreuses tables individuelles sont nécessaires pour mettre à jour les coordonnées et les adresses d’une personne.
Examinons à présent comment nous pourrions modéliser les mêmes données comme une entité autonome dans Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
En suivant cette approche, nous avons dénormalisé l’enregistrement de la personne, en incorporant toutes les informations la concernant (notamment ses coordonnées et adresses) dans un seul document JSON. En outre, étant donné que nous ne sommes pas limités à un schéma fixe, nous avons la possibilité d'avoir des coordonnées de formes entièrement différentes.
La récupération d’un enregistrement complet de personne dans la base de données correspond désormais à une seule opération de lecture sur un conteneur unique et pour un élément unique. La mise à jour des coordonnées et adresses d’un enregistrement de personne correspond également à une seule opération d’écriture sur un élément unique.
Avec la dénormalisation des données, votre application aura peut-être besoin d'émettre moins de requêtes et de mises à jour pour effectuer les opérations courantes.
Quand utiliser l'incorporation
En général, utilisez des modèles de données incorporés dans les cas suivants :
- Il existe des relations de type contenu entre des entités.
- Il existe des relations de type un-à-plusieurs entre des entités.
- Il existe des données incorporées qui changent rarement.
- Il existe des données incorporées qui ne croissent pas sans limite.
- Il existe des données incorporées qui sont fréquemment interrogées ensemble.
Notes
Normalement, les modèles de données dénormalisés offrent de meilleures performances en lecture .
Quand éviter l'incorporation
Bien que la règle générale dans Azure Cosmos DB soit de tout dénormaliser et d’incorporer toutes les données dans un seul élément, cela peut déboucher sur des situations qui devraient être évitées.
Prenons cet extrait de code JSON.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
Une entité post avec commentaires incorporés pourrait avoir cet aspect si nous étions en train de modéliser un système de blog, ou CMS, classique. Dans cet exemple, le problème est que le tableau de commentaires est illimité, c’est-à-dire qu’il n’existe aucune limite (pratique) au nombre de commentaires possibles pour une publication. Cela peut devenir un problème, car la taille de l’élément peut augmenter à l’infini. C’est pourquoi ce type de conception doit être évité.
L’augmentation de la taille de l’élément a une incidence sur les possibilités de transmission des données par câble, ainsi que sur les possibilités de lecture et de mise à jour de l’élément à grande échelle.
Dans ce cas, il serait préférable de considérer le modèle de données suivant.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Ce modèle dispose d’un document pour chaque commentaire avec une propriété qui contient l’identificateur de publication. Cela permet aux publications de contenir un nombre illimité de commentaires et de se développer efficacement. Les utilisateurs qui souhaitent afficher plus de commentaires que les commentaires les plus récents interrogent ce conteneur en transmettant l’ID de publication qui doit être la clé de partition pour le conteneur de commentaires.
Il existe un autre cas de figure où l’incorporation de données est déconseillée : quand les données incorporées sont souvent utilisées dans les différents éléments et changent fréquemment.
Prenons cet extrait de code JSON.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Il pourrait représenter le portefeuille d'actions d'une personne. Nous avons choisi d’incorporer les informations boursières dans chaque document de portefeuille. Dans un environnement où les données associées changent fréquemment (par exemple une application de transactions boursières), incorporer ces données implique de mettre constamment à jour chaque document de portefeuille, chaque fois que des actions sont négociées.
Des actions zbzb peuvent être échangées des centaines de fois au cours d’une même journée, et des milliers d’utilisateurs peuvent posséder des actions zbzb dans leur portefeuille. Avec un modèle de données comme l’exemple, nous devons mettre à jour quotidiennement et à de nombreuses reprises des milliers de documents de portefeuille. Cela aboutit à un système qui n’est pas évolutif.
Données de référence
L’incorporation de données fonctionne bien dans la plupart des cas, mais il existe des scénarios où la dénormalisation des données provoque trop de problèmes pour être intéressante. Que faire, alors ?
