Prise en main de la capture des changements de données dans le magasin analytique pour Azure Cosmos DB
S’APPLIQUE À : ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Utilisez la capture des changements de données (CDC, Change data capture) dans le magasin analytique Azure Cosmos DB comme source pour Azure Data Factory ou Azure Synapse Analytics pour capturer des modifications spécifiques à vos données.
Notes
Veuillez noter que l’interface de service lié pour l’API Azure Cosmos DB for MongoDB n’est pas encore disponible sur Dataflow. Toutefois, vous pouvez utiliser le point de terminaison de document de votre compte avec l’interface de service lié « Azure Cosmos DB for NoSQL » comme solution de contournement jusqu’à ce que le service lié Mongo soit pris en charge. Sur un service lié NoSQL, choisissez « Entrer manuellement » pour fournir les informations du compte Cosmos DB et utiliser le point de terminaison de document du compte (par exemple, https://[your-database-account-uri].documents.azure.com:443/) au lieu du point de terminaison MongoDB (par exemple : mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/)
Prérequis
- Compte Azure Cosmos DB existant.
- Si vous n’avez pas d’abonnement Azure, créez-en un.
- Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Vous pouvez également essayer Azure Cosmos DB gratuitement avant de vous engager.
Activer le magasin analytique
Tout d’abord, activez Azure Synapse Link au niveau du compte, puis activez le magasin analytique pour les conteneurs qui conviennent à votre charge de travail.
Activer Azure Synapse Link : Activer Azure Synapse Link pour un compte Azure Cosmos DB
Activez le magasin analytique pour votre ou vos conteneurs :
Option Guide Activation pour un nouveau conteneur spécifique Activation d’Azure Synapse Link pour vos nouveaux conteneurs Activation pour un conteneur existant spécifique Activation d’Azure Synapse Link pour vos conteneurs existants
Créer une ressource Azure cible à l’aide de flux de données
La fonctionnalité de capture des changements de données du magasin analytique est disponible via la fonctionnalité de flux de données d’Azure Data Factory ou d’Azure Synapse Analytics. Pour ce guide, utilisez Azure Data Factory.
Important
Vous pouvez aussi utiliser Azure Synapse Analytics. D’abord, créez un espace de travail Azure Synapse si vous n’en avez pas déjà un. Dans l’espace de travail nouvellement créé, sélectionnez l’onglet Développer, sélectionnez Ajouter une nouvelle ressource, puis sélectionnez Flux de données.
Créez un Azure Data Factory si vous n’en avez pas déjà un.
Conseil
Si possible, créez la fabrique de données dans la même région que votre compte Azure Cosmos DB.
Lancez la fabrique de données nouvellement créée.
Dans la fabrique de données, sélectionnez l’onglet Flux de données, puis sélectionnez Nouveau flux de données.
Donnez un nom unique au flux de données nouvellement créé. Dans cet exemple, le flux de données se nomme
cosmoscdc.

Configurer les paramètres sources pour le conteneur de magasin analytique
Maintenant, créez et configurez une source pour transmettre des données à partir du magasin analytique du compte Azure Cosmos DB.
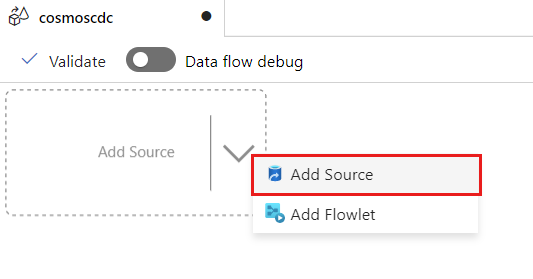
Sélectionnez Ajouter une source.
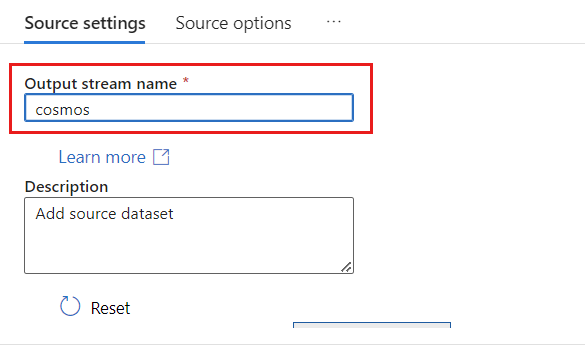
Dans le champ Nom du flux de sortie, entrez cosmos.
