Disponibilité (fiabilité) et récupération d’urgence (DR) dans Azure Cosmos DB for MongoDB vCore : les coulisses
S’APPLIQUE À : ![]() MongoDB vCore
MongoDB vCore
Cet article traite des éléments internes de la haute disponibilité (HA) et de la récupération d’urgence (DR) inter-régions pour Azure Cosmos DB for MongoDB vCore, en décrivant la conception et les capacités de ces fonctionnalités. Il fournit des insights sur la planification efficace de la stratégie dans la région et inter-régions pour garantir la fiabilité et la continuité de l’activité.
Anatomie du cluster Azure Cosmos DB for MongoDB vCore
Un cluster Azure Cosmos DB for MongoDB vCore se compose d’une ou plusieurs partitions physiques (nœuds). Chaque partition physique comprend un nœud de calcul dédié et un stockage SSD Premium distant. Les ressources de calcul et de stockage d’une partition physique sont exclusives à une base de données unique et ne sont pas partagée entre des clusters ou des bases de données.
Dans les clusters avec plusieurs partitions, chaque partition a une configuration de calcul et de stockage identiques. Quel que soit le nombre de partitions, toutes les ressources de cluster sont hébergées dans la même région Azure.
Azure Cosmos DB for MongoDB vCore utilise le stockage localement redondant (LRS), ce qui garantit que toutes les données sont répliquées de manière synchrone trois fois dans l’emplacement physique du cluster. Le Stockage Azure gère en toute transparence ces réplicas, vérifie l’intégrité des données à l’aide de vérifications de redondance cyclique (CRC) et répare toute altération détectée à l’aide de données redondantes. En outre, les sommes de contrôle sont appliquées au trafic réseau pour empêcher l’altération des données pendant le stockage et la récupération.
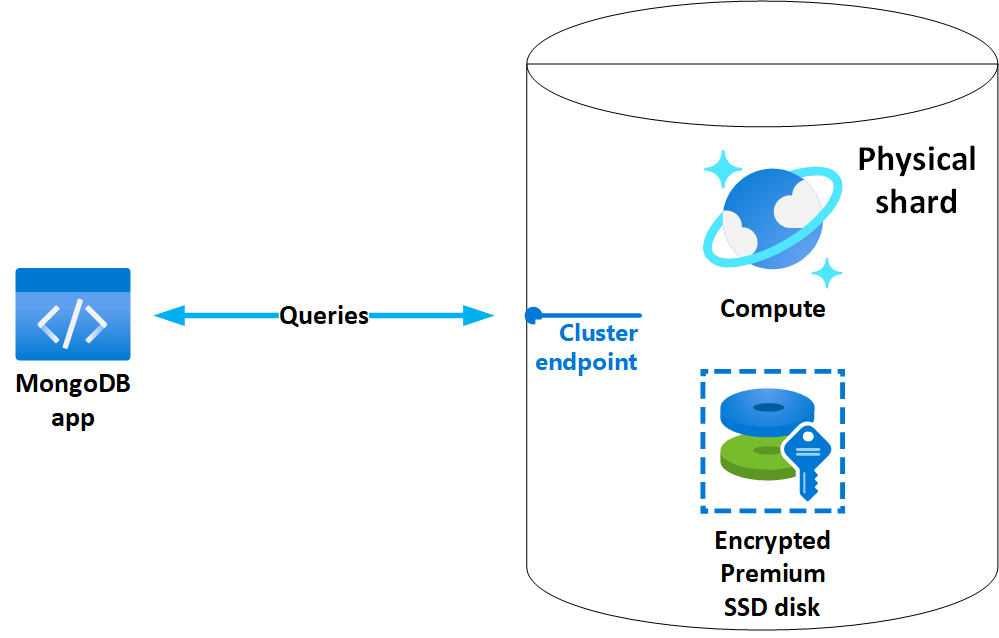 Figure 1. Composants de cluster Azure Cosmos DB for MongoDB vCore.
Figure 1. Composants de cluster Azure Cosmos DB for MongoDB vCore.
Que votre application se connecte à une seule partition ou à un cluster avec plusieurs partitions, elle utilise une seule chaîne de connexion et un point de terminaison. Cette abstraction simplifie les opérations de base de données distribuées, ce qui facilite la connexion à une configuration multi-partitions comme à une base de données MongoDB autonome.