Les bases de données relationnelles ne sont pas le seul endroit où il est possible de créer des relations entre les entités. Une base de données de documents peut comporter des informations dans un document qui sont en relation avec des données d’autres documents. Nous ne recommandons pas de créer des systèmes qui seraient mieux adaptés à une base de données relationnelle dans Azure Cosmos DB ou à une autre base de données de documents. Cependant, des relations simples conviennent et peuvent être utiles.
Dans le code JSON, nous avons choisi d'utiliser l'exemple de portefeuille d'actions précédent, mais cette fois, nous faisons référence à l'action dans le portefeuille au lieu de l'incorporer. Ainsi, lorsque l'action change fréquemment au cours de la journée, le seul document à mettre à jour est le document d'action (stock).
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Cette approche présente cependant un inconvénient si votre application doit afficher des informations sur chaque action qui est conservée lors de l'affichage du portefeuille d'une personne ; dans ce cas, vous devez faire plusieurs aller et retour jusqu'à la base de données afin de charger les informations pour chaque document d'action. Ici, nous avons pris une décision pour améliorer l'efficacité des opérations d'écriture, qui ont lieu fréquemment pendant la journée, mais nous avons fait un compromis sur les opérations de lecture, qui ont potentiellement moins d'impact sur les performances de ce système.
Notes
Les modèles de données normalisés peuvent nécessiter davantage d’aller-retour jusqu’au serveur.
Qu'en est-il des clés étrangères ?
Dans la mesure où il n’existe actuellement aucun concept de contrainte (clé étrangère ou autre), toutes les relations existantes entre les documents constituent en pratique des « maillons faibles ». Elles ne sont pas vérifiées par la base de données. Si vous souhaitez vous assurer que les données auxquelles un document fait référence existent réellement, vous devez le faire dans votre application, ou en utilisant des déclencheurs côté serveur ou des procédures stockées sur Azure Cosmos DB.
Quand utiliser des références
En général, utilisez des modèles de données normalisés dans les cas suivants :
- Représentation des relations un-à-plusieurs .
- Représentation des relations plusieurs-à-plusieurs .
- Les données associées changent fréquemment.
- Les données référencées peuvent être illimitées.
Notes
En général, la normalisation offre de meilleures performances en écriture .
Où placer la relation ?
La croissance de la relation permet de déterminer dans quel document doit être stockée la référence.
Si nous observons le code JSON qui modélise des éditeurs et des livres :
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Si le nombre de livres par éditeur est peu élevé avec une croissance faible limitée, il peut être utile de stocker la référence du livre dans le document d'éditeur (publisher). Toutefois, si le nombre de livres par éditeur est illimité, ce modèle de données aboutira à des tableaux mutables, croissants, comme dans l'exemple de document d'éditeur ci-dessus.
Un petit changement donnera un modèle qui représente toujours les mêmes données, mais évite désormais ces grandes collections mutables.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
Dans cet exemple, nous avons supprimé la collection illimitée dans le document d’éditeur (publisher). À la place, nous avons simplement une référence à l’éditeur dans chaque document de livre (book).
Comment modéliser des relations plusieurs-à-plusieurs ?
Dans une base de données relationnelle plusieurs-à-plusieurs , les relations sont souvent modélisées avec des tables de jointure qui relient simplement les enregistrements d’autres tables.
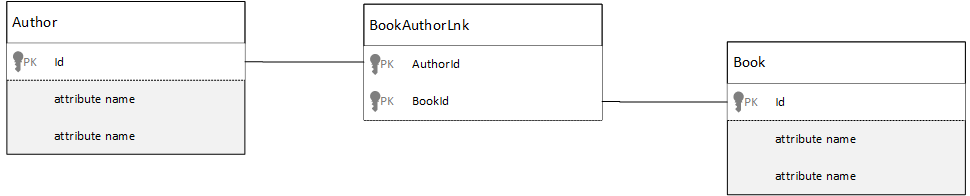
Vous pouvez être tenté de répliquer la même chose à l'aide de documents et de générer un modèle de données qui ressemble à ce qui suit.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Cette méthode fonctionne. Toutefois, le fait de charger soit un auteur avec ses livres soit un livre avec son auteur nécessite toujours au moins deux requêtes supplémentaires sur la base de données. Une requête pour le document de jointure (joining) et une autre requête pour extraire le document joint.