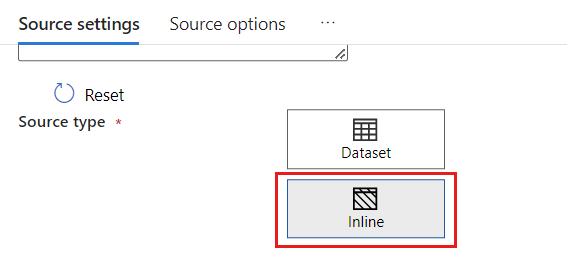
Dans la section Type de source, sélectionnez Inline.
Dans le champ Jeu de données, sélectionnez Azure - Azure Cosmos DB for NoSQL.
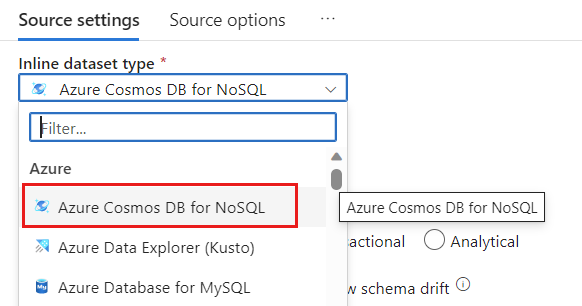
Créez un nouveau service lié pour votre compte nommé cosmoslinkedservice. Sélectionnez votre compte Azure Cosmos DB for NoSQL existant dans la fenêtre de dialogue contextuelle Nouveau service lié, puis sélectionnez Ok. Dans cet exemple, nous sélectionnons un compte Azure Cosmos DB for NoSQL préexistant nommé
msdocs-cosmos-sourceet une base de données nomméecosmicworks.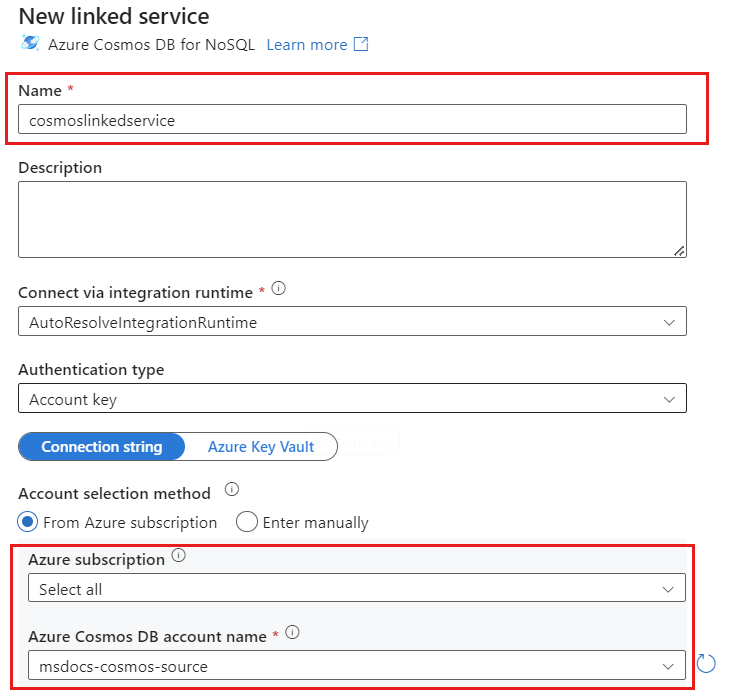
Sélectionnez Analytique pour le type de magasin.
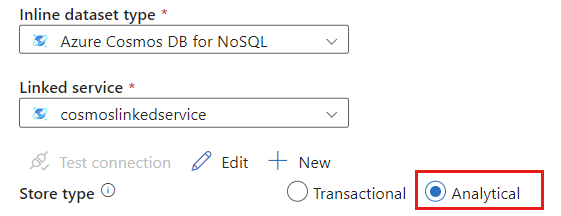
Sélectionnez l’onglet Options de source.
