Migrer des données de MongoDB vers un compte Azure Cosmos DB for MongoDB en utilisant Azure Databricks
S’APPLIQUE À : ![]() MongoDB
MongoDB
Ce guide de migration fait partie de la série sur la migration de bases de données de MongoDB vers l’API Azure Cosmos DB pour MongoDB. Les principales étapes de migration sont la prémigration, la migration proprement dite et la postmigration, comme indiqué ci-dessous.

Migration de données à l’aide d’Azure Databricks
Azure Databricks est une offre PaaS (platform as a service) pour Apache Spark. Elle permet d’effectuer des migrations hors connexion sur un grand jeu de données. Vous pouvez utiliser Azure Databricks pour effectuer une migration hors connexion de bases de données de MongoDB vers Azure Cosmos DB for MongoDB.
Dans ce didacticiel, vous apprendrez à :
Provisionner un cluster Azure Databricks
Ajout de dépendances
Créer et exécuter un notebook Scala ou Python
Optimiser les performances de migration
Résoudre les erreurs de limitation du débit qui peuvent être observées durant la migration
Prérequis
Pour suivre ce didacticiel, vous devez effectuer les opérations suivantes :
- Suivez les étapes de prémigration comme l’estimation du débit et le choix d’une clé de partition.
- Créez un compte Azure Cosmos DB for MongoDB.
Provisionner un cluster Azure Databricks
Vous pouvez suivre les instructions pour approvisionner un cluster Azure Databricks. Nous vous recommandons de sélectionner le runtime Databricks version 7.6, qui prend en charge Spark 3.0.
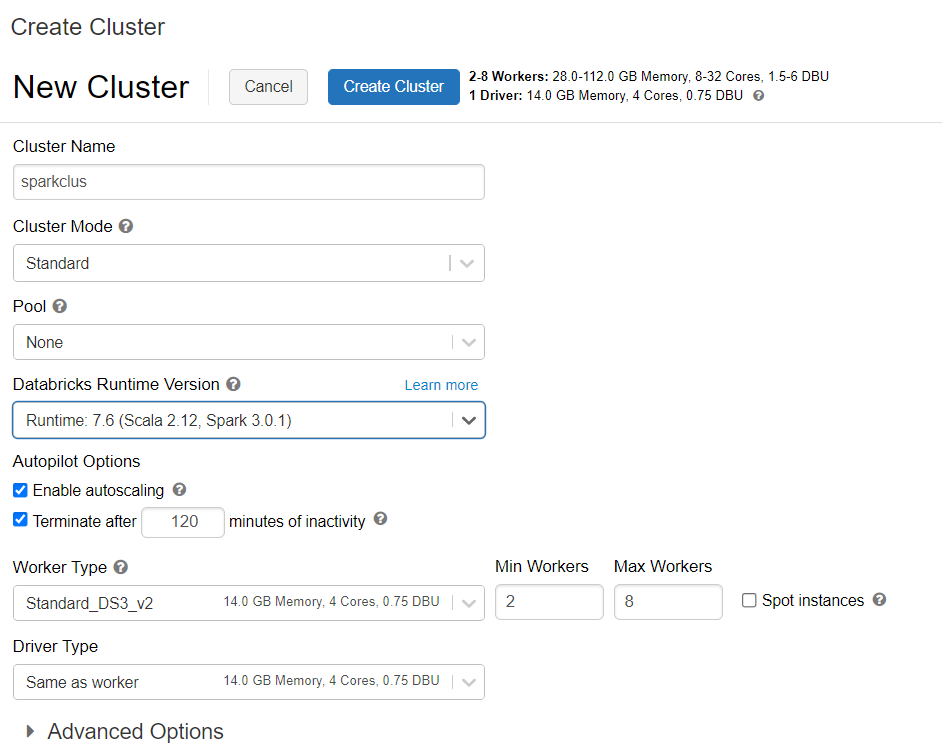
Ajout de dépendances
Ajoutez le connecteur MongoDB pour la bibliothèque Spark à votre cluster pour le connecter à MongoDB en mode natif et aux points de terminaison Azure Cosmos DB for MongoDB. Dans votre cluster, sélectionnez Bibliothèques>Installer nouveau>Maven, puis ajoutez les coordonnées Maven org.mongodb.spark:mongo-spark-connector_2.12:3.0.1.
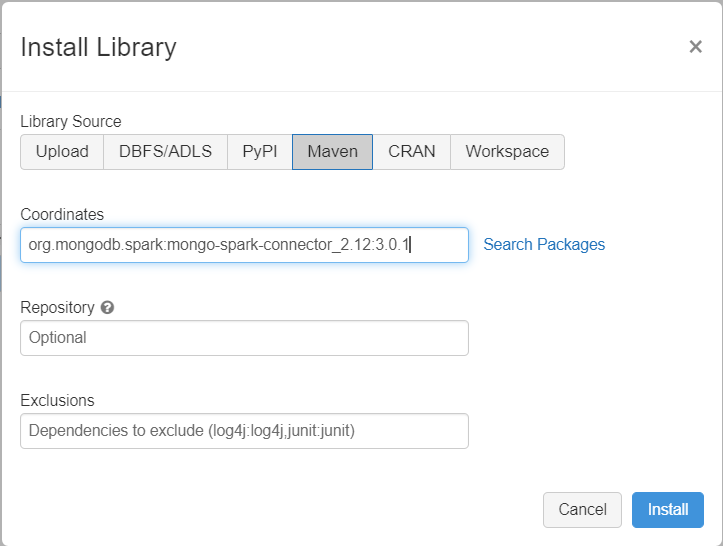
Sélectionnez Installer, puis redémarrez le cluster une fois l’installation terminée.