Si cette jointure ne fait rien d’autre que coller ensemble deux données, pourquoi ne pas la supprimer complètement ? Considérez l'exemple suivant.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Si j’ai un auteur, je sais maintenant immédiatement quels livres il a écrits. Inversement, si un document de livre (book) est chargé, je connais l’ID des auteurs. Cela permet de faire l'économie de cette requête intermédiaire sur la table de jointure en réduisant le nombre d'aller et retour jusqu'au serveur pour votre application.
Modèles de données hybrides
Nous avons vu l’incorporation (ou la dénormalisation) et le référencement (ou la normalisation) des données. Chaque approche présente des avantages et des compromis.
Vous n’êtes pas toujours obligé de choisir l’un ou l’autre, n’ayez pas peur de mélanger un peu les deux.
En fonction des modèles d'utilisation et des charges de travail spécifiques de votre application, dans certains cas, la combinaison de données incorporées et de données référencées peut s'avérer intéressante et conduire à une logique d'application plus simple, avec moins d'aller et retour jusqu'au serveur, tout en préservant un bon niveau de performances.
Examinons le code JSON suivant.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Ici nous avons suivi (principalement) le modèle incorporé, où les données des autres entités sont incorporées dans le document de niveau supérieur, mais les autres données sont référencées.
Dans le document de livre (book), nous pouvons voir quelques champs intéressants lorsque nous examinons le tableau des auteurs. Il existe un champ id que nous utilisons pour faire référence à un document d’auteur (author), une pratique courante dans un modèle normalisé, mais nous disposons également des champs name et thumbnailUrl. Nous aurions pu nous arrêter à l’id et laisser l’application obtenir les informations supplémentaires dont elle avait besoin à partir du document d’auteur (author) respectif à l’aide du « lien », mais comme notre application affiche le nom de l’auteur et une image miniature avec chaque livre, nous pouvons économiser un aller-retour par livre jusqu’au serveur en dénormalisant certaines données de l’auteur.
Bien sûr, si le nom de l’auteur changeait ou s’il souhaitait mettre à jour sa photo, nous devrions procéder à une mise à jour sur chaque livre publié par lui ; mais pour notre application, si l’on se base sur l’hypothèse que les auteurs ne changent pas souvent de nom, il s’agit d’une décision de conception acceptable.
Dans cet exemple, il existe des valeurs d’agrégats précalculés pour économiser un traitement coûteux sur une opération de lecture. Dans l'exemple, certaines données incorporées dans le document d'auteur (author) sont des données calculées au moment de l'exécution. À chaque publication d’un nouveau livre, un document de type livre est créé et le champ countOfBooks est défini sur une valeur calculée en fonction du nombre de documents de type livre existant pour un auteur particulier. Cette optimisation serait appropriée dans les systèmes qui exigent de nombreuses lectures (read heavy), où nous pouvons nous permettre d'effectuer des calculs sur les écritures afin d'optimiser les lectures.
L’existence d’un modèle avec des champs précalculés est possible, car Azure Cosmos DB prend en charge les transactions multidocuments. De nombreux magasins NoSQL, qui ne peuvent pas effectuer des transactions sur plusieurs documents, recommandent des décisions de conception (par exemple « tout incorporer systématiquement ») en raison de cette limitation. Avec Azure Cosmos DB, vous pouvez utiliser des déclencheurs côté serveur, ou des procédures stockées, qui insèrent des livres et mettent à jour les auteurs au sein d’une transaction ACID. Aujourd’hui, vous n’êtes pas tenu d’intégrer tous les éléments dans un seul document, simplement pour vous assurer que vos données restent cohérentes.