Dans Options de source, sélectionnez votre conteneur cible et activez le Débogage de flux de données. Dans cet exemple, le conteneur est nommé
products.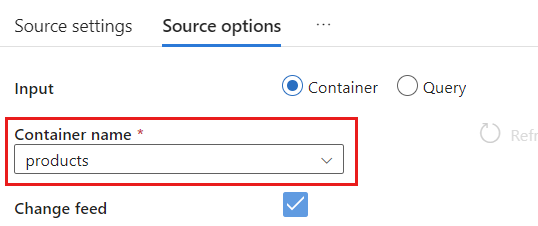
Sélectionnez Débogage de flux de données. Dans la fenêtre de dialogue contextuelle Activer le débogage de flux de données, conservez les options par défaut, puis sélectionnez Ok.
L’onglet Options de source contient également d’autres options que vous pouvez activer si vous le souhaitez. Ce tableau décrit ces options :
| Option | Description |
|---|---|
| Capturer les mises à jour intermédiaires | Activez cette option si vous souhaitez capturer l’historique des changements apportés aux éléments, y compris les modifications intermédiaires entre les lectures de capture des changements de données. |
| Capturer les suppressions | Activez cette option pour capturer les enregistrements supprimés par l’utilisateur et les appliquer sur le récepteur. Les suppressions ne peuvent pas être appliquées sur les récepteurs Azure Data Explorer et Azure Cosmos DB. |
| Capturer les TTL du magasin transactionnel | Activez cette option pour capturer les enregistrements supprimés TTL (time-to-live) du magasin transactionnel Azure Cosmos DB et les appliquer sur le récepteur. Les suppressions de TTL ne peuvent pas être appliquées sur les récepteurs Azure Data Explorer et Azure Cosmos DB. |
| Taille de lot en octets | Ce paramètre est en réalité en gigaoctets. Spécifiez la taille en gigaoctets si vous souhaitez traiter par lot les flux de capture des changements de données |
| Configurations supplémentaires | Configurations supplémentaires du magasin analytique Azure Cosmos DB et leurs valeurs. (Exemple : spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Utilisation des options sources
Lorsque vous consultez les options Capture intermediate updates, Capture Deltes et Capture Transactional store TTLs, votre processus CDC crée et remplit le champ __usr_opTypedans le récepteur avec les valeurs suivantes :
| Valeur | Description | Option |
|---|---|---|
| 1 | UPDATE | Capturer des mises à jour intermédiaires |
| 2 | INSERT | Il n’existe pas d’option pour les insertions, elle est activée par défaut |
| 3 | USER_DELETE | Capturer les suppressions |
| 4 | TTL_DELETE | Capturer les TTL du magasin transactionnel |
Si vous devez différencier les enregistrements supprimés TTL des documents supprimés par les utilisateurs ou les applications, vous devez cocher les options Capture intermediate updates et Capture Transactional store TTLs. Ensuite, vous devez adapter vos processus ou applications ou requêtes CDC pour utiliser __usr_opType en fonction des besoins de votre entreprise.
Conseil
Si les consommateurs en aval doivent rétablir l’ordre des mises à jour avec l’option « capturer les mises à jour intermédiaires » activée, le champ du timestamp système _ts peut être utilisé comme champ de commande.
Créer et configurer des paramètres de récepteur pour les opérations de mise à jour et de suppression
Créez d’abord un récepteur Stockage Blob Azure simple, puis configurez le récepteur pour uniquement filtrer les données sur des opérations spécifiques.
Créez un compte et un conteneur Stockage Blob Azure si vous n’en avez pas déjà un. Pour les exemples suivants, nous allons utiliser un compte nommé
msdocsblobstorageet un conteneur nomméoutput.Conseil
Si possible, créez un compte de stockage dans la même région que votre compte Azure Cosmos DB.