Notes
Veillez à redémarrer le cluster Databricks après l’installation du connecteur MongoDB pour la bibliothèque Spark.
Après cela, vous pouvez créer un notebook Scala ou Python pour la migration.
Créer un notebook Scala pour la migration
Créez un notebook Scala dans Databricks. Veillez à entrer les valeurs appropriées pour les variables avant d’exécuter le code suivant :
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Créer un notebook Python pour la migration
Créez un notebook Python dans Databricks. Veillez à entrer les valeurs appropriées pour les variables avant d’exécuter le code suivant :
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Optimiser les performances de migration
Les performances de migration peuvent être ajustées à l’aide de ces configurations :
Nombre de workers et de cœurs dans le cluster Spark: d’autres workers signifient davantage de partitions de calcul pour exécuter des tâches.
maxBatchSize : la valeur
maxBatchSizecontrôle la vitesse à laquelle les données sont enregistrées dans la collection Azure Cosmos DB cible. Toutefois, si la valeur maxBatchSize est trop élevée pour le débit de collection, cela peut entraîner des erreurs de limitation du débit.Vous devez ajuster le nombre de Workers et la valeur maxBatchSize en fonction du nombre d’Exécuteurs dans le cluster Spark, éventuellement de la taille (et donc du coût de RU) de chaque document et des limites de débit de la collection cible.
Conseil
maxBatchSize = Débit de collection / (coût de RU pour 1 document * nombre de rôles de travail Spark * nombre de cœurs de processeur par rôle de travail)
Partitionneur MongoDB Spark et clé de partition : le partitionneur utilisé par défaut est MongoDefaultPartitioner et la clé de partition par défaut est _id. Vous pouvez modifier le partitionneur en attribuant la valeur
MongoSamplePartitionerà la propriété de configuration d’entréespark.mongodb.input.partitioner. De même, vous pouvez modifier la clé de partition en attribuant le nom de champ approprié à la propriété de configuration d’entréespark.mongodb.input.partitioner.partitionKey. La clé de partition appropriée permet d’éviter l’asymétrie des données (un grand nombre d’enregistrements écrits pour la même valeur de clé de partition).Désactivez les index durant le transfert de données : pour la migration de grandes quantités de données, envisagez de désactiver les index, en particulier l’index générique sur la collection cible. Les index augmentent le coût de RU pour l’écriture de chaque document. La libération de ces RU peut contribuer à améliorer la vitesse de transfert des données. Vous pouvez activer les index après la migration des données.
Dépanner
Erreur de délai d’expiration (code d’erreur 50)
Vous pouvez constater un code d’erreur 50 pour les opérations sur la base de données Azure Cosmos DB for MongoDB. Les scénarios suivants peuvent entraîner des erreurs de délai d’expiration :
- Le débit alloué à la base de données est faible : vérifiez qu’un débit suffisant est attribué à la collection cible.
- Asymétrie excessive des données avec un volume important de données. Si vous avez une grande quantité de données à migrer vers une table donnée, mais que les données présentent une asymétrie importante, vous pouvez quand même subir une limitation de débit, même si vous avez provisionné plusieurs unités de requête dans votre table. Les unités de requête sont réparties de manière égale entre les partitions physiques, et une forte asymétrie des données peut provoquer un goulot d’étranglement des requêtes adressées à une seule partition. L’asymétrie des données signifie qu’il existe un grand nombre d’enregistrements pour la même valeur de clé de partition.
Limitation du débit (code d’erreur 16500)
Vous pouvez constater un code d’erreur 16500 pour les opérations sur la base de données Azure Cosmos DB for MongoDB. Il s’agit d’erreurs de limitation du débit qui peuvent être observées sur des comptes anciens ou des comptes où la fonctionnalité de nouvelle tentative côté serveur est désactivée.
- Activer la fonctionnalité de nouvelle tentative côté serveur : activez la fonctionnalité de nouvelle tentative côté serveur et laissez le serveur réessayer automatiquement les opérations à débit limité.
Optimisation de la post-migration
Après avoir migré les données, vous pouvez vous connecter à Azure Cosmos DB et gérer les données. Vous pouvez également effectuer d’autres étapes post-migration comme l’optimisation de la stratégie d’indexation, la mise à jour du niveau de cohérence par défaut ou la configuration de la distribution mondiale pour votre compte Azure Cosmos DB. Pour plus d’informations, consultez l’article Optimisation de la post-migration.
Ressources supplémentaires
- Vous tentez d’effectuer une planification de la capacité pour une migration vers Azure Cosmos DB ?
- Si vous ne connaissez que le nombre de vCores et de serveurs présents dans votre cluster de bases de données existant, lisez Estimation des unités de requête à l’aide de vCores ou de processeurs virtuels
- Si vous connaissez les taux de requêtes typiques de votre charge de travail de base de données actuelle, lisez la section concernant l’estimation des unités de requête à l’aide du planificateur de capacité Azure Cosmos DB