Faire la distinction entre les différents types de documents
Dans certains scénarios, vous souhaiterez combiner différents types de documents dans la même collection ; cela est généralement le cas quand vous souhaitez que plusieurs documents connexes se trouvent dans la même partition. Par exemple, vous pourriez placer les livres et les critiques de livre dans la même collection et la partitionner par bookId. Dans ce cas, vous souhaitez généralement ajouter à vos documents un champ qui identifie leur type afin de les différencier.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Modélisation de données pour Azure Synapse Link et le magasin analytique Azure Cosmos DB
Azure Synapse Link pour Azure Cosmos DB est une fonctionnalité de traitement transactionnel et analytique (HTAP) hybride et native Cloud qui vous permet d’exécuter des analyses en quasi-temps réel sur les données opérationnelles dans Azure Cosmos DB. Azure Synapse Link crée une intégration transparente entre Azure Cosmos DB et Azure Synapse Analytics.
Cette intégration se produit à travers le magasin analytique Azure Cosmos DB, une représentation en colonnes de vos données transactionnelles qui permet une analytique à grande échelle sans impact sur vos charges de travail transactionnelles. Ce magasin analytique permet d’effectuer des requêtes rapides et rentables sur de grands jeux de données opérationnels, sans copier les données ni impacter les performances de vos charges de travail transactionnelles. Lorsque vous créez un conteneur avec magasin analytique ou activez un magasin analytique sur un conteneur existant, toutes les insertions, mises à jour et suppressions transactionnelles sont synchronisées avec le magasin analytique en quasi-temps réel sans qu’aucun flux de modification ni aucun travail ETL soient requis.
Azure Synapse Link vous permet maintenant de vous connecter directement à vos conteneurs Azure Cosmos DB à partir d’Azure Synapse Analytics et d’accéder au magasin analytique sans frais en unités de requête (Request Units). Azure Synapse Analytics prend actuellement en charge Azure Synapse Link avec Synapse Apache Spark et des pools SQL serverless. Si vous avez un compte Azure Cosmos DB distribué globalement, une fois que vous avez activé le magasin analytique pour un conteneur, il est disponible dans toutes les régions de ce compte.
Inférence automatique du schéma du magasin analytique
Bien que le magasin transactionnel Azure Cosmos DB soit considéré comme des données semi-structurées orientées lignes, le magasin analytique utilise un format structuré en colonnes. Cette conversion est effectuée automatiquement pour les clients en utilisant les règles d’inférence du schéma pour le magasin analytique. Le processus de conversion est limité : nombre maximal de niveaux imbriqués, nombre maximal de propriétés, types de données non pris en charge, etc.
Notes
Dans le contexte du magasin analytique, nous considérons les structures suivantes comme des propriétés :
- « Éléments » ou « paires chaîne-valeur séparées par le signe
:» JSON. - Objets JSON, délimités par les signes
{et}. - Tableaux JSON, délimités par les signes
[et].
Vous pouvez réduire l’impact des conversions d’inférences du schéma et optimiser vos capacités analytiques à l’aide des techniques suivantes.
Normalisation
La normalisation n’a plus de sens, car Azure Synapse Link vous permet d’effectuer une jointure entre vos conteneurs avec T-SQL ou Spark SQL. Les avantages attendus de la normalisation sont les suivants :
- Réduction de l’empreinte des données dans le magasin transactionnel et le magasin analytique
- Réduction de la taille des transactions
- Réduction du nombre de propriétés par document
- Réduction du nombre de niveaux imbriqués dans les structures de données
Ces deux derniers facteurs (moins de propriétés et de niveaux) augmentent le niveau de performance de vos requêtes analytiques, mais diminuent également le risque que certaines parties de vos données ne soient pas représentées dans le magasin analytique. Le nombre de niveaux et de propriétés représentés dans le magasin analytique est limité (cf. article sur les règles d’inférence automatique du schéma).
Il existe un autre facteur important pour la normalisation : dans Azure Synapse, les pools serverless SQL prennent en charge des ensembles de résultats contenant jusqu’à 1 000 colonnes. L’exposition de colonnes imbriquées est également comptabilisée par rapport à cette limite. En d’autres termes, le magasin analytique et les pools serverless Synapse SQL présentent une limite de 1 000 propriétés.