Retournez dans Azure Data Factory et créez un nouveau récepteur pour la capture des changements de données à partir de votre source
cosmos.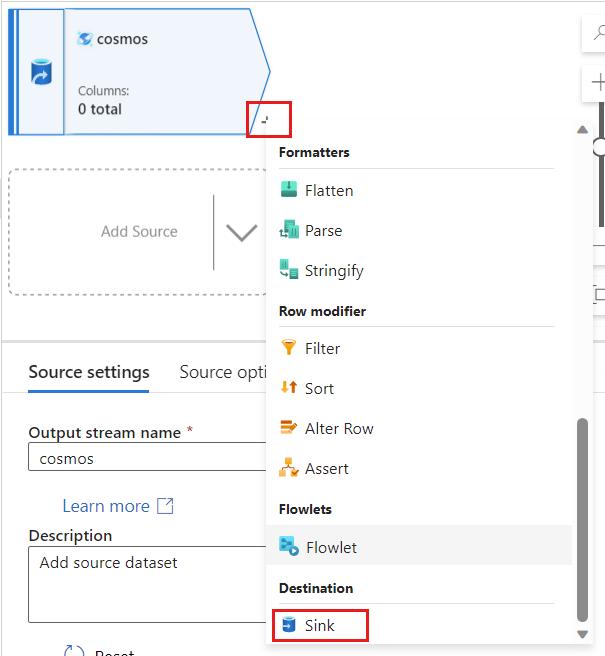
Donnez au récepteur un nom unique. Dans cet exemple, le récepteur est nommé
storage.
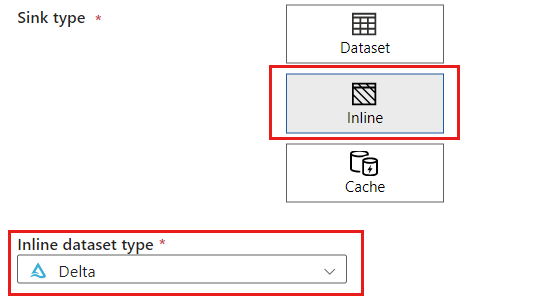
Dans la section Type de récepteur, sélectionnez Inline. Dans le champ Jeu de données, sélectionnez Delta.
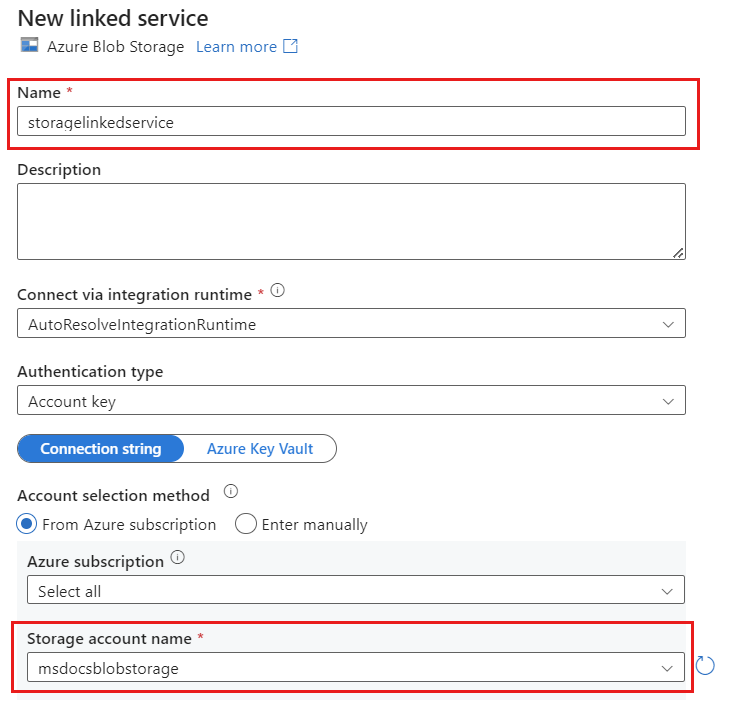
Créez un service lié nommé storagelinkedservice pour votre compte à l’aide du Stockage Blob Azure. Sélectionnez votre compte Stockage Blob Azure existant dans la fenêtre de dialogue contextuelle Nouveau service lié, puis sélectionnez Ok. Dans cet exemple, nous sélectionnons un compte Stockage Blob Azure préexistant nommé
msdocsblobstorage.
Sélectionnez l’onglet Settings (Paramètres).
