Utilisation d’un graphique partitionné dans Azure Cosmos DB
S’APPLIQUE À : ![]() Gremlin
Gremlin
Une des fonctionnalités clés de l’API pour Gremlin dans Azure Cosmos DB est la capacité de gérer des graphes à grande échelle avec la mise à l’échelle horizontale. Les conteneurs peuvent évoluer indépendamment en termes de débit et de stockage. Vous pouvez créer des conteneurs dans Azure Cosmos DB qui peuvent être automatiquement mis à l’échelle pour stocker des données graphiques. Les données sont automatiquement réparties en fonction de la clé de partition spécifiée.
Le partitionnement est effectué en interne si le conteneur doit stocker plus de 20 Go ou si vous souhaitez allouer plus de 10 000 unités de requête (RU) par seconde. Les données sont automatiquement partitionnées en fonction de la clé de partition que vous spécifiez. La clé de partition est requise si vous créez des conteneurs de graphiques à partir du portail Azure ou les versions 3.x ou ultérieures des pilotes Gremlin. La clé de partition n’est pas requise si vous utilisez les versions 2.x ou antérieures des pilotes Gremlin.
Les mêmes principaux généraux du mécanisme de partitionnement Azure Cosmos DB s’appliquent avec quelques optimisations spécifiques des graphiques, décrites ci-dessous.
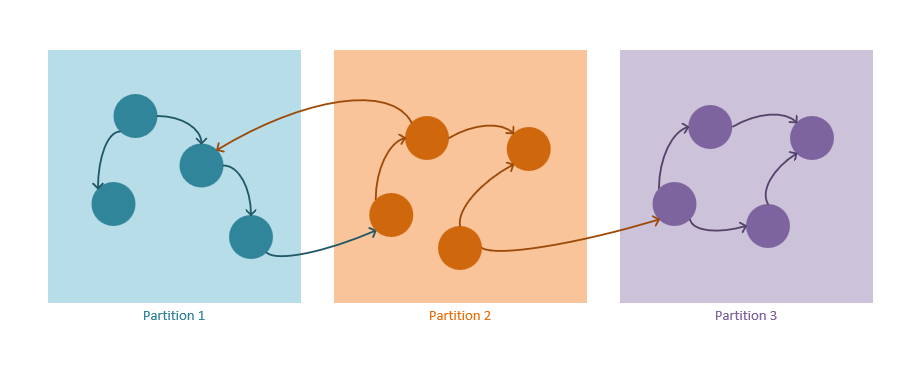
Mécanisme de partitionnement dans Graph
Les instructions suivantes décrivent le fonctionnement de la stratégie de partitionnement dans Azure Cosmos DB :
Les sommets et arêtes sont stockés sous forme de documents JSON.
Les sommets nécessitent une clé de partition. Cette clé détermine dans quelle partition le sommet est stocké par un algorithme de hachage. Le nom de la propriété de clé de partition est défini lors de la création d’un conteneur. Il se présente au format suivant :
/partitioning-key-name.Les arêtes seront stockées avec leur sommet source. En d’autres termes, la clé de partition de chaque sommet définit là où elles sont stockées avec ses arêtes sortantes. Cette optimisation permet d’éviter les requêtes entre partitions lors de l’utilisation de la cardinalité
out()dans les requêtes de graphique.Les bords contiennent des références aux sommets vers lesquels ils pointent. Tous les bords sont stockés avec les clés de partition et les ID des sommets vers lesquels ils pointent. Suite à ce calcul, toutes les requêtes de direction
out()ont la portée d’une requête partitionnée, et non d’une requête entre partition.Les requêtes de graphique doivent spécifier une clé de partition. Pour tirer pleinement parti du partitionnement horizontal dans Azure Cosmos DB, la clé de partition doit être spécifiée lorsqu’un sommet unique est sélectionné, dans la mesure du possible. Les requêtes suivantes permettent de sélectionner un ou plusieurs sommets dans un graphique partitionné :
/idet/labelne sont pas pris en charge en tant que clés de partition d’un conteneur dans l’API pour Gremlin.Sélection d’un sommet par ID, puis à l’aide de l’étape
.has()pour spécifier la propriété de clé de partition :g.V('vertex_id').has('partitionKey', 'partitionKey_value')Sélection d’un sommet en spécifiant un tuple comprenant la valeur de la clé de partition et l’ID :
g.V(['partitionKey_value', 'vertex_id'])Sélection d’un ensemble de sommets avec leurs ID et spécification d’une liste de valeurs de clé de partition :
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Utilisation de la stratégie de partition au début d’une requête et spécification d’une partition pour l’étendue du reste de la requête Gremlin :
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Meilleures pratiques lors de l’utilisation d’un graphique partitionné
Pour garantir de hautes performances et une bonne évolutivité lors de l’utilisation de graphiques partitionnés avec des conteneurs illimités, utilisez les instructions suivantes :
Spécifiez toujours la valeur de la clé de partition lors de l’interrogation d’un sommet. L’obtention des sommets à partir d’une partition connue permet d’optimiser les performances. Toutes les opérations de contiguïté suivantes auront toujours une portée de partition, car les bords contiennent l’ID de référence et la clé de partition de leurs sommets cibles.
Utilisez la direction sortante lorsque vous interrogez des arêtes dans la mesure du possible. Comme nous l’avons déjà vu, les arêtes sont stockées avec leurs sommets sources dans la direction sortante. En d’autres termes, le risque de recourir à des requêtes entre partitions est réduit lorsque les données et les requêtes sont conçues dans cet esprit. Au contraire, la requête
in()sera toujours une requête de distribution ramifiée coûteuse.Choisissez une clé de partition qui répartira les données de manière uniforme entre les partitions. Cette décision dépend fortement du modèle de données de la solution. Pour en savoir plus sur la création d’une clé de partition appropriée, consultez Partitionner et mettre à l’échelle dans Azure Cosmos DB.
Optimisez les requêtes pour obtenir des données dans les limites d’une partition. Une stratégie de partitionnement optimale doit être en phase avec les modèles de requête. Les requêtes qui obtiennent des données à partir d’une seule partition offrent les meilleures performances.
Étapes suivantes
Vous pouvez ensuite passer aux articles suivants :
- Pour en savoir plus, consultez Partitionner et mettre à l’échelle dans Azure Cosmos DB.
- Pour en savoir plus, consultez Prise en charge de Gremlin dans l’API pour Gremlin.
- Pour en savoir plus, consultez Présentation de l’API pour Gremlin.