Mais que faire étant donné que la dénormalisation constitue une technique importante de modélisation des données pour Azure Cosmos DB ? Vous devez trouver le bon équilibre pour vos charges de travail transactionnelles et analytiques.
Clé de partition
Votre clé de partition Azure Cosmos DB n’est pas utilisée dans le magasin analytique. Vous pouvez maintenant utiliser le partitionnement personnalisé du magasin analytique dans des copies du magasin analytique avec la clé de partition de votre choix. En raison de cette isolation, vous pouvez choisir une clé de partition pour vos données transactionnelles en vous concentrant sur l’ingestion de données et les lectures ponctuelles, tandis que les requêtes entre partitions peuvent être réalisées avec Azure Synapse Link. Prenons un exemple :
Dans un scénario d’IoT global hypothétique, device id constitue une bonne clé de partition. Tous les appareils présentent en effet un volume de données similaire, ce qui évite tout problème de partitionnement à chaud. Si en revanche vous voulez analyser les données de plusieurs appareils (par exemple « toutes les données d’hier » ou « totaux par ville »), vous risquez de rencontrer des problèmes dans la mesure où il s’agit de requêtes entre partitions. Ces requêtes peuvent nuire à vos performances transactionnelles, car elles utilisent pour s’exécuter une partie de votre débit d’unités de requête. Toutefois, vous pouvez exécuter ces requêtes analytiques sans frais en unités de requête avec Azure Synapse Link. Le format en colonnes du magasin analytique est optimisé pour les requêtes analytiques. Azure Synapse Link applique de cette caractéristique pour optimiser le niveau de performance avec les runtimes Azure Synapse Analytics.
Types de données et nom des propriétés
L’article sur les règles d’inférence automatique du schéma présente les types de données pris en charge. Si un type de données non pris en charge bloque la représentation dans le magasin analytique, les types de données pris en charge, eux, peuvent être traités différemment par les runtimes Azure Synapse. Prenons par exemple des chaînes DateHeure qui suivent la norme ISO 8601 UTC. Dans Azure Synapse, les pools Spark représentent ces colonnes sous forme de chaîne, et les pools SQL serverless sous forme de varchar(8000).
Un autre problème est que tous les caractères ne sont pas acceptés par Azure Synapse Spark. Si les espaces blancs sont pris en charge, ce n’est pas le cas de caractères comme le deux-points, l’accent grave et la virgule. Supposons que votre document possède une propriété nommée « Prénom, Nom ». Cette propriété est représentée dans le magasin analytique. Le pool serverless Synapse SQL peut la lire sans problème. Azure Synapse Spark, en revanche, ne peut pas lire les données du magasin analytique, y compris toutes les autres propriétés. Vous ne pouvez par conséquent pas utiliser Azure Synapse Spark lorsque le nom d’une propriété comporte les caractères non pris en charge.
Aplatissement de données
Toutes les propriétés situées au niveau racine de vos données Azure Cosmos DB sont représentées en colonnes dans un magasin analytique. Tout ce qui se trouve dans des niveaux plus profonds de votre modèle de données de document est mis au format JSON, également dans des structures imbriquées. Les structures imbriquées demandent un traitement supplémentaire de la part des runtimes Azure Synapse pour aplatir les données au format structuré, ce qui peut se révéler difficile dans les scénarios de Big Data.
Le document ne comporte que deux colonnes dans le magasin analytique : id et contactDetails. Toutes les autres données, email et phone, exigent pour être lues individuellement un traitement supplémentaire au moyen de fonctions SQL.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Le document comporte trois colonnes dans le magasin analytique : id, email et phone. Toutes les données sont directement accessibles sous forme de colonnes.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Hiérarchisation des données
Azure Synapse Link vous permet de réduire vos coûts selon différentes perspectives :
- Moins de requêtes s’exécutent dans votre base de données transactionnelle.
- Il utilise une clé de partition optimisée pour l’ingestion des données et les lectures ponctuelles (ce qui réduit l’empreinte des données), les scénarios de partitionnement à chaud et les fractionnements de partitions.