Dans Paramètres, définissez le Chemin du dossier sur le nom du conteneur blob. Dans cet exemple, le nom du conteneur est
output.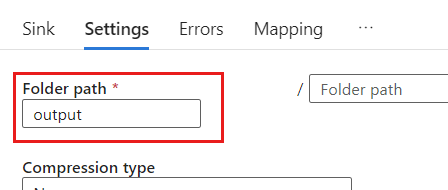
Repérez la section Méthode de mise à jour et modifiez les sélections pour autoriser uniquement les opérations de suppression et de mise à jour. Spécifiez également les Colonnes clés en tant que Liste de colonnes en utilisant le champ
{_rid}comme identificateur unique.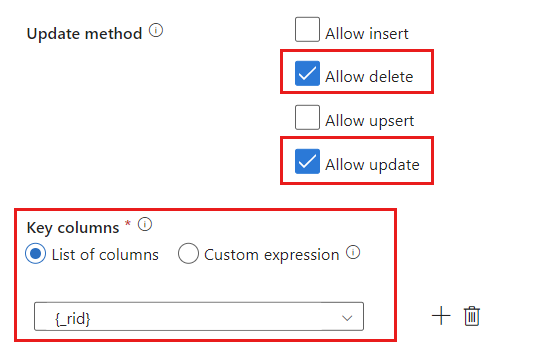
Sélectionnez Valider pour assurer que vous n’avez commis aucune erreur ou omission. Ensuite, sélectionnez Publier pour publier le flux de données.
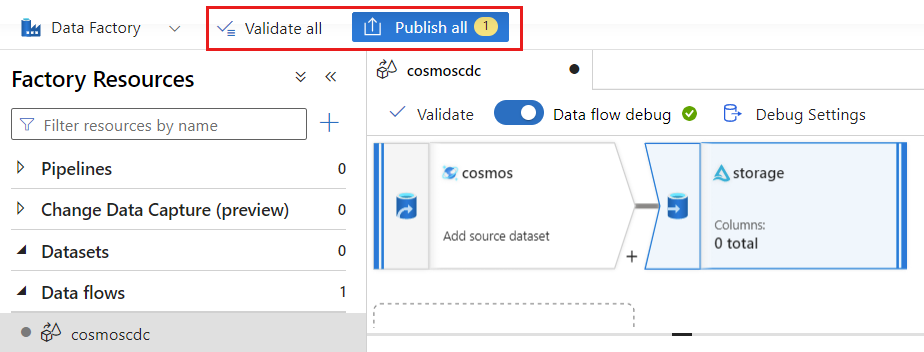
Planifier l’exécution d’une capture des changements de données
Une fois qu’un flux de données a été publié, vous pouvez ajouter un nouveau pipeline pour déplacer et transformer vos données.
Créer un pipeline Donnez un nom unique au pipeline. Dans cet exemple, le pipeline est nommé
cosmoscdcpipeline.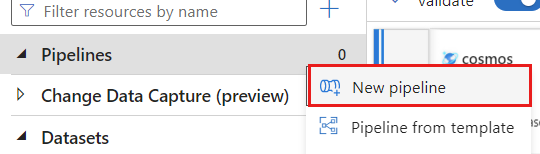
Dans la section Activités, développez l’option Déplacer et transformer, puis sélectionnez Flux de données.
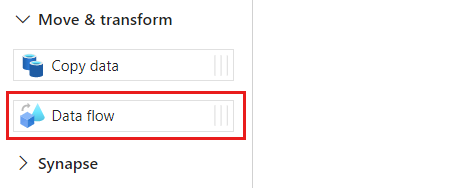
Donnez un nom unique à l’activité de flux de données. Dans cet exemple, l’activité est nommée
cosmoscdcactivity.Sous l’onglet Paramètres, sélectionnez le flux de données nommé
cosmoscdcque vous avez précédemment créé dans ce guide. Ensuite, sélectionnez une taille de calcul basée sur le volume de données et sur la latence requise pour votre charge de travail.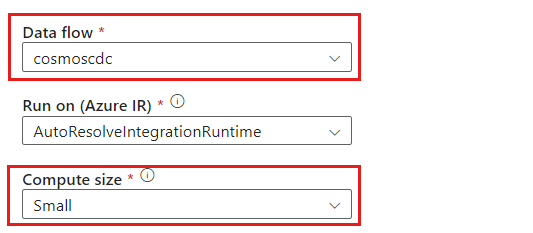
Conseil
Pour les tailles de données incrémentielles supérieures à 100 Go, nous recommandons la taille Personnalisée avec 32 cœurs (+16 cœurs pilotes).