Haute disponibilité (HA) dans la région
Pour les charges de travail de production, nous vous recommandons d’activer la haute disponibilité (HA) dans la région pour répondre aux normes de fiabilité modernes. Bien que la haute disponibilité puisse être désactivée pour les clusters de développement ou expérimentaux afin de réduire les coûts, il est essentiel de maintenir la disponibilité de la base de données en production.
La haute disponibilité peut être activée pendant l’approvisionnement du cluster ou à tout moment après la création du cluster. Elle est disponible dans toutes les régions Azure qui prennent en charge Azure Cosmos DB for MongoDB vCore, quelles que soient les fonctionnalités régionales spécifiques.
Lorsque la haute disponibilité est activée, chaque partition physique principale du cluster est jumelée à une partition de secours. La partition de secours reflète la configuration de calcul et de stockage de son équivalent principal. Cela entraîne six réplicas de données par partition : trois sur la partition principale et trois sur le serveur de secours. Dans les régions avec des zones de disponibilité (AZ), les partitions primaires et de secours sont déployées dans des zones distinctes.
Les données sont répliquées de manière synchrone entre chaque partition principale et de secours. Les écritures sont reconnues uniquement après avoir été validées avec succès sur les deux partitions, ce qui garantit une cohérence forte au sein du cluster à haute disponibilité. En d’autres termes, une partition physique de secours est un réplica complet toujours à jour de sa partition physique principale, fournissant une cohérence forte au sein du cluster à hautement disponible.
 Figure 2. Cluster Azure Cosmos DB for MongoDB vCore avec et sans haute disponibilité dans la région activée.
Figure 2. Cluster Azure Cosmos DB for MongoDB vCore avec et sans haute disponibilité dans la région activée.
En cas d’échec de partition principale, le service effectue automatiquement un basculement vers sa partition de secours. Pendant le basculement, toutes les demandes de lecture et d’écriture sont redirigées vers la partition de secours, qui devient le nouveau serveur principal. Les opérations d’écriture en cours pendant le basculement sont retentées au sein du service pour garantir la continuité. Une partition de remplacement est ensuite créée pour rétablir la réplication synchrone, en devenant le nouveau serveur de secours.
Réplication inter-région : récupération d’urgence (DR) régionale
Bien que rares, les pannes régionales peuvent perturber l’accès à votre base de données. La réplication inter-région fournit une stratégie de récupération d’urgence robuste, garantissant ainsi l’accès à vos données même lors d’interruptions à grande échelle.
Avec la réplication inter-région, vous pouvez créer un cluster de réplica dans une autre région Azure. Chaque partition du cluster de réplica réplique de façon asynchrone les données de son équivalent dans le cluster principal. Ce modèle de réplication garantit une cohérence éventuelle tout en réduisant l’impact du niveau de performance sur le cluster principal.
La réplication asynchrone évite que chaque opération d’écriture soit immédiatement remise et confirmée par les réplicas avant qu’un accusé de réception « écriture terminée » soit renvoyé à l’application. Toutefois, cela signifie que certaines écritures terminées sur le cluster principal peuvent ne pas encore être répliquées sur le cluster de réplica, ce qui entraîne un décalage de réplication. L’étendue du décalage de réplication dépend de l’intensité des opérations d’écriture sur le cluster principal et de la charge globale sur les clusters principaux et de réplicas.
Dans cette configuration :
- Le cluster principal de la région A gère toutes les lectures et écritures.
- Le cluster de réplica dans la région B prend en charge l’accès en lecture seule, ce qui permet d’effectuer des opérations de lecture à hautes performances plus proches des applications ou des utilisateurs de cette région.
Les applications peuvent effectuer des requêtes OLTP sur le cluster principal dans la région A et des opérations de lecture intenses telles que les requêtes OLAP/reporting peuvent être pointées vers le cluster de réplica dans la région B.
Les applications peuvent utiliser une chaîne de connexion en lecture-écriture globale dynamique, qui pointe toujours vers le cluster ouvert pour les écritures. Pendant une panne régionale, le cluster de réplica dans la région B peut être promu pour accepter les écritures. La chaîne de connexion globale est automatiquement mise à jour pour pointer vers le cluster promu, ce qui garantit des opérations d’écriture ininterrompues.
