Recherche en texte intégral dans Azure Cosmos DB for NoSQL (préversion)
Azure Cosmos DB for NoSQL offre désormais une puissante fonctionnalité de recherche en texte intégral en préversion, conçue pour améliorer les fonctionnalités de recherche de vos applications.
Remarque
La recherche en texte intégral et hybride est en préversion anticipée et peut ne pas être disponible dans toutes les régions pour l’instant.
Qu’est-ce que la recherche en texte intégral ?
Azure Cosmos DB for NoSQL offre désormais une puissante fonctionnalité de recherche en texte intégral en préversion, conçue pour améliorer les fonctionnalités d’interrogation de vos données. Cette fonctionnalité inclut des techniques de traitement de texte avancées, telles que la recherche de radical, l’arrêt de la suppression de mots et la segmentation du texte en unités lexicales, ce qui permet de rechercher du texte de manière effective et efficace via un index de texte spécialisé. La recherche en texte intégral inclut également le scoring de texte intégral avec une fonction qui évalue la pertinence des documents par rapport à une requête de recherche donnée. BM25, pour Best Matching 25, prend en compte des facteurs, tels que la fréquence des termes, la fréquence inverse de document et la longueur de document, pour noter et classer des documents. Cela permet de s’assurer que les documents les plus pertinents apparaissent en haut des résultats de la recherche, ce qui améliore la précision et l’utilité des recherches de texte.
La recherche en texte intégral est idéale pour divers scénarios, notamment :
- E-commerce : Recherchez rapidement des produits basés sur des descriptions, des avis et autres attributs de texte.
- Gestion de contenu : Recherchez efficacement des articles, des blogs et des documents.
- Service clientèle : Récupérez des tickets de support, des FAQ et des articles de la base de connaissances qui vous intéressent.
- Contenu utilisateur : Analysez et recherchez du contenu généré par l’utilisateur tel que des posts et des commentaires.
- RAG pour les chatbots : Améliorez les réponses des chatbots en récupérant des informations pertinentes de corpus de texte pour améliorer la précision et la pertinence des réponses.
- Applications IA multi-agent : Permettez à plusieurs agents d’IA de rechercher et d’analyser en collaboration de vastes quantités de données textuelles pour fournir des insights complets et nuancés.
Comment utiliser la recherche en texte intégral
Remarque
La recherche en texte intégral et hybride (préversion) peut ne pas être disponible dans toutes les régions pour l’instant.
- Activez la fonctionnalité en préversion « Recherche en texte intégral et hybride pour NoSQL ».
- Configurez un conteneur avec une stratégie de texte intégral et un index de texte intégral.
- Insérez vos données avec des propriétés de texte.
- Exécutez des requêtes hybrides sur les données.
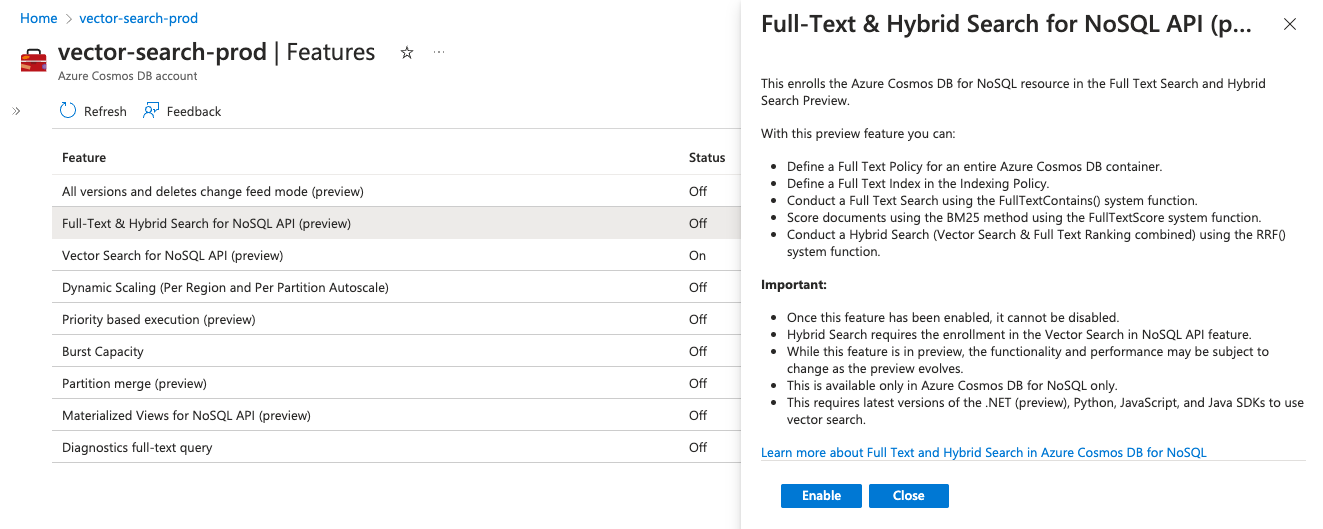
Activer la fonctionnalité en préversion de recherche en texte intégral et hybride pour NoSQL
La recherche en texte intégral, le scoring de texte intégral et la recherche hybride nécessitent tous l’activation de la fonctionnalité en préversion sur votre compte Azure Cosmos DB for NoSQL avant de les utiliser. Suivez les étapes ci-dessous pour vous inscrire :
- Accédez à votre page de ressource Azure Cosmos DB for NoSQL.