- La hiérarchisation des données depuis la durée de vie analytique (ATTL) est indépendante de la durée de vie transactionnelle (TTTL). Vous pouvez conserver vos données transactionnelles dans un magasin transactionnel pendant quelques jours, semaines ou mois, et dans un magasin analytique pendant des années ou pour toujours. Le format en colonnes du magasin analytique permet une compression naturelle des données, de 50 % à 90 %. De plus, son coût par Go correspond à environ 10 % du prix réel du magasin transactionnel. Pour plus d’informations sur les limitations actuelles des sauvegardes, consultez Vue d’ensemble du magasin analytique.
- Aucun travail ETL ne s’exécute dans votre environnement, ce vous évite d’avoir à leur approvisionner des unités de requête.
Redondance contrôlée
Il s’agit d’une excellente solution de remplacement pour les situations dans lesquelles il existe déjà un modèle de données qui ne peut pas être modifié et ne s’intègre pas bien dans le magasin analytique en raison de règles d’inférence automatique du schéma (par exemple la limite de niveaux imbriqués ou le nombre maximal de propriétés). Dans ce cas, vous pouvez utiliser le flux de modification d’Azure Cosmos DB pour répliquer vos données dans un autre conteneur, en appliquant les transformations requises pour un modèle de données compatible avec Azure Synapse Link. Prenons un exemple :
Scénario
Le conteneur CustomersOrdersAndItems sert à stocker les commandes en ligne, notamment les informations relatives aux clients et aux articles : adresse de facturation, adresse de livraison, mode de livraison, état de livraison, prix des articles, etc. Seules les 1 000 premières propriétés sont représentées. Les informations clés ne sont pas incluses dans un magasin analytique, ce qui empêche d’utiliser Azure Synapse Link. Le conteneur possède des pétaoctets d’enregistrements. Il n’est pas possible de modifier l’application ni de remodéliser les données.
Le volume important de données constitue un autre aspect du problème. Des milliards de lignes sont constamment utilisées par le service d’analytique, ce qui l’empêche de se servir de la durée de vie transactionnelle pour la suppression d’anciennes données. Pour maintenir l’historique complet des données dans la base de données transactionnelle en raison de ces besoins analytiques, le service doit constamment augmenter l’approvisionnement en unités de requête. Cette solution a un impact sur les coûts. Les charges de travail transactionnelles et analytiques entrent en concurrence pour les mêmes ressources à un instant t.
Que faire, alors ?
Solution avec le flux de modification
- L’équipe d’ingénierie a décidé d’utiliser le flux de modification pour remplir trois nouveaux conteneurs :
Customers,OrdersetItems. Le flux de modification lui permet de normaliser et d’aplatir les données. Les informations inutiles sont supprimées du modèle de données. Chaque conteneur possède près de 100 propriétés, ce qui évite la perte de données due aux limites d’inférence automatique du schéma. - Le magasin analytique est activé sur ces nouveaux conteneurs. Le service d’analytique se sert maintenant de Synapse Analytics pour lire les données, ce qui réduit la consommation d’unités de requête. En effet, les requêtes analytiques se produisent dans Synapse Apache Spark et les pools SQL serverless.
- Le conteneur
CustomersOrdersAndItemspossède maintenant une durée de vie transactionnelle permettant de conserver les données pendant six mois seulement, ce qui réduit encore l’utilisation des unités de requête. Il existe en effet un minimum d’une unité de requête par Go dans Azure Cosmos DB. Moins de données, moins d’unités de requête.
Éléments importants à retenir
Comprendre que la modélisation des données dans un monde sans schéma reste aussi importante que jamais, telle est la principale leçon à tirer de cet article.
De même qu’il n’existe pas de manière unique de représenter une donnée à l’écran, vous pouvez modéliser vos données de différentes façons. Vous devez comprendre votre application et comment elle produit, utilise et traite les données. Ensuite, en appliquant certaines des instructions présentées ici, vous pouvez entreprendre de créer un modèle qui répond aux besoins immédiats de votre application. Lorsque vos applications doivent changer, vous pouvez utiliser la flexibilité d’une base de données sans schéma pour adopter ce changement et développer facilement votre modèle de données.