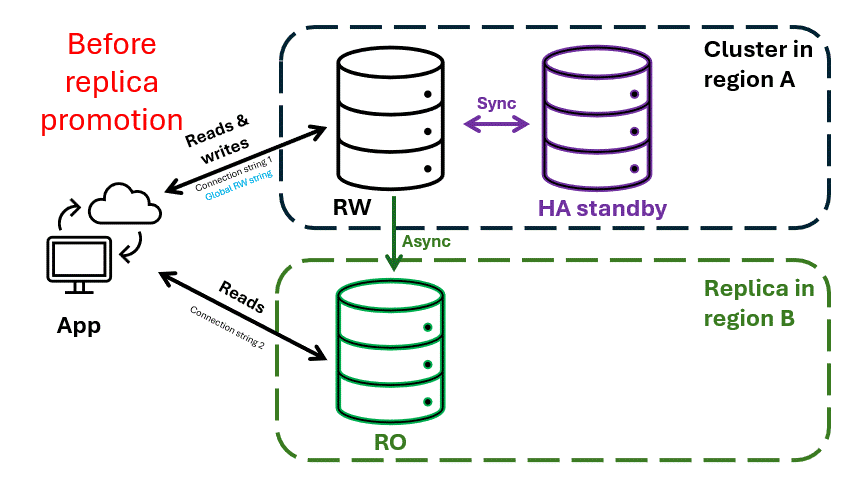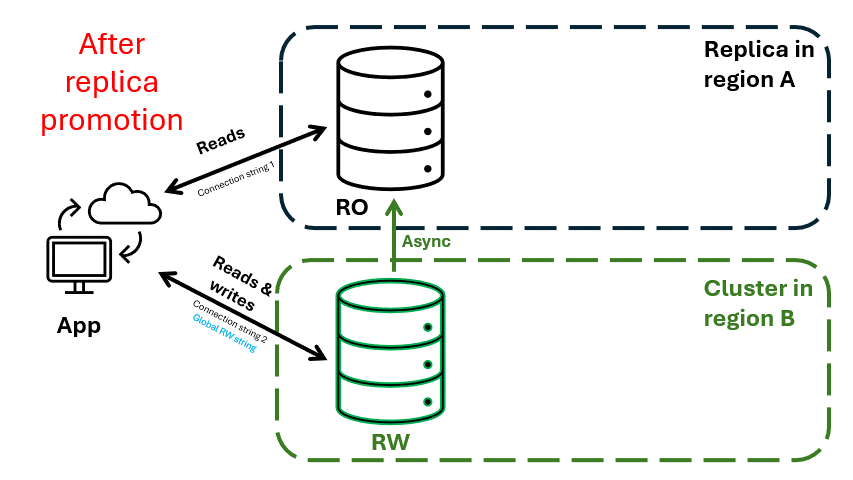 Figure 3. Récupération d’urgence régionale avec un cluster Azure Cosmos DB for MongoDB vCore avec réplication inter-région activée. Le cluster dans la région B est promu pour devenir le nouveau cluster en lecture-écriture. Le cluster dans la région A devient un cluster de réplica.
Figure 3. Récupération d’urgence régionale avec un cluster Azure Cosmos DB for MongoDB vCore avec réplication inter-région activée. Le cluster dans la région B est promu pour devenir le nouveau cluster en lecture-écriture. Le cluster dans la région A devient un cluster de réplica.
Résumé de la disponibilité dans la région et des fonctionnalités de récupération d’urgence inter-régions
Le tableau suivant récapitule les principales considérations relatives à l’activation et à la gestion de la haute disponibilité dans la région et de la stratégie de récupération d’urgence inter-régions.
| Scénario | Fonctionnalité Azure Cosmos DB for MongoDB vCore | Aucune perte de données | Protection contre les pannes à l’échelle de la région | Basculement automatique | Aucune modification de chaîne de connexion |
|---|---|---|---|---|---|
| Échec de partition physique | Haute disponibilité (HA) dans la région | ✔️ | ❌ | ✔️ | ✔️ |
| Panne régionale | Cluster de réplica inter-régions | ❌ | ✔️ | ❌ | ✔️† |
† Lors de l’utilisation de la chaîne de connexion en lecture-écriture globale.