- Sélectionnez le volet « Fonctionnalités » sous l’élément de menu « Paramètres ».
- Sélectionnez la fonctionnalité « API de recherche en texte intégral et hybride pour NoSQL (préversion) ».
- Lisez la description de la fonctionnalité pour confirmer que vous souhaitez l’activer.
- Sélectionnez « Activer » pour activer l’indexation vectorielle et la fonctionnalité de recherche.
Configurer des stratégies de conteneur et des index pour la recherche hybride
Pour utiliser les fonctionnalités de recherche en texte intégral, vous devez d’abord définir deux stratégies :
- Une stratégie de texte intégral de niveau conteneur qui définit les chemins qui contiennent du texte pour les nouvelles fonctions système de requête de texte intégral.
- Un index de recherche en texte intégral ajouté à la stratégie d’indexation qui permet une recherche efficace.
Stratégie de texte intégral
Pour chaque propriété de texte que vous souhaitez configurer pour la recherche en texte intégral, vous devez déclarer à la fois le path de la propriété avec du texte et la language du texte. Une stratégie de texte intégral simple peut être :
{
"defaultLanguage": "en-US",
"fullTextPaths": [
{
"path": "/text",
"language": "en-US"
}
]
}
La définition de plusieurs chemins de texte est facile à réaliser en ajoutant un autre élément au tableau fullTextPolicy :
{
"defaultLanguage": "en-US",
"fullTextPaths": [
{
"path": "/text1",
"language": "en-US"
},
{
"path": "/text2",
"language": "en-US"
}
]
}
Remarque
L’anglais (« en-us » comme langue) est la seule langue prise en charge pour l’instant.
Important
Actuellement, les caractères génériques (*, []) ne sont pas pris en charge dans la stratégie de texte intégral ou l’index de texte intégral.
Index de texte intégral
Toutes les opérations de recherche en texte intégral doivent utiliser un index de texte intégral. Un index de texte intégral peut facilement être défini dans n’importe quelle stratégie d’index Azure Cosmos DB for NoSQL, comme le montre l’exemple ci-dessous.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/\"_etag\"/?"
},
],
"fullTextIndexes": [
{
"path": "/text"
}
]
}
Tout comme avec les stratégies de texte intégral, les index de texte intégral peuvent être définis sur plusieurs chemins.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/\"_etag\"/?"
},
],
"fullTextIndexes": [
{
"path": "/text"
},
{
"path": "/text2"
}
]
}
Requêtes de recherche en texte intégral
Les opérations de recherche en texte intégral et de scoring sont effectuées à l’aide des fonctions système suivantes dans le langage de requête Azure Cosmos DB for NoSQL :
FullTextContains: retournetruesi une chaîne donnée est contenue dans la propriété spécifiée d’un document. Cela est utile dans une clauseWHERElorsque vous souhaitez vous assurer que des mots clés spécifiques se trouvent dans les documents retournés par votre requête.FullTextContainsAll: retournetruesi toutes les chaînes données sont contenues dans la propriété spécifiée d’un document. Cela est utile dans une clauseWHERElorsque vous souhaitez vous assurer que plusieurs mots clés se trouvent dans les documents retournés par votre requête.FullTextContainsAny: retournetruesi une des chaînes données est contenue dans la propriété spécifiée d’un document. Cela est utile dans une clauseWHERElorsque vous souhaitez vous assurer qu’au moins un des mots clés se trouve dans les documents retournés par votre requête.FullTextScore: retourne un score. Vous pouvez uniquement l’utiliser dans une clauseORDER BY RANKoù les documents retournés sont classés en fonction du score de texte intégral, avec les documents les plus pertinents (scoring le plus élevé) en haut et les documents les moins pertinents (scoring le plus faible) en bas.
Voici quelques exemples de chaque fonction utilisée.
FullTextContains
Dans cet exemple, nous voulons obtenir les 10 premiers résultats où le mot clé « bicycle » est contenu dans la propriété c.text.
SELECT TOP 10 *
FROM c
WHERE FullTextContains(c.text, "bicycle")
FullTextContainsAll
Dans cet exemple, nous voulons obtenir les 10 premiers résultats où les mots clés « red» et « bicycle » sont contenus dans la propriété c.text.
SELECT TOP 10 *
FROM c
WHERE FullTextContainsAll(c.text, "red", "bicycle")
FullTextContainsAny
Dans cet exemple, nous voulons obtenir les 10 premiers résultats où les mots clés « red» et « bicycle » ou « skateboard » sont contenus dans la propriété c.text.
SELECT TOP 10 *
FROM c
WHERE FullTextContains(c.text, "red") AND FullTextContainsAny(c.text, "bicycle", "skateboard")
FullTextScore
Dans cet exemple, nous voulons obtenir les 10 premiers résultats où « mountain » et « bicycle » sont inclus et triés par ordre de pertinence. Autrement dit, les documents qui contiennent ces termes plus souvent doivent apparaître plus haut dans la liste.
SELECT TOP 10 *
FROM c
ORDER BY RANK FullTextScore(c.text, ["bicycle", "mountain"])
Important
FullTextScore peut seulement être utilisé dans la clause ORDER BY RANK et non projeté dans l’instruction SELECT ou dans une clause WHERE.