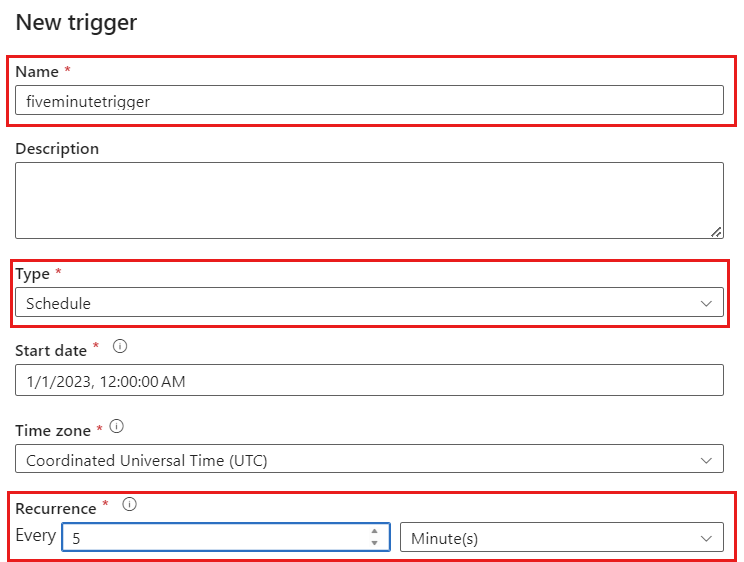
Sélectionnez Ajouter un déclencheur. Planifiez l’exécution de ce pipeline à une cadence logique pour votre charge de travail. Dans cet exemple, le pipeline est configuré pour une exécution toutes les cinq minutes.
Notes
La fenêtre de périodicité minimale pour les exécutions de capture des changements de données est d’une minute.
Sélectionnez Valider pour assurer que vous n’avez commis aucune erreur ou omission. Sélectionnez Publier pour publier le pipeline.
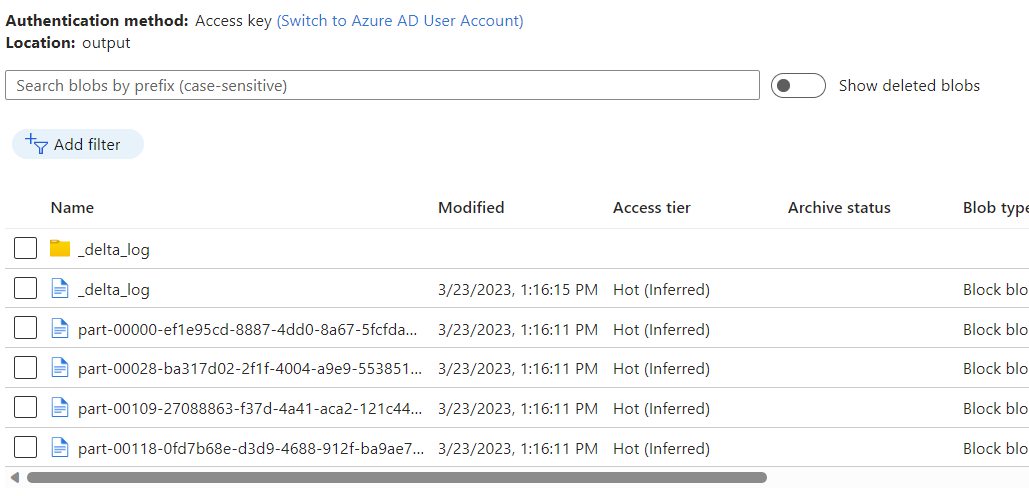
Observez les données placées dans le conteneur Stockage Blob Azure en tant que sortie du flux de données à l’aide de la capture des changements de données du magasin analytique Azure Cosmos DB.
Notes
Le temps de démarrage initial du cluster peut prendre jusqu’à trois minutes. Pour éviter un temps de démarrage du cluster dans les exécutions de capture des changements de données suivantes, configurez la valeur TTL du cluster de flux de données. Pour plus d’informations sur le runtime d’intégration et le TTL, consultez Runtime d’intégration dans Azure Data Factory.
Travaux simultanés
La taille du lot dans les options sources, ou les situations avec le récepteur lent à ingérer le flux de modifications, peuvent entraîner l’exécution simultanée de plusieurs travaux. Pour éviter cette situation, définissez l’option Concurrence sur 1 dans les paramètres du pipeline pour vous assurer que les nouvelles exécutions ne sont pas déclenchées jusqu’à la fin de l’exécution actuelle.
Étapes suivantes
- Consulter la vue d’ensemble du magasin analytique Azure Cosmos DB